AlexNet is an Picture Classification mannequin that reworked deep studying. It was launched by Geoffrey Hinton and his workforce in 2012, and marked a key occasion within the historical past of deep studying, showcasing the strengths of CNN architectures and its huge functions.
Earlier than AlexNet, folks have been skeptical about whether or not deep studying may very well be utilized efficiently to very giant datasets. Nonetheless, a workforce of researchers have been pushed to show that Deep Neural Architectures have been the longer term, and succeeded in it; AlexNet exploded the curiosity in deep studying post-2012.
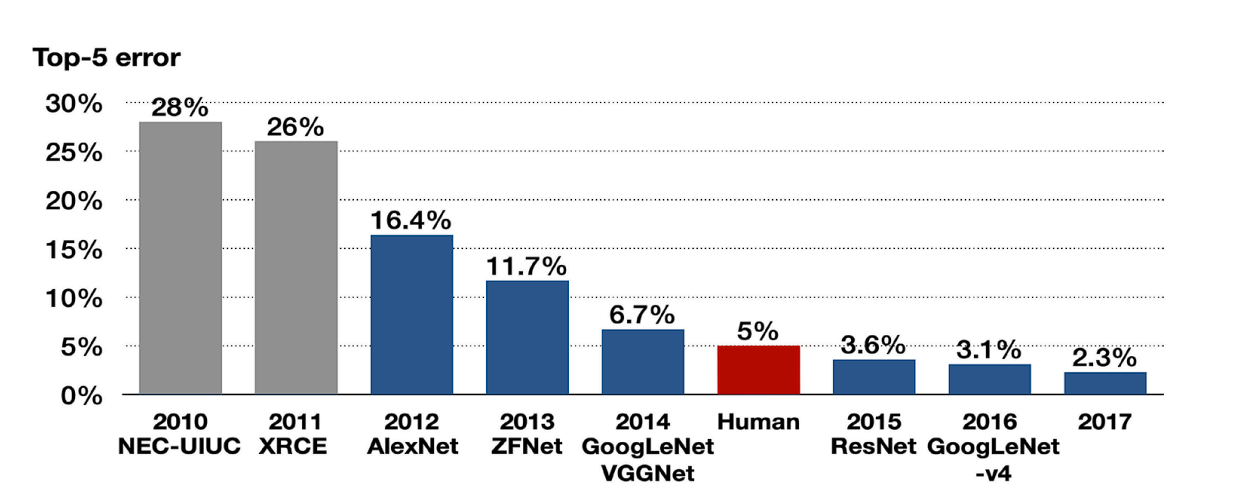
The Deep Studying (DL) mannequin was designed to compete within the ImageNet Giant Scale Visible Recognition Problem (ILSVRC) in 2012. That is an annual competitors that benchmarks algorithms for picture classification. Earlier than ImageNet, there was no availability of a giant dataset to coach Deep Neural Networks. Consequently, consequently, ImageNet additionally performed a job within the success of Deep Studying.
In that competitors, AlexNet carried out exceptionally nicely. It considerably outperformed the runner-up mannequin by decreasing the top-5 error price from 26.2% to 15.3%.

Earlier than AlexNet
Machine studying fashions reminiscent of Help Vector Machines (SVMs) and shallow neural networks dominated laptop imaginative and prescient earlier than the event of AlexNet. Coaching a deep mannequin with hundreds of thousands of parameters appeared unimaginable, we are going to examine why, however first, let’s look into the constraints of the earlier Machine Studying (ML) fashions.
- Function Engineering: SVMs and easy Neural Networks (NNs) require in depth handcrafted function engineering, which makes scaling and generalization unimaginable.
- Computational Assets: Earlier than AlexNet, researchers primarily used CPUs to coach fashions as a result of they didn’t have direct entry to GPU processing. This modified when Nvidia launched the CUDA API, permitting software program to entry parallel processing utilizing GPUs.
