Introduction
Embeddings have develop into a scorching matter within the discipline of pure language processing (NLP) and are gaining traction in laptop imaginative and prescient. This weblog submit will discover using embeddings in laptop imaginative and prescient by analyzing picture clusters, assessing dataset high quality, and figuring out picture duplicates.
We created a Google Colab pocket book that you may run in a separate tab whereas studying this weblog submit, permitting you to experiment and discover the ideas mentioned in real-time. Let’s dive in!
Clustering MNIST photographs utilizing pixel brightness
Earlier than we leap to examples involving OpenAI CLIP embeddings, let’s begin with a much less complicated dataset— clustering MNIST photographs primarily based on the brightness of their pixels.

The MNIST dataset consists of 60,000 grayscale photographs of handwritten digits, every with a measurement of 28×28 pixels. Since every pixel in a grayscale picture might be described by a single worth, we’ve 784 values (or options) describing every picture. Our objective is to make use of t-SNE and UMAP to cut back the variety of dimensions to 3, permitting us to show clusters of photographs in 3D house.
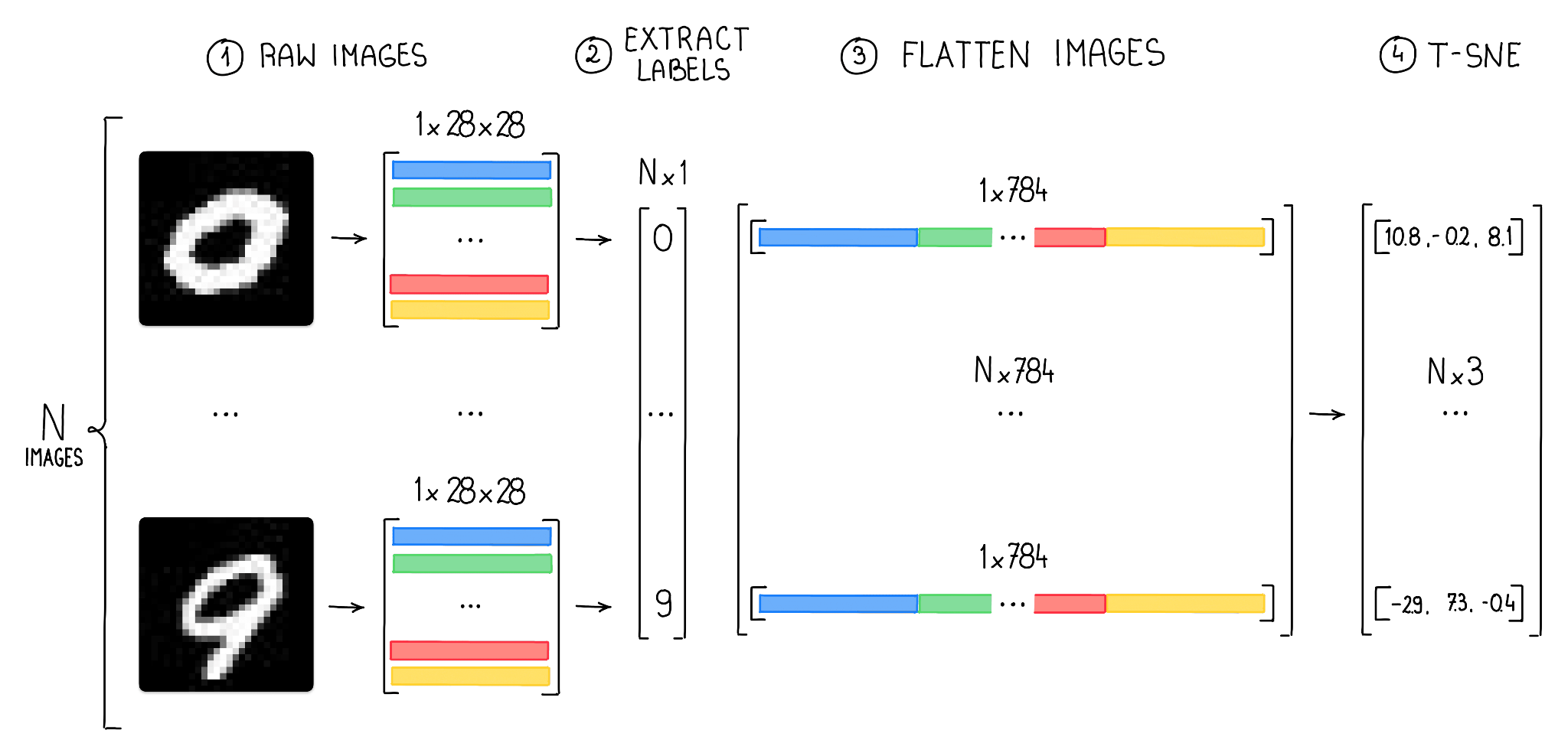
To perform this, we first have to load photographs of every class and reshape the information right into a format that may be consumed by t-SNE (a 2D NumPy array with 784 options).
