Deep neural networks have change into more and more in style for fixing a variety of duties, from figuring out objects in photos utilizing object detection fashions to producing textual content utilizing GPT fashions. Nonetheless, deep studying fashions are sometimes giant and computationally costly, making them tough to deploy on resource-constrained gadgets equivalent to cell phones or embedded programs. Information distillation is a way that addresses this difficulty by compressing a big, advanced neural community right into a smaller, easier one whereas sustaining its efficiency.
On this weblog submit, we’ll discover:
- What’s information distillation?
- How does information distillation work?
- What are the several types of information distillation?
Let’s get began!
What’s Information Distillation?
Information distillation is used to compress a fancy and enormous neural community right into a smaller and easier one, whereas nonetheless retaining the accuracy and efficiency of the resultant mannequin. This course of entails coaching a smaller neural community to imitate the conduct of a bigger and extra advanced “trainer” community by studying from its predictions or inside representations.
The purpose of information distillation is to scale back the reminiscence footprint and computational necessities of a mannequin with out considerably sacrificing its efficiency. Information distillation was first launched by Hinton et al. in 2015. Since then, the thought has gained important consideration within the analysis neighborhood.
The idea of information distillation is predicated on the statement {that a} advanced neural community not solely learns to make correct predictions but additionally learns to seize significant and helpful representations of the information. These representations are realized by the hidden layers of the neural community and might be regarded as “information” acquired by the community throughout the coaching course of.
Within the context of information distillation, the “information” captured by the trainer community is transferred to the scholar community by means of a means of supervised studying. Throughout this course of, the scholar community is skilled to reduce the distinction between its predictions and the predictions of the trainer community on a set of coaching examples.
The instinct behind this method is that the trainer community’s predictions are primarily based on a wealthy and complicated illustration of the enter knowledge, which the scholar community can be taught to copy by means of the distillation course of.
One latest instance of information distillation in observe is Stanford’s Alpaca. This mannequin, fine-tuned from LLaMA, realized information from 52,000 directions that have been fed to OpenAI’s text-davinci-003 mannequin. Stanford reported that the Alpaca mannequin “behaves qualitatively equally to OpenAI’s text-davinci-003, whereas being surprisingly small and simple/low cost to breed (<600$).”
How Does Information Distillation Work?
Information distillation entails two essential steps: coaching the trainer community and coaching the scholar community.
Throughout step one, a big and complicated neural community, or the trainer community, is skilled on a dataset utilizing a normal coaching process. As soon as the trainer community has been skilled, it’s used to generate “gentle” labels for the coaching knowledge, that are chance distributions over the courses as a substitute of binary labels. These gentle labels are extra informative than exhausting labels and seize the uncertainty and ambiguity within the predictions of the trainer community.
Within the second step, a smaller neural community, or the scholar community, is skilled on the identical dataset utilizing the gentle labels generated by the trainer community. The coed community is skilled to reduce the distinction between its personal predictions and the gentle labels generated by the trainer community.
The instinct behind this method is that the gentle labels comprise extra details about the enter knowledge and the trainer community’s predictions than the exhausting labels. Due to this fact, the scholar community can be taught to seize this extra info and generalize higher to new examples.
As proven under, a small “scholar” mannequin learns to imitate a big “trainer” mannequin and leverage the information of the trainer to acquire comparable or larger accuracy.
