Introduction
Picture segmentation is a process in laptop imaginative and prescient that includes dividing a specific picture into a number of segments the place every section represents an object or area within the picture. This process is necessary for purposes akin to object detection, picture recognition, and autonomous driving.
TensorFlow is an open-source framework used for constructing and coaching machine studying fashions, in our case picture segmentation fashions. Tensorflow offers the required instruments and pre-trained fashions to carry out picture segmentation duties.
Picture segmentation has some real-world use circumstances. They embody:
- Object Recognition and Monitoring: Picture segmentation is used to trace and acknowledge objects akin to individuals, autos, and animals in actual time. That is principally utilized in safety methods, surveillance, and autonomous robots.
- Medical Imaging: picture segmentation is used to see and section constructions within the physique akin to organs, tumors, and blood vessels. The information is used for analysis, therapy, and analysis.
- Autonomous Driving: Detecting and classifying objects akin to pedestrians and autos on the street to keep away from accidents and collisions
Studying Targets
- The aim of this mission is to coach a mannequin that may create segmentation masks for 59 lessons. The primary class represents the background of people whereas the remaining 58 lessons signify clothes gadgets akin to shirts, hair, pants, pores and skin, footwear, glasses, and extra.
- Along with that, is to visualise the masks created by the mannequin from the pictures and evaluate them in opposition to the right masks to guage the accuracy of the mannequin.
- Moreover, this goals to supply the person with an understanding of the picture segmentation course of and implement it.
This text was printed as part of the Knowledge Science Blogathon.
Desk of Contents
Terminologies
- Deep Studying: is a subset of machine studying that makes use of neural networks with three or extra layers to simulate the habits of the human mind to be taught from information.
- Picture Segmentation: The method of dividing a picture into segments or areas, every of which represents a separate object or a part of the picture.
- Masks – a portion of a picture that’s remoted from the remainder of a picture.
- Knowledge Augmentation: A option to artificially improve the dimensions of a dataset by making use of transformations to present information.
- Absolutely Convolutional Neural Community(FCNN) is a neural community that solely performs convolution (and subsampling or upsampling) operations. The community includes three fundamental varieties of layers: The convolutional layer, the Pooling layer, and Absolutely-connected layer.
- UNet Structure: A U-shaped encoder-decoder community structure comprising 4 encoder blocks and 4 decoder blocks joined utilizing a bridge.
- DenseNet121: Structure consists of 4 dense blocks and three transition layers. Every dense block has various numbers of layers that includes two convolutions every to carry out the convolution operation.
- Upstack: Additionally known as upsampling or transposed convolutional layers. They’re used within the decoder a part of the community to extend the spatial decision of the function maps.
- Downstack: additionally known as max-pooling layers. They’re used within the encoder a part of the community to cut back the spatial decision of the function maps.
- Skip Connections: are used to attach the corresponding encoder and decoder layers.
Dataset Description
The dataset consists of 1000 photographs and 1000 corresponding semantic segmentation masks in PNG format. Every picture is of measurement 825 pixels by 550 pixels. The segmentation masks belong to 59 lessons, with the primary class being the background of people and the remaining 58 lessons belonging to clothes gadgets for instance shirts, hair, pants, pores and skin, footwear, glasses, and extra. This dataset is accessible on Kaggle.
Importing Needed Libraries and Dependencies
Importing the libraries which are required to carry out the duties on this mission.
import os
import cv2
import numpy as np
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import matplotlib as mpl
from tqdm import tqdm
from sklearn.model_selection import train_test_splitDataset Preparation
We’ll start by creating two separate lists to gather paths for photographs and masks datasets after which we are going to iterate over all of the information utilizing the os.stroll() perform. Lastly, we are going to print out the size of each lists.
# an inventory to gather paths of 1000 photographs
image_path = []
for root, dirs, information in os.stroll('/content material/png_images'): # iterate over 1000 photographs for file in information: # create path path = os.path.be part of(root,file) # add path to record image_path.append(path)
len(image_path) # an inventory to gather paths of 1000 masks
mask_path = []
for root, dirs, information in os.stroll('/content material/png_masks'): #iterate over 1000 masks for file in information: # acquire the trail path = os.path.be part of(root,file) # add path to the record mask_path.append(path)
len(mask_path) This prints out a size of 1000 photographs and 1000 masks respectively.
