Carry this venture to life
Introduction
YOLO is a cutting-edge object detection algorithm, and as a consequence of its processing energy – it has grow to be virtually a normal manner of detecting objects within the discipline of laptop imaginative and prescient. Earlier, folks used strategies like sliding home windows, RCNN, quick RCNN, and sooner RCNN for object detection.
However in 2015, YOLO (You Solely Look As soon as) was invented, and this algorithm and its successors started outperforming all others.
On this article, we current the most recent iteration of the famend real-time object detection and picture segmentation mannequin, Ultralytics’ YOLOv8. This model harnesses the newest developments in deep studying and laptop imaginative and prescient, delivering distinctive pace and accuracy. Its environment friendly design caters to a variety of purposes and may be seamlessly adjusted to numerous {hardware} platforms, spanning from edge units to cloud APIs, because of its implementation within the simple to make use of Ultralytics Python package deal.
YOLO is a state-of-the-art (SOTA) object detection algorithm, and it’s so quick that it has grow to be one of many normal methods of detecting objects within the discipline of laptop imaginative and prescient. Beforehand, sliding window operations had been most typical in object detection. Then got here enhancements and sooner variations of object detection had been launched equivalent to CNN, R-CNN, Quick RCNN and lots of extra.
By means of this text we are going to discover a complete information to know a couple of ideas behind this wonderful mannequin for object detection. We are going to dive deep into the options and perceive the developments of YOLOv8, how you can implement it in a customized dataset seamlessly utilizing the platform supplied by Paperspace, and attempt to perceive the evolution of YOLO and the challenges and limitations growing the earlier YOLO variations.
Temporary overview of object detection in laptop imaginative and prescient
Object detection may be considered the union of two laptop imaginative and prescient sub-disciplines: object localization and picture classification. It entails recognizing particular courses of objects (like people, animals, or automobiles). Its main purpose is to create computational strategies and fashions that reply a elementary query in laptop imaginative and prescient: the identification and placement of objects. Object detection algorithms may be divided into two most important classes: single-shot detectors and two-stage detectors.
This classification relies on the variety of instances the identical enter picture is handed by a community.
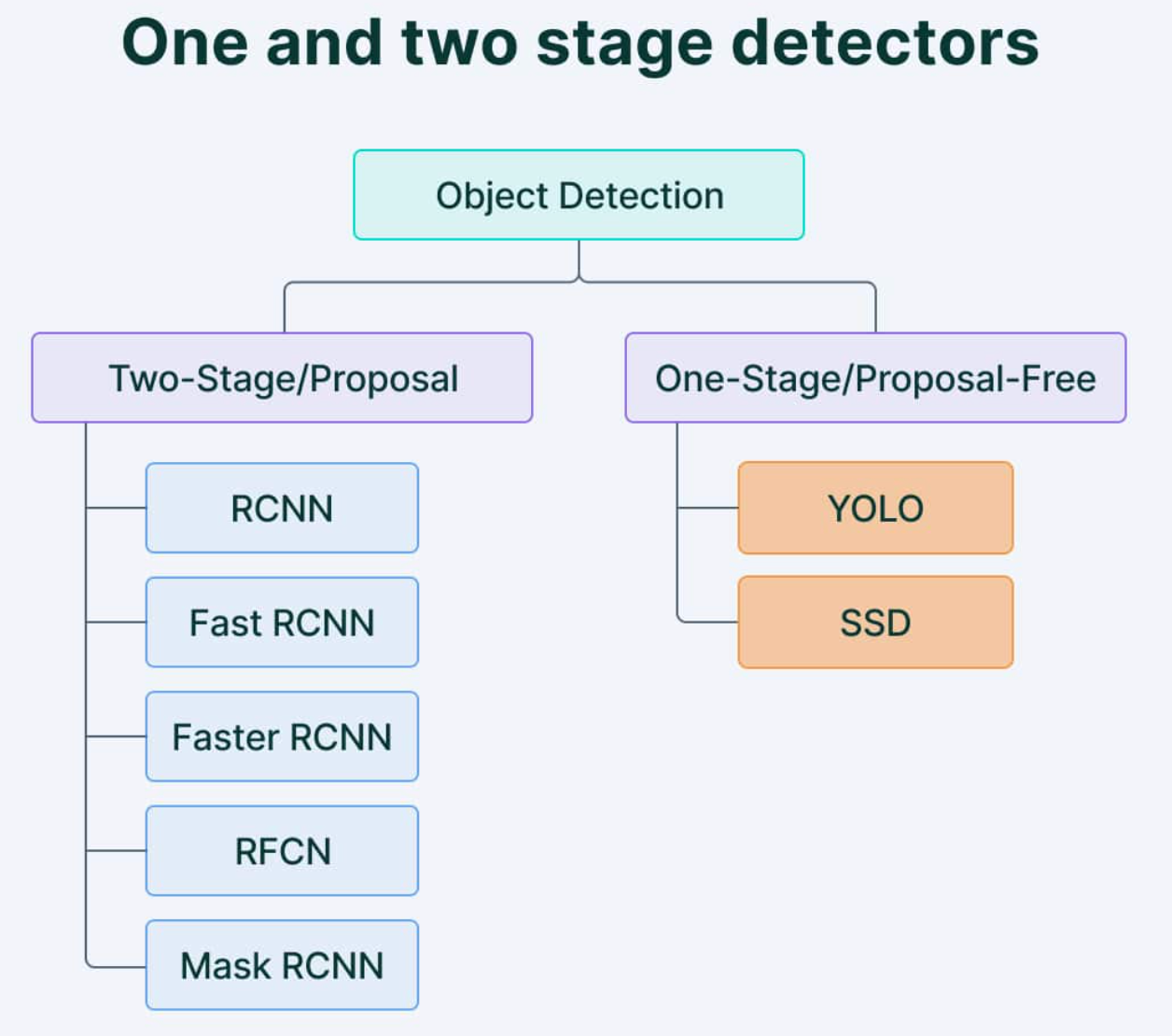
Picture from V7labs
The important thing analysis metrics for object detection are accuracy, encompassing classification and localization precision, and swiftness. Object detection serves as a base for a lot of different laptop imaginative and prescient duties, equivalent to segmentation, picture captioning, object monitoring and extra. Object detection is broadly utilized in many real-world purposes, equivalent to autonomous driving, robotic imaginative and prescient, video surveillance, and so forth. One of many current examples is the article detection system in Tesla automobiles, which is designed to determine different automobiles, pedestrians, animals, street indicators, lane markers, and any obstacles that the automobile could encounter on the street.
Within the under picture, we will assessment the historical past of object detection and the way far this expertise has advanced from conventional object detection to deep studying primarily based detection.
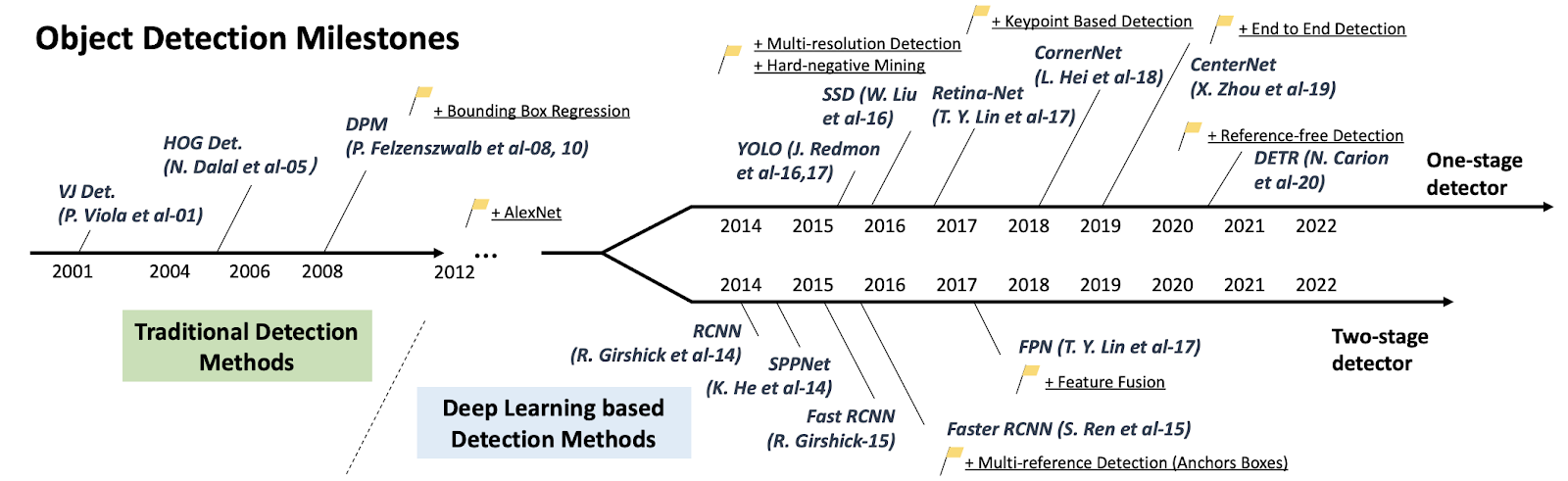
A street map of object detection. Milestone detectors on this determine: VJ Det., HOG Det., DPM, RCNN, SPPNet, Quick RCNN, Sooner RCNN, YOLO, SSD, FPN, Retina-Internet, CornerNet, CenterNet, DETR.
