Picture segmentation architectures have historically been designed for particular duties, comparable to semantic segmentation or occasion segmentation. Nonetheless, this method has a number of limitations. First, it requires specialised data for every process, which could be time-consuming and costly to coach a mannequin to attain. Second, growing specialised data for 2 separate duties can result in suboptimal efficiency, because the structure just isn’t optimized for the particular process.
Lately, there was a development in direction of growing common picture segmentation architectures that can be utilized for a wide range of duties. One such structure is MaskFormer, which was proposed in 2021. MaskFormer is predicated on the DETR structure, which makes use of a transformer decoder to foretell masks for every object in a picture.
MaskFormer has been proven to be efficient for each semantic segmentation and panoptic segmentation. Nonetheless, it has not been as profitable for example segmentation. It’s because MaskFormer makes use of a single decoder for all duties, which isn’t preferrred for example segmentation, which requires extra fine-grained info.
To handle the constraints of MaskFormer, Mask2Former has been proposed. Mask2Former has two key improvements: A multi-scale decoder that helps Mask2Former to establish small objects in addition to giant objects and a masked consideration mechanism that enables Mask2Former to concentrate on the related options for every object to stop the decoder from higher dealing with background noise.
On this weblog submit, we are going to discover Mask2Former intimately, inspecting the way it works, the place it performs properly, and what limitations the mannequin has.
What’s Mask2Former?
Mask2Former is a common picture segmentation structure that was proposed in 2022 by Meta AI Analysis. It’s based mostly on the DETR structure, which makes use of a transformer decoder to foretell masks for every object in a picture.
Mask2Former is a common structure that can be utilized for a wide range of duties, together with semantic segmentation, panoptic segmentation, and occasion segmentation. It’s extra correct than earlier picture segmentation architectures attributable to its use of a multi-scale decoder and a masked consideration mechanism.
The multi-scale decoder in Mask2Former permits it to take care of each native and international options. That is vital for example segmentation, because it permits Mask2Former to establish small objects in addition to giant objects.
The masked consideration mechanism in Mask2Former restricts the eye of the decoder to the foreground area of every object. This helps Mask2Former to concentrate on the related options for every object, and it additionally helps to stop the decoder from attending to background noise.
The masked consideration mechanism in Mask2Former works by solely permitting the decoder to take care of the foreground area of every object. That is accomplished by masking out the background areas within the consideration weights. This helps Mask2Former to concentrate on the related options for every object, and it additionally helps to stop the decoder from attending to background noise.
Mask2Former has been proven to be efficient for a wide range of picture segmentation duties, together with semantic segmentation, panoptic segmentation, and occasion segmentation. It has achieved state-of-the-art outcomes on a number of widespread datasets, together with COCO, ADE20Ok, and Cityscapes.
Mask2Former Professionals and Cons
Let’s speak about among the benefits and downsides with the Mask2Former mannequin. The benefits embody:
- Mask2Former is a common structure that can be utilized for a wide range of duties. Which means you need not have a separate structure for every process, which may save time and assets.
- Mask2Former is extra correct than earlier picture segmentation architectures. This is because of its use of a multi-scale decoder and a masked consideration mechanism.
- Mask2Former is extra environment friendly than earlier picture segmentation architectures. This is because of its use of the transformer decoder, which is a extra environment friendly technique to course of info than conventional CNNs.
With that stated, there are limitations, which embody:
- Mask2Former could be computationally costly to coach and deploy. This is because of its use of the transformer decoder, which is a computationally intensive mannequin.
- It may be troublesome to fine-tune Mask2Former for particular duties. It’s because it’s a common structure, and it is probably not as well-suited for some duties as it’s for others.
Mask2Former Structure
To raised perceive the Mask2Former structure, it’s helpful to first describe the structure from which Mask2Former was impressed> the MaskFormer structure. The MaskFormer structure is proven within the beneath image.
