Convey this undertaking to life
Context Cluster
Convolutional Neural Networks and Imaginative and prescient based mostly Transformer fashions (ViT) are extensively unfold methods to course of pictures and generate clever predictions. The flexibility of the mannequin to generate predictions solely relies on the best way it processes the picture. CNNs contemplate a picture as well-arranged pixels and extract native options utilizing the convolution operation by filters in a sliding window style. On the opposite facet, Imaginative and prescient Transformer (ViT) descended from NLP analysis and thus treats a picture as a sequence of patches and can extract options from every of these patches. Whereas CNNs and ViT are nonetheless very fashionable, you will need to take into consideration different methods to course of pictures that will give us different advantages.
Researchers at Adobe & Northeastern College lately launched a mannequin named Context-Cluster. It treats a picture as a set of many factors. Slightly than utilizing subtle methods, it makes use of the clustering approach to group these units of factors into a number of clusters. These clusters might be handled as teams of patches and might be processed in a different way for downstream duties. We are able to make the most of the identical pixel embeddings for various duties (classification, semantic segmentation, and so forth.)
Mannequin structure
Initially, we’ve a picture of form (3, W, H) denoting the variety of channels, width, and peak of the picture. This uncooked picture comprises Three channels (RGB) representing completely different coloration values. So as to add 2 extra knowledge factors, we additionally contemplate the place of the pixel within the W x H airplane. To reinforce the distribution of the place function, the place worth (i, j) is transformed to (i/W – 0.5, j/H – 0.5) for all pixels in a picture. Finally, we find yourself with the dataset with form (5, N) the place N represents the variety of pixels (W * H) within the picture. This sort of illustration of picture might be thought-about common since we have not assumed something till now.
Now if we recall the standard clustering methodology (Okay-means), we have to assign some random factors as cluster facilities after which compute the closest cluster heart for all of the accessible knowledge factors (pixels). However for the reason that picture can have arbitrarily giant decision and thus could have too many pixels of a number of dimensions in it. Computing the closest cluster heart for all of them is not going to be computationally possible. To beat this difficulty, we first cut back the dimension of factors for the dataset by an operation referred to as Level Reducer. It reduces the dimension of the factors by linearly projecting (utilizing a totally related layer) the dataset. Because of this, we get a dataset of dimension (N, D) the place D is the variety of options of every pixel.
The subsequent step is context clustering. It randomly selects some c heart factors over the dataset, selects okay nearest neighbors for every heart level, concatenates these okay factors, and inputs them to the totally related linear layer. Outputs of this linear layer are the options for every heart level. From the c-center options, we outline the pairwise cosign similarity of every heart with every pixel. The form of this similarity matrix is (C, N). Notice right here that every pixel is assigned to solely a single cluster. It means it’s exhausting clustering.
Now, the factors in every cluster are aggregated based mostly on the similarity to the middle. This aggregation is finished equally utilizing a totally related layer(s) and converts options of M knowledge factors inside the cluster to form (M, D’). This step applies to the factors in every cluster independently. It aggregates options of all of the factors inside the cluster. Consider it just like the factors inside every cluster sharing data. After aggregation, the factors are dispatched again to their authentic dimension. It’s once more carried out utilizing a totally related layer(s). Every level is once more remodeled again into D dimensional function.
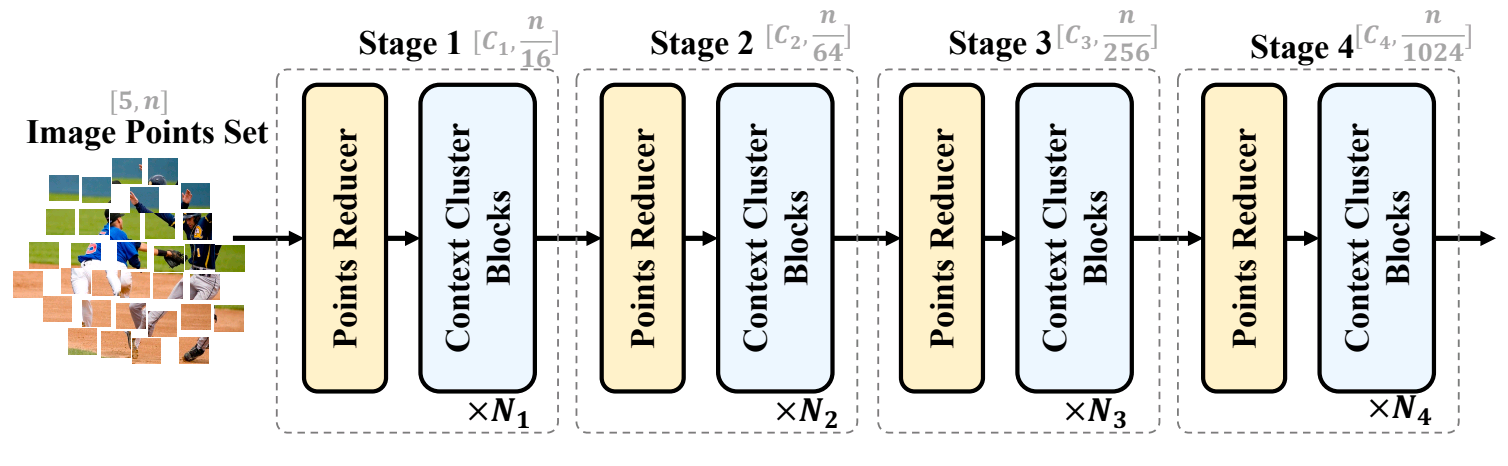
The described four steps (Level Reducer, Context Clustering, Function Aggregation & Function Dispatching) create a single stage of the mannequin. Relying on the complexity of the info, we will add a number of such levels with completely different lowering dimensions in order that it improves its studying instructions. The unique paper describes a mannequin with four levels as proven in Fig 1.