Introduction to YOLO (You Solely Look As soon as) and its significance
YOLO was proposed by R. Joseph (PJ Reddie) within the 12 months 2015. The pace of YOLO was exceptionally excessive in comparison with different object detection choices on the time; a faster iteration achieves 155 frames per second and maintains a VOC07, Imply common precision (mAP) of 52.7%. In distinction, an upgraded model operates at a pace of 45 frames per second whereas reaching the next VOC07 mAP of 63.4%.
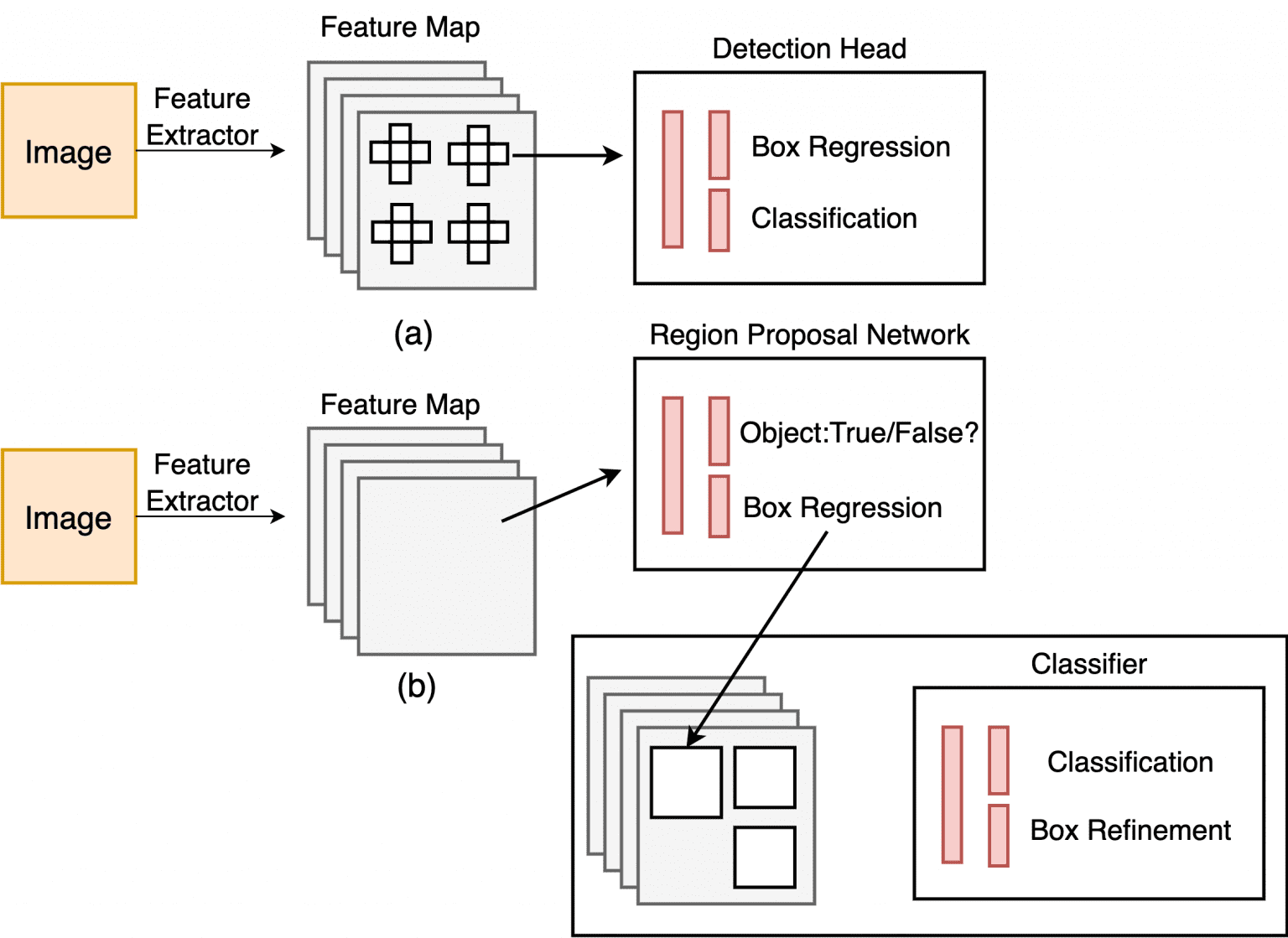
The YOLO method diverges considerably from two-stage detectors by using a single neural community on all the picture. This community segments the picture into areas and predicts bounding containers and chances for every area concurrently. This ends in an elevated pace throughout the detection course of. Regardless of its vital enhancement in detection pace, YOLO experiences a lower in localization accuracy when in comparison with two-stage detectors, notably in detecting small objects. YOLO’s subsequent variations have paid extra consideration to this downside.
Single-shot object detection
Single-shot object detection swiftly analyzes complete photographs in a single go for figuring out objects, however tends to be much less correct than different strategies and would possibly wrestle with detecting smaller objects. Regardless of this, it is computationally environment friendly and appropriate for real-time detection in resource-limited settings. YOLO, a single-shot detector, employs a completely convolutional neural community for picture processing.
Two-shot object detection
Whereas in two-shot or two stage object detection entails using two rounds of the enter picture to forecast the existence and positioning of objects. The preliminary spherical generates a sequence of proposals or potential object areas, whereas the following spherical enhances these proposals to make conclusive predictions. Whereas extra exact than single-shot object detection, this methodology additionally incurs better computational expense.
Functions on numerous domains
YOLO (You Solely Look As soon as) has discovered numerous purposes throughout totally different domains as a consequence of its real-time object detection capabilities. A few of its purposes embrace:
- Surveillance and Safety: YOLO is used for real-time monitoring in surveillance programs, figuring out and monitoring objects or people in video streams
- Autonomous Automobiles: It is employed in self-driving automobiles and autonomous programs to detect pedestrians, automobiles, and objects on roads, aiding in navigation and collision avoidance
- Retail: YOLO can be utilized for stock administration, monitoring inventory ranges, and even for purposes like sensible retail cabinets or cashier-less shops
- Healthcare: It has potential in medical imaging for the detection and evaluation of anomalies or particular objects in medical scans
- Augmented Actuality (AR) and Digital Actuality (VR): YOLO can help in AR purposes for recognizing and monitoring objects or scenes in actual time
- Robotics: YOLO is used for object recognition and localization in robotics, enabling robots to understand and work together with their surroundings extra successfully
- Environmental Monitoring: It may be utilized in analyzing satellite tv for pc photographs or drone footage for environmental research, like monitoring wildlife or assessing land use
- Industrial Automation: YOLO can help in high quality management processes by figuring out defects or anomalies in manufacturing traces
The flexibility of YOLO to carry out real-time object detection with fairly good accuracy makes it versatile for a variety of purposes that require swift and correct object recognition.
How does YOLO work?
Allow us to assume we’re engaged on a picture classification downside and we wish to perceive if the given picture is of an individual or of a canine, in that case the output of a neural community is straightforward. It’s going to output 1 if a canine is current or Zero if there are not any canine current within the picture.

After we discuss object localization, the issue isn’t solely the category, however the place the article is current within the picture. That is finished by drawing a bounding field or figuring out the place of the picture inside the picture.

Briefly, the YOLO mannequin is skilled on labeled datasets, optimizing the mannequin parameters to attenuate the distinction between predicted bounding containers and floor fact bounding containers. With the assistance of bounding field coordinates and the category likelihood we not not solely have the detected object, we even have the reply to object localization.
Now let’s get right into a bit extra element, and break down what we simply described.
The YOLO algorithm takes a picture an enter and is handed to deep Convolutional Neural Community and this neural community generates an output within the type of a vector that seems much like this [Pc, bx, by, bw, bh, c1, c2, c3]. For comfort allow us to denote this vector by n.
- Computer is the likelihood of the category which exhibits if an object is current or not
- bx, by, bw, bh specifies the coordinates of the bounding field from the middle level of the article
- c1, c2, c3 represents the courses that are current within the picture. For instance c1=1 if it’s a canine and relaxation can be 0. Equally, if c2 represents human c2 can be equal to 1 and remainder of the courses can be 0. if there is no such thing as a object current within the picture, the vector can be [0,?,?,?,…?]. On this case, the Computer can be Zero and the remainder of the weather within the vector is not going to matter
- That is fed to the neural community. Right here we’ve supplied one instance, however in the true world an enormous variety of photographs are supplied because the coaching set. These photographs are transformed into vectors for every corresponding picture. Since it is a supervised downside, the X_train, y_train would be the photographs and the vectors comparable to the picture and the community will once more output a vector
This method works for a single object in a picture, but when there are a number of objects in a single picture. It is going to be tough to find out the dimension output of the neural community.