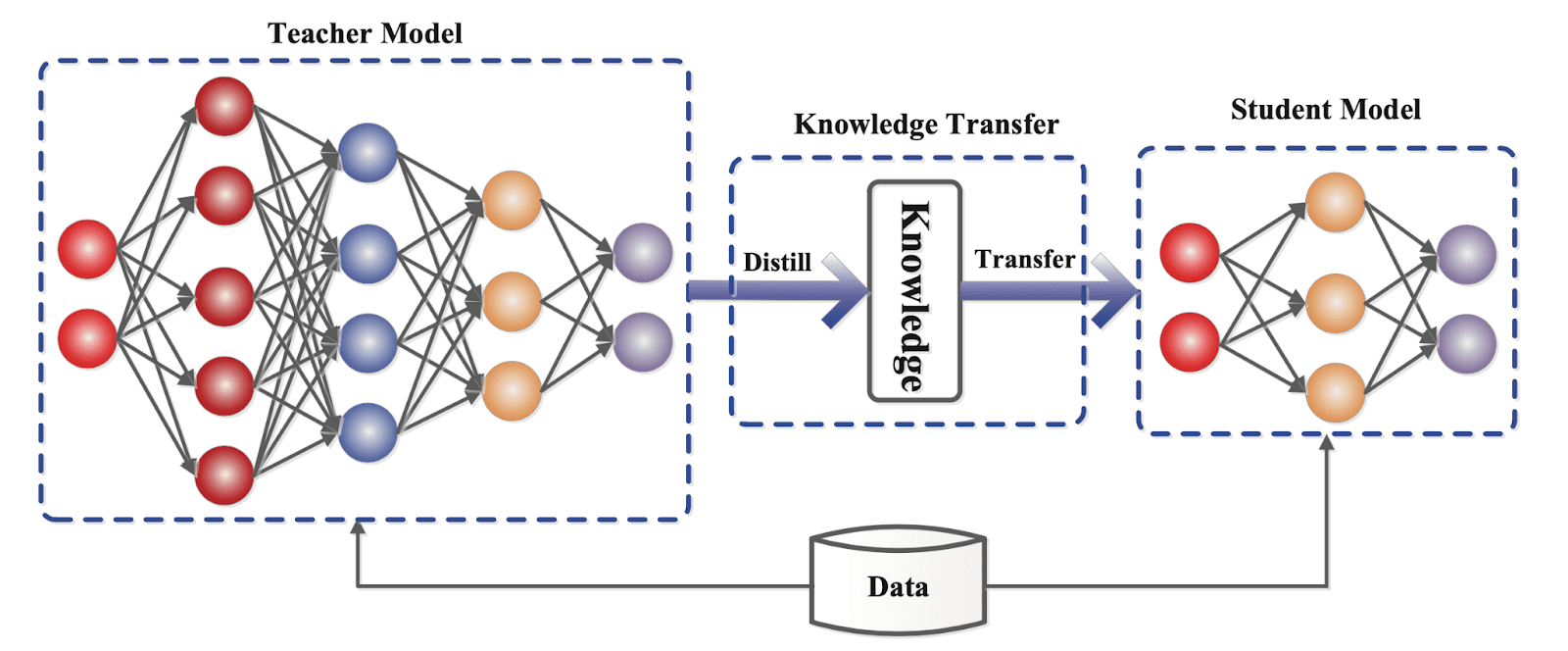
Information Distillation Use Circumstances
One of many key advantages of information distillation is that it could possibly considerably cut back the reminiscence and computational necessities of a mannequin whereas sustaining comparable efficiency to the bigger mannequin.
That is significantly necessary for functions that require fashions to run on resource-constrained gadgets equivalent to cell phones, embedded programs, or Web of Issues (IoT) gadgets. By compressing a big and complicated mannequin right into a smaller and easier one, information distillation allows fashions to be deployed on these gadgets with out compromising their efficiency.
Distillation Information Sorts
Information distillation might be categorized into differing types relying on how the knowledge is gathered from the trainer mannequin.
Typically, there are three varieties of information distillation, every with a novel method to transferring information from the trainer mannequin to the scholar mannequin. These embody:
- Response-based distillation;
- Function-based distillation, and;
- Relation-based distillation.
On this part, we’ll focus on every sort of information distillation intimately and clarify how they work.
