Imaginative and prescient Language Fashions (VLMs) bridge the hole between visible and linguistic understanding of AI. They encompass a multimodal structure that learns to affiliate data from picture and textual content modalities.
In easy phrases, a VLM can perceive photographs and textual content collectively and relate them collectively.
Through the use of advances in Transformers and pretraining methods, VLMs unlock the potential of imaginative and prescient language purposes starting from picture search to picture captioning, generative duties, and extra!
This text will discover imaginative and prescient language fashions alongside code examples to assist with implementation. Matters lined embrace:
- VLMs Structure and pretraining methods
- VLMs knowledge and benchmarks
- Purposes, use instances, and the perfect open-source implementations
Let’s begin digging!
How Do Imaginative and prescient Language Fashions Work?
People can effortlessly course of data from a number of sources concurrently; as an illustration, we depend on decoding phrases, physique language, facial expressions, and tone throughout a dialog.
Equally, imaginative and prescient language fashions (VLMs) can course of such multimodal indicators successfully and effectively, enabling machines to grasp and generate picture data that blends visible and textual components.
Fashionable VLM architectures rely totally on transformer-based fashions for picture and textual content processing as a result of they effectively seize long-range dependencies.
On the core of Transformers lies the multi-head consideration mechanism launched by Google’s “Consideration Is All You Want” paper, which is able to turn out to be useful quickly.
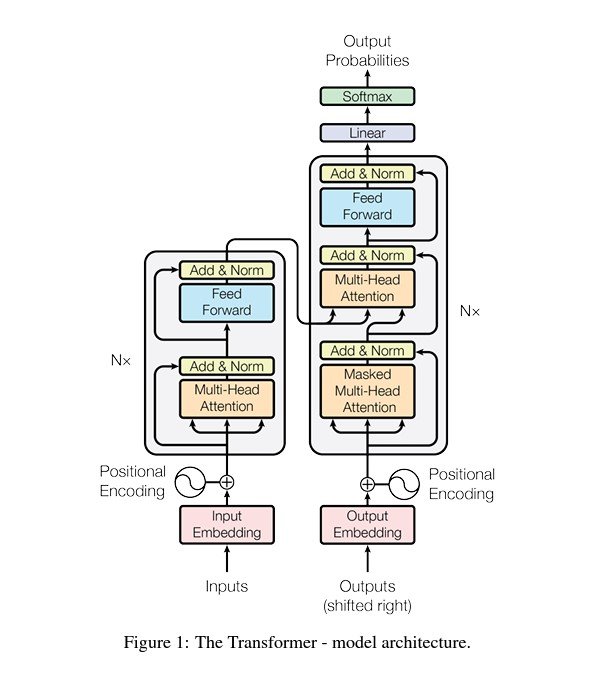
Elements of Imaginative and prescient Language Fashions
To realize this multimodal understanding, VLMs usually consist of three foremost components:
- An Picture Mannequin: Accountable for extracting significant visible data corresponding to options and representations from visible knowledge, i.e., Picture encoder.
- A Textual content Mannequin: Designed to course of and perceive the pure language processing (NLP), i.e., textual content encoder.
- A Fusion Mechanism: A method to mix the representations discovered by the picture and textual content fashions, permitting for cross-modal interactions.
