Over the previous few years, AI and laptop imaginative and prescient researchers and practitioners have constructed highly effective mannequin architectures that work throughout a single modality. As an illustration, fashions like YOLO absorb a picture and generate predictions from the picture; GPT-3.5 takes in textual content and generates textual content.
There’s curiosity in constructing fashions that may mix a number of totally different modalities, generally known as multimodal fashions. We’ve got taken steps on this path with fashions like DALL-E, which might settle for a textual content immediate and generate a picture, or Grounding DINO, which takes a textual content immediate and generates bounding packing containers. With that mentioned, these fashions cross two modalities; within the aforementioned examples, textual content and picture modalities are mixed.
ImageBind, a brand new embedding mannequin by Meta Analysis, is pioneering an method to AI embeddings that lets you encode data throughout many various modalities, from pictures to textual content to audio to depth data. These modalities, which might historically be in their very own fashions, are mixed right into a single area, enabling varied use instances from superior semantic search to new methods of interacting with fashions.
On this information, we’re going to debate:
- What’s ImageBind?
- How does ImageBind work?
- What are you able to do with ImageBind?
- How one can get began with ImageBind
With out additional ado, let’s get began!
What’s ImageBind?
ImageBind, launched in Might 2023 by Meta Analysis, is an embedding mannequin that mixes knowledge from six modalities: pictures and video, textual content, audio, thermal imaging, depth, and IMUs, which include sensors together with accelerometers and orientation displays.
Utilizing ImageBind, you may present knowledge in a single modality – for instance, audio – and discover associated paperwork in several modalities, reminiscent of video.
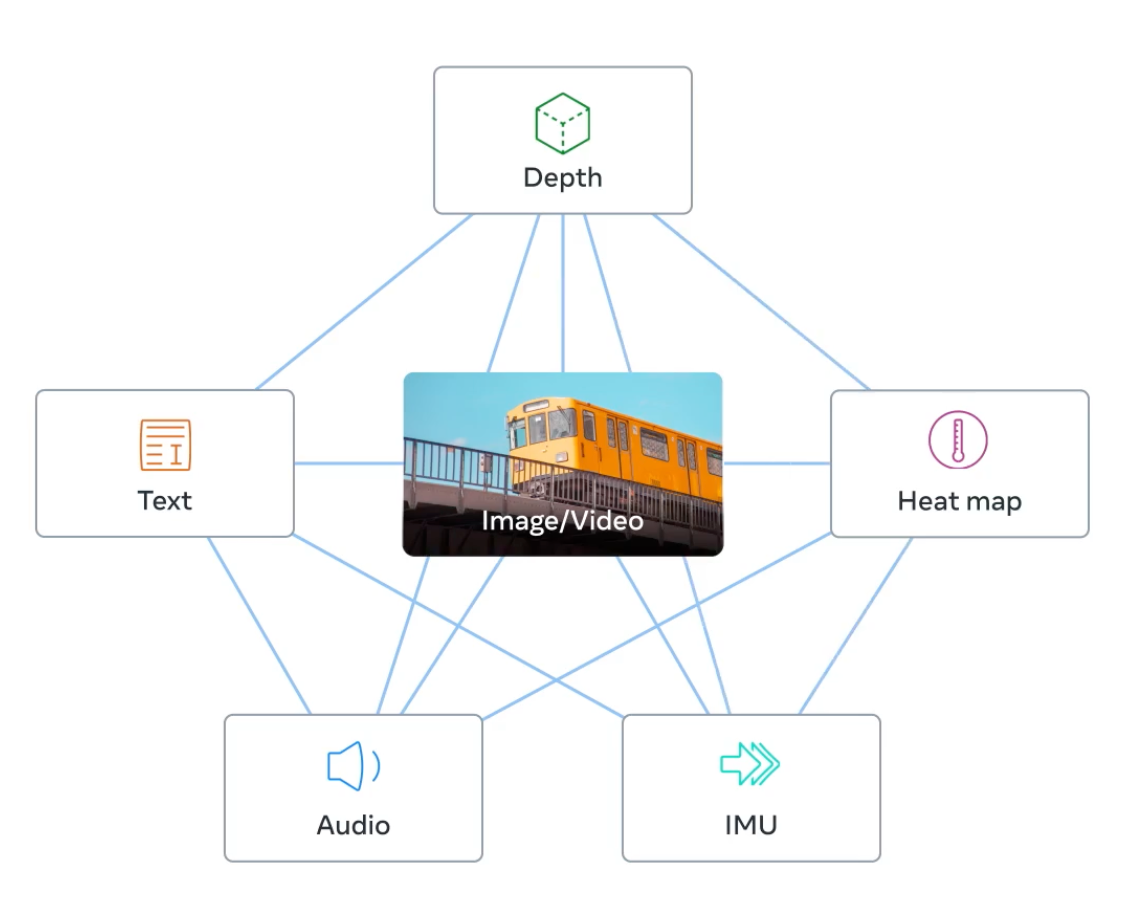
By means of ImageBind, Meta Analysis has proven that knowledge from many modalities could be mixed in the identical embedding area, permitting richer embeddings. That is in distinction to earlier approaches, the place an embedding area might embrace knowledge from one or two modalities. Later on this submit, we’ll speak concerning the sensible purposes of the ImageBind embeddings.