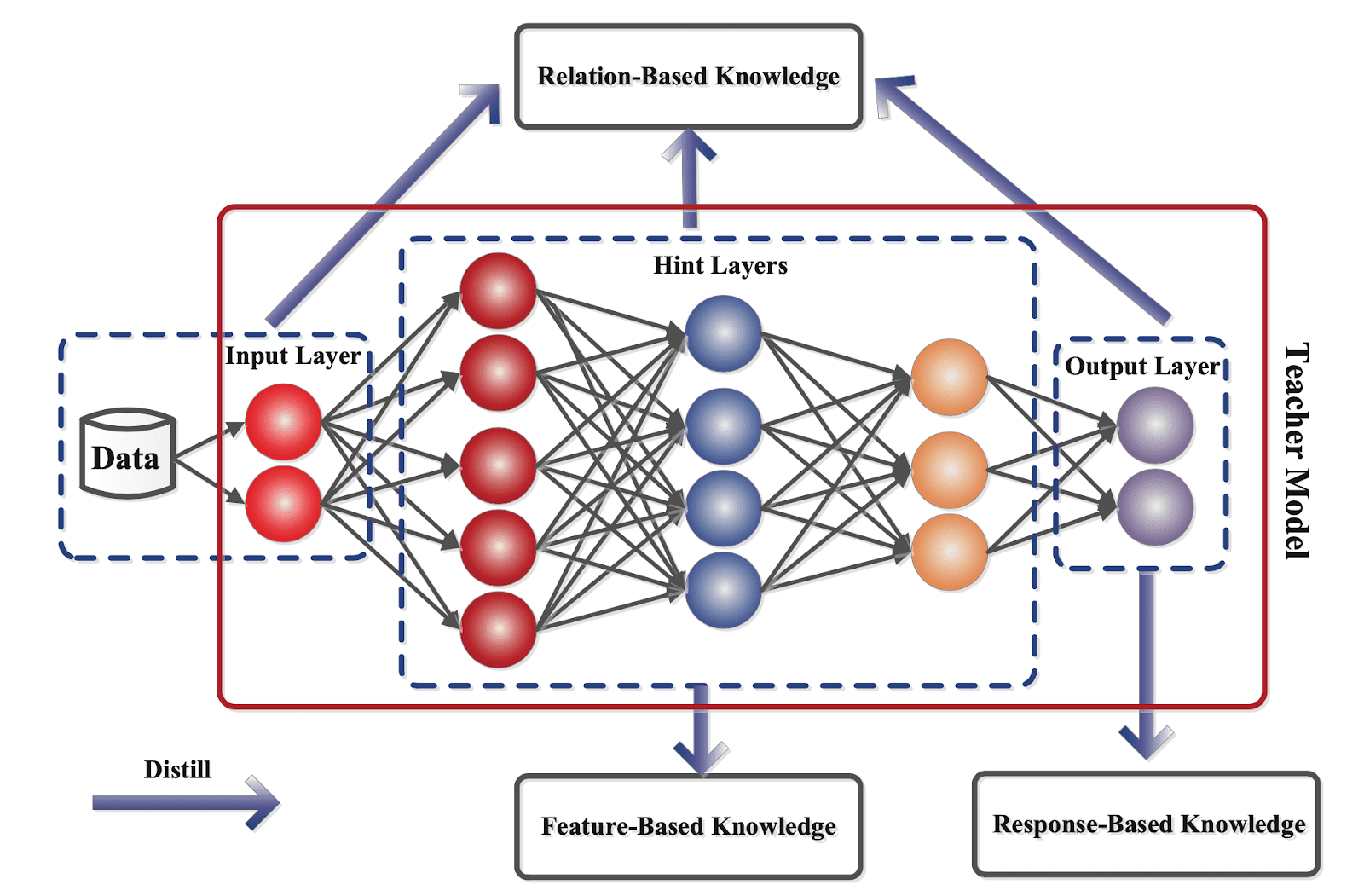
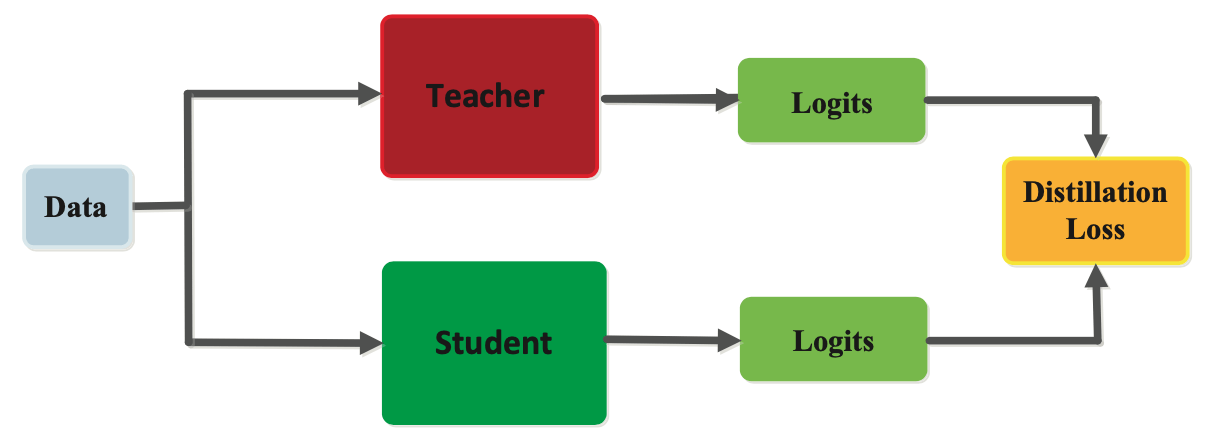
Response-based
In response-based information distillation, the scholar mannequin learns to imitate the predictions of the trainer mannequin by minimizing the distinction between predicted outputs. Through the distillation course of, the trainer mannequin generates gentle labels, that are chance distributions over the courses, for every enter instance. The coed mannequin is then skilled to foretell the identical gentle labels because the trainer mannequin by minimizing a loss perform that measures the distinction between their predicted outputs.