After finding out the datasets to get the best image-mask pairs, we are going to decode the pictures and masks to retailer them in separate lists. To do that, we are going to learn every PNG file into reminiscence utilizing a Tensorflow perform. They’re then decoded into tensors and appended to 2 separate lists: masks and pictures.
# create an inventory to retailer photographs
photographs = []
# iterate over 1000 picture paths
for path in tqdm(image_path): # learn file file = tf.io.read_file(path) # decode png file right into a tensor picture = tf.picture.decode_png(file, channels=3, dtype=tf.uint8) # append to the record photographs.append(picture) # create an inventory to retailer masks
masks = []
# iterate over 1000 masks paths
for path in tqdm(mask_path): # learn the file file = tf.io.read_file(path) # decode png file right into a tensor masks = tf.picture.decode_png(file, channels=1, dtype=tf.uint8) # append masks to the record masks.append(masks)Visualizing Dataset Samples
The code beneath makes use of matplotlib to create a determine of the pictures within the vary Four to six utilizing a for-loop.
plt.determine(figsize=(25,13)) # Iterate over the pictures within the vary 4-6
for i in vary(4,7): # Create a subplot for every picture plt.subplot(4,6,i) # Get the i-th picture from the record img = photographs[i] # Present the picture with a colorbar plt.imshow(img) plt.colorbar() # Flip off the axis labels plt.axis('off') # Show the determine
plt.present()Output:

We once more use matplotlib to print out the corresponding masks. We outline a normalizer in order that the masks have a consistency.
# Outline a normalizer that may be utilized whereas visualizing masks to have a consistency
NORM = mpl.colours.Normalize(vmin=0, vmax=58) # plot masks
plt.determine(figsize=(25,13))
for i in vary(4,7): plt.subplot(4,6,i) img = masks[i] plt.imshow(img, cmap='jet', norm=NORM) plt.colorbar() plt.axis('off')
plt.present()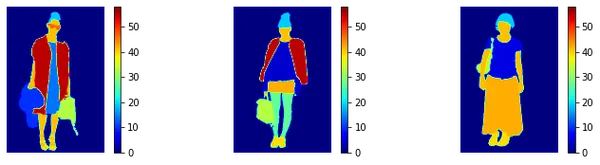
Knowledge Preprocessing
We’ll begin the info preprocessing with two features to take a picture and the corresponding masks from the dataset and resize them to a hard and fast measurement of 128 by 128 pixels. The perform resize_image will rescale the pixel worth and the tf.picture.resize will resize the picture to the specified measurement. The masks is resized utilizing the tf.picture.resize perform with out scaling the pixel values. Lastly, it converts the info sort of the masks tensor to uint8.
We’ll then use an inventory comprehension to use the resizing features to every picture and masks within the unique lists of photographs and masks, respectively. The ensuing lists of resized photographs and masks have the identical measurement as the unique lists.
#features to resize the pictures and masks def resize_image(picture): # scale the picture picture = tf.solid(picture, tf.float32) picture = picture/255.0 # resize picture picture = tf.picture.resize(picture, (128,128)) return picture def resize_mask(masks): # resize the masks masks = tf.picture.resize(masks, (128,128)) masks = tf.solid(masks, tf.uint8) return masks X = [resize_image(i) for i in images]
y = [resize_mask(m) for m in masks]
len(X), len(y) This prints a size of 1000 in each X and y.
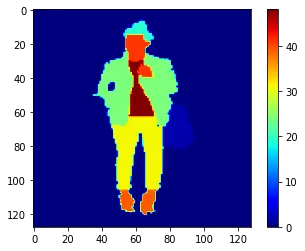
Visualizing a pattern of the resized Picture and Masks.
#visualizing a resized picture and respective masks
# plot a picture
plt.imshow(X[36])
plt.colorbar()
plt.present() #plot a masks
plt.imshow(y[36], cmap='jet')
plt.colorbar()
plt.present()Output:

Splitting Knowledge into Coaching and Validation
We’ll begin by splitting the datasets X and y into coaching and validation units. The validation information shall be 20% of the coaching information, and the random_state is ready to Zero for reproducibility. After that, we are going to create TensorFlow Dataset objects from the NumPy arrays train_X, val_X, train_y, and val_y utilizing the tensor slices methodology.