As of scripting this submit, ImageBind follows a sequence of pioneering new open supply fashions launched by Meta Analysis with makes use of in laptop imaginative and prescient. This contains the Phase Something Mannequin that set a brand new normal for zero-shot picture segmentation, and DINOv2, one other zero-shot laptop imaginative and prescient mannequin.
How Does ImageBind Work?
ImageBind was skilled with pairs of knowledge. Every pair mapped picture knowledge – together with movies – to a different modality, and the mixed knowledge was used to coach a big embedding mannequin. As an illustration, image-audio pairings and image-thermal pairings have been used. ImageBind discovered that options for various modalities may very well be discovered utilizing the picture knowledge used of their coaching.
A notable conclusion from ImageBind is that pairing pictures with one other modality, then combining the ends in the identical embedding area, is adequate to create a multi-modal embedding mannequin. Beforehand, one would want to have separate fashions that mapped totally different modalities collectively.
The embeddings from ImageBind could be mixed with different fashions to immediately leverage generative AI fashions alongside ImageBind. Within the ImageBind paper, Meta Analysis notes that they use a pre-trained DALLE-2 diffusion mannequin (personal) and changed the immediate embeddings with audio embeddings from ImageBind. This enabled the researchers to generate pictures utilizing DALLE-2 immediately with speech, with out an middleman mannequin (i.e. speech-to-text).
What Can You Do With ImageBind?
Like all embedding fashions, there are lots of potential use instances for ImageBind. On this part, we’re going to speak about three major use instances for ImageBind: data retrieval, zero-shot classification, and connecting the output of ImageBind to different fashions.
Data Retrieval
One can construct an data retrieval system that traverses modalities with ImageBind. To take action, one would embed knowledge in supported modalities – reminiscent of video, depth knowledge, and audio – after which create a search system that embeds a question in any modality and retrieves associated paperwork.
You would have a search engine that permits you to add a photograph and reveals you the entire audio supplies related to that picture. One instance situation the place this could be helpful is in birding. A nature fanatic might enter a hen name that they hear and the search engine might return the closest picture paperwork it has saved. Inversely, the fanatic might take a photograph of a hen and retrieve an audio clip with its name.
Meta analysis printed an interactive playground to accompany the paper that reveals data retrieval throughout totally different modalities.
Classification
ImageBind embeddings can be utilized for zero-shot classification. In zero-shot classification, a bit of knowledge is embedded and fed to the mannequin to retrieve a label that corresponds with the contents of the info. Within the case of ImageBind, you may classify audio, pictures, and data within the different supported modalities. Additional, ImageBind helps few-shot classification, the place a couple of examples of knowledge earlier than classification is run.
ImageBind realized “features of roughly 40 % accuracy in top-1 accuracy on ≤four-shot classification” when in comparison with Meta’s self-supervised and supervised AudioMAE fashions, in line with Meta’s abstract weblog submit printed to accompany the venture.
Listed below are the outcomes of ImageBind’s zero-shot classification capabilities:
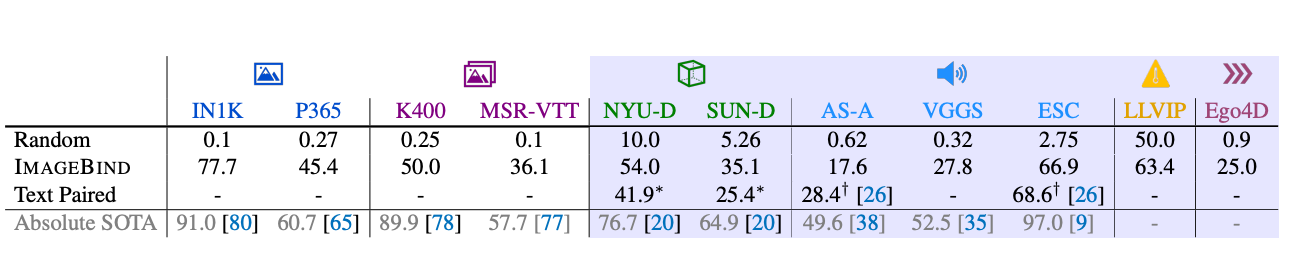
From this desk, we are able to see ImageBind achieves robust efficiency throughout a spread of datasets from totally different modalities. Whereas ImageBind doesn’t obtain scores in extra of the “Absolute SOTA” rating, Meta notes the fashions that obtain these scores usually use extra supervision and different options.