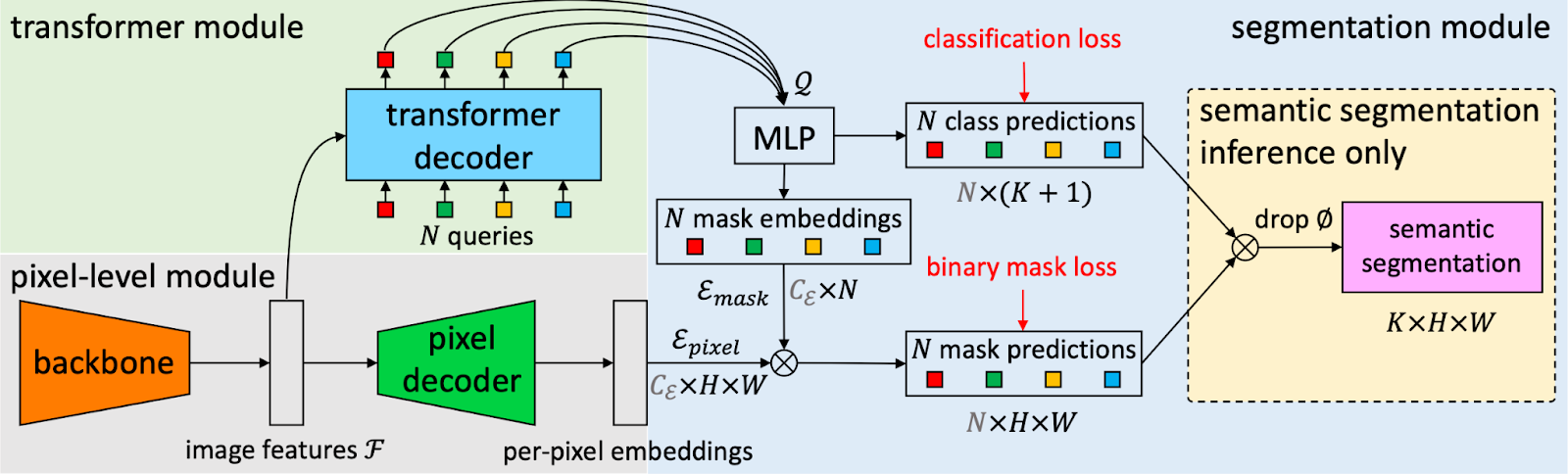
The preliminary stage of MaskFormer entails the utilization of a spine community to extract picture options. These options endure an upsampling course of to generate per-pixel embeddings.
Concurrently, a Transformer Decoder comes into play, crafting per-segment embeddings that encapsulate potential objects inside the picture.
These embeddings function the muse for predicting class labels and their corresponding masks embeddings. Binary masks are then shaped by executing a dot product between pixel and masks embeddings, in the end yielding doubtlessly overlapping binary masks for every occasion of an object.
In eventualities like semantic segmentation, the final word prediction materializes by amalgamating binary masks with their related class predictions.
The pivotal query now emerges: what units Mask2Former aside, permitting the mannequin to attain superior efficiency over MaskFormer?
