Information high quality is important to constructing an excellent pc imaginative and prescient mannequin: the extra exact your annotations are, and the less annotations which might be mislabeled, the higher your mannequin will carry out. However how does one determine mislabelled photos in a dataset? Good query!
On this information, we’re going to point out use CLIP and the Roboflow CVevals mission to determine photos which will have been assigned the unsuitable label throughout the annotation course of. On the finish of this information, you’ll have a report exhibiting any probably mislabeled photos in your pc imaginative and prescient dataset. With out additional ado, let’s get began!
Step 1: Add Photos to Roboflow
If you have already got photos in Roboflow, you may skip this part.
On this information, we’re going to load our photos from Roboflow to be used in figuring out mislabelled photos. Utilizing a platform like Roboflow is useful for bettering knowledge high quality as a result of Roboflow numerous automated checks are carried out to guarantee your knowledge high quality (i.e. determine bounding bins with 0x0 dimensions).
As well as, you may examine every annotation in Roboflow and make adjustments to them. That is perfect for those who discover a picture that has been mislabelled in your dataset.
First, signal as much as the Roboflow platform. Then, click on the “Create a Mission” button:
Subsequent, add all your annotated photos to the Roboflow platform. This can take a number of moments relying on what number of photos are in your dataset. On this instance, we’ll work with the TACO trash dataset, which comprises images of trash in context (i.e. litter on the bottom). You may work with any photos you’ve gotten.
You probably have not annotated your photos, you may add annotations utilizing the Roboflow Annotate software. Along with your annotated photos within the Roboflow platform, we’re prepared to begin figuring out mislabelled photos.
Step 2: Obtain Mislabeled Photos Script
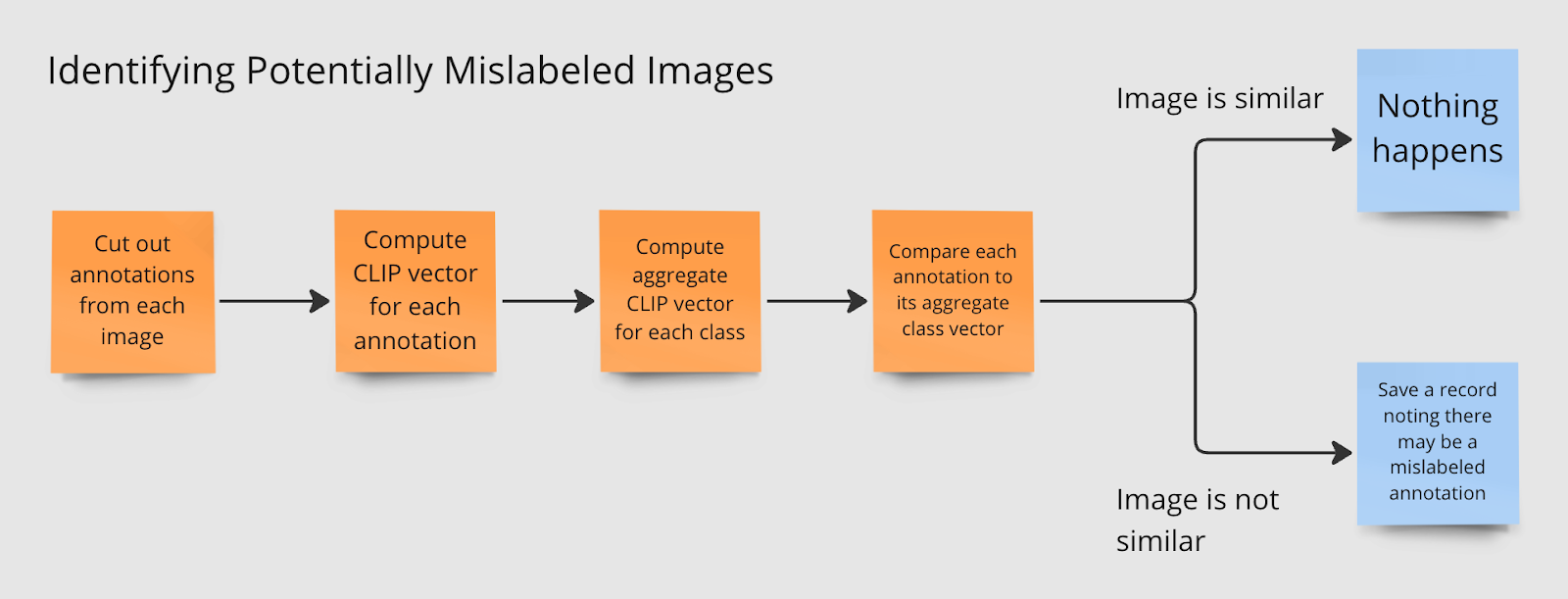
Roboflow maintains an open-source mission known as CVevals with numerous utilities for evaluating pc imaginative and prescient fashions and datasets. On this information, we’re going to make use of the cutout.py script, which leverages CLIP, a picture embedding mannequin developed by OpenAI, to determine photos that might not be labeled appropriately.