Visualizing Excessive-dimensional Knowledge
Visualizing and dealing with high-dimensional information might be difficult, because it turns into more and more troublesome to know the underlying construction and relationships within the information. Dimensionality discount methods, resembling t-SNE and UMAP, are important instruments for simplifying these complicated datasets, making them extra manageable and simpler to interpret.

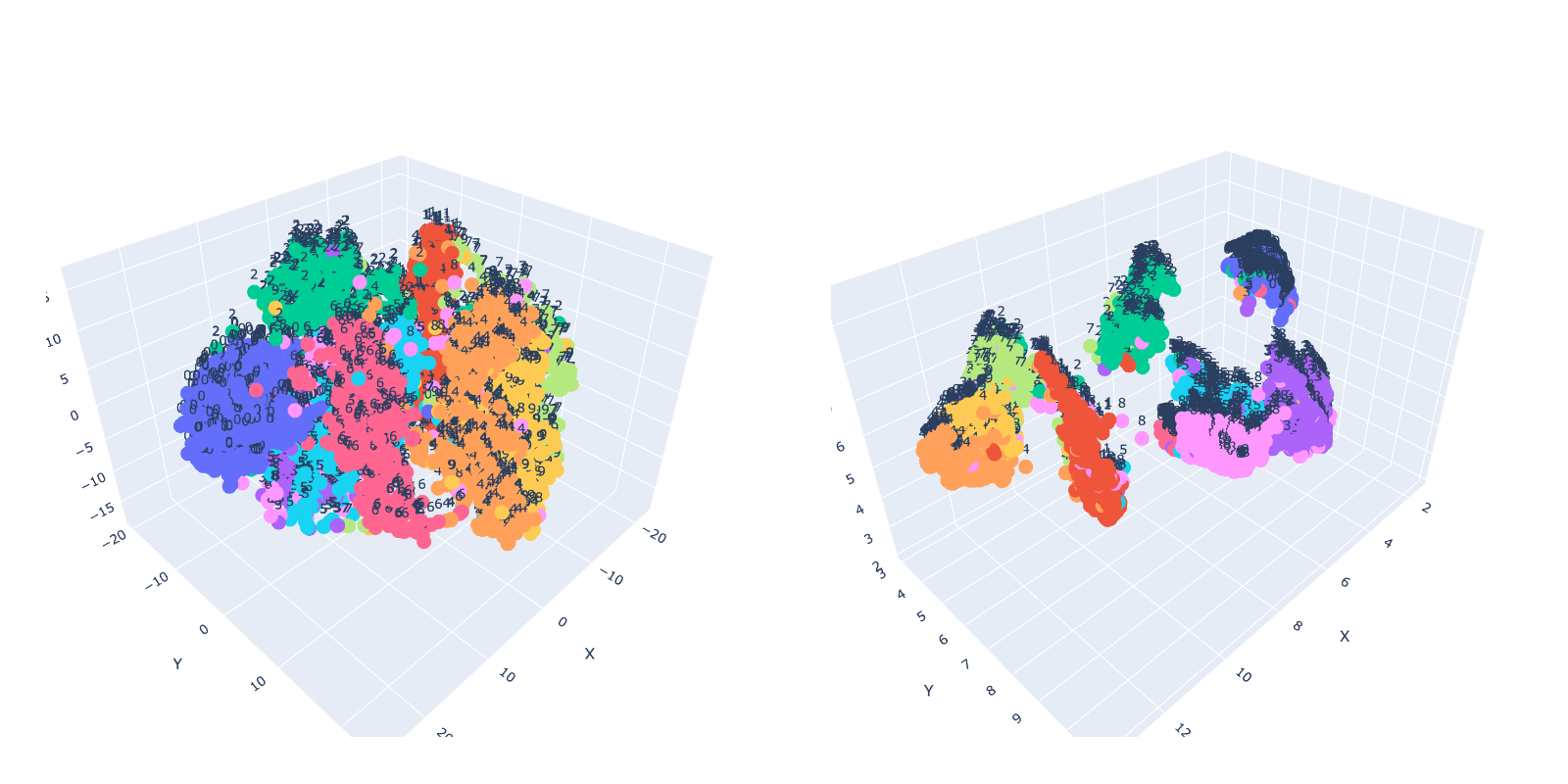
Two photographs depicting the quantity 6 in an identical writing type shall be represented as factors in a lower-dimensional house which are shut to one another. It is because these methods intention to protect the relative similarity between information factors within the unique high-dimensional house. Because of this, factors representing comparable photographs shall be positioned close to one another. Conversely, photographs exhibiting totally different numbers, like 1 and eight, shall be represented by factors which are farther aside within the reduced-dimensional house.