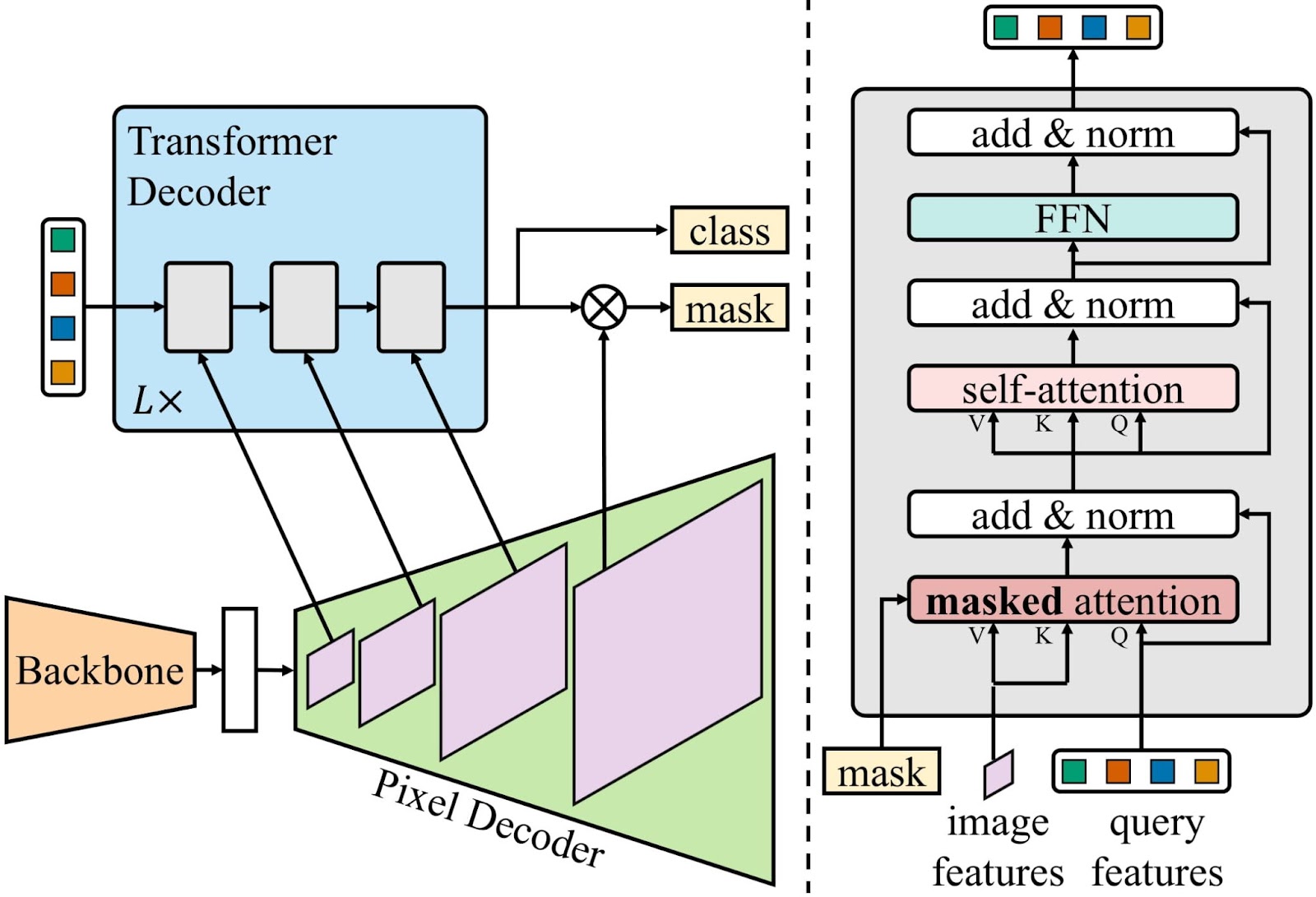
Mask2former employs an structure equivalent to that of MaskFormer, marked by two main distinctions: utilizing masks consideration as a substitute of cross consideration, and the multi-scale high-resolution options with which the mannequin works.
Utilizing Masks Consideration as a substitute of Cross Consideration
Mask2Former makes use of masked consideration as a substitute of cross consideration to enhance its efficiency for example segmentation. Cross consideration permits the decoder to take care of all pixels within the picture, together with background pixels. This may be problematic for example segmentation, because the decoder could be simply distracted by background noise.
Masked consideration restricts the eye of the decoder to the foreground area of every object. This helps the decoder to concentrate on the related options for every object, and it additionally helps to stop the decoder from attending to background noise.
Furthermore, masked consideration is extra environment friendly than cross consideration, which may cut back the coaching and inference time of Mask2Former.
Multi-scale high-resolution options
To sort out the problem of small objects, Mask2Former makes use of a multi-scale function illustration. Which means it makes use of options at completely different scales or resolutions, which permits it to seize each fine-grained particulars and broader context info.
For optimum processing of those multi-scale options, Mask2Former systematically directs a single scale of the multi-scale function to a person Transformer decoder layer throughout every iteration. Consequently, every Transformer decoder layer course of options at a chosen scale, comparable to 1/32, 1/16, or 1/8. This method permits Mask2Former to considerably improve its capability to adeptly handle objects of various sizes.