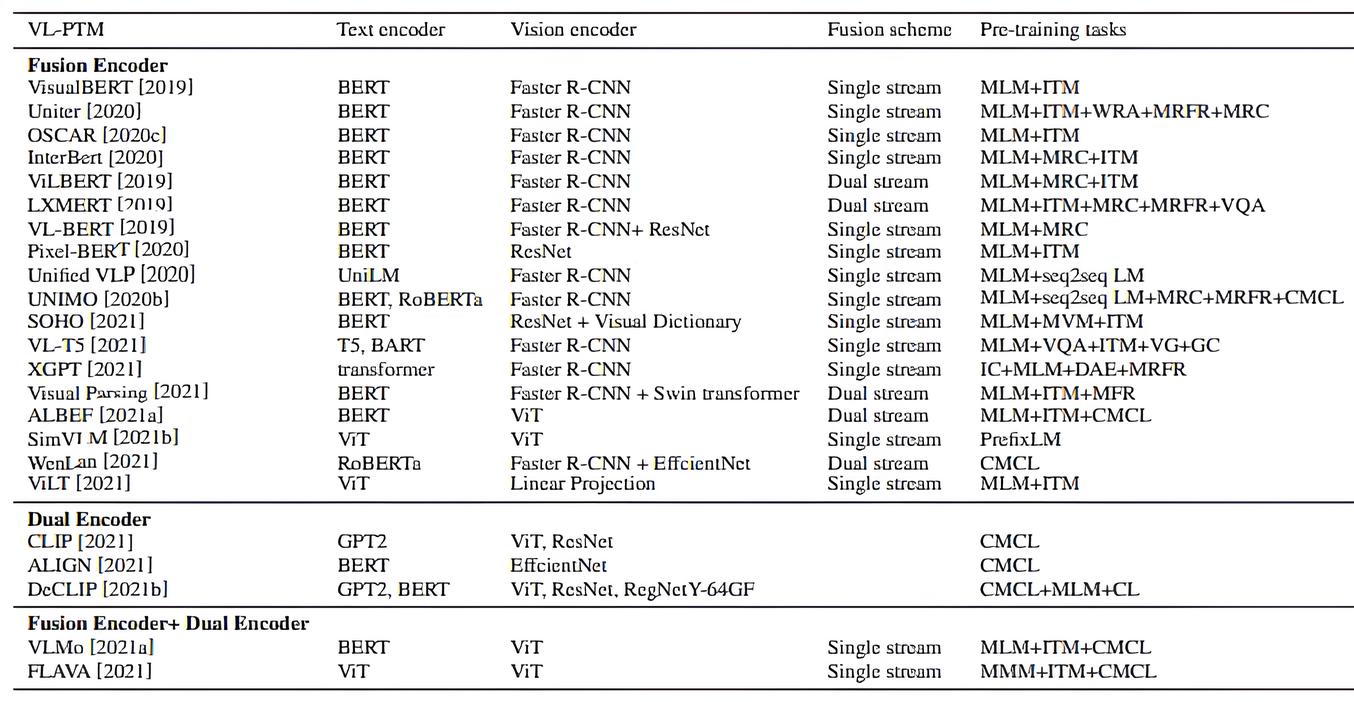
Primarily based on this paper, we are able to group encoders relying on the fusion mechanism to mix representations into three classes: Fusion encoders (which instantly mix picture and textual content embeddings), twin encoders (which course of them individually earlier than interplay), and hybrid strategies that leverage each strengths.
Additionally, based mostly on the identical paper, two foremost kinds of fusion schemes for cross-modal interplay exist: single-stream and dual-stream.
Earlier than digging deeper into particular architectures and pretraining strategies, we should contemplate that the surge of multimodal improvement over the latest years, powered by advances in vision-language pretraining (VLP) strategies, has given rise to varied vision-language purposes.
They broadly fall into three classes:
Nonetheless, this text will solely overview a couple of imaginative and prescient language fashions, specializing in image-text and core pc imaginative and prescient duties.
Open-Supply Imaginative and prescient Language Mannequin Architectures
VLMs usually extract textual content options (e.g., phrase embeddings) and visible options (e.g., picture areas or patches) utilizing a textual content encoder and visible encoder. A multimodal fusion module then combines these unbiased streams, producing cross-modal representations.
A decoder interprets these representations into textual content or different outputs for generation-type duties.