So, on this case the place there are a number of objects with a number of bounding containers in a single picture. YOLO will divide the picture into S x S grid cells.
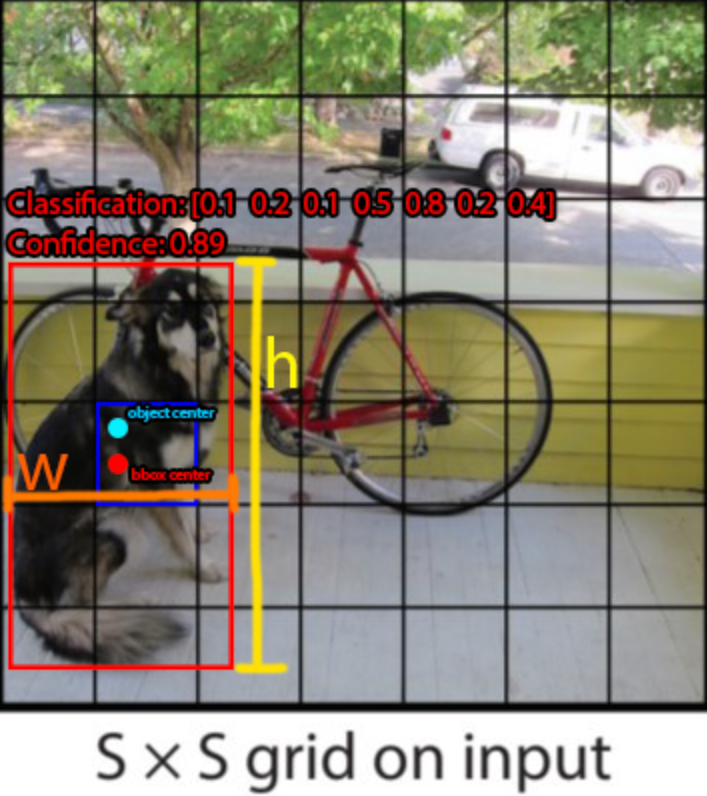
Right here, each particular person part of the grid is tasked with each predicting and pinpointing the article’s class whereas offering a likelihood worth. These are known as Residual blocks.
The subsequent step is to search out the Bounding field of the objects within the picture. These bounding containers corresponding to every object are the vectors which find the article as we mentioned earlier. The attributes of the vector are n=[Pc, bx,by,bw,bh,c1,c2,c3]. YOLO will generate many of those bounding containers for every potential object within the picture, and later filter these right down to these with the very best prediction accuracy.
Which means for one picture we are going to get S x S x n. It is because we’ve an S x S grid of cells, and every cell is a vector of dimension n. So now, with the picture we’ve the corresponding bounding field or rectangles that we will use because the coaching knowledge set. Utilizing this now we will prepare our neural community and generate predictions. That is the premise of the YOLO algorithm. The identify YOLO or ‘You Solely Look As soon as’ is as a result of the algorithm isn’t iterating over one picture.
Even with this technique, sure changes are crucial to boost the accuracy of predictions. One subject that always comes up is the detection of a number of bounding containers or rectangles for one given object. Out of all of the bounding containers just one is the related one.
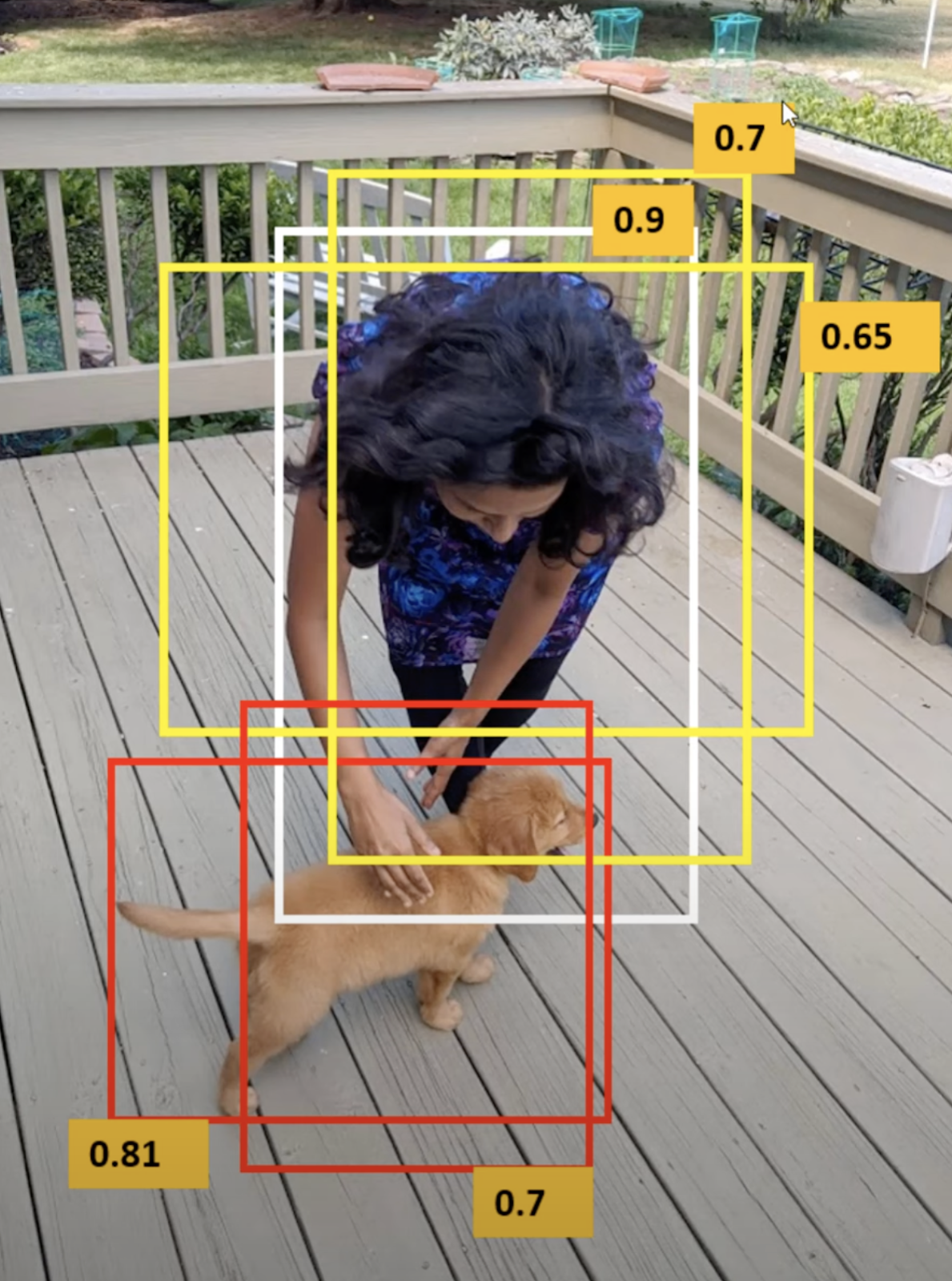
To sort out the a number of bounding field subject, the mannequin makes use of the idea of IOU or Intersections over unions, this worth lies within the vary of Zero to 1. The primary purpose of the IOU is to find out essentially the most related field out of the a number of containers.
IoU measures the overlap between a predicted bounding field and a floor fact bounding field. The worth is calculated because the ratio of the realm of overlap between these two bounding containers to the entire space encompassed by their union.
The system for calculating IoU is:
IoU=Space of Overlap/Space of UnionIoU
The place:
- Space of Overlap: The area the place the expected bounding field and the bottom fact bounding field intersect
- Space of Union: The full space encompassed by each the expected bounding field and the bottom fact bounding field
IoU values vary from Zero to 1. A worth of 1 signifies excellent overlap between the expected and floor fact bounding containers, whereas a worth of Zero means there is no such thing as a overlap between the 2 containers. Within the context of object detection, the next IoU sometimes signifies higher accuracy and precision in localizing objects inside photographs.
The algorithm ignores the expected worth of the grid cell having a low IOU worth.
Subsequent, establishing a threshold for IoU alone could not suffice, as an object might doubtlessly be related to a number of bounding containers surpassing the edge worth. Retaining all of the containers might introduce undesirable noise. Therefore calculating the Non-Most Suppression (NMS) turns into essential, as this permits the mannequin to retain solely these object bounding containers with the very best chances.
Now there may very well be one other subject after getting these distinctive containers. What if a single cell accommodates two facilities of objects? On this case the grid cell can symbolize just one class. In such circumstances Anchor Packing containers can resolve the difficulty.