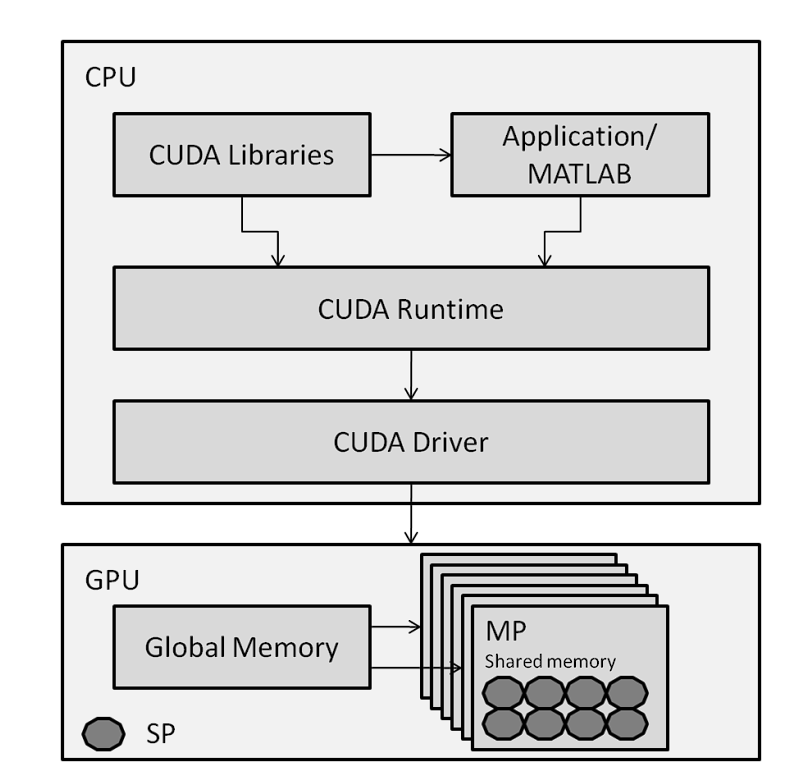
CUDA Structure –supply
- Vanishing Gradient Downside: Deep Networks confronted a vanishing gradient downside. That is the place the gradients turn out to be too small throughout backpropagation or disappear fully.
Because of computational limitations, gradient vanishing, and lack of enormous datasets to coach the mannequin on, most neural networks have been shallow. These obstacles made it unimaginable for the mannequin to generalize.
What’s ImageNet?

ImageNet is an enormous visible database designed for object recognition analysis. It consists of over 14 million hand-annotated photos with over 20,000 classes. This dataset performed a serious function within the success of AlexNet and the developments in DL, as there was no giant dataset on which Deep NNs may very well be skilled beforehand.
The ImageNet challenge additionally conducts an annual ImageNet Giant Scale Visible Recognition Problem (ILSVRC) the place researchers consider their algorithms to categorise objects and scenes accurately.
The competitors is essential as a result of it permits researchers to push the boundaries of present fashions and invent new methodologies. A number of breakthrough fashions have been unveiled on this competitors, AlexNet being one in all them.
Contribution of AlexNet
The analysis paper on AlexNet titled “ImageNet Classification with Deep Convolutional Neural Networks” solved the above-discussed issues.
This paper’s launch deeply influenced the trajectory of deep studying. The strategies and innovation launched grew to become a typical for coaching Deep Neural Networks. Listed here are the important thing improvements launched:
- Deep Structure: This mannequin utilized deep structure in comparison with any NN mannequin launched beforehand. It consisted of 5 convolutional layers adopted by three absolutely linked layers.
- ReLU Nonlinearity: CNNs at the moment used capabilities reminiscent of Tanh or Sigmoid to course of info between layers. These capabilities slowed down the coaching. In distinction, ReLU (Rectified Linear Unit) made your entire course of easier and plenty of occasions quicker. It outputs provided that the enter is given to it as constructive, in any other case it outputs a zero.
- Overlapping Pooling: Overlapping pooling is rather like common max pooling layers, however, in overlap pooling, because the window strikes throughout, it overlaps with the earlier window. This improved the error proportion in AlexNet.
- Use of GPU: Earlier than AlexNet, NNs have been skilled on the CPU, which made the method gradual. Nonetheless, the researcher of AlexNet integrated GPUs, which accelerated computation time considerably. This proved that Deep NNs might be skilled feasibly on GPUs.
- Native Response Normalization (LRN): This can be a strategy of normalizing adjoining channels within the community, which normalizes the exercise of neurons inside a neighborhood neighborhood.