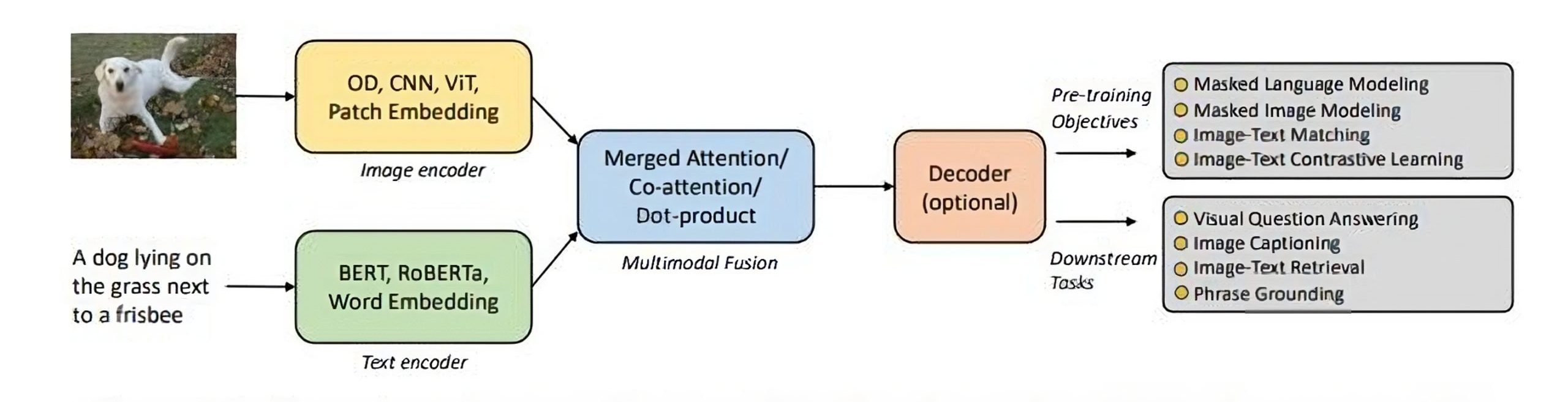
Now, let’s get into a number of particular architectures for transformer-based VLMs.
CLIP (Contrastive Language–Picture Pretraining)
CLIP is an open-source mannequin discovered by OpenAI that depends on transformers’ consideration mechanisms.
The CLIP mannequin includes a twin encoder structure. Fusion of the multimodal representations is achieved by calculating the dot product between international picture and textual content characteristic vectors.
CLIP leverages a modified ResNet-50 for environment friendly picture characteristic extraction. Notably, changing international common pooling with a transformer-style consideration pooling mechanism enhances its capacity to give attention to related picture areas.
It additionally employs a 12-layer, 8-attention heads Transformer with masked self-attention for textual content encoding, permitting potential integration with pre-trained language fashions.
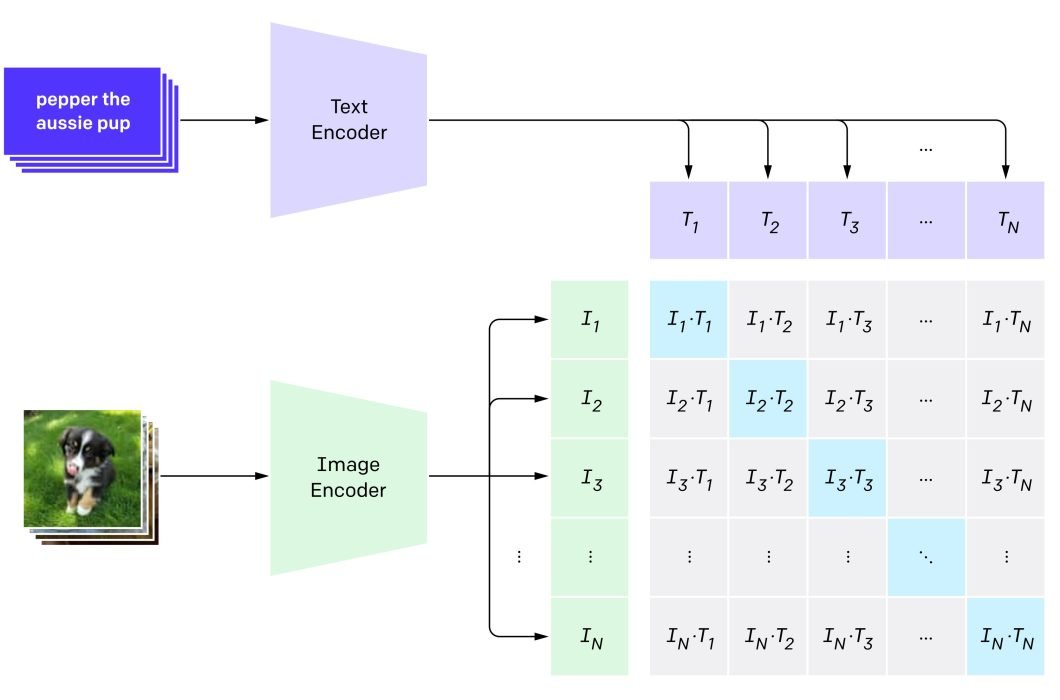
CLIP is pre-trained on a various dataset of image-text pairs. This pretraining empowers CLIP with zero-shot studying capabilities, enabling it to carry out duties with out specific coaching on new class labels. Listed below are a couple of examples:
- Novel Picture Classification
- Picture-Textual content Retrieval
- Visible Query Answering
ViLBERT (Imaginative and prescient-and-Language BERT)
ViLBERT is one other instance of a imaginative and prescient language mannequin that will depend on the eye mechanism. It extends the well-known BERT structure to encompass two parallel BERT-style fashions working over picture areas and textual content segments that work together by means of co-attentional transformer layers.