# break up information into 80/20 ratio
train_X, val_X,train_y, val_y = train_test_split(X, y, test_size=0.2, random_state=0 )
# develop tf Dataset objects
train_X = tf.information.Dataset.from_tensor_slices(train_X)
val_X = tf.information.Dataset.from_tensor_slices(val_X) train_y = tf.information.Dataset.from_tensor_slices(train_y)
val_y = tf.information.Dataset.from_tensor_slices(val_y) # confirm the shapes and information varieties
train_X.element_spec, train_y.element_spec, val_X.element_spec, val_y.element_specKnowledge Augmentation
Knowledge augmentation is a method of artificially rising the coaching set by creating modified copies of a dataset utilizing present information. Listed below are the features and what they do:
- Brightness: adjusts brightness of the picture
- Gamma: adjusts the gamma of the picture. The masks isn’t modified.
- Hue: adjusts the hue of the picture. The masks isn’t reworked.
- Crop: crops the picture and the masks and resizes them.
- Flip_hori: perform to flip the picture and the masks horizontally.
- Flip_vert: perform to flip each the picture and the masks vertically.
- Rotate: perform to rotate each the picture and masks by 90 levels within the clockwise path.
Every perform takes tensors of the picture and masks as inputs and returns the ensuing picture tensor and the unique masks tensor. The transformations are designed to be utilized identically to each the picture and masks tensors in order that they keep aligned. That is used to generate new coaching examples from unique information.
# regulate brightness of picture
# do not alter in masks
def brightness(img, masks): img = tf.picture.adjust_brightness(img, 0.1) return img, masks # regulate gamma of picture
# do not alter in masks
def gamma(img, masks): img = tf.picture.adjust_gamma(img, 0.1) return img, masks # regulate hue of picture
# do not alter in masks
def hue(img, masks): img = tf.picture.adjust_hue(img, -0.1) return img, masks def crop(img, masks): # crop each picture and masks identically img = tf.picture.central_crop(img, 0.7) # resize after cropping img = tf.picture.resize(img, (128,128)) masks = tf.picture.central_crop(masks, 0.7) # resize afer cropping masks = tf.picture.resize(masks, (128,128)) # solid to integers as they're class numbers masks = tf.solid(masks, tf.uint8) return img, masks
# flip each picture and masks identically
def flip_hori(img, masks): img = tf.picture.flip_left_right(img) masks = tf.picture.flip_left_right(masks) return img, masks # flip each picture and masks identically
def flip_vert(img, masks): img = tf.picture.flip_up_down(img) masks = tf.picture.flip_up_down(masks) return img, masks # rotate each picture and masks identically
def rotate(img, masks): img = tf.picture.rot90(img) masks = tf.picture.rot90(masks) return img, masksWe’ll then unzip the pictures and masks file, apply the augmentation features, and concatenate the brand new information to the coaching set.
# zip photographs and masks
practice = tf.information.Dataset.zip((train_X, train_y))
val = tf.information.Dataset.zip((val_X, val_y)) # carry out augmentation on practice information solely a = practice.map(brightness)
b = practice.map(gamma)
c = practice.map(hue)
d = practice.map(crop)
e = practice.map(flip_hori)
f = practice.map(flip_vert)
g = practice.map(rotate) # concatenate each new augmented units
practice = practice.concatenate(a)
practice = practice.concatenate(b)
practice = practice.concatenate(c)
practice = practice.concatenate(d)
practice = practice.concatenate(e)
practice = practice.concatenate(f)We now have a dataset of the unique 800*7=5600 plus the unique 800 which is a complete of 6400 coaching examples. After that, the batch measurement and buffer measurement are set to prepare for mannequin constructing.
#setting the batch measurement
BATCH = 64 AT = tf.information.AUTOTUNE
#buffersize
BUFFER = 1000 STEPS_PER_EPOCH = 800//BATCH
VALIDATION_STEPS = 200//BATCH practice = practice.cache().shuffle(BUFFER).batch(BATCH).repeat()
practice = practice.prefetch(buffer_size=AT)
val = val.batch(BATCH)Defining and Constructing the Mannequin
We’ll use FCNN (Absolutely Convolutional Neural Networks) which as said above accommodates two sections: the encoder(down-stack) and the decoder(up-stack). The encoder is a down-stack of convolutional neural layers that performs the position of extracting options from the enter picture. A decoder is an up-stack of transposed convolutional neural layers that construct the segmented picture from the extracted options. On this mission, we are going to use the U-Web structure.