The AlexNet Structure
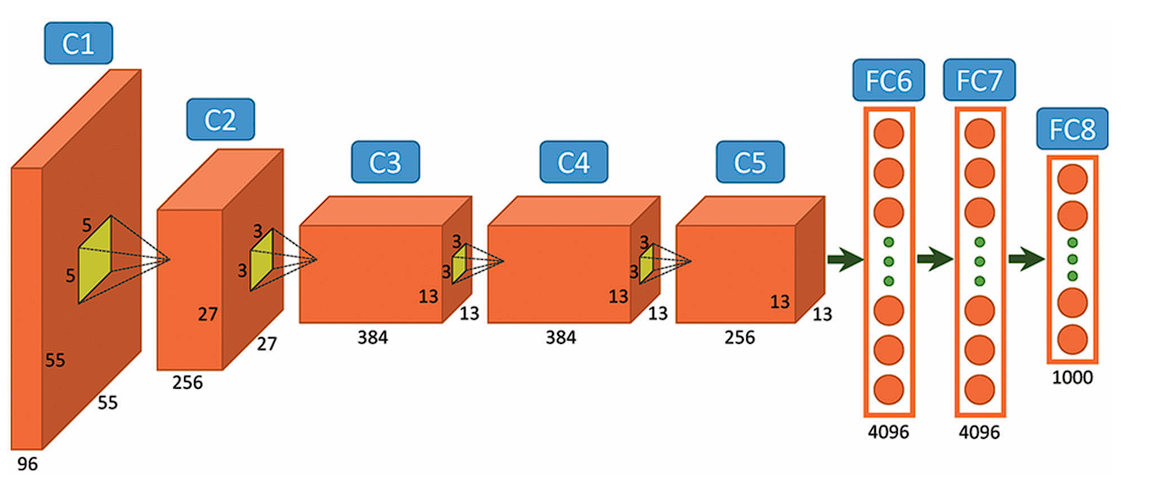
AlexNet includes a reasonably easy structure in comparison with the most recent Deep Studying Fashions. It consists of eight layers: 5 convolutional layers and three absolutely linked layers.
Nonetheless, it integrates a number of key improvements of its time, together with the ReLU Activation Features, Native Response Normalization (LRN), and Overlapping Max Pooling. We’ll take a look at every of them under.
Enter Layer
AlexNet takes photos of the Enter measurement of 227x227x3 RGB Pixels.
Convolutional Layers
- First Layer: The primary layer makes use of 96 kernels of measurement 11×11 with a stride of 4, prompts them with the ReLU activation operate, after which performs a Max Pooling operation.
- Second Layer: The second layer takes the output of the primary layer because the enter, with 256 kernels of measurement 5x5x48.
- Third Layer: 384 kernels of measurement 3x3x256. No pooling or normalization operations are carried out on the third, fourth, and fifth layers.
- Fourth Layer: 384 kernels of measurement 3x3x192.
- Fifth Layer: 256 kernels of measurement 3x3x192.
Absolutely Linked Layers
The absolutely linked layers have 4096 neurons every.
Output Layer
The output layer is a SoftMax layer that outputs chances of the 1000 class labels.
Stochastic Gradient Descent
AlexNet makes use of stochastic gradient descent (SGD) with momentum a for optimization. SGD is a variant of Gradient Descent. In SGD, as an alternative of performing calculations on the entire dataset, which is computationally costly, SGD randomly picks a batch of photos, calculates loss, and updates the load parameters.
