In September 2023, OpenAI rolled out the flexibility to ask questions on photos utilizing GPT-4. A month later on the OpenAI DevDay, these capabilities had been made obtainable by an API, permitting builders to construct functions that use GPT-Four with picture inputs.
Whereas GPT-Four with Imaginative and prescient has captured vital consideration, the service is just one of many Giant Multimodal Fashions (LMMs). LMMs are language fashions that may work with a number of varieties, or “modalities,” of knowledge, corresponding to photos and audio.
On this information, we’re going to discover 5 options to GPT-Four with Imaginative and prescient: 4 LMMs (LLaVA, BakLLaVA, Qwen-VL, and CogVLM) and coaching a fine-tuned laptop imaginative and prescient mannequin. within the TL;DR? Take a look at our desk displaying the outcomes from our checks protecting VQA, OCR, and zero-shot object detection:
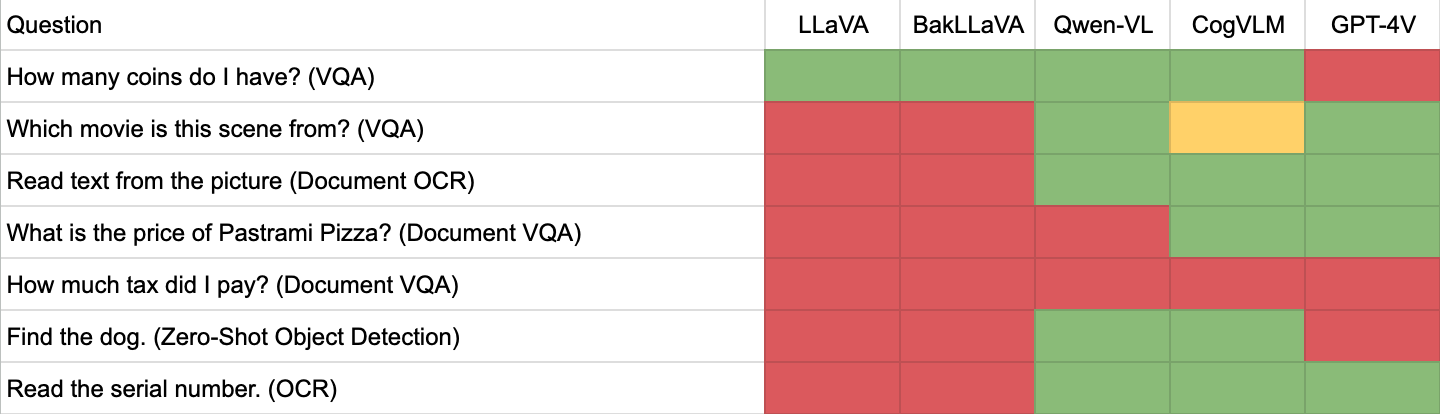
We stroll by every of those checks, and the concerns when utilizing fine-tuned imaginative and prescient fashions (i.e. object detection fashions), on this information. We’ve included excerpts from checks beneath, however you’ll be able to see all of our leads to our LMM analysis outcomes (ZIP file, 10.6 MB).
Our checks aren’t complete, somewhat a snapshot of a sequence of checks we ran consistentlya cross all fashions.
With out additional ado, let’s get began!
What’s GPT-Four with Imaginative and prescient?
Launched in September 2023, GPT-Four with Imaginative and prescient allows you to ask questions concerning the contents of photos. That is known as visible query answering (VQA), a pc imaginative and prescient subject of research that has been researched intimately for years. You too can carry out different imaginative and prescient duties corresponding to Optical Character Recognition (OCR), the place a mannequin reads characters in a picture.
Utilizing GPT-Four with Imaginative and prescient, you’ll be able to ask questions on what’s or is just not in a picture, how objects relate in a picture, the spatial relationships between two objects (is one object to the left or proper of one other), the colour of an object, and extra.
GPT-Four with Imaginative and prescient is on the market by the OpenAI net interface for ChatGPT Plus subscribers, in addition to by the OpenAI GPT-Four Imaginative and prescient API.