We want to use the purposeful strategy of U-Web structure, however we can have our structure appropriate for our perform. The down-stack generally is a pre-trained CNN skilled for picture classification (e.g., MobileNetV2, ResNet, NASNet, Inception, DenseNet, or EfficientNet). It might successfully extract the options. However now we have to construct our up-stack to match our lessons (right here, 59), construct skip-connections, and practice it with our information.
On this case, we are going to use DenseNet121 from Keras.
# Use pre-trained DenseNet121 with out head
base = keras.purposes.DenseNet121(input_shape=[128,128,3], include_top=False, weights='imagenet') Subsequent, we outline an inventory of skip-connections for the CNN mannequin. The skip-connections are used to alleviate the vanishing gradient downside in deep neural networks, which might happen when coaching networks with many layers. The concept is to skip a number of layers and join earlier layers on to later layers, permitting gradients to circulate extra simply throughout coaching. They’re utilized in a U-Web structure to enhance the accuracy of semantic segmentation.
#last ReLU activation layer for every function map measurement, i.e. 4, 8, 16, 32, and 64, required for skip-connections
skip_names = ['conv1/relu', # size 64*64 'pool2_relu', # size 32*32 'pool3_relu', # size 16*16 'pool4_relu', # size 8*8 'relu' # size 4*4 ]Constructing the Downstack
We’re constructing the down-stack, which is used to extract options from the enter picture and downsample them to cut back the spatial decision. It makes use of the DenseNet mannequin, enter, output, and weights set to not be up to date.
#output of those layers
skip_outputs = [base.get_layer(name).output for name in skip_names]
#Constructing the downstack with the above layers. We use the pre-trained mannequin as such, with none fine-tuning.
downstack = keras.Mannequin(inputs=base.enter, outputs=skip_outputs)
# freeze the downstack layers
downstack.trainable = FalseConstructing the Upstack
An up-stack is used within the decoder a part of a U-Web structure for picture segmentation. We’ll use an up-sampling template for the up-stack pix2pix template which is accessible open-source within the TensorFlow examples repo.
The up-stack consists of 4 upsample layers that double the spatial decision of the function maps by performing a 2x nearest neighbor upsampling adopted by a 3×Three convolutional layer with stride 1. The variety of output channels decreases in every successive layer from 512 to 64.
!pip set up -q git+https://github.com/tensorflow/examples.git --quiet from tensorflow_examples.fashions.pix2pix import pix2pix # 4 upstack layers for upsampling sizes # 4->8, 8->16, 16->32, 32->64 upstack = [pix2pix.upsample(512,3), pix2pix.upsample(256,3), pix2pix.upsample(128,3), pix2pix.upsample(64,3)]Constructing the U-Web mannequin with skip connections by merging the down-stack and up-stack with skip-connections. The code defines the entire U-Web structure for picture segmentation utilizing the down-stack and up-stack layers outlined within the prior sections. The down-stack downsamples the pictures and extracts options, and the up-stack is used to upsample the function maps to the unique enter measurement of the picture and concatenate them with the corresponding skip from the down-stack to refine the segmentation output.
Lastly, a Conv2DTranspose layer with 59 filters and a kernel measurement of three is utilized to the output function maps to get the ultimate segmentation map.
# outline the enter layer
inputs = keras.layers.Enter(form=[128,128,3]) # downsample down = downstack(inputs)
out = down[-1] # put together skip-connections
skips = reversed(down[:-1])
# select the final layer at first 4 --> 8 # upsample with skip-connections
for up, skip in zip(upstack,skips): out = up(out) out = keras.layers.Concatenate()([out,skip]) # outline the ultimate transpose conv layer
# picture 128 by 128 with 59 lessons
out = keras.layers.Conv2DTranspose(59, 3, strides=2, padding='identical', )(out)
# full unet mannequin
unet = keras.Mannequin(inputs=inputs, outputs=out)Compiling and Coaching the Mannequin
A perform to compile the mannequin with a studying fee of 0.001 and accuracy because the analysis metric.
# compiling the mannequin def Compile_Model(): unet.compile(loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), optimizer=keras.optimizers.RMSprop(learning_rate=0.001), metrics=['accuracy']) Compile_Model()Becoming the mannequin on the coaching set and fine-tuning the mannequin.
#coaching and fine-tuning
hist_1 = unet.match(practice, validation_data=val, steps_per_epoch=STEPS_PER_EPOCH, validation_steps=VALIDATION_STEPS, epochs=20, verbose=2)Making a masks prediction utilizing the mannequin.