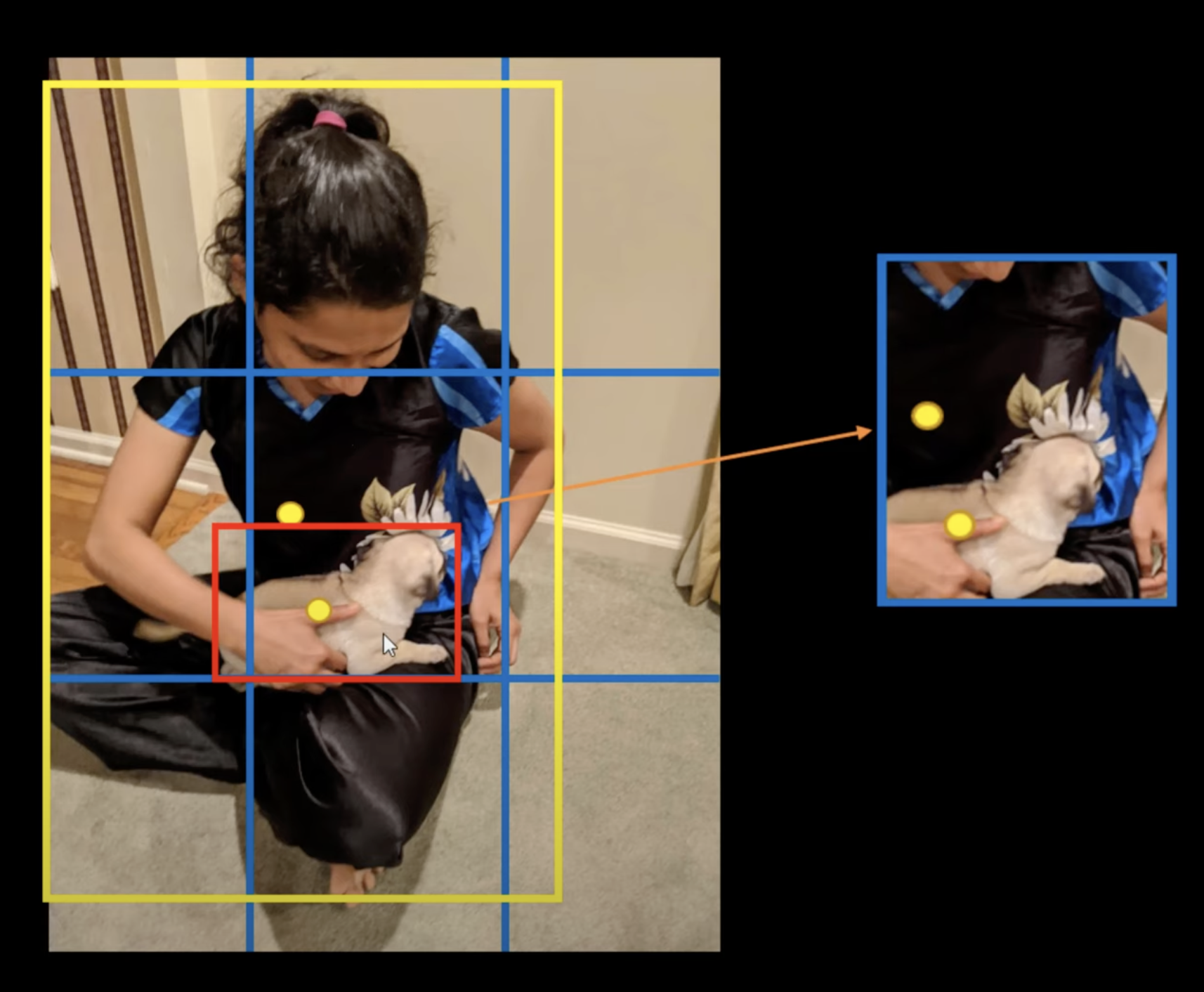
Anchor containers symbolize predetermined bounding containers with particular dimensions of peak and width. These containers are established to embody the size and proportions of specific object courses that one goals to detect, usually chosen in line with the article sizes current inside the coaching datasets.
This covers the fundamentals of the YOLO algorithm. YOLO’s power lies in its skill to detect objects in real-time, but it surely typically nonetheless struggles with small objects or intently packed objects in a picture as a consequence of its single cross method.
The evolution of YOLO fashions from YOLOv1 to YOLOv8
Carry this venture to life
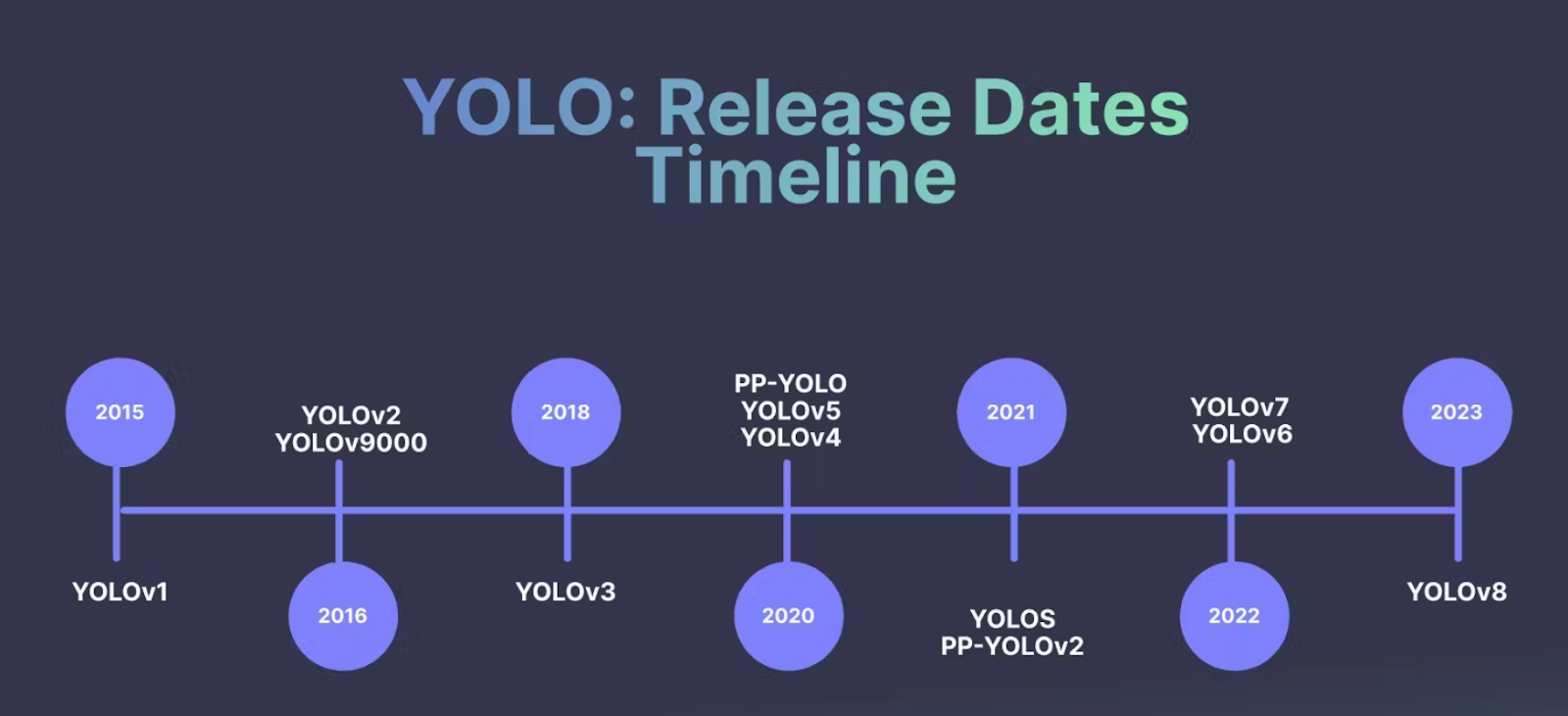
Supply
This part supplies a short overview of the YOLO framework’s evolution, from YOLOV1 to YOLOv8. YOLO was launched in a sequence of papers by Joseph Redmon and Ali Farhadi and has seen a number of iterations which have improved its pace, accuracy, and robustness. This SOTA mannequin was a major growth for the pc imaginative and prescient neighborhood.
YOLOv1 (2016): The primary model of YOLO launched a groundbreaking method to object detection by framing it as a regression downside to spatially separated bounding containers and related class chances. YOLO divided the enter picture right into a grid and predicted bounding containers and sophistication chances immediately from the complete picture in a single cross. This enabled real-time object detection.
YOLOv2 (2016): YOLOv2 introduced enhancements over the unique model by introducing numerous modifications within the structure. It included batch normalization, high-resolution classifiers, anchor containers, and so forth., aiming to boost each pace and accuracy.
YOLOv3 (2018): Within the 12 months 2018, Joseph Redmon and Ali Farhadi printed a paper on arXiv known as YOLOv3: An Incremental Enchancment. YOLOv3 additional refined the structure and coaching strategies. It integrated the usage of characteristic pyramid networks (FPN) and prediction throughout totally different scales to enhance detection efficiency, particularly for small objects. YOLOv3 additionally launched a number of scales for detection and surpassed the accuracy of earlier variations. Please take into account testing the 2 half weblog put up on implementing the YOLOv3 object detector from scratch utilizing PyTorch.