Response-based distillation is extensively utilized in numerous machine studying domains, together with picture classification, pure language processing, and speech recognition.
Response-based information distillation is especially helpful when the trainer mannequin has a lot of output courses, the place it could be computationally costly to coach a scholar mannequin from scratch. By utilizing response-based information distillation, the scholar mannequin can be taught to imitate the conduct of the trainer mannequin with out having to be taught the advanced determination boundaries that distinguish between all of the output courses.
One of many essential benefits of response-based information distillation is its ease of implementation. Since this method solely requires the trainer mannequin’s predictions and the corresponding gentle labels, it may be utilized to a variety of fashions and datasets.
Moreover, response-based distillation can considerably cut back the computational necessities of working a mannequin by compressing it right into a smaller and easier one.
Nonetheless, response-based information distillation has its limitations. For instance, this system solely transfers information associated to the trainer mannequin’s predicted outputs and doesn’t seize the interior representations realized by the trainer mannequin. Due to this fact, it might not be appropriate for duties that require extra advanced decision-making or characteristic extraction.
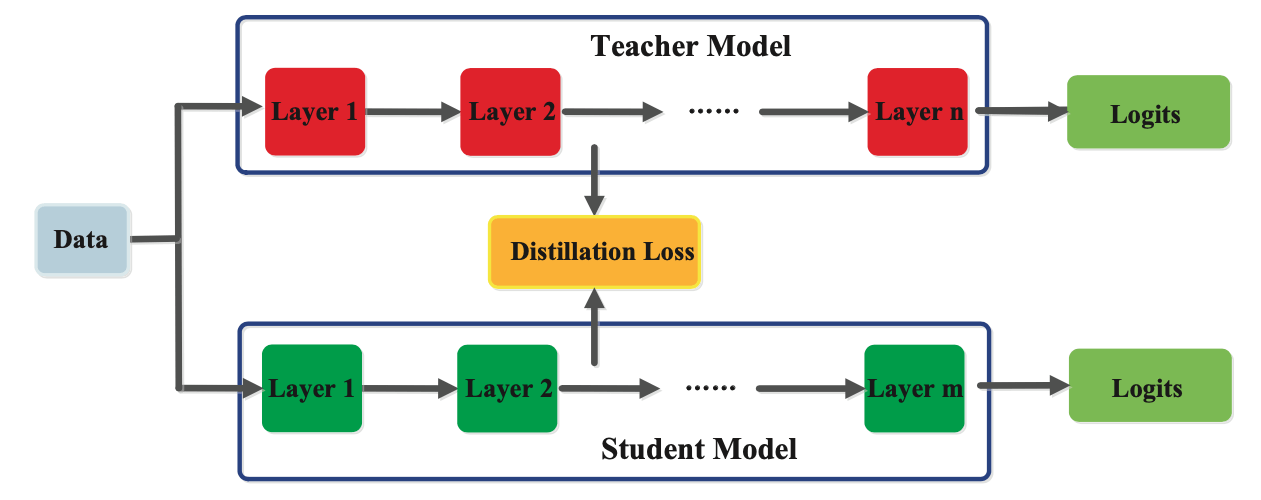
Function-based
In feature-based information distillation, the scholar mannequin is skilled to imitate the interior representations or options realized by the trainer mannequin. The trainer mannequin’s inside representations are extracted from a number of intermediate layers of the mannequin, that are then used as targets for the scholar mannequin.
Through the distillation course of, the trainer mannequin is first skilled on the coaching knowledge to be taught the task-specific options which are related to the duty at hand. The coed mannequin is then skilled to be taught the identical options by minimizing the space between the options realized by the trainer mannequin and people realized by the scholar mannequin. That is usually carried out utilizing a loss perform that measures the space between the representations realized by the trainer and scholar fashions, such because the imply squared error or the Kullback-Leibler divergence.
