Picture segmentation has lengthy been a basic process in pc imaginative and prescient, enabling machines to grasp and interpret visible content material. Through the years, quite a few methods have emerged to deal with completely different elements of segmentation, similar to semantic, occasion, and panoptic segmentation. Nevertheless, these approaches have typically existed as separate entities, every requiring particular person coaching and fine-tuning.
However what if there was a groundbreaking answer that would deliver all these segmentation duties collectively? Enter OneFormer, a revolutionary common picture segmentation framework that goals to unify and simplify the segmentation course of like by no means earlier than.
This weblog submit will delve into the internal workings of this progressive mannequin, assessing its strengths and weaknesses. Let’s get began!
What’s OneFormer?
OneFormer breaks the limitations between semantic, occasion, and panoptic segmentation by introducing a novel multi-task train-once design. As an alternative of coaching and fine-tuning fashions individually for every process, OneFormer leverages a single unified framework that covers all elements of picture segmentation.
OneFormer is educated simply as soon as, considerably decreasing the complexity and time required to attain outstanding outcomes.
With OneFormer, you do not want to speculate substantial effort in coaching a number of fashions for various segmentation duties. This common framework guarantees to streamline your segmentation pipeline, making it extra environment friendly and accessible for numerous purposes.
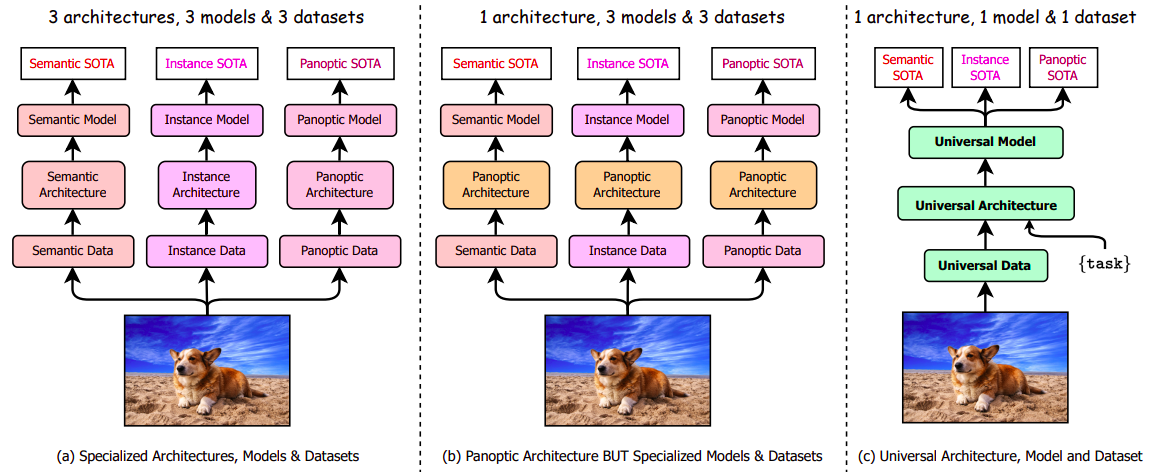
OneFormer Structure
The 2 key parts of OneFormer are the Process Conditioned Joint Coaching, which allows the framework to concurrently practice on panoptic, semantic, and occasion segmentation duties and the Question Representations which facilitates the communication and interplay between completely different elements of the mannequin structure.
Let’s go deeper into these two parts.