YOLOv4 (2020): Alexey Bochkovskiy and others developed a brand new and improved model of YOLO, YOLOv4: Optimum Velocity and Accuracy of Object Detection. YOLOv4 introduced vital pace and accuracy enhancements over its predecessor. This model centered on enhancing the community spine and integrated numerous state-of-the-art strategies equivalent to the usage of the CSPDarknet53 because the spine, the Mish activation perform, and the introduction of the weighted-Residual-Connections (WRC) in addition to different novel approaches to enhance efficiency. Nevertheless, this was the 12 months Joseph Redmon left laptop imaginative and prescient analysis.
YOLOv5 (2020): In 2020, merely two months after the introduction of YOLOv4, Glenn Jocher, representing Ultralytics, unveiled YOLOv5. This launch marked a major stride within the YOLO sequence. YOLOv5, whereas not a direct iteration from the unique YOLO creators, was a preferred launch from the open-source neighborhood. It optimized and simplified the structure and launched a give attention to compatibility, making the mannequin extra accessible and simpler to implement for numerous purposes. YOLOv5 launched a extra modular and versatile structure. The first distinction with YOLOv5 was its growth utilizing PyTorch versus DarkNet, the framework utilized in prior YOLO variations.
When examined on the MS COCO dataset test-dev 2017, YOLOv5x showcased a formidable AP of 50.7% utilizing a picture dimension of 640 pixels. With a batch dimension of 32, it may possibly function at a pace of 200 FPS on an NVIDIA V100. By opting for a bigger enter dimension of 1536 pixels, YOLOv5 can obtain a fair better AP of 55.8%.
Scaled-YOLOv4: In CVPR 2021, the authors of YOLOv4 launched Scaled-YOLOv4. The first innovation in Scaled-YOLOv4 concerned the incorporation of scaling strategies, the place scaling up led to a extra exact mannequin at the price of diminished pace, whereas cutting down resulted in a sooner mannequin with a sacrifice in accuracy. The scaled down structure was known as YOLOv4-tiny and labored properly on low-end GPUs. The algorithm ran at 46 FPS on a Jetson TX2 or 440 FPS on RTX2080Ti, reaching 22% mAP on MS COCO. The expanded mannequin structure generally known as YOLOv4-large encompassed three various sizes: P5, P6, and P7. This structure was particularly tailor-made for cloud GPU use and attained a cutting-edge efficiency, surpassing all previous fashions by reaching a 56% imply common precision (mAP) on the MS COCO dataset.
YOLOR: YOLOR (You Solely Be taught One Illustration) was developed within the 12 months 2021 by the identical analysis crew who developed YOLOv4. A multi-task studying methodology was devised to create a unified mannequin dealing with classification, detection, and pose estimation duties by buying a basic illustration and using sub-networks for task-specific knowledge. YOLOR, designed akin to how people make the most of prior information for brand new challenges, underwent evaluation on the MS COCO test-dev 2017 dataset, reaching an mAP of 55.4% and mAP50 of 73.3% whereas sustaining a pace of 30 FPS on an NVIDIA V100.
YOLOX (2021): YOLOX aimed to additional enhance pace and accuracy. It launched the idea of Decoupled Head and Spine (DHBB) and designed a brand new knowledge augmentation technique known as “Cross-Stage Partial Community (CSPN) Distillation” to boost efficiency on small objects.
YOLOv6: Printed within the 12 months 2022, by Meituan Imaginative and prescient AI DepartmentYOLOv6: A Single-Stage Object Detection Framework for Industrial Functions YOLOv6-L achieved higher accuracy efficiency (i.e., 49.5%/52.3%) than different detectors with an analogous inference pace on an NVIDIA Tesla T4.
Be happy to revisit an earlier Paperspace blogpost that performed a efficiency evaluation evaluating the effectivity of YOLOv6 and YOLOv7 on three generally used GPU machines accessible by Paperspace.
YOLOv7 (2022): The identical authors of YOLOv4 and YOLOR printed YOLOv7: Trainable bag-of-freebies units new state-of-the-art for real-time object detectors. YOLOv7 introduces three key components: E-ELAN for environment friendly studying, mannequin scaling for adaptability, and a “bag-of-freebies” technique for accuracy and effectivity. One facet, re-parametrization, enhances mannequin efficiency. The newest YOLOv7 mannequin surpassed YOLOv4 by lowering parameters and computation considerably—75% and 36%, respectively—whereas enhancing common precision by 1.5%. YOLOv7-tiny additionally diminished parameters and computation by 39% and 49% with out compromising imply common precision (mAP).
DAMO-YOLO (2022): Alibaba Group printed a paper titled DAMO-YOLO : A Report on Actual-Time Object Detection Design. The doc particulars numerous strategies to boost real-time video object detection accuracy. A novel detection spine design derived from Neural Structure Search (NAS) exploration, an prolonged neck construction, a extra refined head construction, and the mixing of distillation expertise to boost efficiency even additional.
These strategies concerned using MAE-NAS for neural structure search and implementing Environment friendly-RepGFPN impressed by GiraffeDet.
YOLOv8(2023): Lately we had been launched to YOLOv8 from the Ultralytics crew. A full vary of imaginative and prescient AI duties, together with detection, segmentation, pose estimation, monitoring, and classification are supported by YOLOv8. This SOTA algorithm has greater mAPs and decrease inference pace on the COCO dataset. Nevertheless, the official paper is but to be launched.
What’s new in YOLOv8
YOLOv8 is the newest model of YOLO within the object detection discipline. Few of the important thing updates on this variations are:
- A refined community structure designed for enhanced efficiency and effectivity
- Revised Anchor containers design: Anchor containers have been restructured to optimize the detection of object scales and facet ratios inside particular courses. These predefined bounding containers are tailor-made to the sizes and variations of objects in coaching datasets, making certain extra correct object localization and recognition in object detection fashions
- Adjusted loss perform to enhance general accuracy within the predictions
- YOLOv8 integrates an tailored CSPDarknet53 spine alongside a self-attention mechanism located within the community’s head
Structure overview of YOLOv8
The precise paper remains to be to be launched, therefore there’s not a lot details about the structure of the mannequin. Nevertheless, we are going to nonetheless attempt to get an summary of the mannequin. The structure proven within the picture was made by RangeKing on GitHub and is a good way of visualizing the structure.
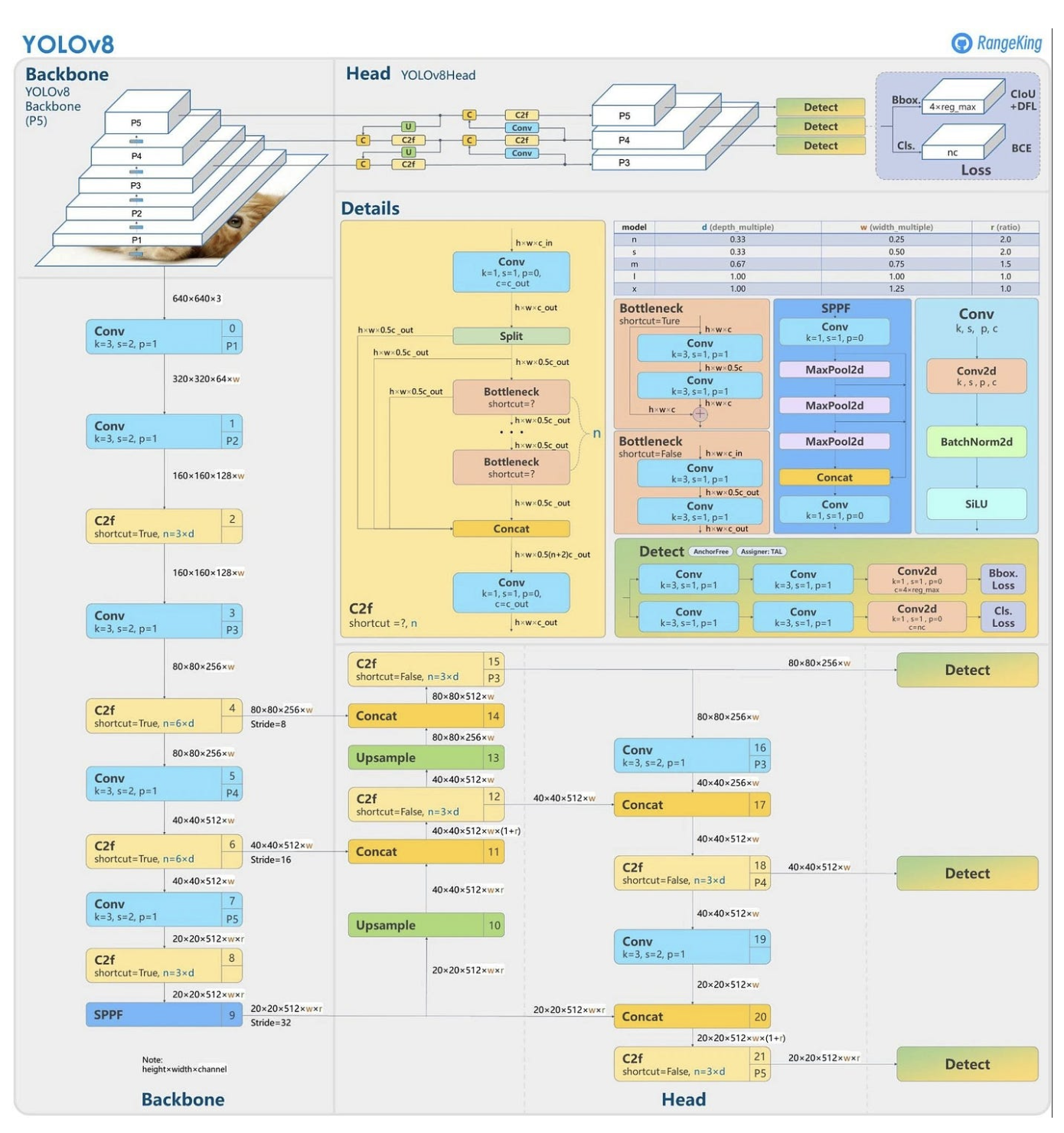
The key modifications within the structure are:
- New convolutions in YOLOv8
- Anchor-free Detections
- Mosaic Augmentation
For a extra complete rationalization, we advocate referring to the sooner put up on Paperspace, the place the intricate particulars of the YOLOv8 structure are completely defined.