The Roboflow workforce has experimented extensively with GPT-Four with Imaginative and prescient. We’ve discovered robust efficiency in visible query answering, Optical Character Recognition (handwriting, doc, math), and different fields. We’ve additionally famous limitations. For instance, GPT-Four with Imaginative and prescient struggles to establish the particular location of objects in photos.
Options to GPT-Four with Imaginative and prescient
The pc imaginative and prescient trade is transferring quick, with multimodal fashions taking part in a rising function within the trade. On the identical time, fine-tuned fashions are displaying vital worth in a variety of use circumstances, as we are going to focus on beneath.
OpenAI is considered one of many analysis groups pursuing LMM analysis. Within the final 12 months, now we have seen GPT-Four with Imaginative and prescient, LLaVA, BakLLaVA, CogVLM, Qwen-VL, and different fashions all goal to attach textual content and picture information collectively to create an LMM.
Each mannequin has its personal strengths and weaknesses. The huge capabilities of LLMs – protecting areas from Optical Character Recognition (OCR) to Visible Query Answering (VQA) – are arduous to check; that is the function of benchmarking. Thus, no mannequin beneath “replaces” GPT-Four with Imaginative and prescient, somewhat acts as an alternative choice to GPT-Four with Imaginative and prescient.
Let’s speak about among the options to GPT-Four with Imaginative and prescient, noting professionals and cons.
Qwen-VL
code | paper | demo
Qwen-VL is an LMM developed by Alibaba Cloud. Qwen-VL accepts photos, textual content, and bounding packing containers as inputs. The mannequin can output textual content and bounding packing containers. Qwen-VL naturally helps English, Chinese language, and multilingual dialog. Thus, this mannequin could also be value exploring when you have a use case the place you anticipate Chinese language and English for use in prompts or solutions.