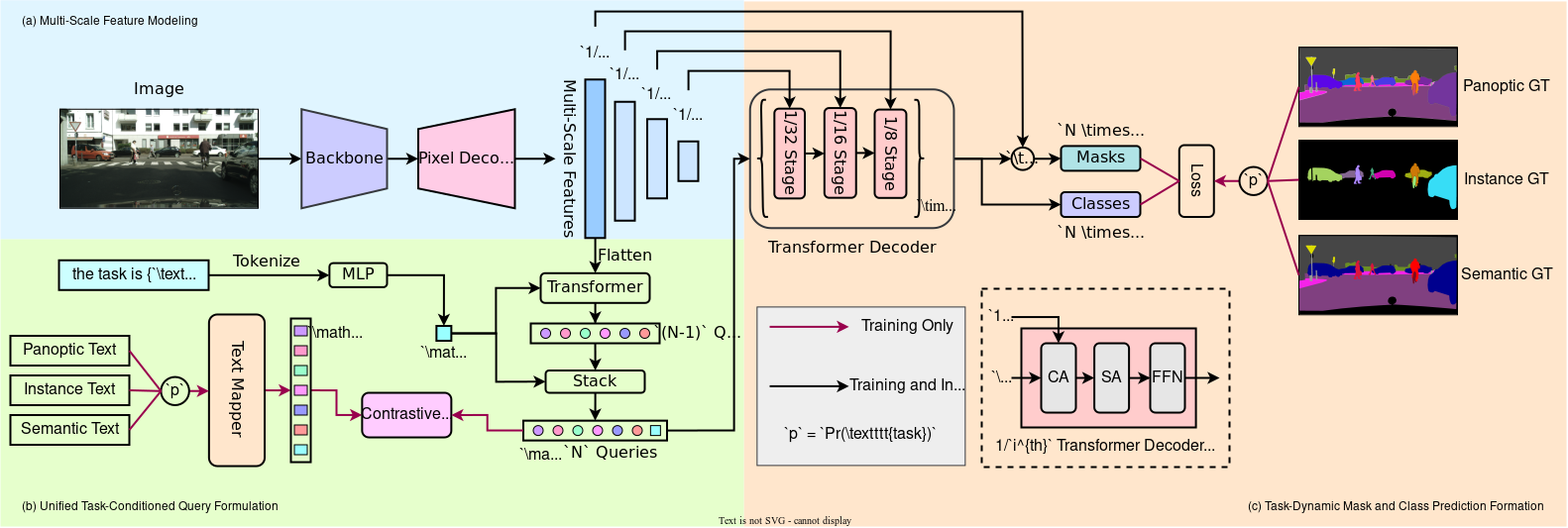
Process Conditioned Joint Coaching
Process Conditioned Joint Coaching empowers the framework to coach concurrently on panoptic, semantic, and occasion segmentation duties. This system ensures that the mannequin turns into proficient in all duties, leading to exact and dependable segmentations throughout the board.
Through the coaching course of, OneFormer makes use of a process conditioning mechanism to dynamically adapt the mannequin’s behaviour primarily based on the particular segmentation process at hand. This conditioning is achieved via the inclusion of a process enter that follows the format “the duty is {process}“.
For every coaching picture, the duty enter is randomly sampled from the set of accessible duties, which incorporates panoptic, semantic, and occasion segmentation. This random sampling permits the mannequin to study and adapt to several types of segmentation duties throughout coaching.
The duty enter is tokenized to acquire a 1-D process token, which is then used to situation the item queries and information the mannequin’s predictions for the given process. By incorporating this process token, OneFormer ensures that the mannequin has data concerning the process it must carry out and may alter its behaviour accordingly.
Moreover, the duty enter influences the creation of a textual content listing that represents the variety of binary masks for every class within the floor reality label. This textual content listing is mapped to textual content question representations, offering task-specific info that helps information the mannequin’s predictions and segmentations.
By conditioning the mannequin on the duty enter and incorporating task-specific info, OneFormer allows task-aware studying and fosters the event of a unified segmentation framework.
Question Representations
Question representations facilitate communication and interplay amongst numerous parts inside the mannequin structure. Question representations are utilised within the transformer decoder, the place they’re chargeable for capturing and integrating info from each the enter picture and the task-specific context.
Through the coaching course of, OneFormer makes use of two units of queries: textual content queries (Qtext) and object queries (Q).
Qtext represents the text-based illustration of segments inside the picture, whereas Q represents the image-based illustration. To acquire Qtext, the textual content entries Tpad are tokenized and handed via a text-encoder, which consists of a 6-layer transformer. This encoding course of produces Ntext textual content embeddings that seize details about the variety of binary masks and their corresponding lessons current within the enter picture.
Subsequent, a set of learnable textual content context embeddings (Qctx) is concatenated with the encoded textual content embeddings, ensuing within the closing N textual content queries (Qtext). The textual content mapper is illustrated within the determine under.
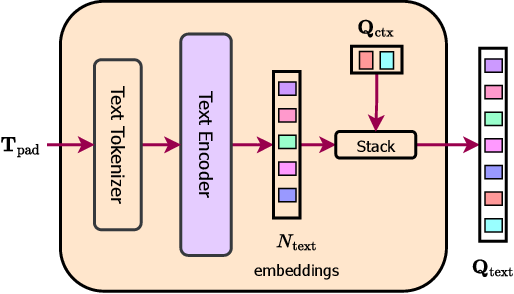
To acquire Q, the item queries (Q’) are initialized as a repetition of the task-token (Qtask) N − 1 instances. Subsequently, Q’ is up to date utilizing steerage from flattened 1/4-scale options inside a 2-layer transformer. The up to date object queries are concatenated with Qtask, leading to a task-conditioned illustration of N queries, denoted as Q.
This initialization and concatenation step, in distinction to utilizing all-zeros or random initialization, is essential for the mannequin to successfully study a number of segmentation duties.