One of many essential benefits of feature-based information distillation is that it could possibly assist the scholar mannequin be taught extra informative and strong representations than it could be capable to be taught from scratch. It’s because the trainer mannequin has already realized probably the most related and informative options from the information, which might be transferred to the scholar mannequin by means of the distillation course of. Moreover, feature-based information distillation might be utilized to a variety of duties and fashions, making it a flexible method.
Nonetheless, feature-based information distillation has its limitations. This method might be extra computationally costly than different varieties of information distillation, because it requires extracting the interior representations from the trainer mannequin at every iteration. Moreover, a feature-based method might not be appropriate for duties the place the trainer mannequin’s inside representations will not be transferable or related to the scholar mannequin.
Relation-based
In relation-based distillation, a scholar mannequin is skilled to be taught a relationship between the enter examples and the output labels. In distinction to feature-based distillation, which focuses on transferring the intermediate representations realized by the trainer mannequin to the scholar mannequin, relation-based distillation focuses on transferring the underlying relationships between the inputs and outputs.
First, the trainer mannequin generates a set of relationship matrices or tensors that seize the dependencies between the enter examples and the output labels. The coed mannequin is then skilled to be taught the identical relationship matrices or tensors by minimizing a loss perform that measures the distinction between the connection matrices or tensors predicted by the scholar mannequin and people generated by the trainer mannequin.
One of many essential benefits of relation-based information distillation is that it could possibly assist the scholar mannequin be taught a extra strong and generalizable relationship between the enter examples and output labels than it could be capable to be taught from scratch. It’s because the trainer mannequin has already realized probably the most related relationships between the inputs and outputs from the information, which might be transferred to the scholar mannequin by means of the distillation course of.
Nonetheless, producing the connection matrices or tensors, particularly for giant datasets, might be computationally costly. Moreover, a relation-based method might not be appropriate for duties the place the relationships between the enter examples and the output labels will not be well-defined or tough to encode right into a set of matrices or tensors.
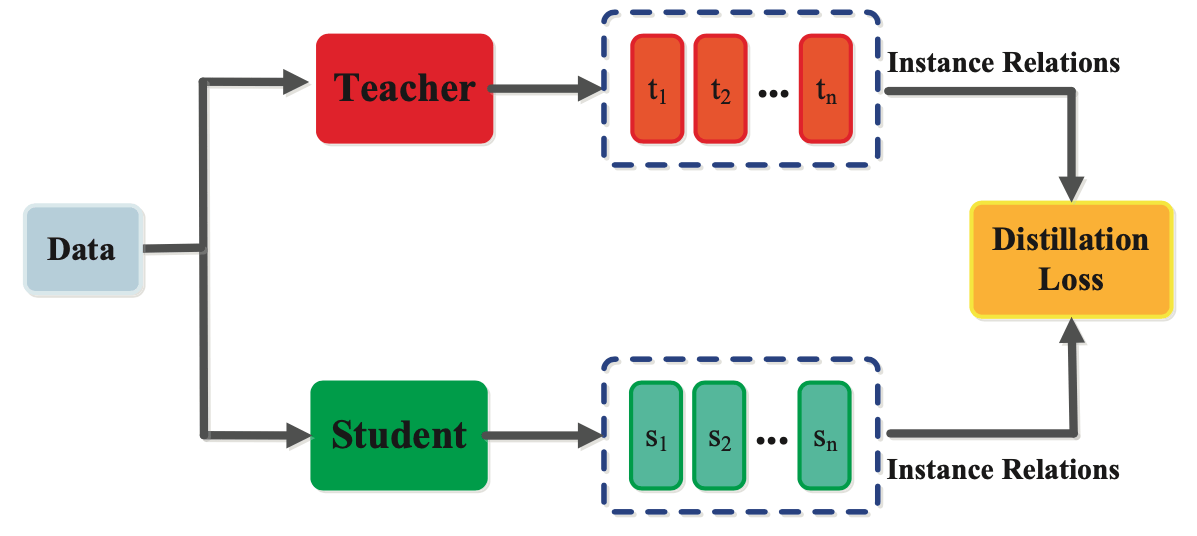
Distillation Information Coaching Strategies
There are three main strategies out there for coaching scholar and trainer fashions:
- Offline;
- On-line, and;
- Self Distillation.