Benchmark Outcomes Throughout YOLO lineage
As soon as extra, the Ultralytics crew has performed benchmarking of YOLOv8 utilizing the COCO dataset, revealing notable developments in comparison with prior YOLO iterations throughout all 5 mannequin sizes. The under determine represents the comparability of YOLOv8 with the earlier YOLO sequence.
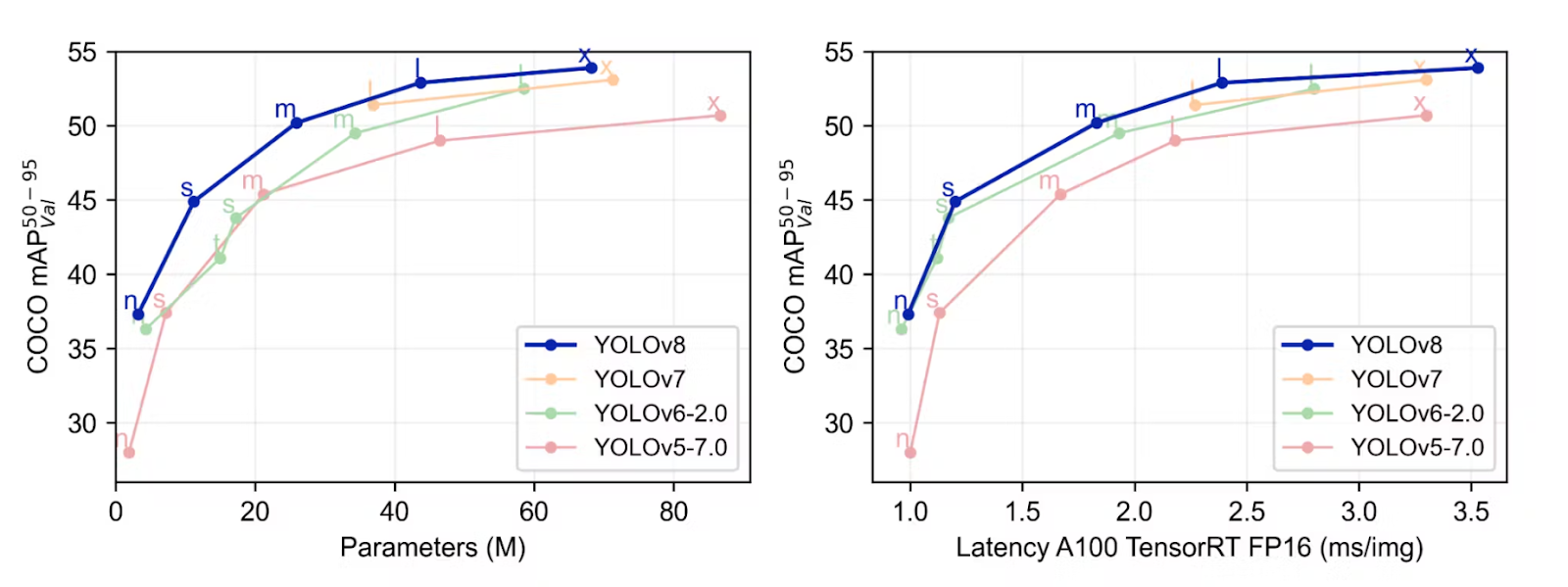
Supply
Metrics, as talked about in these sections, had been used to know the mannequin effectivity.
- Efficiency (mAP)
- Velocity of the inference (In fps)
- Compute or the mannequin dimension in FLOPs and params
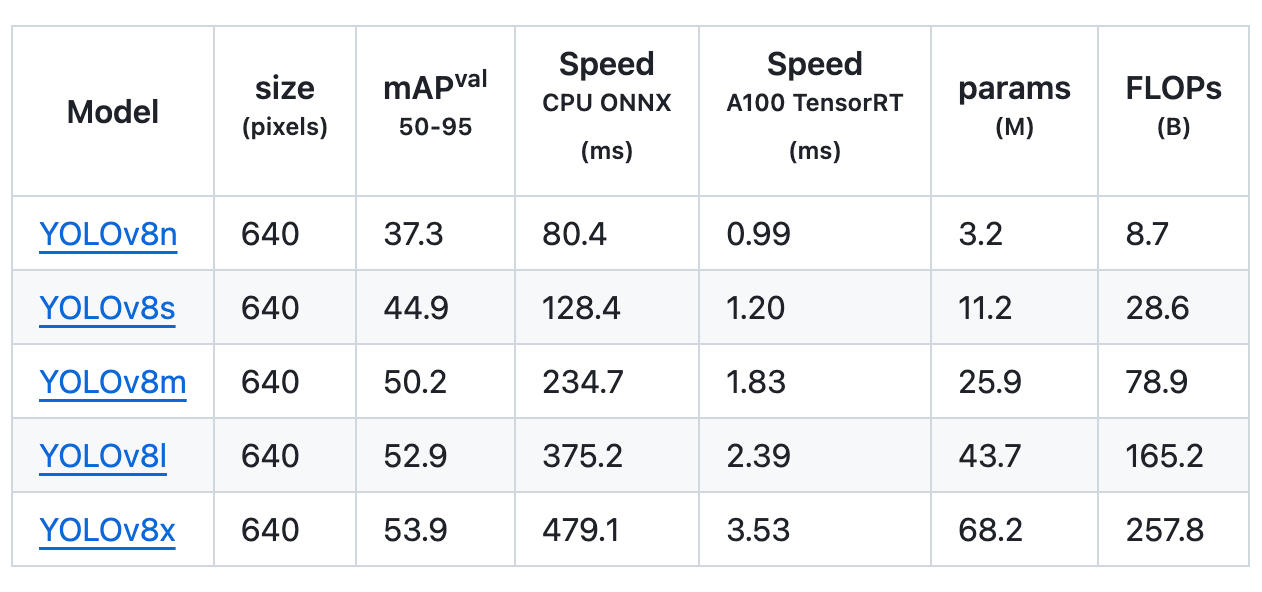
YOLOv8 accommodates numerous laptop imaginative and prescient duties, enabling the execution of object detection, picture segmentation, object classification, and pose estimation. Every activity serves a definite objective and caters to totally different aims and use circumstances. Listed here are benchmarking outcomes of 5 YOLOv8 fashions.
Detection
Object detection is the duty that entails figuring out the placement and sophistication of objects in a picture or video stream.
Within the comparability of object detection throughout 5 totally different mannequin sizes, the YOLOv8m mannequin obtained a imply Common Precision (mAP) of 50.2% on the COCO dataset. In the meantime, the YOLOv8x, the most important mannequin among the many set, achieved 53.9% mAP, regardless of having greater than twice the variety of parameters.