Qtext captures info from the text-based representations of picture segments, whereas Q represents the image-based question illustration. These question units, with their task-conditioned initialization and concatenation, allow efficient studying of a number of segmentation duties inside the OneFormer framework.
OneFormer Mannequin Efficiency
OneFormer was evaluated by researchers on three extensively used datasets that embody semantic, occasion, and panoptic segmentation duties. The datasets are Cityscapes, ADE20Ok, and COCO. Under, we describe every dataset used alongside the outcomes obtained by OneFormer in comparison with different fashions.
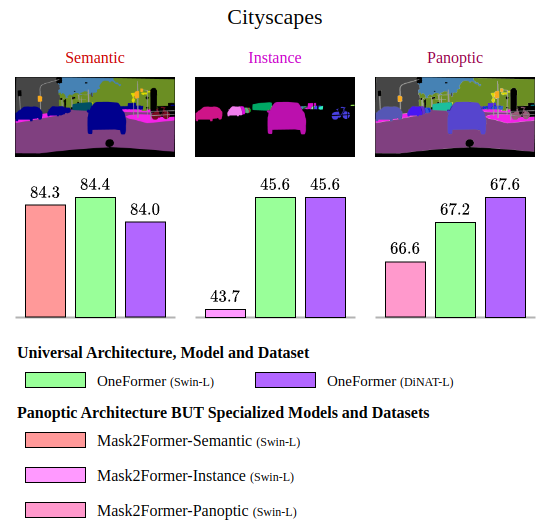
CityScapes Dataset
Cityscapes dataset consists of a complete of 19 lessons, comprising 11 “stuff” lessons and eight “factor” lessons. The dataset includes 2,975 coaching pictures, 500 validation pictures, and 1,525 take a look at pictures.
ADE20Ok Dataset
ADE20Ok serves as one other benchmark dataset, providing 150 lessons, together with 50 “stuff” lessons and 100 “factor” lessons. It consists of 20,210 coaching pictures and a pair of,000 validation pictures.

COCO Dataset
COCO dataset includes 133 lessons, encompassing 53 “stuff” lessons and 80 “factor” lessons. The dataset consists of 118,000 coaching pictures and 5,000 validation pictures.
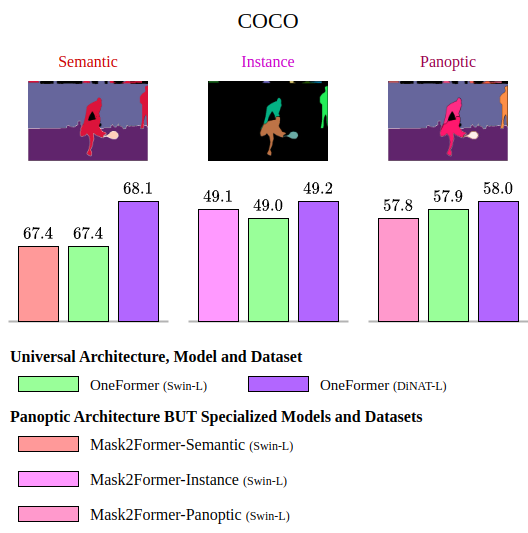
These datasets present a various vary of pictures and labels, enabling a complete analysis of OneFormer’s efficiency throughout the three segmentation duties.
OneFormer Limitations
OneFormer does have some limitations. These limitations embrace computational necessities, because the framework could demand vital computational sources for coaching and deployment.
Moreover, the efficiency of OneFormer closely is determined by the provision and high quality of coaching knowledge, making it delicate to the dataset used. Coaching OneFormer could be time-consuming because of the complexity of the mannequin structure and the joint coaching course of.
The interpretability of OneFormer could also be difficult as a consequence of its complicated structure, which can restrict its utility in domains the place explainability is essential.
Whereas OneFormer performs effectively on benchmark datasets, its generalisation to new or domain-specific datasets could fluctuate and require fine-tuning or further coaching.
Lastly, the bigger mannequin dimension of OneFormer, ensuing from its multi-task parts and transformer decoders, could affect reminiscence utilization and deployment feasibility in resource-constrained environments.
Conclusion
OneFormer represents a major step ahead within the area of picture segmentation. By leveraging process conditioning and question representations, OneFormer achieves sturdy efficiency throughout these picture segmentation duties in numerous domains.
The architectural design of OneFormer, with its spine, pixel decoder, transformer decoders, and multi-scale characteristic extraction, provides robustness and flexibility. The inclusion of task-specific info via question representations enhances the mannequin’s understanding and allows task-aware predictions.
The analysis of OneFormer on broadly used datasets, together with Cityscapes, ADE20Ok, and COCO, showcases its proficiency throughout completely different segmentation duties. OneFormer does have some limitations, nonetheless, as mentioned above.