Under, we use Qwen-VL to ask from what film the picture was taken:
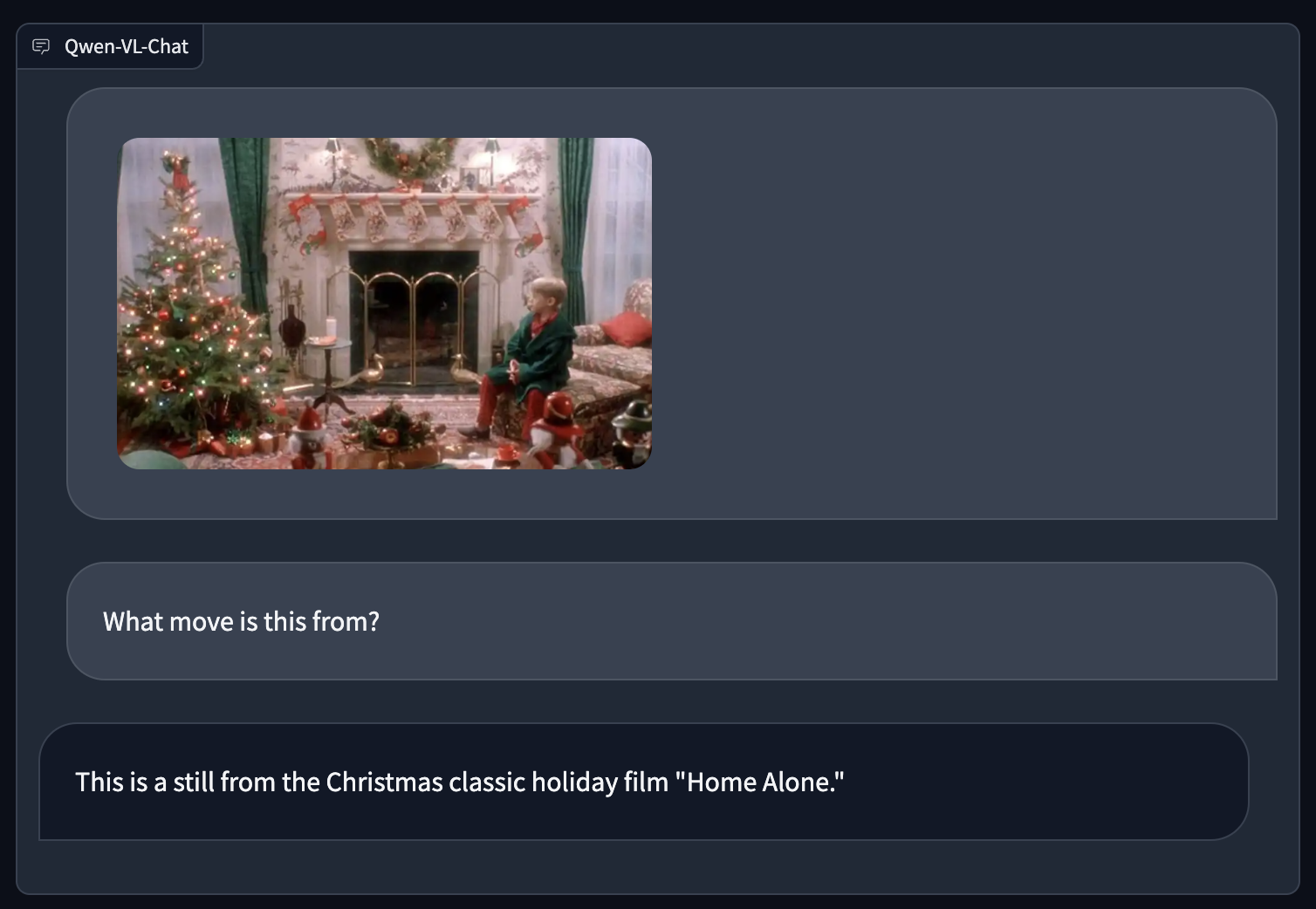
Qwen-VL efficiently identifies the film from the supplied picture as Residence Alone.
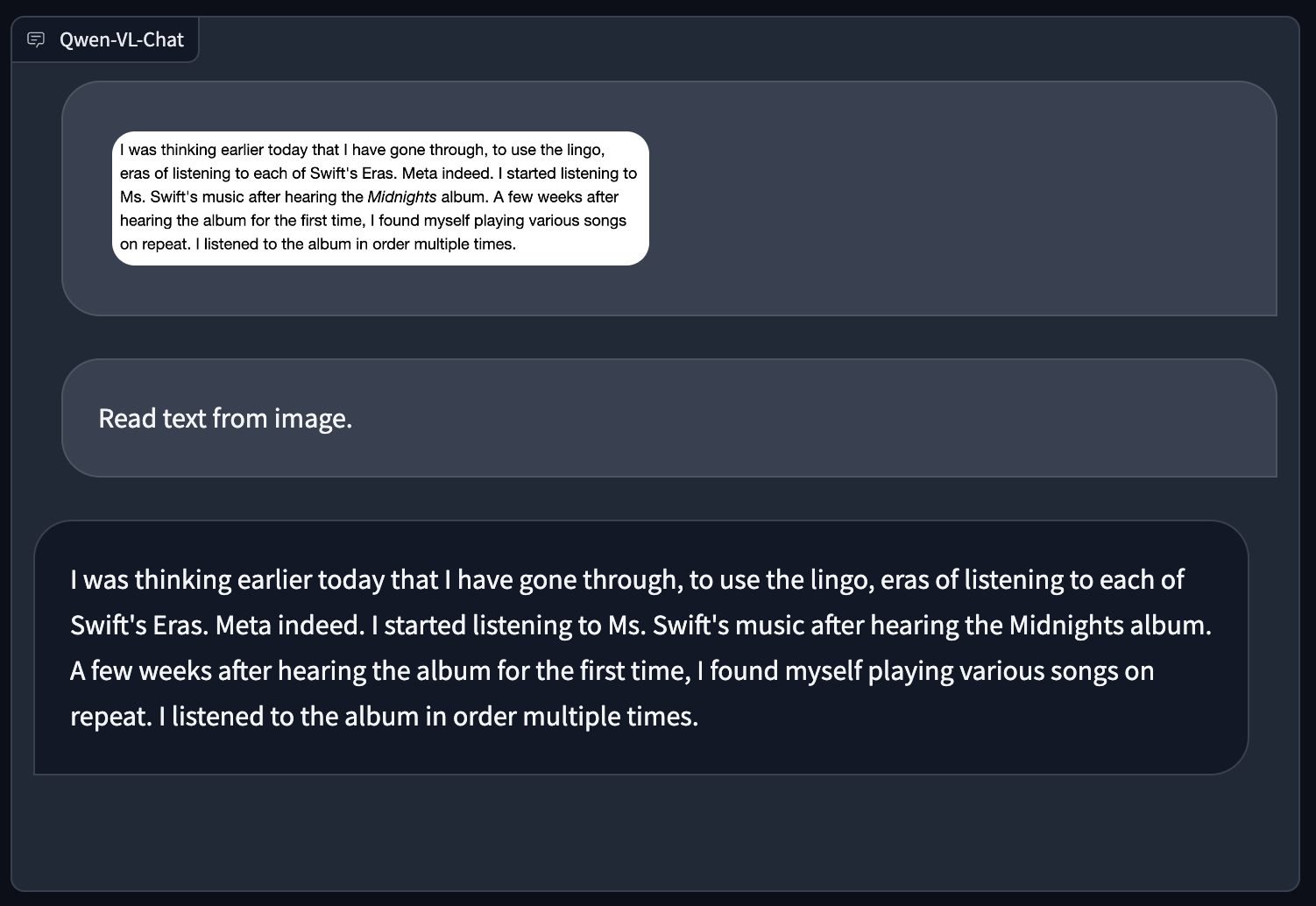
Qwen-VL succeeded with doc OCR, too, during which we requested the mannequin to supply the textual content in a screenshot of an online web page:
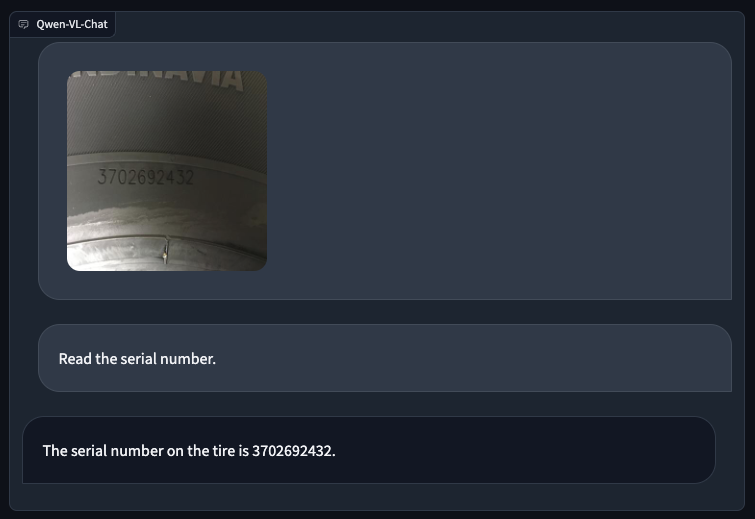
Qwel-VL additionally succeeded in figuring out the serial quantity on a tire:
CogVLM
code | paper | demo
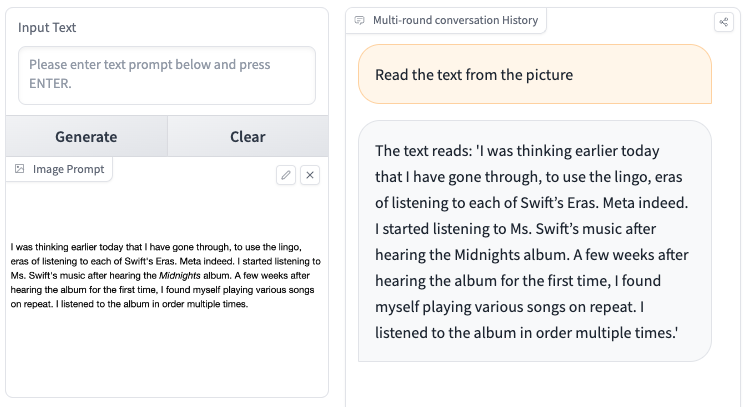
CogVLM can perceive and reply varied kinds of questions and has a visible grounding model. Grounding the flexibility of the mannequin to attach and relate its responses to real-world information and details, in our case objects on the picture.