After computing the final stage of the mannequin, we will deal with the resultant options of every pixel in a different way relying on the downstream process. For the classification process, we will calculate the typical of all the purpose options and go it by means of totally related layer(s) which is connected to softmax or sigmoid operate to categorise the logits. For the dense prediction process like segmentation, we have to place the info factors by their location options on the finish of all stage computation. As a part of this weblog, we’ll carry out a cluster visualization process that’s considerably just like a segmentation process.
Comparability with different fashions
The context cluster mannequin is educated in several variants: tiny, small & medium. The variant principally has variations in depth (variety of levels). The context cluster mannequin is educated for 310 epochs on the ImageNet dataset. It’s then in comparison with different well-liked fashions which use Convolutional Neural Networks (CNNs) and Transformers. The mannequin is educated and in contrast for a number of duties like picture classification, object detection, 3D level cloud classification, semantic segmentation, and so forth. The fashions are in contrast for various metrics just like the variety of parameters, variety of FLOPs, top-1% accuracy, throughputs, and so forth.
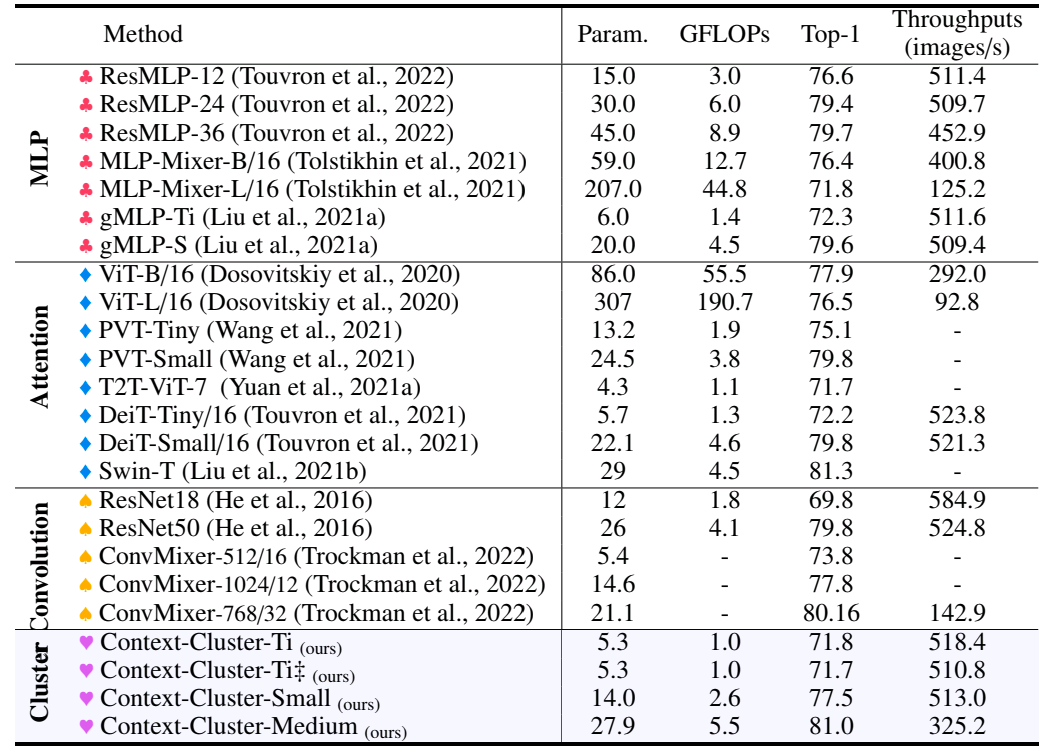
Fig. 2 reveals the comparability of various variants of context-cluster fashions with many different well-liked pc imaginative and prescient fashions. The above-shown comparability is for the classification process. The paper additionally has comparable comparability tables for different duties which you is likely to be concerned with .