For multimodal fusion, this mannequin employs a co-attention Transformer structure. This structure dedicates separate Transformers to course of picture area and textual content options, with a further Transformer fusing these representations.
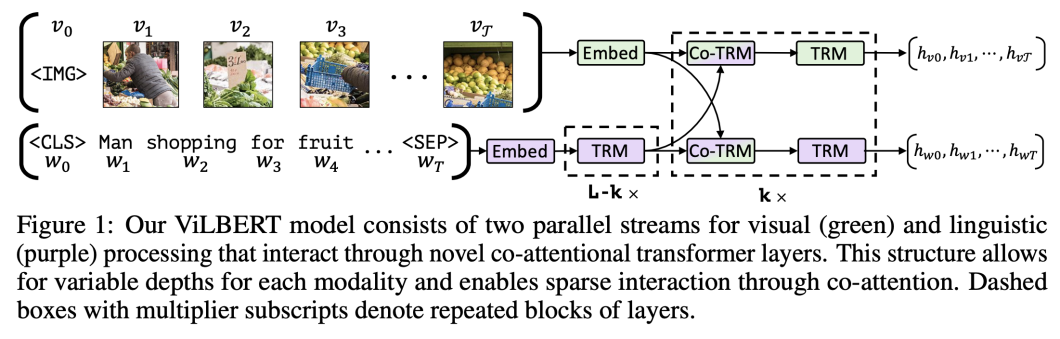
ViLBERT’s joint modeling method makes it well-suited for duties requiring tight alignment between picture areas and textual content segments, corresponding to visible query answering (VQA) and referring expression comprehension.
The primary distinction between the 2 above fashions is the fusion mechanism. CLIP’s dual-encoder structure makes use of dot-product for multimodal fusion, whereas ViLBERT makes use of the co-attention module.
These are prime examples of the perfect open-source imaginative and prescient language fashions, showcasing the ability of various architectures and pretraining methods for multimodal understanding.
Having mentioned the architectures, let’s discover a couple of pre-training methods extensively used within the improvement of VLMs.
Pretraining Methods for Imaginative and prescient Language Fashions
Apart from the architectural decisions we mentioned earlier, vision-language pretraining (VLP) performs a significant function in VLM efficiency.
These methods, usually tailored from text-based pretraining, empower visible language fashions to attain spectacular multi-modal understanding and unlock the potential for a variety of duties corresponding to image-text alignment, zero-shot classification, and visible query answering.
Now, let’s listing a couple of important methods extensively used for VLMs.
Contrastive Studying
Contrastive studying is an unsupervised deep studying method. The aim is to be taught representations by maximizing the similarity between aligned image-text pairs whereas minimizing the similarity between mismatched ones.
Contrastive studying usually serves as a useful pretraining aim for imaginative and prescient fashions, showcasing its versatility in enhancing efficiency throughout varied pc imaginative and prescient and pure language processing duties.
The dataset for the sort of pretraining goal would have image-text pairs; some pairs can be real matches, whereas others can be mismatched.