# choose a validation information batch
img, masks = subsequent(iter(val))
# make prediction
pred = unet.predict(img)
plt.determine(figsize=(20,28)) ok = 0
for i in pred: # plot the expected masks plt.subplot(4,3,1+ok*3) i = tf.argmax(i, axis=-1) plt.imshow(i,cmap='jet', norm=NORM) plt.axis('off') plt.title('Prediction') # plot the groundtruth masks plt.subplot(4,3,2+ok*3) plt.imshow(masks[k], cmap='jet', norm=NORM) plt.axis('off') plt.title('Floor Fact') # plot the precise picture plt.subplot(4,3,3+ok*3) plt.imshow(img[k]) plt.axis('off') plt.title('Precise Picture') ok += 1 if ok == 4: break
plt.suptitle('Predition After 20 Epochs (No Advantageous-tuning)', coloration='purple', measurement=20) plt.present()
Coaching the mannequin and superb tuning from the 21st epoch to the 40th epoch.
downstack.trainable = True
# compile once more
Compile_Model()
# practice from epoch 20 to 40
hist_2 = unet.match(practice, validation_data=val, steps_per_epoch=STEPS_PER_EPOCH, validation_steps=VALIDATION_STEPS, epochs=40, initial_epoch = 20, verbose = 2 )Making a masks prediction utilizing the mannequin.
# choose a validation information batch
img, masks = subsequent(iter(val))
# make prediction
pred = unet.predict(img)
plt.determine(figsize=(20,30)) ok = 0
for i in pred: # plot the expected masks plt.subplot(4,3,1+ok*3) i = tf.argmax(i, axis=-1) plt.imshow(i,cmap='jet', norm=NORM) plt.axis('off') plt.title('Prediction') # plot the groundtruth masks plt.subplot(4,3,2+ok*3) plt.imshow(masks[k], cmap='jet', norm=NORM) plt.axis('off') plt.title('Floor Fact') # plot the precise picture plt.subplot(4,3,3+ok*3) plt.imshow(img[k]) plt.axis('off') plt.title('Precise Picture') ok += 1 if ok == 4: break
plt.suptitle('Predition After 40 Epochs (By Advantageous-tuning from 21th Epoch)', coloration='purple', measurement=20) plt.present()
The mannequin has improved tremendously.
Efficiency Curves
We’ll use the code to visualise the coaching and validation accuracy of a deep studying mannequin throughout a number of epochs.
history_1 = hist_1.historical past
acc=history_1['accuracy']
val_acc = history_1['val_accuracy'] history_2 = hist_2.historical past
acc.lengthen(history_2['accuracy'])
val_acc.lengthen(history_2['val_accuracy']) plt.plot(acc[:150], '-', label='Coaching')
plt.plot(val_acc[:150], '--', label='Validation')
plt.plot([50,50],[0.7,1.0], '--g', label='Advantageous-Tuning')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.ylim([0.7,1.0])
plt.legend()
plt.present()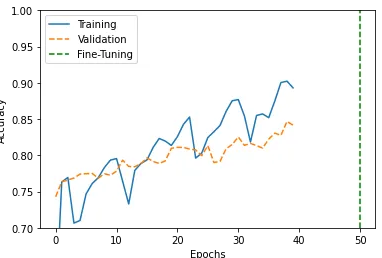
The mannequin would undoubtedly enhance with elevated epochs and coaching information.
Conclusion
The mission has achieved the target of coaching a mannequin that generates masks for the 59 lessons of clothes. We have been in a position to evaluate the generated masks to the corresponding masks within the datasets. We ready the info, decoded it into tensors, resized, break up the dataset, carried out information augmentation, and skilled the mannequin utilizing the UNet structure.
- Object segmentation has real-world purposes in lots of fields, together with laptop imaginative and prescient, medical imaging, robotics, and unbiased driving.
- The method of object segmentation utilizing TensorFlow contains dataset preparation, information preprocessing, information augmentation, defining the mannequin, splitting information into coaching and validation units, after which coaching and fine-tuning the mannequin to get the specified outcomes.
- Object segmentation can be utilized to create masks of garments from random photographs to be used within the trend trade.
The code is accessible in my github.
The media proven on this article isn’t owned by Analytics Vidhya and is used on the Creator’s discretion.