We are able to discover within the comparability desk that the context cluster fashions have comparable & generally higher accuracy as in comparison with different fashions. It additionally has a lesser variety of parameters and FLOPs than many different fashions. In use instances the place we’ve big knowledge of pictures to categorise and we will bear little accuracy loss, context cluster fashions is likely to be a more sensible choice.
Attempt it your self
Convey this undertaking to life
Allow us to now stroll by means of how one can obtain the dataset & prepare your individual context cluster mannequin. For the demo goal, you needn’t prepare the mannequin. As an alternative, you may obtain pre-trained mannequin checkpoints to attempt. For this process, we’ll get this operating in a Gradient Pocket book right here on Paperspace. To navigate to the codebase, click on on the “Run on Gradient” button above or on the prime of this weblog.
Setup
The file installations.sh comprises all the required code to put in the required issues. Notice that your system will need to have CUDA to coach Context-Cluster fashions. Additionally, you could require a unique model of torch based mostly on the model of CUDA. In case you are operating this on Paperspace, then the default model of CUDA is 11.6 which is suitable with this code. In case you are operating it some place else, please test your CUDA model utilizing nvcc --version. If the model differs from ours, you could need to change variations of PyTorch libraries within the first line of installations.sh by compatibility desk.
To put in all of the dependencies, run the under command:
bash installations.sh
The above command additionally clones the unique Context-Cluster repository into context_cluster listing in order that we will make the most of the unique mannequin implementation for coaching & inference.
Downloading datasets & Begin coaching (Non-obligatory)
As soon as we’ve put in all of the dependencies, we will obtain the datasets and begin coaching the fashions.
dataset listing on this repo comprises the required scripts to obtain the info and make it prepared for coaching. At the moment, this repository helps downloading ImageNet dataset that the unique authors used.
We have now already setup bash scripts for you which can robotically obtain the dataset for you and can begin the coaching. prepare.sh comprises the code which can obtain the coaching & validation knowledge to dataset the listing and can begin coaching the mannequin.
This bash script is suitable to the Paperspace workspace. However if you’re operating it elsewhere, then you’ll need to exchange the bottom path of the paths talked about on this script prepare.sh.
Earlier than you begin the coaching, you may test & customise all of the mannequin arguments in args.yaml file. Particularly, you could need to change the argument mannequin to one of many following: coc_tiny, coc_tiny_plain, coc_small, coc_medium. These fashions differ by the variety of levels.
To obtain knowledge information and begin coaching, you may execute the under command:
bash prepare.sh
Notice that the generated checkpoints for the educated mannequin will probably be accessible in context_cluster/outputs listing. You have to to maneuver checkpoint.pth.tar file to checkpoints listing for inference on the finish of coaching.
Don’t be concerned in case you do not need to prepare the mannequin. The under part illustrates downloading the pre-trained checkpoints for inference.
Working Gradio Demo
Python script app.py comprises Gradio demo which helps you to visualize clusters on the picture. However earlier than we do this, we have to obtain the pre-trained checkpoints into checkpoints listing.
To obtain current checkpoints, run the under command:
bash checkpoints/fetch_pretrained_checkpoints.sh
Notice that the newest model of the code solely has the pre-trained checkpoints for coc_tiny_plain mannequin variant. However you may add the code in checkpoints/fetch_pretrained_checkpoints.sh each time the brand new checkpoints for different mannequin sorts can be found in authentic repository.
Now, we’re able to launch the Gradio demo. Run the next command to launch the demo:
gradio app.py
Open the hyperlink offered by the Gradio app within the browser and now you may generate inferences from any of the accessible fashions in checkpoints listing. Furthermore, you may generate cluster visualization of particular stage, block and head for any picture. Add your picture and hit the Submit button.