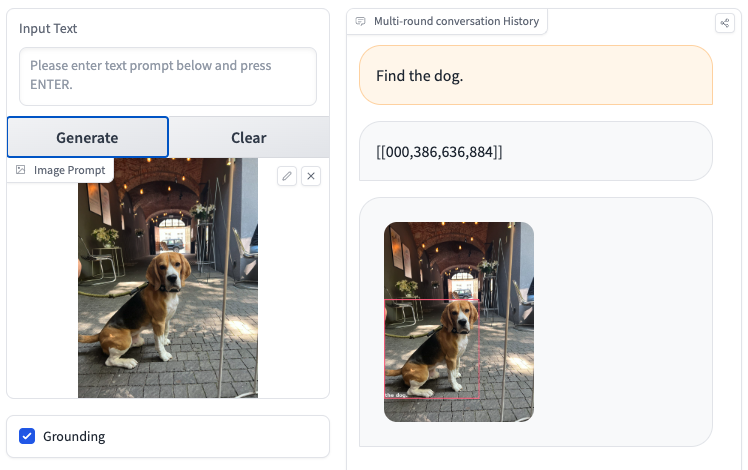
CogVLM can precisely describe photos intimately with only a few hallucinations. The picture beneath exhibits the instruction “Discover the canine”. CogVLM has drawn a bounding field across the canine, and supplied the coordinates to the canine. This exhibits that CogVLM can be utilized for zero-shot object detection, because it returns coordinates of grounded objects. (Notice: Within the demo area we used, CogVLM plotted bounding packing containers for predictions)
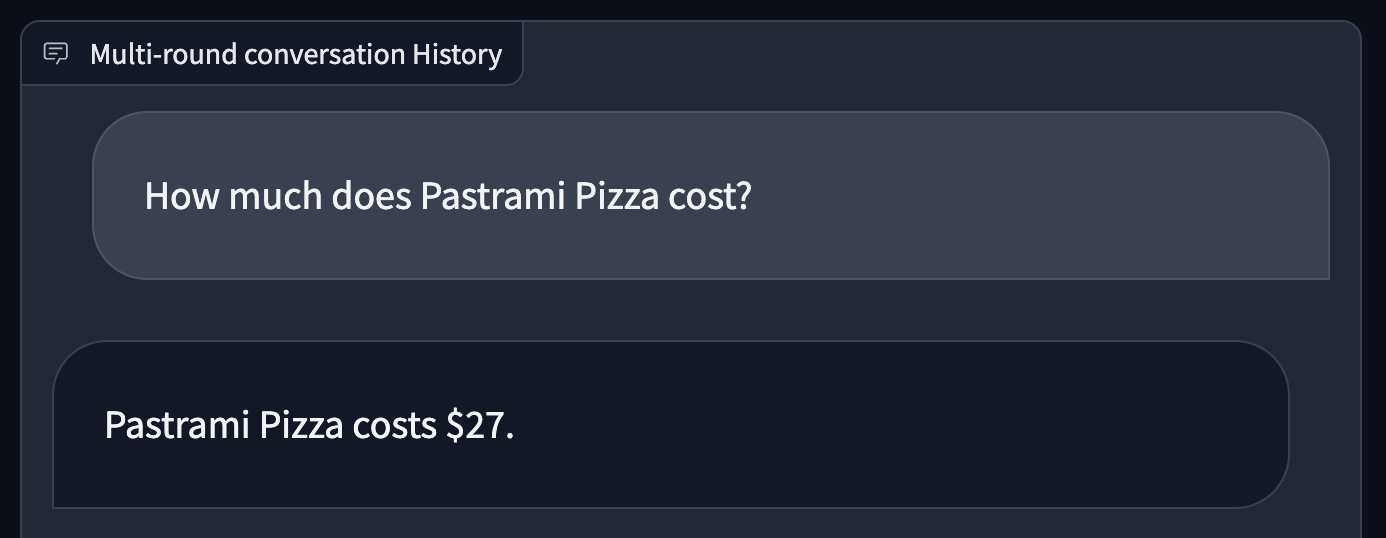
CogVLM, like GPT-Four with Imaginative and prescient, may also reply questions on infographics and paperwork with statistics or structured data. Given a photograph of a pizza, we requested CogVLM to return the worth of a pastrami pizza. The mannequin returned the proper response:

LLaVA
code | paper | demo
Giant Language and Imaginative and prescient Assistant (LLaVA) is a Giant Multimodal Mannequin (LMM) developed by Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. On the time of writing this text, the newest model of LLaVA is model 1.5.
