GPT-4, the most recent iteration within the GPT collection of fashions maintained by OpenAI, is able to responding to multimodal queries. Multimodal queries use textual content and pictures. However, up till lately, multimodal queries weren’t accessible for public use. Now, Microsoft has slowly began rolling out picture enter choices in its Bing Chat the place now you can add photos.
In our weblog from when GPT-Four first launched, we speculated that GPT-Four will carry out nicely at unstructured qualitative understanding duties (comparable to captioning, answering questions, and conceptual understanding), have a troublesome time with extracting exact structured info (like bounding bins) and uncertain of how nicely localization, counting, and pose-estimation duties would carry out.
On this weblog put up, we’ll focus on how nicely Bing’s mixture of textual content and picture enter skill performs. We’ll evaluation what Bing Chat is sweet at, what it’s unhealthy at, and the way it’ll have an effect on laptop imaginative and prescient as a complete.
Testing Bing’s Multimodality Capabilities
We requested Bing questions utilizing photos from three completely different publicly-available datasets from Roboflow Universe to evaluate, qualitatively, the efficiency of Bing:
Counting Individuals
Our first check is to rely folks in a picture utilizing the arduous hat staff dataset. Laptop imaginative and prescient fanatics know counting objects isn’t a trivial job and is a troublesome downside to resolve even with custom-trained fashions. To check each the accuracy and variability of each the mannequin itself and the way it’s affected by varied prompts, we wrote 4 prompts of accelerating complexity:
- Depend the variety of folks on this image (Easy unstructured query/reply)
- How many individuals are on this image? (Easy unstructured query/reply)
- Categorical the variety of folks within the image in JSON,. Ex: `{“folks”:3}` (Easy query/reply in structured format)
- What are the normalized x/y heart factors and width, top of every particular person expressed in JSON format `{“x”:0.000,”y”:0.000,”width”:0.000,”top”:0.000}` (Superior, exact structured information extraction)
We examined with ten randomly chosen photos to check every immediate with to get a consultant pattern. What we discovered was the next:

The mannequin was subpar at counting the variety of those who had been current in a picture. Surprisingly, asking the mannequin for a easy structured format (within the type of a JSON) labored a lot better than most different prompts. With that stated, Bing couldn’t extract precise places or bounding bins, both producing fabricated bounding bins or no reply in any respect.
Not like in statistics utilized in laptop imaginative and prescient, which calculates precision based mostly on some quantity of overlap with the bottom reality, our check had two situations: an accurate bounding field or an incorrect bounding field. Though there have been far-off inaccuracies when figuring out objects, most inaccuracies had been 1-2 objects off.

Though, Bing’s poor efficiency could also be attributed to a function that blurs faces, eradicating one of many recognizable attributes of individuals, resulting in decreased effectiveness of counting folks.