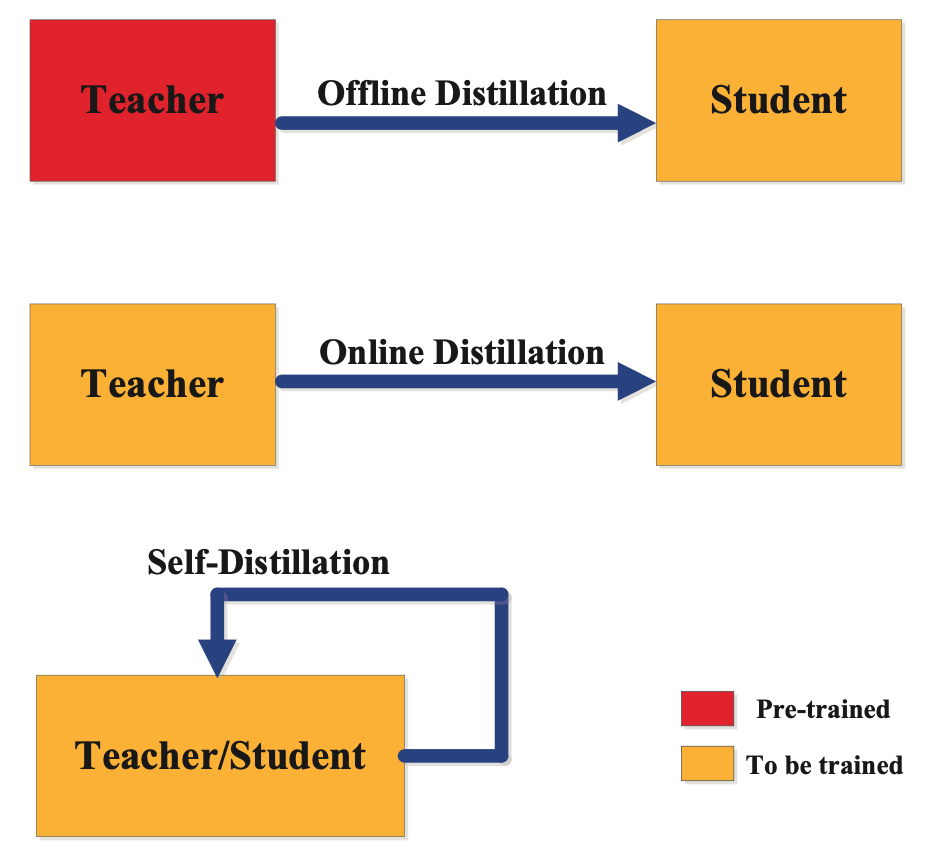
The suitable categorization of a distillation coaching technique will depend on whether or not the trainer mannequin is modified concurrently with the scholar mannequin, as proven within the determine under:
Offline Distillation
Offline Distillation is a well-liked information distillation technique by which the trainer community is pre-trained after which frozen. Through the coaching of the scholar community, the trainer mannequin stays fastened and isn’t up to date. This method is often utilized in many earlier information distillation strategies, together with the bottom paper by Hinton et al.
The principle focus of analysis on this discipline has been on enhancing the information switch mechanism in offline distillation, with much less consideration given to the design of the trainer community structure. This method has allowed for the switch of information from pre-trained and well-performing trainer fashions to scholar fashions, enhancing total mannequin efficiency.
On-line Distillation
On-line information distillation, also called dynamic or continuous distillation, is used to switch information from a bigger mannequin to a smaller one in a sequential or on-line method.
On this technique, the trainer mannequin is up to date constantly with new knowledge, and the scholar mannequin is up to date to mirror this new info. The method of on-line information distillation entails the trainer mannequin and the scholar mannequin being skilled concurrently. The trainer mannequin is up to date constantly as new knowledge turns into out there, and the scholar mannequin learns from the trainer’s output. The purpose is to have the scholar mannequin be taught from the trainer mannequin’s updates in real-time, which allows the scholar mannequin to constantly enhance its efficiency.
On-line information distillation usually entails a suggestions loop the place the trainer mannequin’s output is used to replace the scholar mannequin, and the scholar mannequin’s output is used to offer suggestions to the trainer mannequin. The suggestions is often within the type of an error sign, which signifies how nicely the scholar mannequin is performing in comparison with the trainer mannequin. The trainer mannequin then makes use of this suggestions to regulate its parameters and output new predictions.