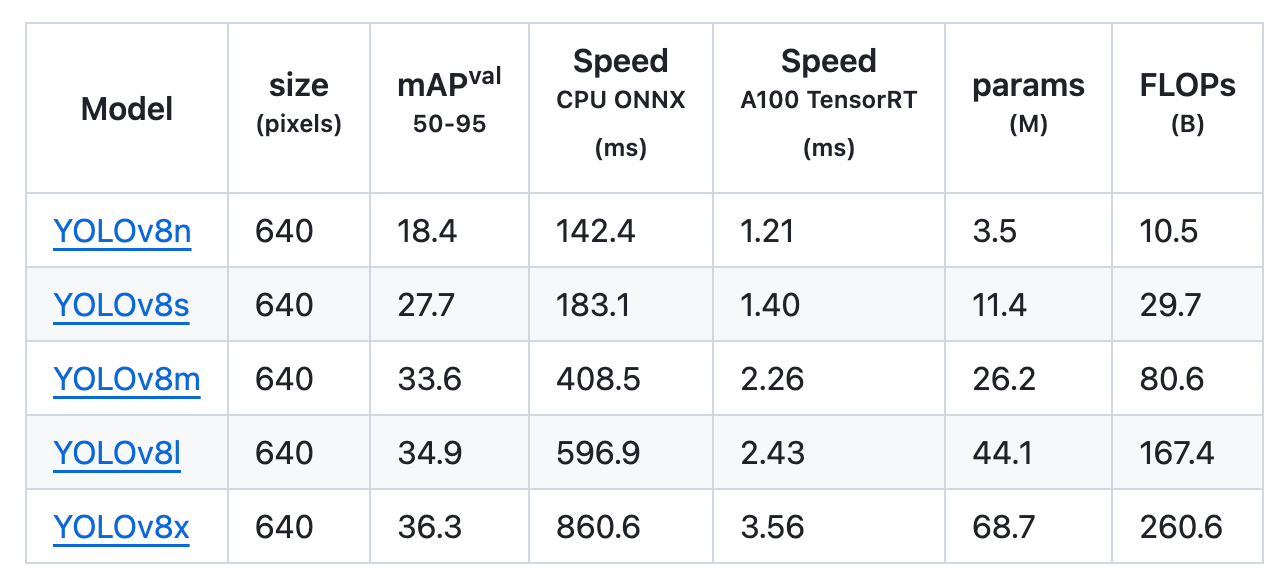
Whereas utilizing the Open Picture v7 dataset, the YOLOv8x mannequin obtained a mAP of 36.3% with virtually the identical variety of parameters.
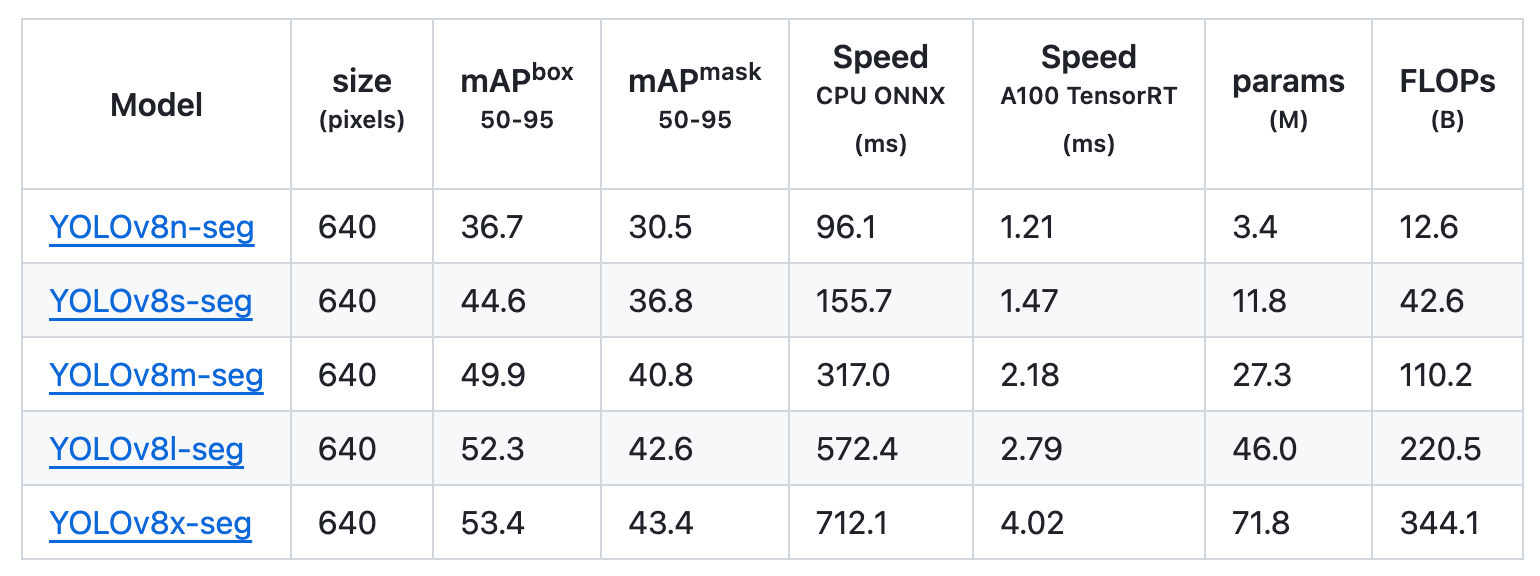
Segmentation
Occasion segmentation in object detection entails figuring out particular person objects in a picture and segments them from the remainder of the picture.
For object segmentation, these fashions had been skilled on COCO-Seg, which included 80 pre-trained courses.
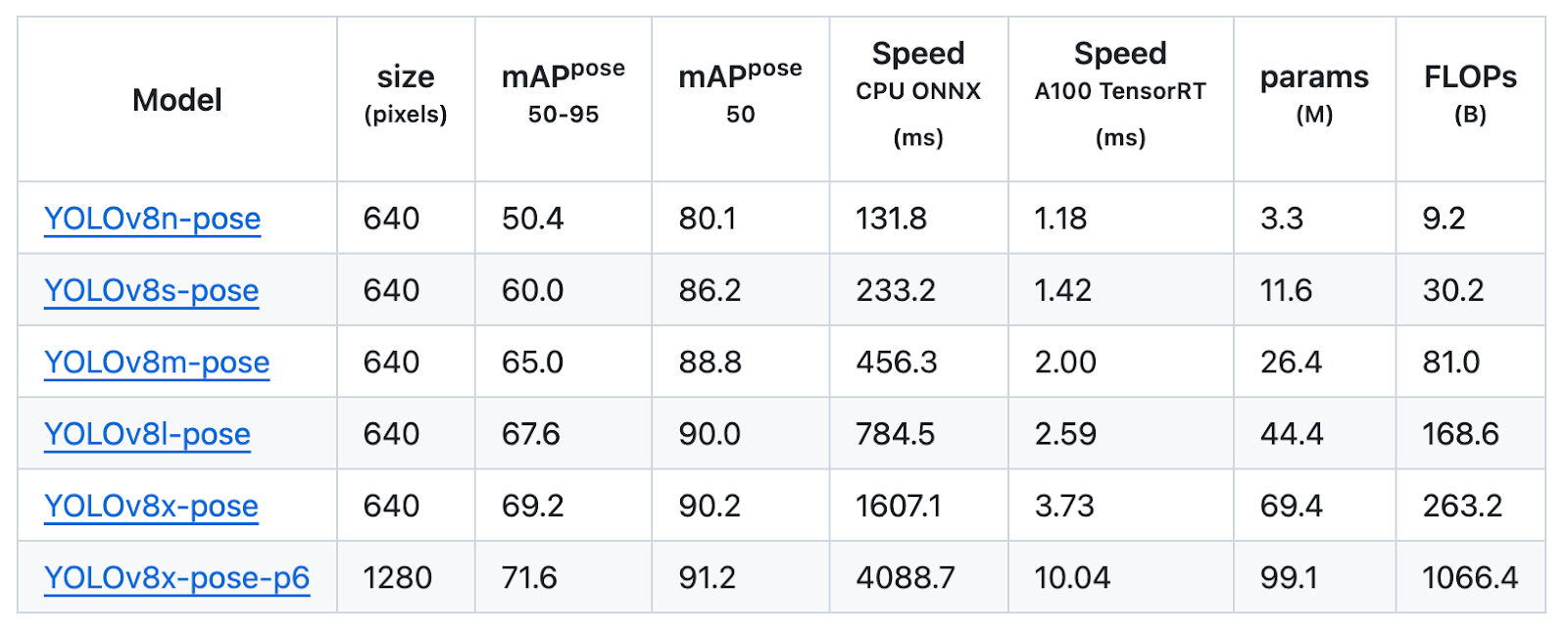
Pose
Pose estimation is the method of figuring out key factors inside a picture, generally generally known as keypoints, which determines their particular areas.
These fashions skilled on COCO-Pose, included 1 pre-trained class, individual.