t-SNE vs. UMAP
t-SNE and UMAP are each common methods for dimensionality discount and visualization of high-dimensional information. Nevertheless, there are some key variations between them. UMAP is thought for its computational effectivity and scalability, which permits it to deal with bigger datasets extra shortly in comparison with t-SNE. In our easy take a look at utilizing 5,000 photographs, UMAP was almost 3x quicker than t-SNE.
from sklearn.manifold import TSNE projections = TSNE(n_components = 3).fit_transform(prepare)from umap import UMAP projections = umap.UMAP(n_components=3).fit_transform(prepare)Moreover, UMAP is designed to protect the worldwide construction higher, whereas t-SNE primarily focuses on sustaining native relationships amongst information factors. In observe, the selection between t-SNE and UMAP might rely upon the particular wants and constraints of the duty at hand, resembling dataset measurement, computational sources, and the specified stability between native and international construction preservation.
Utilizing OpenAI CLIP to Analyze Dataset Class Distribution
Pixel brightness is an acceptable function for the MNIST dataset as a result of it contains easy, grayscale photographs of handwritten digits, the place the distinction between the digit and the background is essentially the most essential side. Nevertheless, for normal photographs relying solely on pixel brightness is inadequate. These photographs have tens of millions of pixels with various shade channels and include rather more complicated and numerous visible info. Utilizing pixel brightness as the first function in such instances would fail to seize the intricate particulars, textures, and relationships amongst objects within the picture.
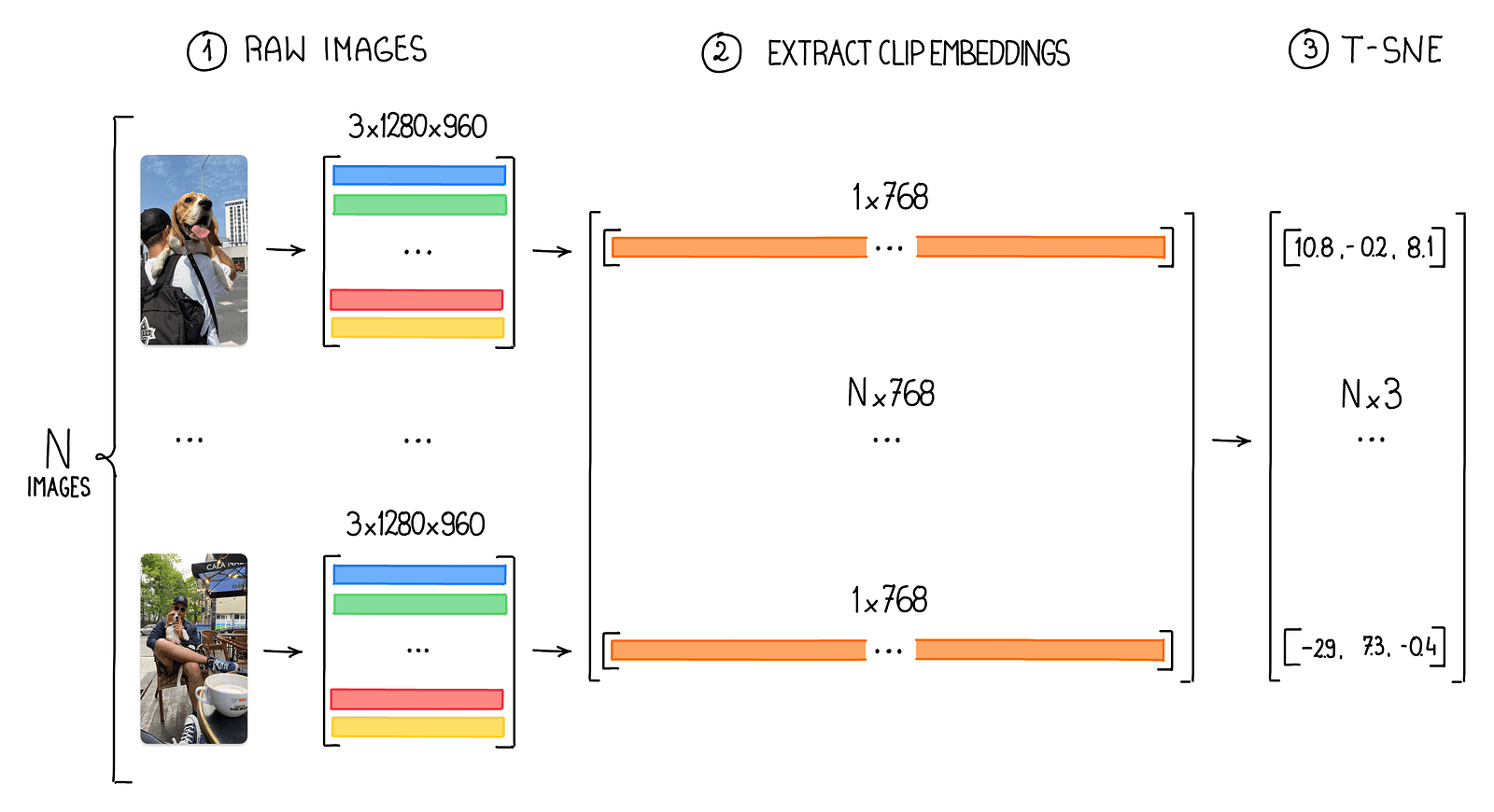