The script cuts out annotations from every picture, computes its CLIP vector, then aggregates CLIP vectors for every class. Then, every annotation is in comparison with the mixture CLIP vector. The additional aside an annotation is from the typical class vector, the extra possible it’s that the annotation is wrong.
To get began, first clone the CVevals repository, set up the requisite dependencies, and replica the cutout.py script into the primary mission listing:
git clone https://github.com/roboflow/cvevals
cd cvevals
pip3 set up -r necessities.txt
pip3 set up -e .
cp scripts/cutout.py .Now we’re able to run the script to determine mislabelled photos.
Step 3: Run Script on a Dataset
To determine mislabelled photos utilizing the CVevals label checking script, you’ll need your Roboflow API key, workspace ID, dataset model, and mission ID. Yow will discover out retrieve these items of knowledge in our documentation.
With these items of knowledge prepared, we are able to run the analysis script. Listed here are the required arguments it’s good to specify:
python3 cutout.py --eval_data_path=photos --roboflow_workspace_url=<> --roboflow_project_url=<> --roboflow_model_version=<>The eval_data_path refers back to the folder during which you need to save the dataset downloaded from the Roboflow API.
Optionally, you may specify the next arguments:
--generate_pdf=true: Generate a PDF report exhibiting numerous dataset metrics, together with the names of recordsdata which will have mislabelled photos.--fp_threshold=0.7: The similarity threshold that have to be met earlier than a picture is taken into account just like the typical CLIP vector for a category. By default, this worth is 0.7. We advocate leaving this worth as 0.7 except you discover the script flags legitimate annotations as mislabeled.
We’ll specify the --generate-pdf=true report on this instance to generate a PDF abstract:
python3 cutout.py --eval_data_path=photos --roboflow_workspace_url=workspace --roboflow_project_url=mission --roboflow_model_version=1 –-generate_pdf=trueLet’s run the command on our TACO dataset. Our dataset comprises over 3,00Zero photos so it’ll take a while to run the evaluation.
The command will present messages as vectors are computed for floor reality knowledge:
After computing vectors, the command prints out the names of any photos which will have been misidentified:
knowledge/prepare/photos/000068_jpg.rf.9b9cbf4a646084759cf497bda644590a.jpg has a false optimistic at (325, 273, 428, 346)
Evaluating knowledge/prepare/photos/000086_jpg.rf.28c7a99a2009feab19227107629024a9.jpg
Evaluating knowledge/prepare/photos/000085_jpg.rf.0c83a3b05ee4a9753194afb50f61f33f.jpg
Evaluating knowledge/prepare/photos/000003_jpg.rf.6c0f89788e0aa72792c150a98abd7378.jpg
Evaluating knowledge/prepare/photos/000053_jpg.rf.e40407e687da7a73c86c2714898372b4.jpg
Evaluating knowledge/prepare/photos/000041_jpg.rf.872d29dbeb93f1e38d8212e6d8eaacb9.jpg
Evaluating knowledge/prepare/photos/000003_jpg.rf.f9f5224a16e4175bb5302c96d0cd1d40.jpg
knowledge/prepare/photos/000003_jpg.rf.f9f5224a16e4175bb5302c96d0cd1d40.jpg has a false optimistic at (68, 267, 605, 514)
…The report is saved as a markdown file. Right here’s a preview of the file exhibiting a number of the outcomes from our evaluation:
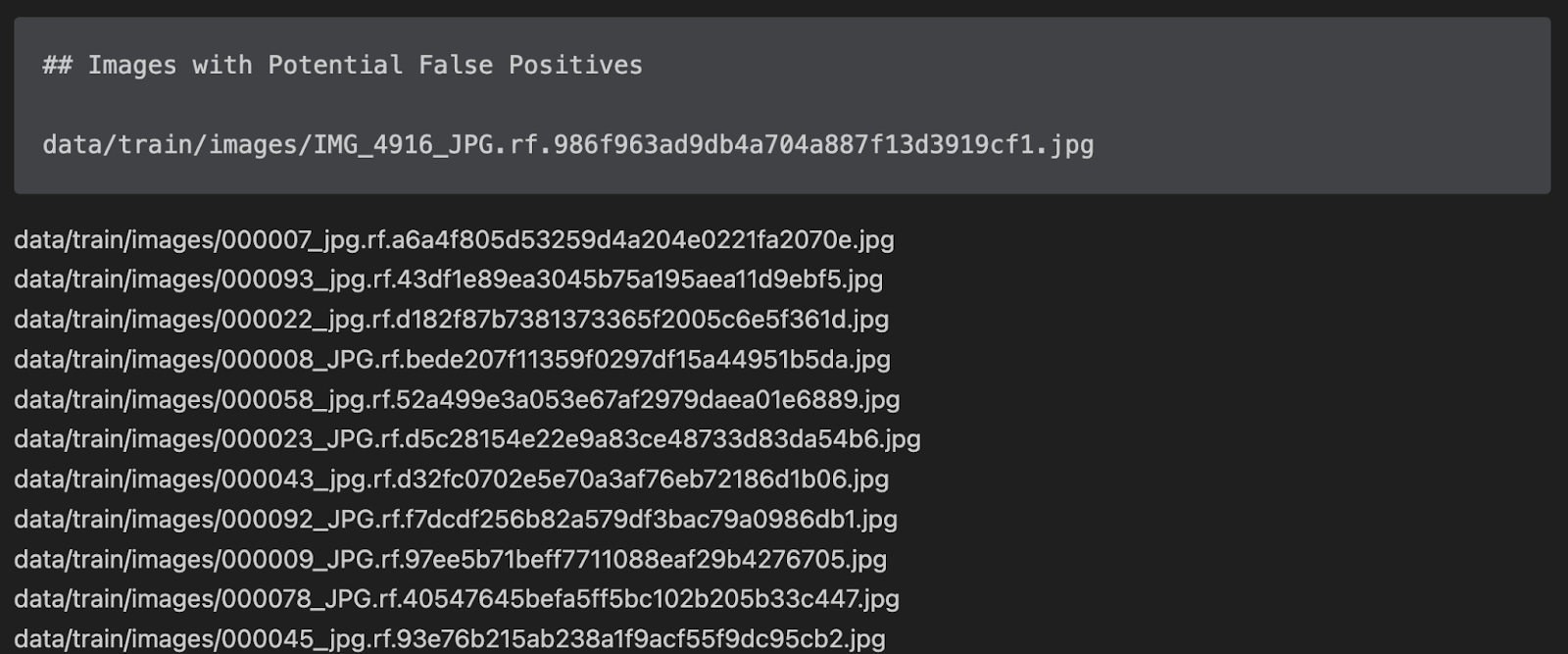
Let’s open up one in all these recordsdata in Roboflow Annotate to see the annotations:
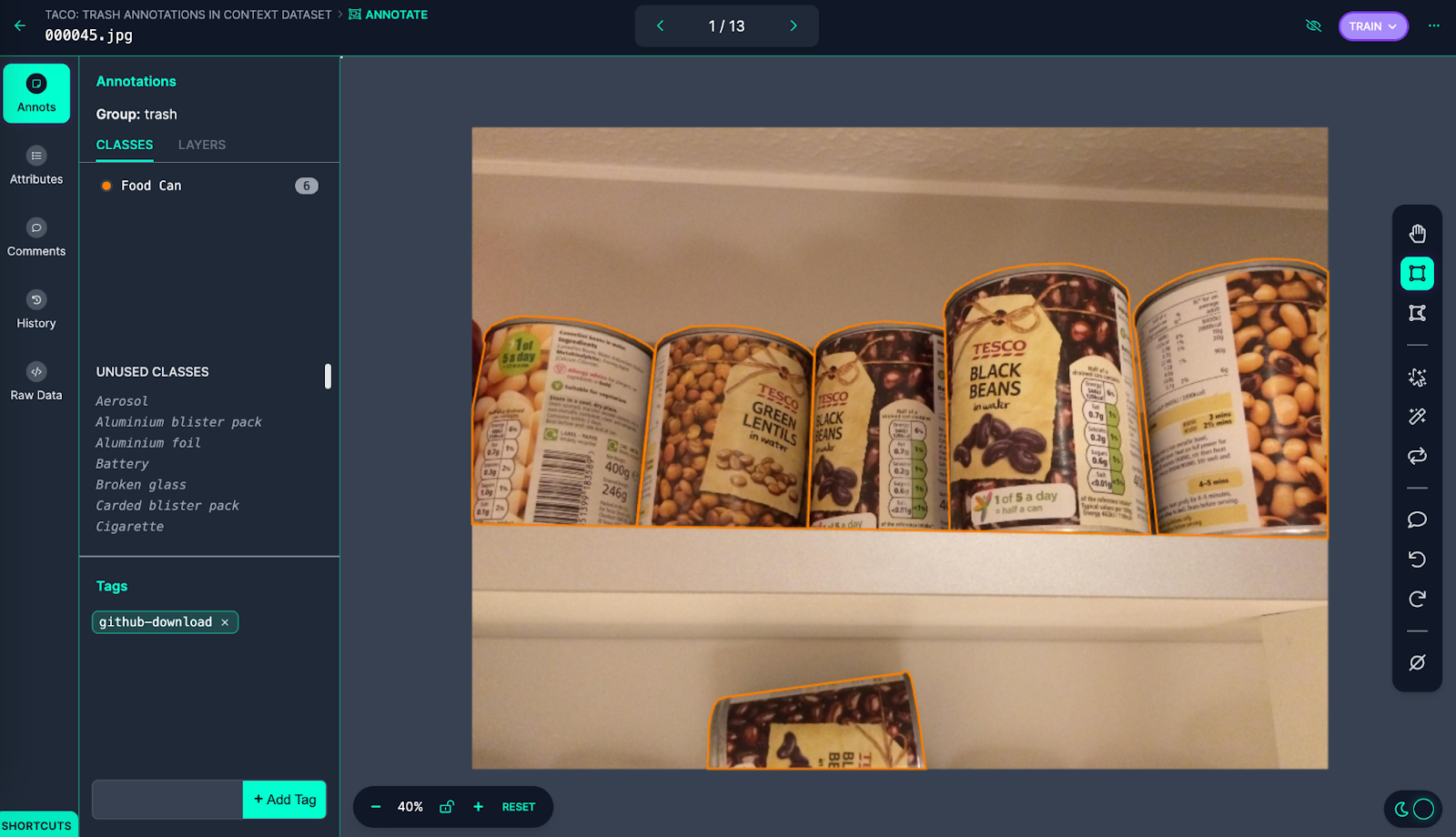
These photos have been labeled as “Meals Can” within the annotation group “trash”. With that stated, the photographs don’t appear like trash; the cans are on a shelf in what seems to be a kitchen and there’s no signal that any of the cans have been opened. Whereas TACO is a dataset of trash annotations in context, the cans are misplaced: they’re in an surroundings the place the objects should not trash.
