In current months and years, there was a drastic rise within the availability, recognition, and usefulness of AI fashions that may deal with a number of duties. This information will present you methods to use a number of fashions collectively to bootstrap an preliminary pc imaginative and prescient mannequin with little handbook work by utilizing the most recent developments in pc imaginative and prescient and machine studying.
Massive language fashions (LLMs), such because the lately launched LLaMa 2, can carry out language duties and have the flexibility to comply with up and iterate on them. Midjourney allowed the short era of detailed, customizable photos. Roboflow’s Autodistill made it attainable to coach smaller, sooner, and extra specialised fashions based mostly on the huge quantity of information and data held by bigger fashions.
On this article, we work to mix these newly unlocked capabilities into coaching an object detection mannequin end-to-end with out the necessity for amassing or labeling knowledge.
LLaMa 2: Writing the prompts
With the responsive and iterative nature of chat LLMs, we discovered that it will be attainable to make use of the newly launched LLaMa 2 mannequin from Meta to have it write and iterate by prompts to have Midjourney create the pictures we wish for our venture dataset.
First, we began with a activity. For this tutorial, we determined to create an object detection mannequin for detecting visitors lights in intersections.
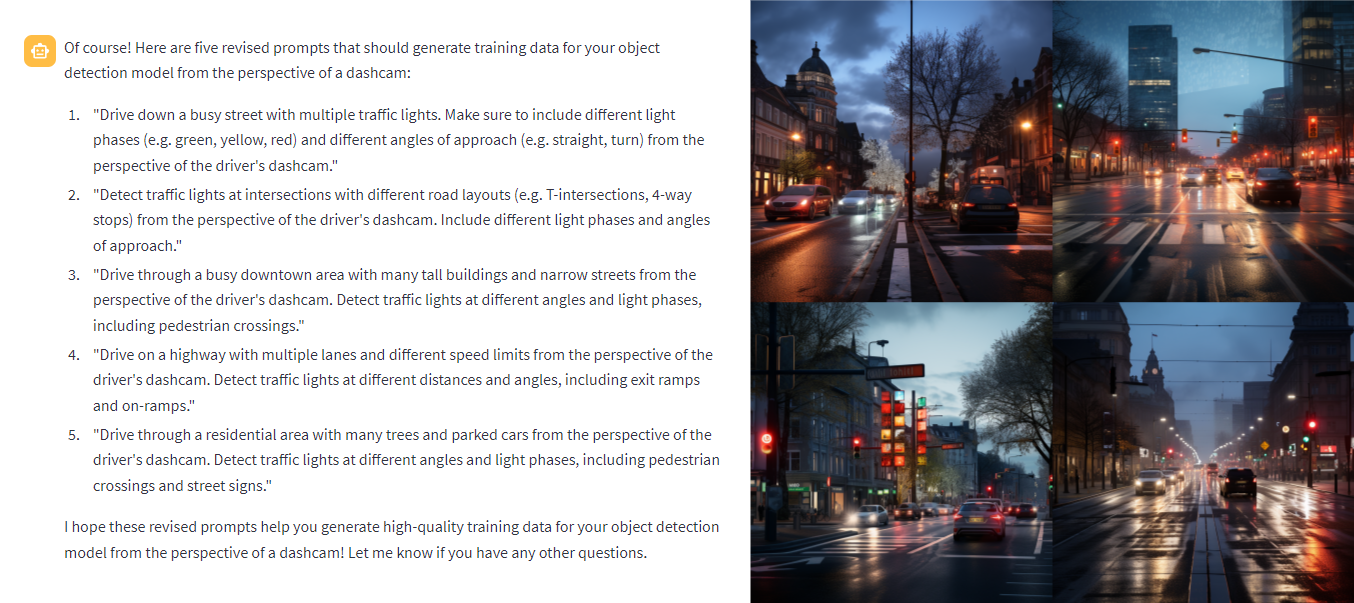
Then, we defined what we needed to do to LLaMa 2 after which requested it to put in writing 5 prompts for us:

We tried these prompts on Midjourney, which did present outcomes, however not those we needed:

Speaking these points to LLaMa 2, we requested it to put in writing new prompts:
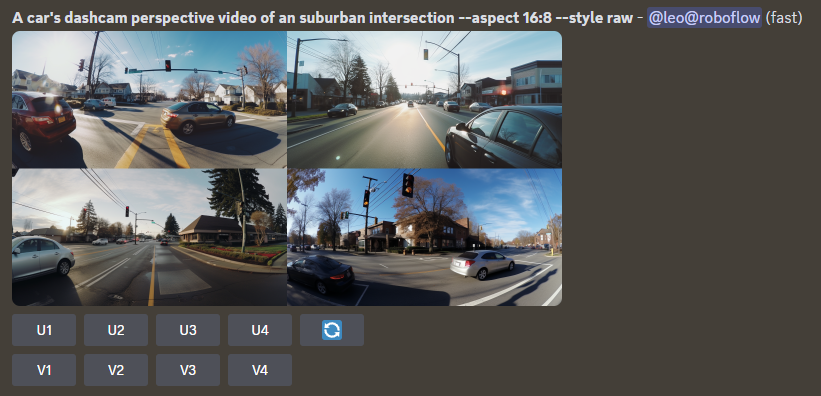
Midjourney: Creating the dataset
After a couple of iterations of prompting Midjourney and iterating by them with LLaMa 2, we landed on the prompts we needed to make use of. Now, it was time to generate the pictures we have been going to make use of for coaching our mannequin.
Since Midjourney already creates a set of 4 photos per era, we determined to create 100 photos or 25 generations utilizing Midjourney. We cut up that up with 5 makes an attempt for every of the 5 prompts, as the character of Midjourney meant it will create distinctive photos with every try.
Along with the generated photos, we additionally used the extra `–style uncooked` parameter to create extra photo-realistic photos, the `–facet` parameter to generate extra sensible and diverse picture sizes, and `–repeat 5` to run every immediate 5 instances robotically.
Changing the picture grid to particular person photos
📓
From this level onward, you may comply with alongside utilizing our pocket book!
The four-image grid is helpful for seeing the a number of prospects that our immediate offers, however is ineffective for coaching fashions, as we wish to recreate the circumstances through which the mannequin might be used to ensure that it to carry out properly.
So, we use Python’s PIL to crop and save every quadrant of the picture grid, turning the 4x picture right into a singular picture:
import os
import glob
import cv2
from PIL import Picture for im_dir in midjourney_images: im = Picture.open(im_dir) im_width, im_height = im.measurement res_im1_props = 0,0,im_width/2,im_height/2 res_im2_props = im_width/2,0,im_width,im_height/2 res_im3_props = 0,im_height/2,im_width/2,im_height res_im4_props = im_width/2,im_height/2,im_width,im_height for i in vary(1,5): res_im = im.crop(locals()[f'res_im{i}_props']) res_im_dir = f'transformed/{i}-{os.path.basename(im_dir)}' res_im.save(res_im_dir)
These photos are saved in our `transformed` folder, which we will then use to coach our mannequin.

Autodistill: Automated Knowledge Labeling and Mannequin Coaching
Now we transfer on to labeling and coaching our mannequin on Ultralytics YOLOv8. We’ll do that utilizing the GroundedSAM and YOLOv8 modules for Autodistill.
We set up and import our obligatory packages and create our ontology, which is used to categorize our prompts for GroundedSAM and the category names we wish them to have:
base_model = GroundedSAM(ontology=CaptionOntology({ "visitors gentle": "traffic_light"
}))
❕
For our venture, the ontology is fairly easy. You may change this in your personal venture, like including, changing or together with vehicles, individuals, and so forth.
Then, we will rapidly study and iterate the prompting of GroundedSAM by checking the way it masked a pattern picture from our dataset, which confirmed that it was in a position to label all of the visitors lights within the picture efficiently:

Automated Knowledge Labeling and Mannequin Coaching
Now that we nailed down our ontology for Autodistill, now we will label our full dataset and prepare it, which may be performed in three traces of code.
base_model.label( input_folder = input_dir, extension = "", output_folder = output_dir,
) target_model = YOLOv8("yolov8n.pt")
target_model.prepare("dataset/knowledge.yaml", epochs=200)
Mannequin Coaching Outcomes
As soon as that’s performed we will consider how the mannequin did and check out some check dataset photos to see how our skilled mannequin carried out.

Roboflow: Add and deploy the mannequin
Now that we now have an preliminary mannequin and preliminary dataset, we now have efficiently bootstrapped a mannequin to make use of in manufacturing. With this, we will add the mannequin and dataset into Roboflow to handle additional enhancements and additions to our mannequin.
First, we’ll add the dataset utilizing the `roboflow` Python bundle by changing it right into a VOC dataset utilizing Supervision.
images_path = Path("voc_dataset/photos")
images_path.mkdir(dad and mom=True, exist_ok=True) annotations_path = Path("voc_dataset/annotations")
annotations_path.mkdir(dad and mom=True, exist_ok=True) train_dataset = sv.DetectionDataset.from_yolo(images_directory_path="dataset/prepare/photos", annotations_directory_path="dataset/prepare/labels", data_yaml_path="dataset/knowledge.yaml")
valid_dataset = sv.DetectionDataset.from_yolo(images_directory_path="dataset/legitimate/photos", annotations_directory_path="dataset/legitimate/labels", data_yaml_path="dataset/knowledge.yaml") dataset = sv.DetectionDataset.merge([train_dataset,valid_dataset])
dataset.as_pascal_voc( images_directory_path = str(images_path), annotations_directory_path = str(annotations_path)
) for image_name, picture in dataset.photos.objects(): print("importing:",image_name) image_path = os.path.be part of(str(images_path),image_name) annotation_path = os.path.be part of(str(annotations_path),f'{os.path.splitext(image_name)[0]}.xml') print(image_path,annotation_path) venture.add(image_path, annotation_path) After that, we will generate a model of the dataset, then add our mannequin there.
venture.model("1").deploy(model_type="yolov8", model_path=f"runs/detect/prepare/")
Including Energetic Studying
As soon as the mannequin is uploaded, we will deploy it and use energetic studying so as to add real-world knowledge into our dataset to coach the following iteration of our mannequin.
mannequin = venture.model("1").mannequin mannequin.confidence = 50
mannequin.overlap = 25 image_path = "/transformed/b0816d3f-3df7-4f48-a8fb-e937f221d6db.png"
prediction = mannequin.predict(image_path) prediction.json() venture.add(image_path)
Conclusion
On this venture, we have been in a position to automate the duty of making an object detection mannequin utilizing quite a lot of new AI instruments.
When you’d wish to be taught extra about Autodistill’s potential to label and prepare fashions robotically, try the docs for Autodistill. When you’d wish to recreate this course of, or create your personal venture utilizing this course of, try our pocket book that we made.