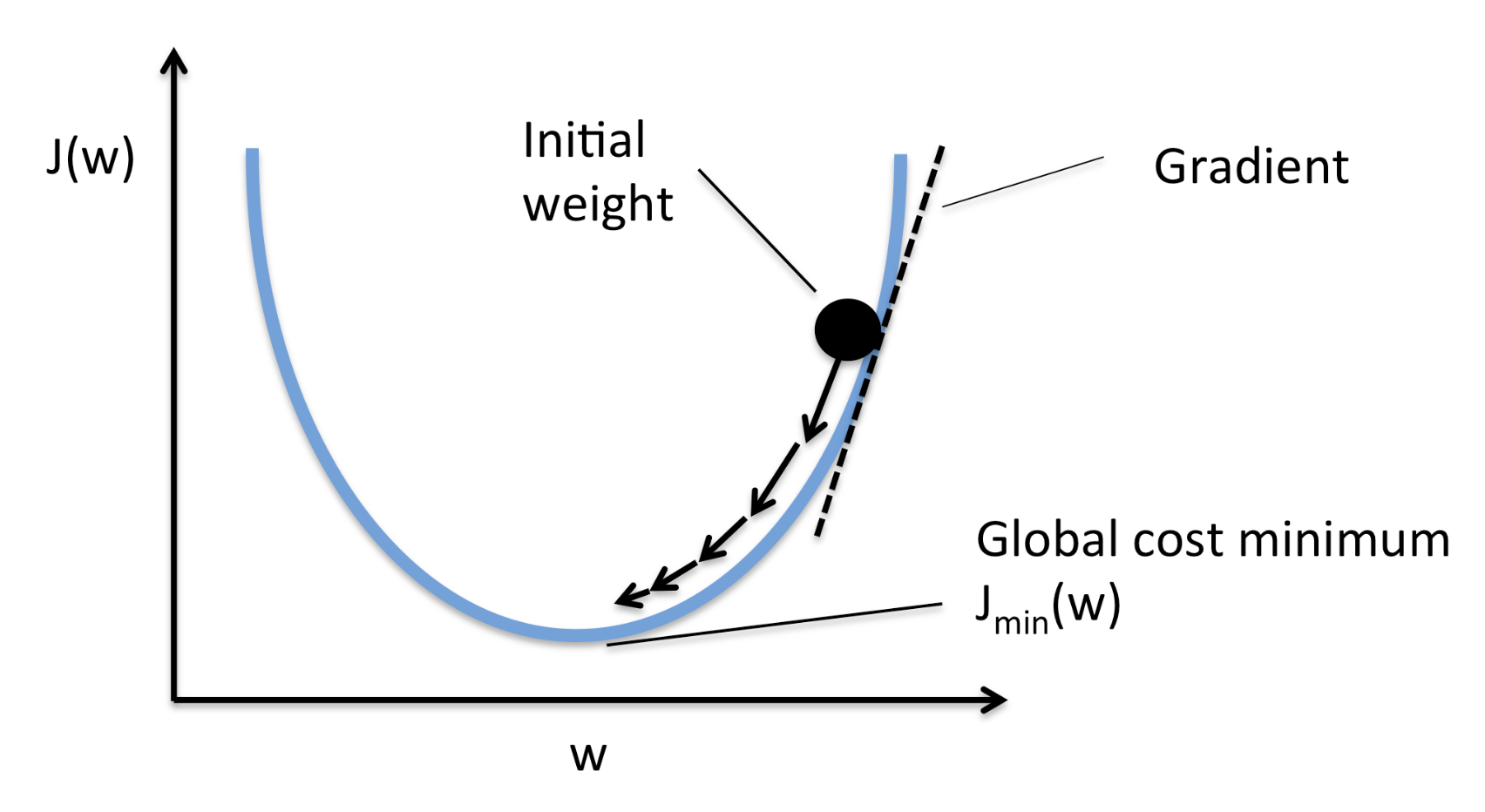
Momentum
Momentum helps speed up SGD and dampens fluctuations. It performs this by including a fraction of the earlier weight vector to the present weight vector. This prevents sharp updates and helps the mannequin overcome saddle factors.
Weight Decay
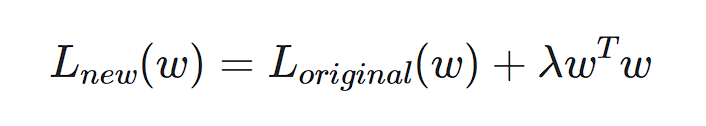
Weight decay provides a penalty on the dimensions of the weights. By penalizing bigger weights, weight decay encourages the mannequin to study smaller weights that seize the underlying patterns within the information, reasonably than memorizing particular particulars that ends in overfitting.
Information Augmentation
Information Augmentation artificially will increase the dimensions and variety of the coaching information utilizing transformations that don’t change the precise object within the picture. This forces the mannequin to study higher and enhance its skill to cater to unseen photos.
AlexNet used Random Cropping and Flipping, and Coloration Jitter Augmentations.