Within the context of imaginative and prescient language pretraining, contrastive studying, often known as image-text contrastive studying (ITC), was popularized primarily by CLIP and ALIGN to pre-train twin encoders. Twin encoders are pertaining by computing image-to-text and text-to-image similarities by means of a mathematical operation.
Masked-Picture Modeling (MIM) / Masked Language Modeling (MLM)
Masked picture modeling (MIM) is just like Masked Language Modeling (MLM) and has confirmed useful in vision-language structure.
In MIM, 15% of phrases in an image-text pair get masked, and the aim is to foretell them based mostly on the context and the picture.
Researchers have explored varied masked picture modeling (MIM) duties for pretraining, which share similarities with the MLM goal.
In these duties, researchers practice the mannequin to reconstruct the masked patches or areas given the remaining seen patches or areas and all of the phrases.
Current state-of-the-art text-image fashions don’t use MIM throughout pretraining however make use of masked vision-language modeling as an alternative. Fashions like BEiT, iBOT, and others have demonstrated the ability of this method.
Picture-Textual content Matching (ITM)
In Picture-Textual content Matching (ITM), the mannequin receives a batch containing each appropriately matched and mismatched image-caption pairs. Its activity is to tell apart between real and misaligned pairings.
ITM is just like the Subsequent Sentence Prediction (NSP) activity in pure language processing, which requires the mannequin to find out whether or not a picture and a textual content match.
We then feed the mannequin with an equal chance of a matched or mismatched image-caption pair. A classifier is added to find out if a given image-caption pair is matched, which predicts a binary label (matched/mismatched).
The important thing to this activity is representing an image-text pair in a single vector in order that the rating perform may output a chance.
ITM often works greatest alongside Masked-Language Modeling (MLM). Fashions like ViLBERT and UNITER usually incorporate ITM as an auxiliary pre-training activity.
These are just some foundational examples of VLP; for a extra complete research of strategies, learn right here.
That stated, refining current methods and creating novel pretraining strategies can additional improve the capabilities of imaginative and prescient language fashions.
The selection of datasets and benchmarks used throughout pre-training instantly influences mannequin efficiency. Let’s discover the important thing datasets and analysis metrics used within the VLM area.
Datasets and Benchmarks in Imaginative and prescient Language Fashions
Datasets are the inspiration for mannequin improvement all through a imaginative and prescient language mannequin lifecycle, from the preliminary pretraining to the essential phases of finetuning and analysis.
Analysis and benchmarking are simply as important for monitoring progress in VLM improvement. They reveal how successfully completely different fashions leverage the strengths and weaknesses of varied datasets.
Pretraining datasets are often large-scale datasets consisting of image-text pairs. Throughout coaching, every textual content is tokenized as a sequence of tokens, and every picture is remodeled right into a sequence of options.
Some widespread pertaining datasets are:
- COCO (328,124 image-text pairs)
- LAION (400M)
- Conceptual Caption (3.1M)
These datasets are inherently noisy. Thus, VLMs take pre-processing steps to denoise them; ALIGN notably makes use of its personal high-quality dataset.

Nonetheless, this part will give attention to task-specific datasets and benchmarks. The kind of duties we are going to briefly discover embrace:
- Picture-text Retrieval
- Visible Query Answering and Visible Reasoning
- Picture Captioning
- Zero-Shot Classification
Datasets and benchmarks for Picture-Textual content Retrieval
Picture-text retrieval has two sub-tasks: image-to-text retrieval, which retrieves a textual description that may be grounded within the picture question, and text-to-image retrieval, which retrieves a textual description that may be grounded within the picture question.
Common datasets embrace COCO and Flickr30Ok attributable to their giant dimension, various picture content material, and the inclusion of a number of descriptive captions per picture.
For analysis, Recall@Ok (Ok=1, 5,10) is used., Recall@Ok measures the proportion of instances the place the right picture (or textual content) seems inside the prime Ok retrieved outcomes.
