
Introduction
2024 is the yr of Generative AI with the likes of Claude Three in textual content era, Devin AI with software program engineering, and even taking strides in picture era with Steady Diffusion 3. It’s been over a month since Steady Diffusion, so allow us to discover what Stability AI’s new cutting-edge mannequin has to supply!
What’s Steady Diffusion?
Steady Diffusion is the brainchild of Stability AI, an open AI model primarily based in the UK. It’s a group of open-source fashions used to generate pictures. Mostly used as text-to-image era, it additionally serves image-to-image and performs inpainting and outpainting. Steady Diffusion has many variations previous to the most recent Steady Diffusion 3. Allow us to take a look at them briefly.
- Steady Diffusion 1.5, or SD1.5, is the oldest model, launched in August 2022. Being an outdated mannequin, it outputs a picture dimension of 512 x 512. Though it’s an outdated mannequin, it requires much less reminiscence and is therefore sooner.
- Then there may be Steady Difussion 2.1 or SD2.1, launched in October 2022. It had enhancements like adverse prompts, a textual content encoder—OpenCLIP, and enormous picture outputs.
- Steady Diffusion, or SDXL, is one other mannequin launched in July 2023. It is vitally common and may create reasonable pictures in any side ratio.
- SDXL Turbo is an excellent model of SDXL launched in November 2023. It may well produce nice pictures in a single immediate and serves as a non-commercial mannequin, establishing itself as essentially the most superior open-source picture generator.
- Lastly, there was SD Turbo, which was additionally launched in November 2023 and was additionally a non-commercial mannequin.
Steady Diffusion 3
Steady Diffusion 3, or SD 3, is the most recent picture era mannequin from Stability AI. They spotlight enhancements like higher photo-realistic picture era, adherence to robust prompts, and multimodal enter.

Promt “Tokyo, Shinjuku”
SD Three constitutes a set of fashions of small sizes, from 800 million parameters to eight billion parameters. This provides a variety of scalability and high quality to satisfy the inventive wants of the customers. Stability AI has given big choice to security proper from when the mannequin begins coaching, testing, and analysis up till last deployment.
What’s new in Steady Diffusion 3?
As seen earlier, SD Three had many predecessor fashions. However what new does it carry to the desk? Allow us to discover a few of them.
Efficiency
Steady Diffusion Three can generate a 1024×1024 picture with 50 steps in lower than 35 seconds on an Nvidia RTX 4090 GPU with 24GB vRAM. For the reason that mannequin is large, it requires extra GPU compute for sooner picture era.
Sampling
Stability AI has given quite a lot of thought to implementing efficient sampling to make it sooner and higher high quality. They found a noise schedule that sampled the center a part of the trail and produced higher-quality pictures. The Steady Diffusion Three mannequin depends on Rectified Circulation Sampling, which is the quickest method to go from a loud to a transparent picture—in the intervening time!
Higher Textual content Era
One of many big pluses of Steady Diffusion Three is that it may well generate legible, lengthy texts in pictures, in contrast to its predecessors, which can’t generate legible texts or usually are not good. SD3 mannequin provides significantly better textual content rendering total.
Textual content Encoder
Steady Difussion Three has Three encoders, in contrast to its predecessors, which had fewer. They’re as follows:
- CLIP l/14
- OpenCLIP bigG/14 and
- T5-v1.1 XXL
Safer
With the probabilities of producing inappropriate pictures, Stability AI is taking the safer route by utterly eradicating the era of NSFW pictures on their newest mannequin, Steady Diffusion.
Noise Predictor
Noise Predictor estimates the quantity of noise within the latent house and subtracts the from the picture. This course of is repeated for a selected variety of instances, decreasing noise in response to user-specific steps. Older Steady Diffusion fashions like Steady Diffusion 1 and a pair of use the U-Internet Noise predictor structure. Then again, Steady Diffusion Three makes use of a repeating stack of Diffusion Transformers that means it makes use of a number of transformers for the diffusion course of when in comparison with earlier SD fashions.