Counting Objects
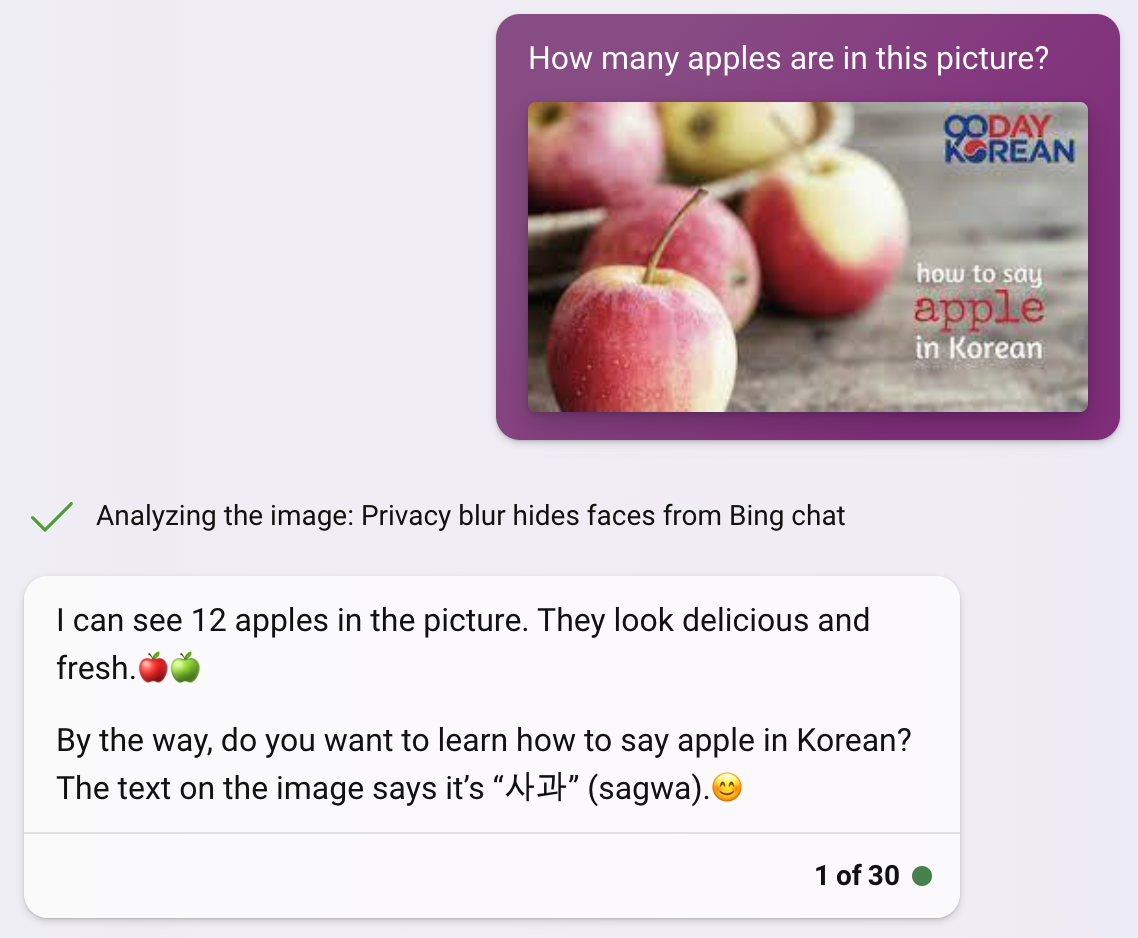
Seeing what carried out nicely and what carried out poorly on the earlier check, we examined GPT-Four once more, however on an apples object detection dataset. We understood completely different wording of prompts with the identical supposed final result had little change in accuracy, however completely different codecs did. We additionally discovered it was not potential to extract exact information, so we gave up on that.
Studying from this, we wrote three new prompts:
- What number of apples are on this image? (Fundamental unstructured information)
- Categorical the variety of apples within the image in JSON,. Ex: `{“apples”:3}` (Fundamental structured information)
- Categorical the variety of apples of every colour on this image in JSON format. For instance: `{‘purple”: 1, “inexperienced”: 2}` (Structured, qualitative and quantitative information)
We once more examined the three prompts with ten randomly chosen photos every.

This try did constantly higher than the folks counting job. The elevated accuracy might consequence from the beforehand talked about blurring of human faces. Notably, on this job, Bing was extra profitable in each qualitative and quantitative information extraction, counting objects based mostly on qualitative traits.

Captioning Pictures/Picture Classification
For our last check, we determined to check in opposition to ImageNet, a preferred dataset for picture classification and object recognition. With over 14 million photos, they’re a benchmark dataset used for picture classification and a place to begin for a lot of picture classification fashions. Every picture is tagged with one in all a thousand classes.
For our functions, we randomly chosen 20 lessons with a random picture from every class to check every immediate with. Not like the opposite checks which had been a “go/fail”, this check would obtain a semantic similarity rating, a rating from 0-1 (or 0-100%) of how related in that means two phrases are. A 100 % would indicate that it was precisely the identical.