One of many essential benefits of on-line information distillation is its means to deal with non-stationary or streaming knowledge. That is significantly helpful in functions equivalent to pure language processing, the place the distribution of the enter knowledge might change over time. By updating the trainer mannequin and the scholar mannequin in real-time, on-line information distillation allows the fashions to adapt to altering knowledge distributions.
Self Distillation
The traditional method to information distillation equivalent to Offline and On-line Distillation faces two essential challenges. First, the accuracy of the scholar mannequin is closely influenced by the selection of trainer mannequin. The very best accuracy trainer shouldn’t be essentially the most suitable choice for distillation. Secondly, scholar fashions typically can’t obtain the identical degree of accuracy as their academics, resulting in accuracy degradation throughout inference.
To deal with these points, the Self Distillation technique employs the identical community as each the trainer and scholar. This method entails attaching attention-based shallow classifiers on the intermediate layers of the neural community at completely different depths. Throughout coaching, the deeper classifiers act as trainer fashions and information the coaching of the scholar fashions utilizing a divergence metric-based loss on the outputs and L2 loss on the characteristic maps. Throughout inference, the extra shallow classifiers are dropped.
Distillation Information Algorithms
On this part, we’ll discover a few of the in style algorithms used for information distillation, a way for transferring information from a big mannequin to a smaller mannequin. Particularly, we’ll focus on three algorithms:
- Adversarial distillation;
- Multi-teacher distillation, and;
- Cross-modal distillation.
These algorithms allow scholar fashions to accumulate information from trainer fashions effectively, resulting in improved mannequin efficiency and decreased mannequin complexity. Let’s dive into every one.
Adversarial Distillation
Adversarial distillation makes use of adversarial coaching to enhance the efficiency of scholar fashions. On this method, a scholar mannequin is skilled to imitate the trainer mannequin’s output by producing artificial knowledge that’s tough for the trainer mannequin to categorise accurately.
The adversarial distillation algorithm consists of two phases of coaching. Within the first stage, the trainer mannequin is skilled on the coaching set to acquire the bottom reality labels. Within the second stage, the scholar mannequin is skilled on each the coaching set and the artificial knowledge generated by an adversarial community.
The adversarial community is skilled to generate samples that the trainer mannequin finds tough to categorise accurately, and the scholar mannequin is skilled to categorise these samples accurately. Throughout coaching, the adversarial community generates artificial knowledge by including small perturbations to the unique knowledge samples, making them difficult to categorise. The coed mannequin is then skilled to categorise each the unique and the artificial knowledge. By doing so, the scholar mannequin learns to generalize extra successfully and thus carry out higher on real-world knowledge.
The adversarial distillation algorithm has a number of benefits over conventional information distillation strategies. It’s extra strong to adversarial assaults, as the scholar mannequin learns to categorise artificial knowledge that’s tougher to categorise. Adversarial distillation additionally improves the generalization functionality of the scholar mannequin by forcing it to be taught from difficult examples that aren’t current within the coaching set.
Multi-Trainer Distillation
Multi-teacher distillation entails utilizing a number of trainer fashions to coach a single scholar mannequin. The thought behind multi-teacher distillation is that by utilizing a number of sources of information, the scholar mannequin can be taught a extra complete set of options, resulting in improved efficiency.
The multi-teacher distillation algorithm consists of two phases of coaching. First, the trainer fashions are skilled independently on the coaching set to acquire their outputs. Second, the scholar mannequin is skilled on the identical coaching set, utilizing the outputs of all trainer fashions as targets. Throughout coaching, the scholar mannequin learns from the outputs of a number of trainer fashions, every offering a unique perspective on the coaching set. This enables the scholar mannequin to be taught a extra complete set of options, resulting in improved efficiency.
Multi-teacher distillation has a number of benefits over conventional information distillation strategies. This method reduces the bias that may be launched by a single trainer mannequin, as a number of academics present a extra various set of views. Multi-teacher distillation additionally improves the robustness of the scholar mannequin because it learns from a number of sources of information.