CLIP embeddings deal with this subject by offering a extra summary and compact illustration of photographs, successfully encoding high-level visible and semantic info. These embeddings are generated by a strong neural community educated on a various vary of photographs, enabling it to be taught significant options from complicated, real-world images. Through the use of CLIP embeddings, we will effectively work with high-resolution photographs whereas preserving their important visible and semantic traits for numerous laptop imaginative and prescient duties. You may get CLIP embeddings utilizing the CLIP python package deal or instantly from Roboflow search.
import clip machine = "cuda" if torch.cuda.is_available() else "cpu"
mannequin, preprocess = clip.load("ViT-B/32", machine=machine) image_path = "path/to/your/picture.png"
picture = preprocess(Picture.open(image_path)).unsqueeze(0).to(machine) with torch.no_grad(): embeddings = mannequin.encode_image(picture)Establish Comparable Photographs with Embeddings
Embeddings may also be used to determine comparable or close-to-similar photographs. By evaluating the vectors of the embeddings, we will measure the similarity between two photographs utilizing the cosine worth. This worth, which ranges from -1 to 1, gives a quantitative illustration of picture similarity. Within the context of laptop imaginative and prescient vector evaluation, a cosine worth of 1 signifies a excessive diploma of similarity, a worth of -1 signifies dissimilarity and a worth of Zero suggests orthogonality, which means the photographs share no frequent options. By leveraging this perception, we will successfully determine and group comparable photographs primarily based on their cosine values whereas distinguishing these which are unrelated or orthogonal.