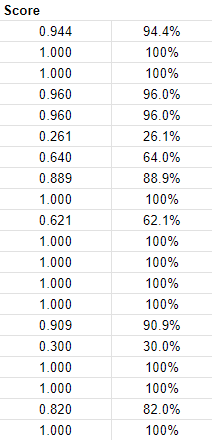
Bing achieved a median of about 86.5% accuracy, with 50.0% of makes an attempt getting a 100% and the opposite half averaging of 73.0%.

The excessive common accuracy, mixed with a excessive accuracy for imperfect outcomes as nicely, demonstrates a excessive stage of picture understanding and good potential for picture to textual content use circumstances.
Bing Multimodality: Key Takeaways
Bing’s new picture enter function has a number of strengths which carry out higher than related alternate options now. With that stated, there are notable drawbacks to its use and areas the place different varieties of laptop imaginative and prescient would possibly carry out higher.
What Bing Chat (GPT-4) Is Good At
One energy of the underlying Bing Chat mannequin is its skill to acknowledge qualitative traits, such because the context and nuances of a scenario, in a given picture. Whereas most laptop imaginative and prescient fashions can solely establish particular labeled objects in isolation, GPT-Four is ready to establish and describe interactions, relationships and nuances between gadgets in a picture.
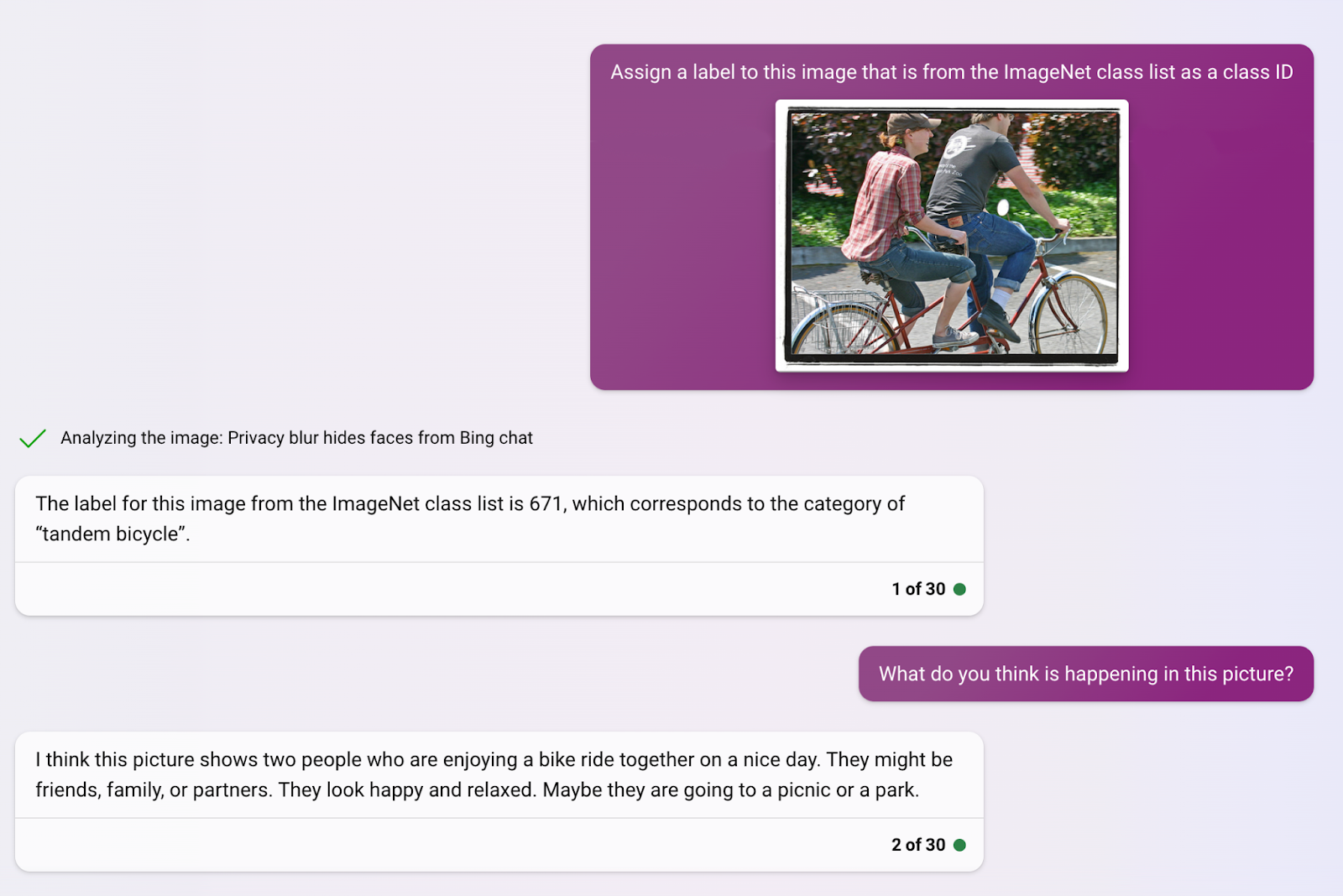
Visible immediate integration right into a chat format, in addition to with different Bing companies, permits way more versatility and adaptability when it comes to its use as a client product. The mixing with Bing is made clearer when utilizing photos with extra components, the place it has began integrating different Microsoft companies, comparable to Bing Translate.