Mask2Former Efficiency
On this part, we talk about Mask2Former efficiency alongside visible demonstrations of MaskFormer’s capabilities in panoptic segmentation and occasion segmentation on the COCO dataset. We additionally present semantic segmentation predictions on the ADE20Ok dataset.
Panoptic Segmentation
Panoptic segmentation on COCO panoptic val2017 with 133 classes. Mask2Former constantly outperforms MaskFormer by a big margin with completely different backbones on all metrics. The very best Mask2Formere mannequin outperforms prior state-of-the-art MaskFormer by 5.1 PQ and Ok-Internet by 3.2 PQ.
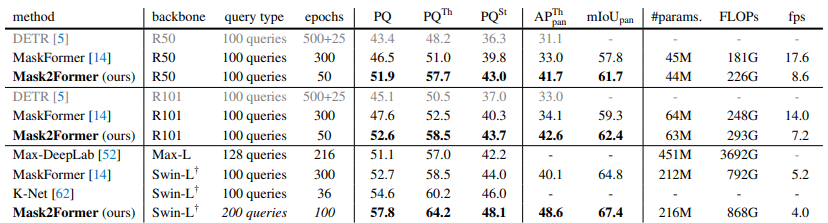
Mask2Former efficiency on panoptic segmentation. Supply

Visualization of panoptic segmentation predictions on the COCO panoptic dataset: Mask2Former with Swin-L spine which achieves 57.Eight PQ on the validation set. First and third columns: floor reality. Second and fourth columns: prediction.
Occasion Segmentation
Occasion segmentation on COCO val2017 with 80 classes. Mask2Former outperforms sturdy Masks R-CNN baselines for each AP and APboundary metrics when coaching with 8x fewer epochs. For a good comparability, solely single-scale inference and fashions skilled utilizing solely COCO practice2017 set knowledge have been thought-about.

Mask2Former efficiency on occasion segmentation. Supply

Visualization of occasion segmentation predictions on the COCO dataset: Mask2Former with Swin-L spine which achieves 50.1 AP on the validation set. First and third columns: floor reality. Second and fourth columns: prediction. We present predictions with confidence scores higher than 0.5.
Semantic Segmentation
Semantic segmentation on ADE20Ok val with 150 classes. Mask2Former constantly outperforms MaskFormer by a big margin with completely different backbones (all Mask2Former fashions use MSDeformAttn as pixel decoder, besides Swin-L-FaPN makes use of FaPN). Each single scale (s.s.) and multi-scale (m.s.) inference outcomes have been reported.
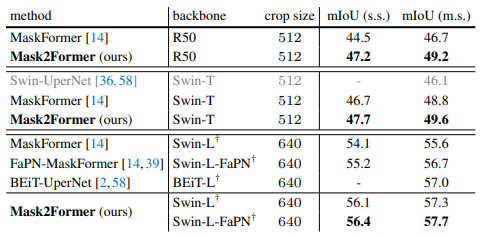
Mask2Former efficiency on semantic segmentation. Supply

Visualization of semantic segmentation predictions on the ADE20Ok dataset: Mask2Former with Swin-L spine which achieves 57.7 mIoU (multi-scale) on the validation set. First and third columns: floor reality. Second and fourth columns: prediction
Conclusion
MaskFormer is a sophisticated picture segmentation mannequin that adopts a novel mixture of masked consideration and transformer decoder. By means of a collection of visible demonstrations, we witnessed MaskFormer’s excellent efficiency in panoptic segmentation, occasion segmentation, and semantic segmentation duties on the COCO and ADE20Ok datasets.
MaskFormer’s masked consideration mechanism permits it to effectively extract native options by specializing in the foreground areas of predicted masks, enabling exact segmentation and enhancing its adaptability throughout numerous duties. Moreover, the implementation of an environment friendly multi-scale technique empowers MaskFormer to deal with small objects successfully, with out compromising computational effectivity.