Let’s take a look at the benchmarks of imaginative and prescient language fashions on the COCO and Flickr30Ok for Picture-to-Textual content Retrieval utilizing the Recall@1 analysis metric because it exhibits the distinction in accuracy essentially the most:
| MS COCO | Flickr30Ok | ||
|---|---|---|---|
| Mannequin | Recall@1 Rating | Mannequin | Recall@1 Rating |
| BLIP-2 ViT-G (fine-tuned) |
85.4 | InternVL-G-FT (finetuned, w/o rating) |
97.9 |
| ONE-PEACE (w/o rating) |
84.1 | BLIP-2 ViT-G (zero-shot, 1K take a look at set) |
97.6 |
| BLIP-2 ViT-L (fine-tuned) |
83.5 | ONE-PEACE (finetuned, w/o rating) |
97.6 |
| IAIS | 67.78 | InternVL-C-FT (finetuned, w/o rating) |
97.2 |
| FLAVA (zero-shot) |
42.74 | BLIP-2 ViT-L (zero-shot, 1K take a look at set) |
96.9 |
Desk: Benchmarks of imaginative and prescient language fashions on the COCO and Flickr30Ok – Source1. Source2.
Datasets and benchmarks for Visible Query Answering and Visible Reasoning
Visible Query Answering (VQA) requires the mannequin to reply a query appropriately based mostly on a given question-image pair.
The query may be both open-ended, with a free-form reply, or multiple-choice, with a set of reply decisions offered. Nonetheless, for simplification functions, most research deal with each kinds of questions in VQA as a classification downside.
Equally, visible reasoning goals to guage the precise reasoning capabilities of a imaginative and prescient language mannequin. In most research, researchers formulate visible reasoning duties as VQA.
The unique VQA dataset is essentially the most used, and its variations are designed as completely different diagnostic datasets to carry out a stress take a look at for VQA fashions. For instance, VQAv2, the second model of the VQA dataset, is the present benchmark for VQA duties.
Fashions utilizing datasets derived from the VQA dataset are evaluated utilizing the VQA rating. Accuracy is the usual analysis metric for different VLM benchmarks.
Let’s check out the highest 5 benchmarks for vision-language fashions on the visible question-answering activity utilizing the VQAv2 dataset:
Observe: These benchmarks are test-std scores, which precisely measure mannequin efficiency.
| Mannequin | Total Rating |
|---|---|
| BEiT-3 | 84.03 |
| mPLUG-Large | 83.62 |
| ONE-PEACE | 82.52 |
| X2-VLM (giant) |
81.8 |
| VLMo | 81.30 |
Desk: High 5 benchmarks for VLMs on VQA activity – Supply.
Datasets and benchmarks for Picture Captioning
Picture captioning is the intersection between pc imaginative and prescient and pure language processing. It’s the activity of describing a visible picture in a free-form textual caption.
Two proposed captions for Picture-captioning are single-sentence and multi-sentence descriptive paragraph captions.
Common datasets, together with COCO, TextCaps, and VizWiz-Captions, are often designed for single-sentence captions.
There have been fewer efforts in constructing datasets with extra descriptive, multi-sentence captions.
Captioning efficiency is often evaluated utilizing normal textual content technology metrics based mostly on n-gram overlap or semantic content material matching metrics. Probably the most used analysis metrics embrace BLEU-4, CIDER, METEOR, and SPICE.
Here’s a take a look at the benchmarks of the highest 5 fashions on the COCO Captions dataset utilizing the BLEU-Four analysis metric:
| Mannequin | Total Rating |
|---|---|
| mPLUG | 46.5 |
| OFA | 44.9 |
| GIT | 44.1 |
| BLIP-2 ViT-G OPT 2.7B (zero-shot) |
43.7 |
| LEMON | 42.6 |
Supply.