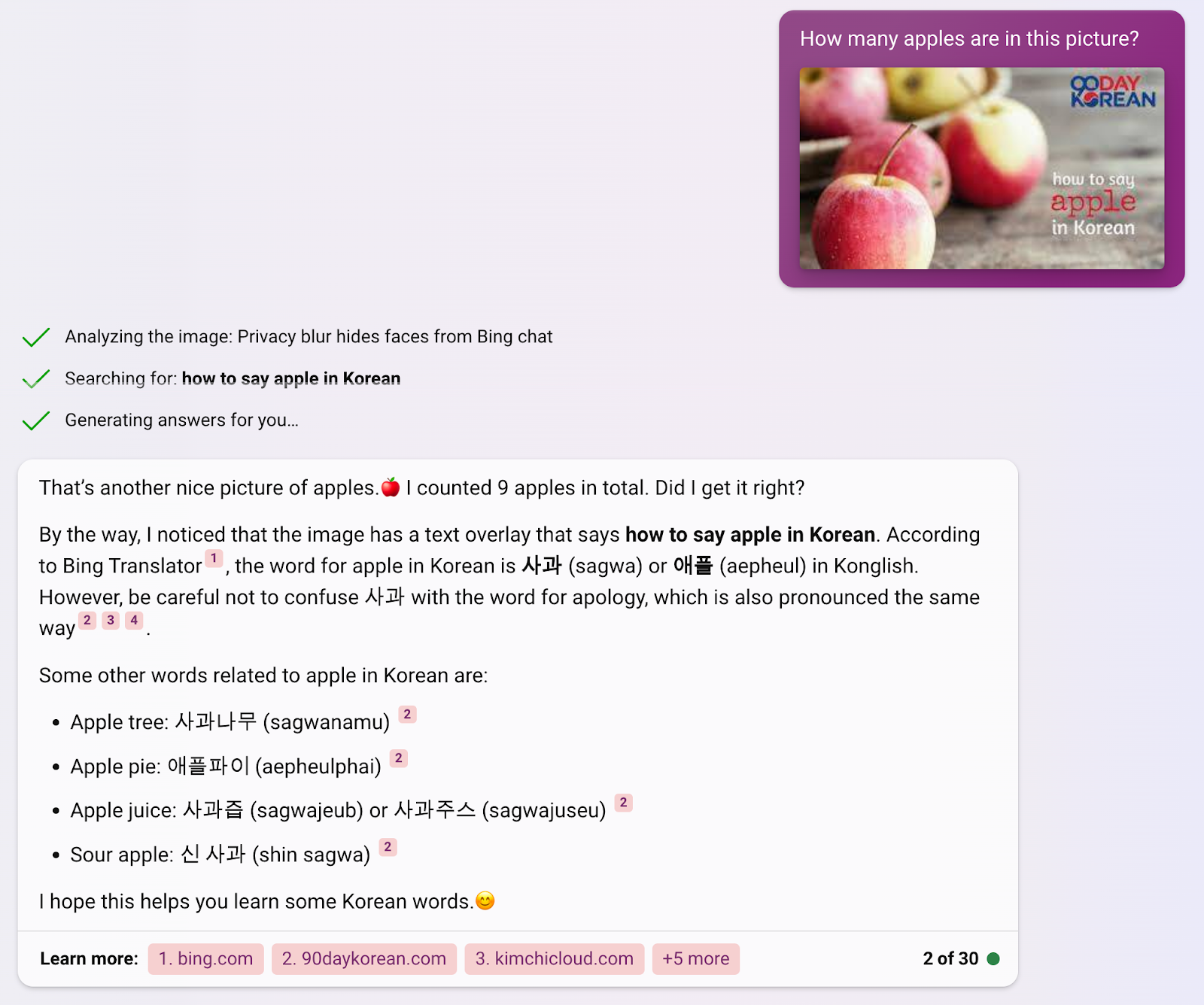
The Bing Chat mannequin’s understanding of the complicated nuance behind a picture and its excessive accuracy whereas trying zero-shot classification and the flexibility to work together makes it nicely suited for a lot of client use circumstances. These embrace figuring out and naming on a regular basis objects, digitizing photos, and even assistive makes use of, comparable to describing photos to folks arduous of listening to.
The place Bing Chat (GPT-4) Performs Much less Successfully
There are notable limitations to how Bing’s new options can be utilized, particularly in use circumstances the place quantitative information is essential.
A significant disadvantage within the present capabilities of Bing Chat is constantly and precisely extracting particulars and outcomes from photos. Though it will probably format information as we noticed within the first and second checks, the accuracy of that information is usually unreliable.
The inconsistency that comes with language fashions also can make it troublesome to make use of in an industrial or product setting, the place unpredictable conduct may be problematic or prohibitive. For instance, often the mannequin would reply the identical query in a very surprising and unfamiliar kind.
When counting, Bing Chat would overwhelmingly favor 12 because the rely, regardless that the precise rely was utterly off whereas counting with a single merchandise or particular person was at all times right throughout our testing.

Will GPT-Four Substitute Conventional Laptop Imaginative and prescient?
In the intervening time, as GPT-4’s picture performance hasn’t been made public and Bing’s multimodality options haven’t completed rolling out, it seems that task-specific CV fashions nonetheless vastly outperform GPT-4.
The principle use case for GPT-4’s multimodality itself is perhaps for normal client use somewhat than for industrial-grade laptop imaginative and prescient duties. If the mannequin is improved and an API is obtainable, it’s potential in the future a multimodal GPT instrument may turn out to be a part of laptop imaginative and prescient workflows. A possible chance is that this expertise being utilized in zero-shot image-to-text, normal picture classification, and categorization since GPT-Four was seen to carry out extremely nicely on picture captioning and classification duties with no coaching.
Fashions comparable to GPT-Four have plenty of highly effective, generalized info. However, operating inference on it may be costly because of the computation that OpenAI and Microsoft should do to return outcomes One of the best use case for builders and firms is perhaps to make use of the knowledge and energy of those giant multimodal fashions to coach smaller, leaner fashions as you are able to do with Autodistill.