It is best to have the ability to generate cluster visualization for any picture as proven under:
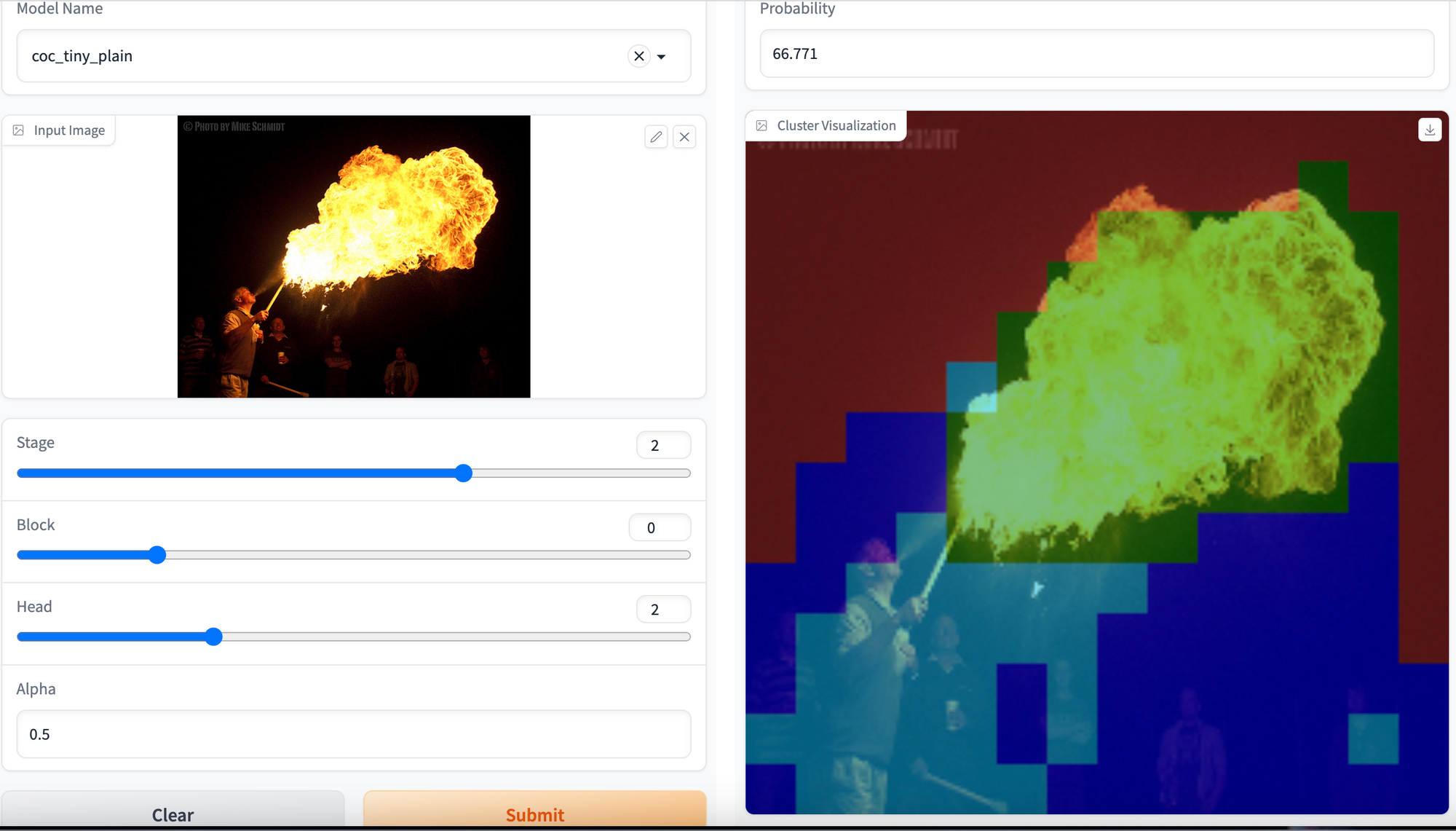
Hurray! 🎉🎉🎉 We have now created a demo to visualise clusters over any picture by inferring the Context-Cluster mannequin.
Conclusion
Context-Cluster is a pc imaginative and prescient approach that treats a picture as a set of factors. It is rather completely different from how CNNs and Imaginative and prescient based mostly Transformer fashions course of pictures. By lowering the factors, the context cluster mannequin performs clever clustering over the picture pixels and partitions pictures into completely different clusters. It has a relatively lesser variety of parameters and FLOPs. On this weblog, we walked by means of the target & the structure of the Context-Cluster mannequin, in contrast the outcomes obtained from Context-Cluster with different state-of-the-art fashions, and mentioned learn how to arrange the setting, prepare your individual Context-Cluster mannequin & generate inference utilizing Gradio app on Gradient Pocket book.
Remember to check out every of the mannequin varieties utilizing Gradient’s big selection of obtainable machine sorts!