Datasets and benchmarks for Zero-Shot Recognition
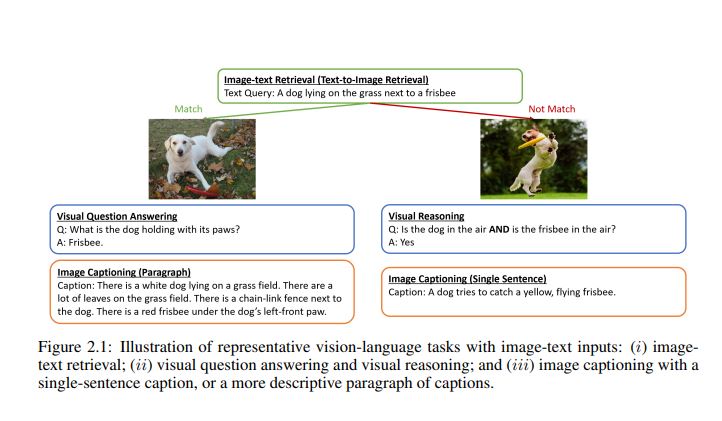
The duties we’ve talked about to this point are thought of image-text duties that want an image-text pair, as proven within the determine beneath:
Zero-shot recognition is barely completely different than Picture-Textual content duties; CLIP-like vision-language basis fashions have enabled open vocabulary visible recognition by mapping photographs with their corresponding language descriptions.
Early strategies reveal its effectiveness on picture classification duties. For instance, CLIP can obtain zero-shot accuracy on 27 picture classification datasets. Given its potential, language-driven visible recognition duties lengthen to object detection and semantic segmentation capabilities.
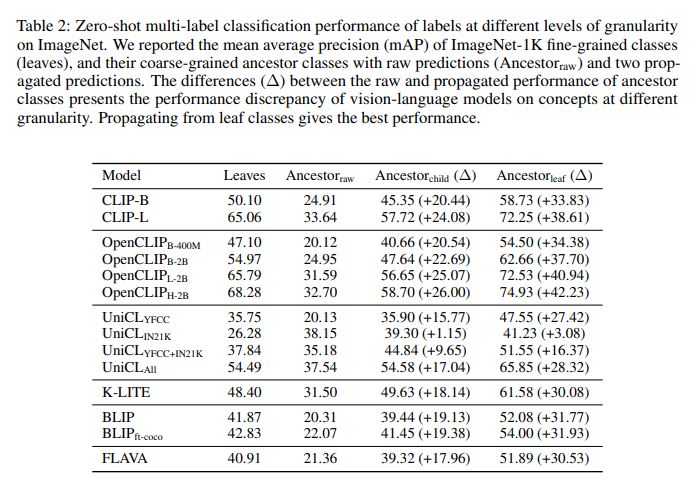
A number of analysis metrics exist based mostly on the granularity consistency, though on this article, we are going to take a look at this paper and see their analysis for contrastive studying fashions on ImageNet:
With that, we conclude the datasets and benchmarks part, wherein we explored a number of duties, datasets, and ideas.
Subsequent, we are going to contemplate use instances and open-source implementations for imaginative and prescient language fashions that resolve real-world issues.
Use Circumstances and Implementations of Imaginative and prescient Language Fashions
We’ve explored the various duties VLMs allow and their distinctive architectural strengths. Let’s now delve into real-world purposes of those highly effective fashions:
- Picture Search and Retrieval: VLMs energy fine-grained picture searches utilizing pure language queries, altering how we discover related imagery on-line and even in non-relational database retrieval.
- Visible Help for the Impaired: Fashions can generate detailed picture descriptions or reply questions on visible content material, aiding visually impaired people.
- Enhanced Product Discovery: VLMs allow customers to seek for merchandise utilizing photographs or detailed descriptions, streamlining the procuring expertise and boosting e-commerce web sites.
- Automated Content material Moderation: Detecting inappropriate or dangerous content material inside photographs and movies usually leverages VLM capabilities.
- Robotics: Integrating VLMs can enable robots to grasp visible directions or describe their environment, enabling extra advanced object interactions and collaboration.