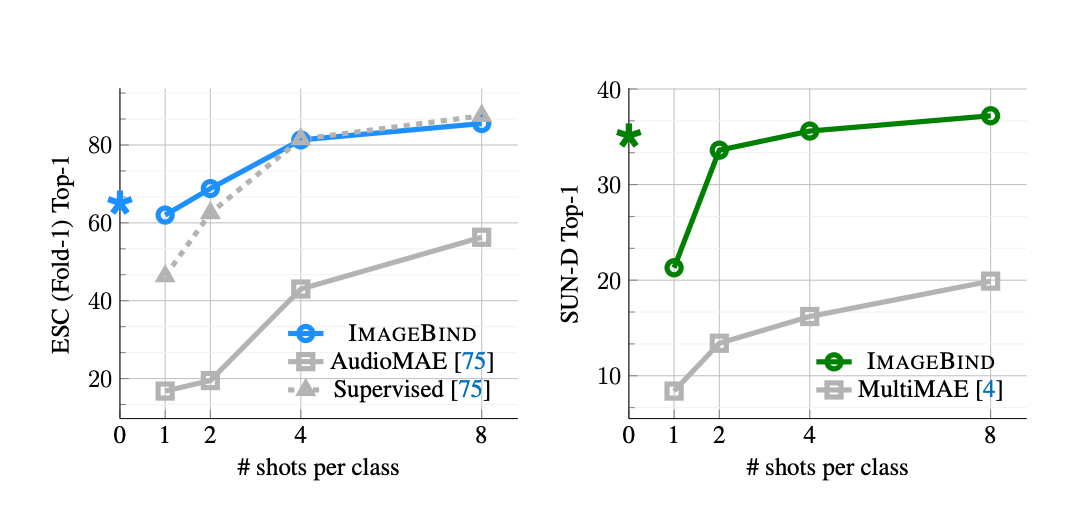
With few-shot classification, ImageBind discovered robust outcomes when in comparison with AudioMAE (supervised and unsupervised) and MultiMAE:
Combining Modalities for New Functions
Meta experimented with utilizing ImageBind embeddings to permit for audio-to-image era with DALLE-2. Whereas this was achieved utilizing a non-public mannequin, the experiment reveals the potential of utilizing ImageBind embeddings for generative AI and augmented object detectors.
With ImageBind, one can present a number of potential inputs for a generative AI mannequin – audio, video, textual content – with out having separate translation logic, reminiscent of an middleman mannequin to transform the enter knowledge into textual content to be used with a textual content embedding mannequin.
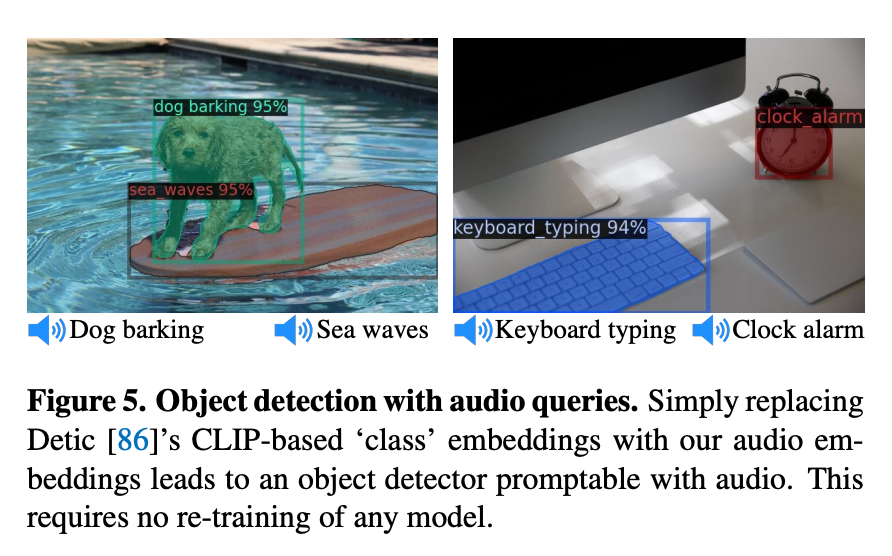
In one other instance, Meta used audio embeddings calculated utilizing ImageBind with Detic, an object detection mannequin. Meta changed the CLIP textual content embeddings with their audio embeddings. The consequence was an object detection mannequin that might absorb audio knowledge and return bounding packing containers for detections related to the audio immediate.
The way to Get Began
To experiment with retrieving pictures throughout totally different modalities, you need to use the ImageBind playground printed by Meta analysis. This playground offers a couple of pre-made examples that present data retrieval in motion.
ImageBind is open supply. An “imagebind_huge” checkpoint is offered to be used with the venture. Within the venture README, there are examples displaying learn how to feed textual content, picture, and audio knowledge into ImageBind. This code is an effective way to get began with ImageBind. The mannequin and accompanying weights are licensed beneath a CC-BY-NC 4.zero license.
With the repository, you may construct your personal classifiers and data retrieval techniques that use ImageBind. Though no instruction is given for this within the README, you can too experiment with utilizing the ImageBind embeddings with different fashions, reminiscent of in Meta’s instance of utilizing audio embeddings with Detic.
Conclusion
ImageBind is the newest in a spread of vision-related fashions printed by Meta Analysis, following on from publications earlier this 12 months together with DINOv2 and Phase Something.
ImageBind creates a joint embedding area that encodes data from six modalities, demonstrating that knowledge from totally different modalities doesn’t require separate embeddings for every modality.
The modal can be utilized for superior data retrieval throughout modalities and zero- and few-shot classification. The embeddings, when mixed with different fashions, for object detection and generative AI.