Improvements Launched
ReLU
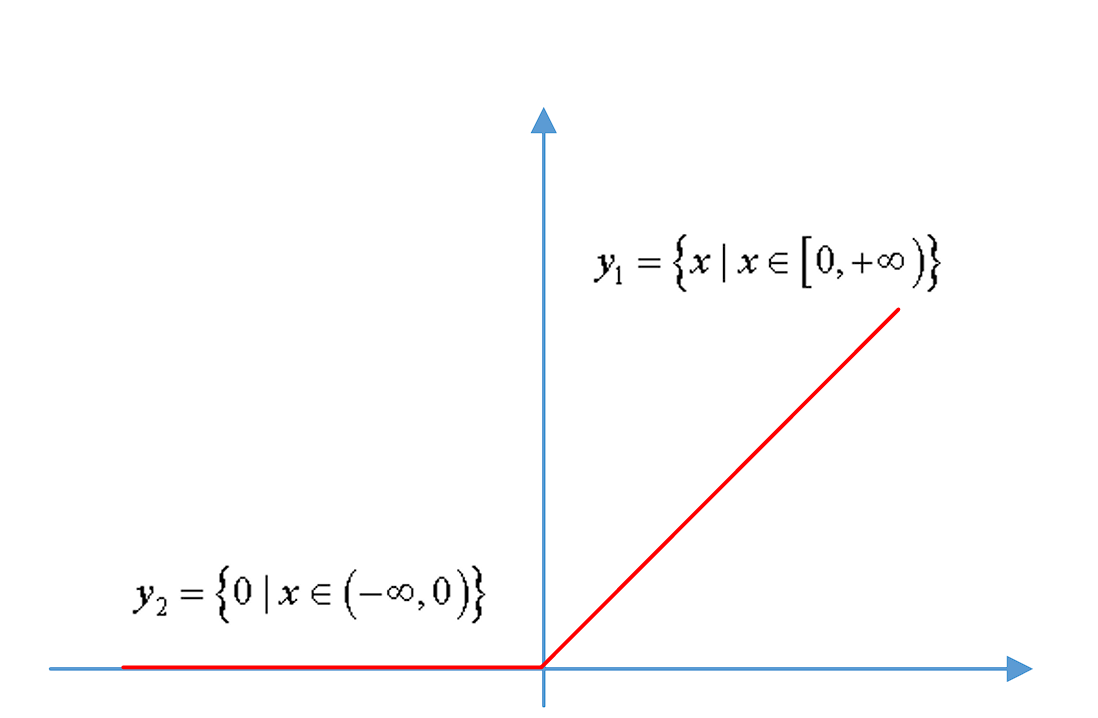
This can be a non-linear activation operate that has a easy by-product. (It eradicates unfavourable values and solely outputs constructive values).
Earlier than ReLU, Sigmoid and Tanh capabilities have been used, however they slowed down the coaching and brought on gradient vanishing. ReLU got here up instead since it’s quicker and requires fewer computation assets throughout backpropagation as a result of the by-product of Tanh is all the time lower than 1, whereas the by-product of ReLU is both zero or 1.
Dropout Layers
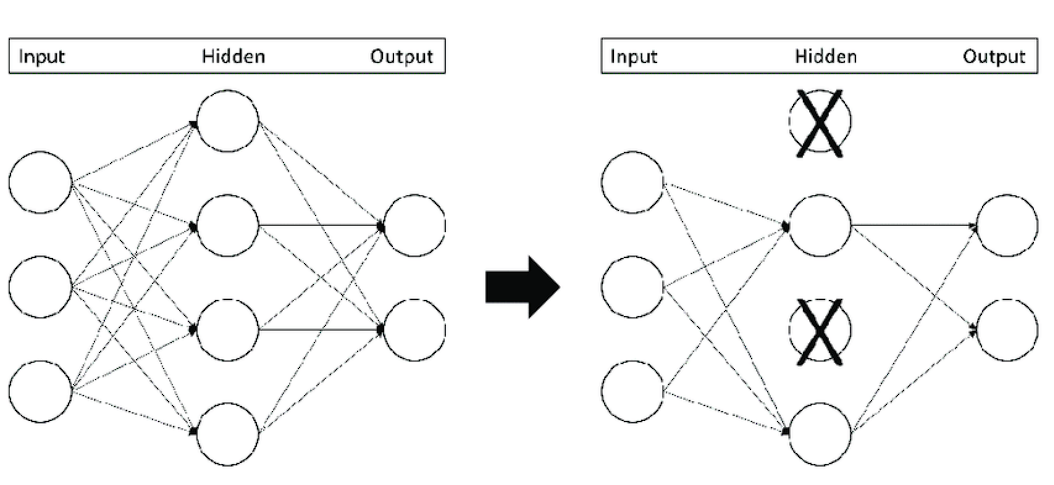
This can be a regularization approach (a way used to deal with overfitting) that “drops out” or turns off neurons.