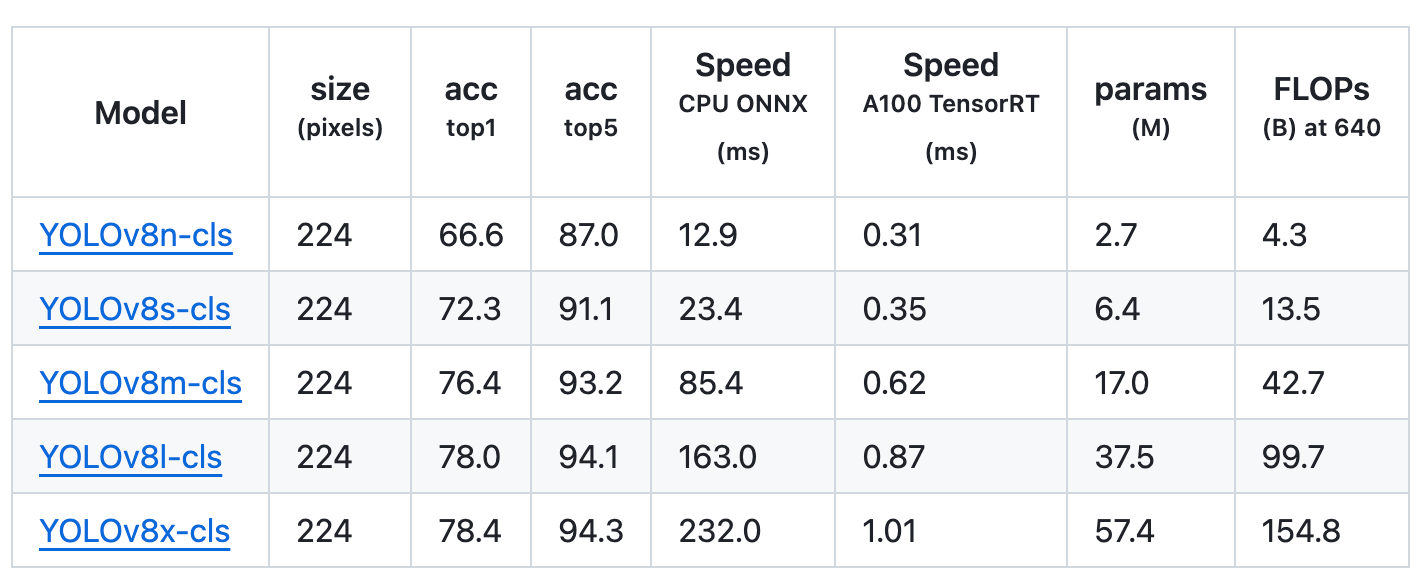
Classification
Classification is the only of the opposite duties and entails classifying a complete picture into one in all a set of predefined courses. A picture classifier produces a singular class label accompanied by a confidence rating.
These fashions had been skilled on ImageNet, which included 1000 pre-trained courses.
Because of its distinctive accuracy and efficiency, YOLOv8 emerges as a sturdy candidate in your upcoming laptop imaginative and prescient venture.
Code Demo
Carry this venture to life
On this article we are going to walkthrough the steps to implement YOLOv8 on the Paperspace platform. To implement YOLOv8 on Paperspace utilizing a GPU, please comply with the step-by-step course of. Alternatively, click on on the supplied hyperlink to use YOLOv8 on the Paperspace platform. YOLOv8 is very environment friendly and may be accelerated considerably by using the computational energy of a GPU. The YOLOv8n mannequin can simply be skilled on a Free GPU.
Paperspace provides numerous GPU choices appropriate for deep studying duties, together with NVIDIA GPUs. Right here’s a basic information on the way you would possibly implement YOLO utilizing Paperspace:
- Putting in ultralytics to work with yolov8 and import the required libraries
!pip set up ultralytics#Import crucial Libraries
from PIL import Picture
import cv2
from roboflow import Roboflow
from ultralytics import YOLO
from PIL import PictureEstablishing a customized dataset generally is a tedious activity, demanding quite a few hours to assemble photographs, annotate them precisely, and guarantee they’re exported within the acceptable format. Happily, Roboflow simplifies this course of considerably.
We are going to make the most of the Onerous Hat Picture Dataset supplied by Roboflow for the aim of figuring out the presence of onerous hats worn by development web site staff.
- Set up roboflow to export the dataset
!pip set up roboflow- Export Dataset
We are going to prepare the YOLOv8 on Onerous Hat Picture Dataset from Roboflow.
To entry a dataset from Roboflow Universe, we are going to use our pip package deal. With Roboflow we’ve the choice to generate the acceptable code snippet immediately inside our consumer interface. When on a dataset’s Universe dwelling web page, merely click on the “Export this Dataset” button, then choose the YOLO v8 export format.
This can generate a code snippet much like the code supplied under, copy and paste the code to the Paperspace pocket book or an analogous surroundings. Execute the code, the dataset can be downloaded within the acceptable format.
from roboflow import Roboflow
rf = Roboflow(api_key="ObZiCCFfi6a0GjBMxXZi")
venture = rf.workspace("shaoni-mukherjee-umnyu").venture("hard-hat-sample-ps3xv")
dataset = venture.model(2).obtain("yolov8")As soon as the is efficiently run please refresh the recordsdata part and we will discover the info set folder with the required recordsdata and folder.
- Mannequin prepare
Go to the downloaded listing and entry the info.yaml file. Guarantee to switch the paths of the coaching, testing, and validation folders to precisely replicate their respective folder areas.
names:
- head
- helmet
- individual
nc: 3
roboflow: license: Public Area venture: hard-hat-sample-ps3xv url: https://app.roboflow.com/shaoni-mukherjee-umnyu/hard-hat-sample-ps3xv/2 model: 2 workspace: shaoni-mukherjee-umnyu
take a look at: /notebooks/Onerous-Hat-Pattern-2/take a look at/photographs
prepare: /notebooks/Onerous-Hat-Pattern-2/prepare/photographs
val: /notebooks/Onerous-Hat-Pattern-2/legitimate/photographsThe under steps hundreds the mannequin and start the coaching course of
# Load a mannequin
mannequin = YOLO("yolov8n.yaml") # construct a brand new mannequin from scratch
mannequin = YOLO("yolov8n.pt") # load a pretrained mannequin (advisable for coaching) # Use the mannequin
outcomes = mannequin.prepare(knowledge="Onerous-Hat-Pattern-2/knowledge.yaml", epochs=20) # prepare the mannequin
outcomes = mannequin.val() # consider mannequin efficiency on the validation set- Consider mannequin efficiency on take a look at picture from internet
from PIL import Picture
import cv2 # from PIL
# Predict with the mannequin
outcomes = mannequin('https://safetyculture.com/wp-content/media/2022/02/Development.jpeg')- View the outcomes
The under code will show the coordinates of the bounding containers
# View outcomes
for r in outcomes: print(r.containers)- Consider the outcomes
Analyze the efficiency of the mannequin on numerous take a look at photographs to make sure it’s detecting objects precisely
# Present the outcomes
for r in outcomes: im_array = r.plot() # plot a BGR numpy array of predictions im = Picture.fromarray(im_array[..., ::-1]) # RGB PIL picture im.present() # present picture im.save('outcomes.jpg') 
As we will see that the mannequin has capable of detect objects very clearly. Be happy to judge the mannequin on totally different photographs.
Benefits of YOLOv8
- The latest model of the YOLO object detection mannequin, generally known as YOLOv8, focuses on enhancing accuracy and effectivity in comparison with its predecessors. It incorporates developments equivalent to a refined community structure, redesigned anchor containers, and an up to date loss perform to enhance accuracy
- The mannequin has achieved higher accuracy than its earlier variations
- YOLOv8 may be efficiently put in and runs effectively in any normal {hardware}. The newest YOLOv8 implementation comes with quite a lot of new options, particularly the user-friendly CLI and GitHub repo
- The benefit of Anchor-free detection provides the improved flexibility and effectivity by eliminating the necessity for manually specifying anchor containers. This omission is useful because the collection of anchor containers may be difficult and would possibly end in suboptimal outcomes in earlier YOLO fashions like v1 and v2
- Customized datasets can be utilized to refine YOLOv8, enhancing its accuracy for specific object detection assignments
- Additionally, the codebase is open supply with detailed documentation from Ultralytics
- To work with YOLOv8 the necessities are, a pc geared up with a GPU, deep studying frameworks (like PyTorch or TensorFlow), and entry to the YOLOv8 repository on GitHub. Paperspace’s big selection of GPU-based cloud computing sources that may be utilized to coach, fine-tune, and run YOLO fashions, one can benefit from the parallel processing energy of the GPU to expedite object detection processes. Additionally Paperspace platform comes with put in Pytorch and Tensorflow
Conclusion
This weblog put up delved into the developments of YOLOv8, the latest iteration of the YOLO algorithm, which has caused a major transformation in object detection strategies.
We additionally defined the constructing blocks of YOLO, and what makes the algorithm a breakthrough algorithm in laptop imaginative and prescient. Additionally, we emphasised the numerous attributes and benchmarking of various YOLOv8 variations. Together with this we additionally understood the YOLO evolution briefly and the way with every model there’s vital enchancment.
We additional applied YOLOv8 on a customized dataset utilizing Roboflow Onerous Hat object detection Picture Dataset and Paperspace platform.
Finally, we outlined a spread of potential makes use of for YOLOv8, spanning autonomous automobiles, surveillance, retail, medical imaging, agriculture, and robotics. YOLOv8 stands as a potent and adaptable object detection algorithm, showcasing its skill to precisely and quickly detect and categorize objects throughout numerous real-world purposes.
Please you’ll want to take a look at out this tutorial! Thanks for studying.
Carry this venture to life
References