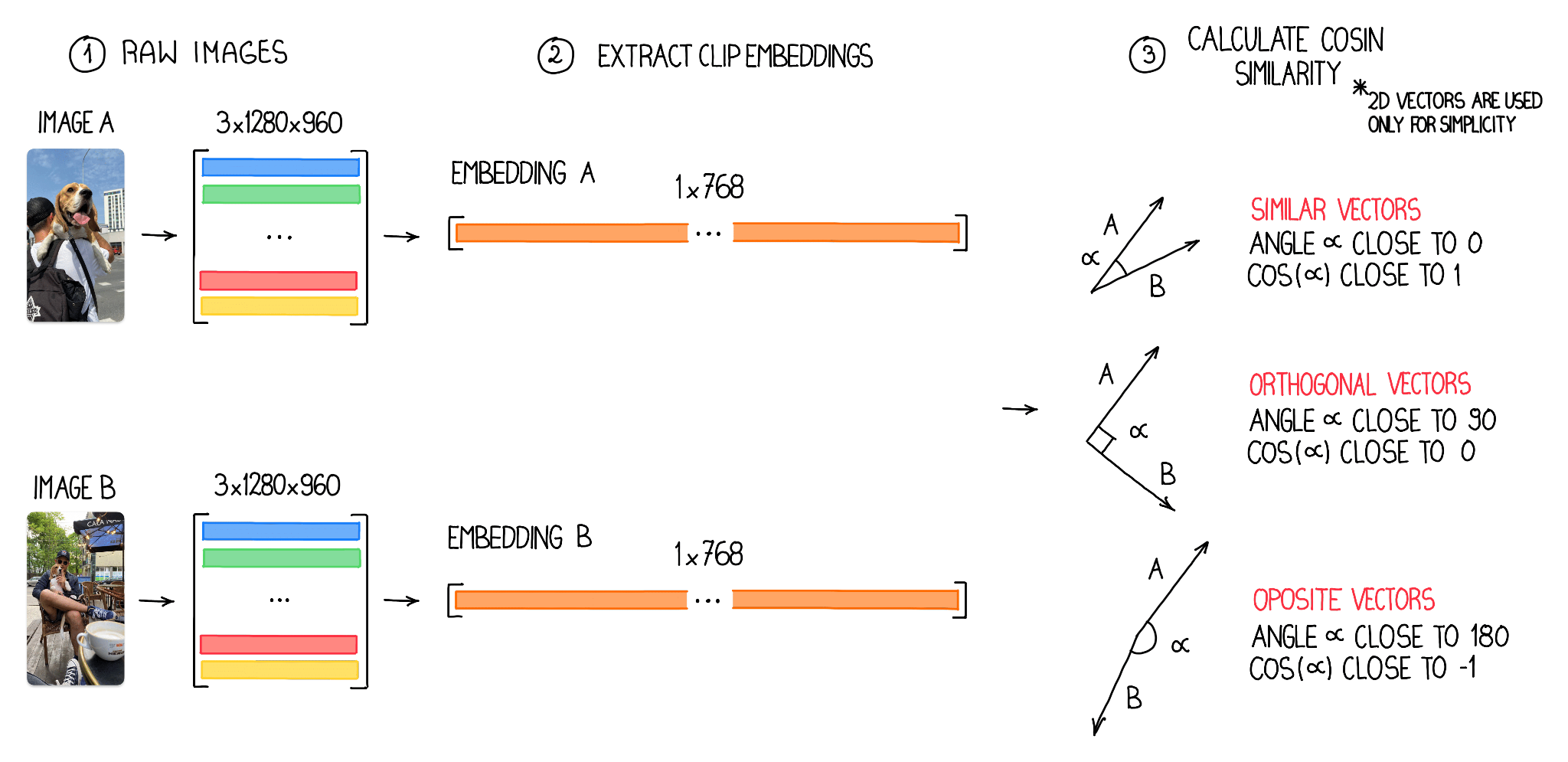
Within the technique of trying to find comparable photographs, we first construction picture embeddings right into a 2D NumPy array with dimensions N x M, the place N represents the variety of analyzed photographs and M signifies the dimensions of particular person embedding vectors — in our case 768. Earlier than computing the cosine similarity, it’s important to normalize these vectors.
Vector normalization is the method of scaling a vector to have a unit size, which ensures that the cosine similarity measures solely the angular distance between vectors and never their magnitudes. With the normalized vectors, we will effectively calculate the cosine similarity for all picture pairs utilizing vectorization, enabling us to determine and group comparable photographs successfully.

Conclusion
OpenAI CLIP embeddings are an extremely highly effective software in your Laptop Imaginative and prescient arsenal. As we transfer ahead, we plan to discover extra use instances, take a look at new fashions (apart from CLIP), and delve deeper into the world of embeddings that can assist you unlock much more potentialities within the fast-paced discipline of laptop imaginative and prescient. Keep tuned for future posts the place we’ll proceed to push the boundaries and unveil new methods to harness the facility of embeddings.