On this case “null” could also be a extra acceptable annotation since there aren’t any visible indicators the gadgets are trash.
With that stated, this picture can be an excellent candidate for artificial knowledge era: the background may very well be modified to be extra acceptable (i.e. cans on the bottom, or cans on grass) to assist the mannequin higher perceive cans in context. We might then use the brand new artificial knowledge to coach an up to date model of our mannequin.
Relying in your use case and the surroundings your mannequin will function in, the motion you are taking when discovering outlier knowledge is as much as your discretion. As an example, if this mannequin will at all times be deployed in environments the place litter is current, this explicit instance could be ignored. However, if you will be figuring out trash in different contexts (i.e. a kitchen), this picture must be marked as null.
As a result of we specified the `–generate_pdf` flag, we even have a PDF model of the evaluation markdown file. That is saved in a file known as `report.pdf`.
Conclusion
On this information, now we have used CLIP to determine annotations which will embrace incorrect labels in a picture dataset.
Operating this analysis on a pc imaginative and prescient dataset will assist guarantee the standard of your dataset, thereby aiding to maximise the efficiency of the fashions you prepare in your dataset.
We advocate working an analysis earlier than coaching new variations of a mannequin the place new photos have been added to assist guarantee incorrect annotations don’t affect the standard of subsequent educated fashions.
Now you’ve gotten the instruments it’s good to determine mislabelled photos in your datasets.