LLaVA 1.5 is arguably the most well-liked different to GPT-4V. LLaVA is especially utilized in VQA. You may ask LLaVA questions on photos and retrieve solutions. With that stated, the Roboflow workforce has discovered some capabilities in zero-shot object detection and Object Character Recognition (OCR).
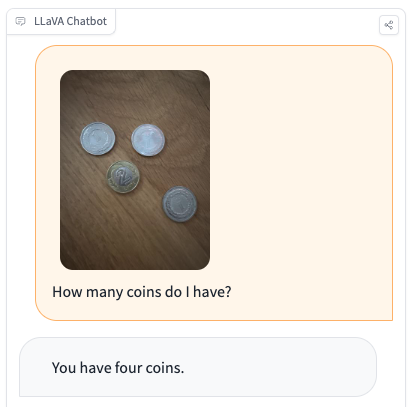
In all however considered one of our checks (the coin instance above), LLaVA did not return the proper response to a query.
BakLLaVA
code
BakLLaVA is a LMM developed by LAION, Ontocord, and Skunkworks AI. BakLLaVA makes use of a Mistral 7B base augmented with the LLaVA 1.5 structure. Utilized in mixture with llama.cpp, a instrument for working the LLaMA mannequin in C++, you need to use BakLLaVA on a laptop computer, supplied you could have sufficient GPU sources obtainable.
BakLLaVA is a sooner and fewer resource-intensive different to GPT-Four with Imaginative and prescient. Nevertheless, with out fine-tuning LLaVA extra typically returns incorrect outcomes. In all however considered one of our checks, BakLLaVA did not return the proper response.
Positive-Tuned Laptop Imaginative and prescient Fashions
Positive-tuned fashions are educated to establish a restricted set of objects. For instance, you could prepare a fine-tuned mannequin to establish particular product skus to be used in a retail retailer software, or prepare a mannequin to establish forklifts to be used in a security assurance instrument.
To construct a fine-tuned mannequin, you want a group of labeled photos. These photos needs to be consultant of the surroundings during which your mannequin is deployed. Every label ought to level to an object of curiosity (i.e. a product, a defect). This data is then used to coach a mannequin to establish all the courses you added as labels to your dataset.
Positive-tuned fashions, corresponding to fashions educated utilizing the YOLOv8 or ViT architectures, can run in near actual time. For instance, you may join a YOLOv8 mannequin to the output of a digital camera that displays a building yard to search for when forklifts get too near an individual.
Coaching a fine-tuned mannequin takes time since you should collect and label information. That is in distinction to LMMs, which work out of the field with none fine-tuned coaching. With that stated, the requirement to collect and label information is a blessing in disguise: as a result of you recognize what goes in your mannequin, you’ll be able to debug what goes flawed.
For instance, in case your mannequin struggles to establish a category, you’ll be able to tweak your mannequin till it performs nicely. LMMs, in distinction, are a lot tougher to grasp; fine-tuning an LMM is prohibitively costly for many, and technically difficult.
The Way forward for Multimodality
GPT-Four with Imaginative and prescient introduced multimodal language fashions to a big viewers. With the discharge of GPT-Four with Imaginative and prescient within the GPT-Four net interface, individuals the world over may add photos and ask questions on them. With that stated, GPT-Four with Imaginative and prescient is just one of many multimodal fashions obtainable.
Multimodality is an lively subject of analysis, with new fashions launched frequently. Certainly, all the fashions listed above had been launched in 2023. Multimodal fashions like GPT-Four with Imaginative and prescient, LLaVA, and Qwen-VL exhibit capabilities to unravel a variety of imaginative and prescient issues, from OCR to VQA.
On this information, we walked by two fundamental options to GPT-Four with Imaginative and prescient:
- Utilizing a fine-tuned mannequin, supreme if you should establish the situation of objects in photos.
- Utilizing one other LMM corresponding to LLaVA, BakLLaVA, Qwen-VL, or CogVLM, which are perfect for duties corresponding to VQA.
With the tempo that multimodal fashions are being developed, we are able to anticipate many extra to be educated and launched over the approaching years.