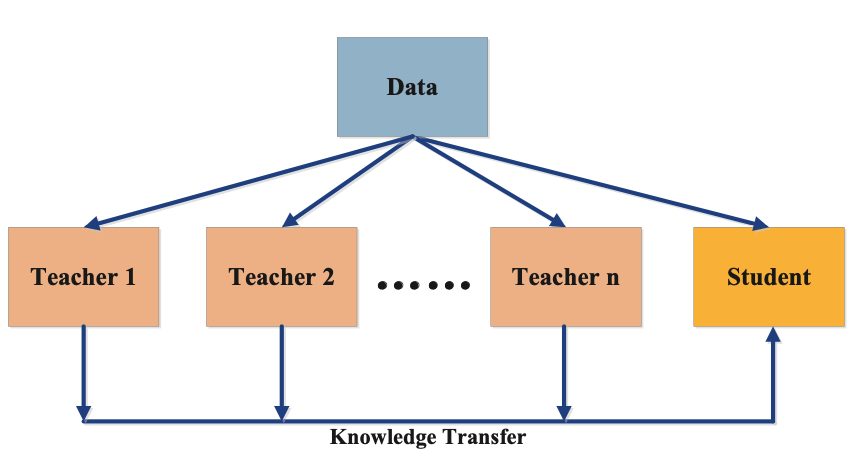
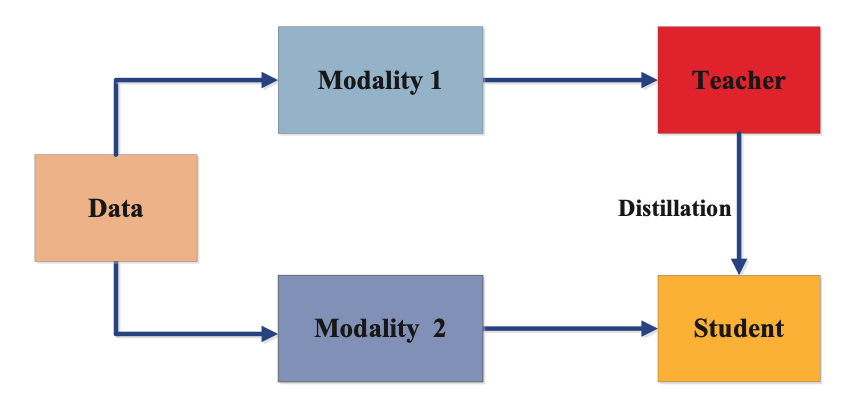
Cross-Modal Distillation
Cross-modal distillation is a information distillation algorithm that transfers information from one modality to a different. This method is helpful when knowledge is offered in a single modality however not in one other. For instance, in picture recognition, there could also be no textual content labels out there for the pictures, however there could also be out there textual content knowledge describing the pictures. In such circumstances, cross-modal distillation can be utilized to switch information from the textual content modality to the picture modality.
The cross-modal distillation algorithm consists of two phases of coaching. Within the first stage, a trainer mannequin is skilled on the supply modality (e.g., textual content knowledge) to acquire its outputs. Within the second stage, a scholar mannequin is skilled on the goal modality (e.g., picture knowledge), utilizing the outputs of the trainer mannequin as targets.
Throughout coaching, the scholar mannequin learns to map the goal modality to the output of the trainer mannequin. This enables the scholar mannequin to be taught from the information of the trainer mannequin within the supply modality, enhancing its efficiency within the goal modality.
Cross-modal distillation permits the switch of information from one modality to a different, making it helpful when knowledge is offered in a single modality however not in one other. Moreover, cross-modal distillation improves the generalization functionality of the scholar mannequin, because it learns from a extra complete set of options.
Conclusion
Information distillation is a strong method for enhancing the efficiency of small fashions by transferring information from giant and complicated fashions. It has been proven to be efficient in numerous functions, together with pc imaginative and prescient, pure language processing, and speech recognition.
There are three essential varieties of distillation information method: offline, on-line, and self-distillation. These labels are assigned relying on whether or not the trainer mannequin is modified throughout coaching or not. Every sort has its personal benefits and downsides, and the selection will depend on the particular utility and sources out there.
There are a number of algorithms for information distillation, together with adversarial distillation, multi-teacher distillation, and cross-modal distillation, every with its distinctive method to transferring information from trainer to scholar.
General, information distillation offers a strong instrument for enhancing the effectivity and efficiency of machine studying fashions. That is an space of ongoing analysis and growth, with many sensible functions within the discipline of AI.