How does Steady Diffusion Three carry out towards different fashions?
Crucial query arises in everybody’s thoughts: How does Steady Diffusion Three stack up towards different text-to-image era fashions like Midjourney or DALL-E 3??
Nicely, to place it into perspective, Steady Diffusion Three performs superiorly to all the above!
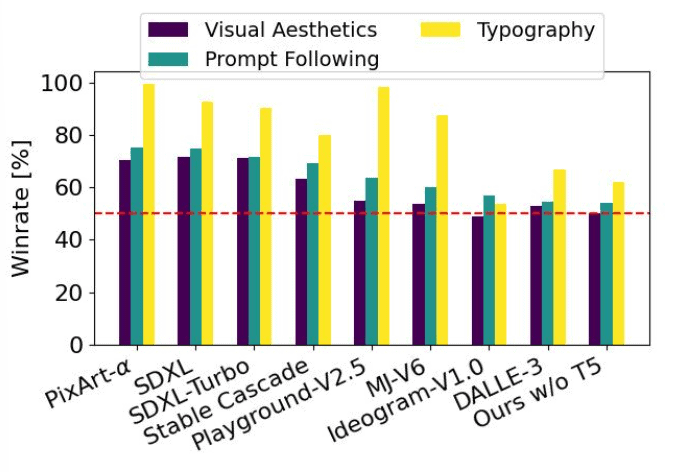
Mannequin Comparability
As seen from the above visualization, Stability AI has carried out efficiency evaluations on SD3 with completely different fashions, together with predecessors like SDXL, SDXL Turbo, and Steady Cascade, and rivals like Midjourney v6 and DALLE-3, with precise human evaluators. The evaluations have been made primarily based on how nicely the fashions output the leads to the context of the given prompts and the way aesthetically pleasing the generated pictures have been. Steady Diffusion Three marginally outperforms present state-of-the-art text-to-image era programs in all the above areas. Stability AI additionally ran unoptimized inference checks on shopper {hardware} for the SD3 mannequin, which has eight billion parameters and suits into the 24GB VRAM of an RTX 4090. Utilizing 50 sampling steps, it took simply 34 seconds to generate a picture with a decision of 1024×1024! That is loopy, proper?
Limitations of Steady Diffusion 3
Though Steady Diffusion Three is a formidable structure and performs significantly better than its predecessors, it nonetheless has a couple of drawbacks.
- One such downside is that SD3 feels extra aligned with particular person creators than enterprises, in contrast to its rivals like Dall-E, which may work for firms.
- Steady Diffusion requires highly effective {hardware} like an NVIDIA RTX 3060 or an RTX 4020 for optimum efficiency and outcomes.
- It will not be appropriate for every type of pictures like noisy pictures or poor distinction pictures.
- It may be computationally demanding and in addition time-consuming particularly with massive visible information.
- This can’t be referred to as a difficulty however reasonably a typical enemy of all picture generative fashions—misuse. This includes making the fashions much less liable to misuse, like wrongful political imagery or fictitious imagery of celebrities. Though Steady DIiffusion Three would probably generate solely SFW pictures, making the fashions much less liable to misuse, it’s nonetheless not utterly free from it!
The way to entry Steady Diffusion 3?
Stability AI is providing Steady Diffusion Three within the early preview stage. This preview mode offers suggestions for analyzing efficiency, security, and different metrics. Go examine Steady DIffusion Three for yourselves right here! When you get entry, you’ll obtain an e-mail invite to the Discord server.
Conclusion
Steady Diffusion has taken picture era up a notch, loaded with new options, and marginally beating its rivals, like MidJourney and DALLE-3, throughout completely different assessments.
Steady Diffusion Three solely scratches the floor of the true potential of picture era and the trajectory of Generative AI. That’s a wrap of this enjoyable learn. See you guys within the subsequent one!
<!–
–>