Let’s transfer from idea to follow and discover how code brings these purposes to life. We’ll begin with an instance demonstrating Picture captioning utilizing BLIP:
BLIP Picture-Captioning Base Implementation
BLIP is on the market with the Transformers library and might run on CPU or GPU. Let’s check out the code and an inference instance:
For the Imports, we’re going to want the next:
from PIL import Picture from transformers import BlipProcessor, BlipForConditionalGeneration
Then, we must always load the fashions and put together the photographs as follows:
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
mannequin = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base").to("cuda")
img_url = 'Path/to/your/Picture' raw_image = Picture.open(img_url).convert('RGB')
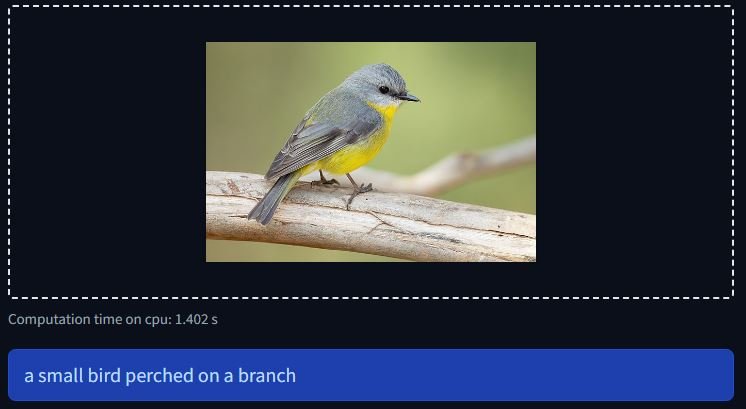
Lastly, we are able to generate a caption for our enter picture:
inputs = processor(raw_image, return_tensors="pt").to("cuda")
out = mannequin.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
Here’s what the outcomes would appear to be:
ViLT VQA Base Implementation
Imaginative and prescient-and-Language Transformer (ViLT) mannequin fine-tuned on VQAv2 based mostly on ViT. Out there with the Transformers library with Pytorch, right here is an instance code and inference:
Importing the wanted libraries:
from transformers import ViltProcessor, ViltForQuestionAnswering from PIL import Picture
Loading fashions, getting ready enter picture and query:
url = "/path/to/your/picture"
picture = Picture.open(url)
textual content = "What number of cats are there?"
processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
mannequin = ViltForQuestionAnswering.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
Encoding and inference:
encoding = processor(picture, textual content, return_tensors="pt")
# ahead go
outputs = mannequin(**encoding)
logits = outputs.logits
idx = logits.argmax(-1).merchandise()
print("Predicted reply:", mannequin.config.id2label[idx])
Right here is an instance inference:
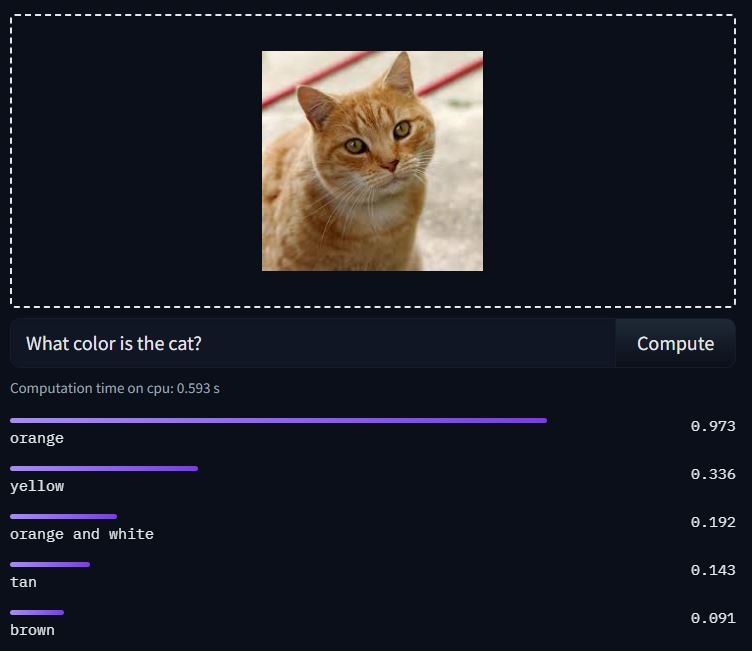
Observe: To make use of any mannequin from the Transformers library, be sure that to put in it with (pip)
Conclusion and Way forward for Imaginative and prescient Language Fashions
The intersection of visible enter and language understanding is a fertile floor for innovation.
As coaching knowledge expands and fashions evolve, we are able to anticipate the advance of vision-language duties from image-based search to assistive applied sciences, shaping the way forward for how we work together with the world.
They’ve the potential to rework industries, empower people, and unlock new methods of interacting with the world round us; multimodal AI can also be the best way to make general-purpose robots!