This can be a easy technique that stops the mannequin from overfitting. It does this by making the mannequin study extra strong options and stopping the mannequin from condensing options in a single space of the community.
Dropout will increase the coaching time; nevertheless, the mannequin learns to generalize higher.
Overlapping Pooling
Pooling layers in CNNs summarize the outputs of neighboring teams of neurons in the identical kernel map. Historically, the neighborhoods summarized by adjoining pooling models don’t overlap. Nonetheless, in Overlapping pooling the adjoining pooling operations overlap with one another. This method:
- Reduces the dimensions of the community
- Gives slight translational invariance.
- Makes it troublesome for the mannequin to overfit.
Efficiency and Influence
The AlexNet structure dominated in 2012 by reaching a top-5 error price of 15.3%, considerably decrease than the runner-up’s 26.2%.
This huge discount in error price excited the researchers with the untapped potential of deep neural networks in dealing with giant picture datasets. Subsequently, numerous Deep Studying fashions have been developed later.
AlexNet impressed Networks
The success of AlexNet impressed the design and growth of varied neural community architectures. These embody:
- VGGNet: It was developed by Okay. Simonyan and A. Zisserman at Oxford. The VGGNet integrated concepts from AlexNet and was the subsequent step taken after AlexNet.
- GoogLeNet (Inception): This was Launched by Google, which additional developed the structure of AlexNet.
- ResNets: AlexNet began to face a vanishing gradient with deeper networks. To beat this, ResNet was developed. These networks launched residual studying, additionally known as skip connections. The skip connection connects activations of decrease layers to larger layers by skipping some layers in between.
Functions of AlexNet
Builders created AlexNet for picture classification. Nonetheless, advances in its structure and switch studying (a way the place a mannequin skilled on one job is repurposed for a novel associated job) opened up a brand new set of prospects for AlexNet. Furthermore, its convolutional layers kind the inspiration for object detection fashions reminiscent of Quick R-CNN and Quicker R-CNN, and professionals have utilized them in fields like autonomous driving and surveillance.
- Autism Detection: Gazal and their workforce developed a mannequin utilizing switch studying, for early detection of autism in kids. The mannequin was first skilled on ImageNet after which the pre-trained mannequin was additional skilled on their dataset associated to autism.

Classification for Autism –supply
- Video Classification: For video classification, researchers have used AlexNet to extract important options in movies for motion recognition and occasion classification.

UAV Automobile Goal –supply
- Agriculture: AlexNet analyzes photos to acknowledge the well being and situation of crops, empowering farmers to take well timed measures that enhance crop yield and high quality. Moreover, researchers have employed AlexNet for plant stress detection and weed and pest identification.
- Catastrophe Administration: Rescue groups use the mannequin for catastrophe evaluation and making emergency aid selections utilizing photos from satellites and drones.
- Medical Photographs: Docs make the most of AlexNet to diagnose numerous medical situations. For instance, they use it to research X-rays, MRIs (notably mind MRIs), and CT scans for illness detection, together with numerous kinds of cancers and organ-specific diseases. Moreover, AlexNet assists in diagnosing and monitoring eye illnesses by analyzing retinal photos.
Conclusion
AlexNet marked a major milestone within the growth of Convolutional Neural Networks (CNNs) by demonstrating their potential to deal with large-scale picture recognition duties. The important thing improvements launched by AlexNet embody ReLU activation capabilities for quicker convergence, using dropout for controlling overfitting, and using GPU to feasibly prepare the mannequin. These contributions are nonetheless in use at present. Furthermore, the additional fashions developed after AlexNet took it as a base groundwork and inspiration.



