The article under was contributed by Timothy Malche, an assistant professor within the Division of Pc Functions at Manipal College Jaipur.
Pc imaginative and prescient expertise has revolutionized the way in which we deal with necessary issues similar to wildfire detection and management in recent times.
Conventional fireplace detection applied sciences steadily depend on ground-based gear or satellite tv for pc imaging, which could have limitations when it comes to accuracy, velocity, and protection
To handle the rising hazard of wildfires, pc imaginative and prescient can be utilized. Pc imaginative and prescient can permit earlier detection of wildfires when deployed throughout massive swathes of forest that might be troublesome for people to watch on daily basis.
On this information, we’re going to present how one can detect fires utilizing aerial imagery. Let’s start!
Aerial Hearth Detection with Pc Imaginative and prescient
To construct the system, we are going to want the next gear and software program:
- A drone;
- A WiFi digicam module, by means of which pictures could be collected;
- A Roboflow account, which we are going to use to label information, and;
- A Google Colab Pocket book, which we are going to use to coach a mannequin.

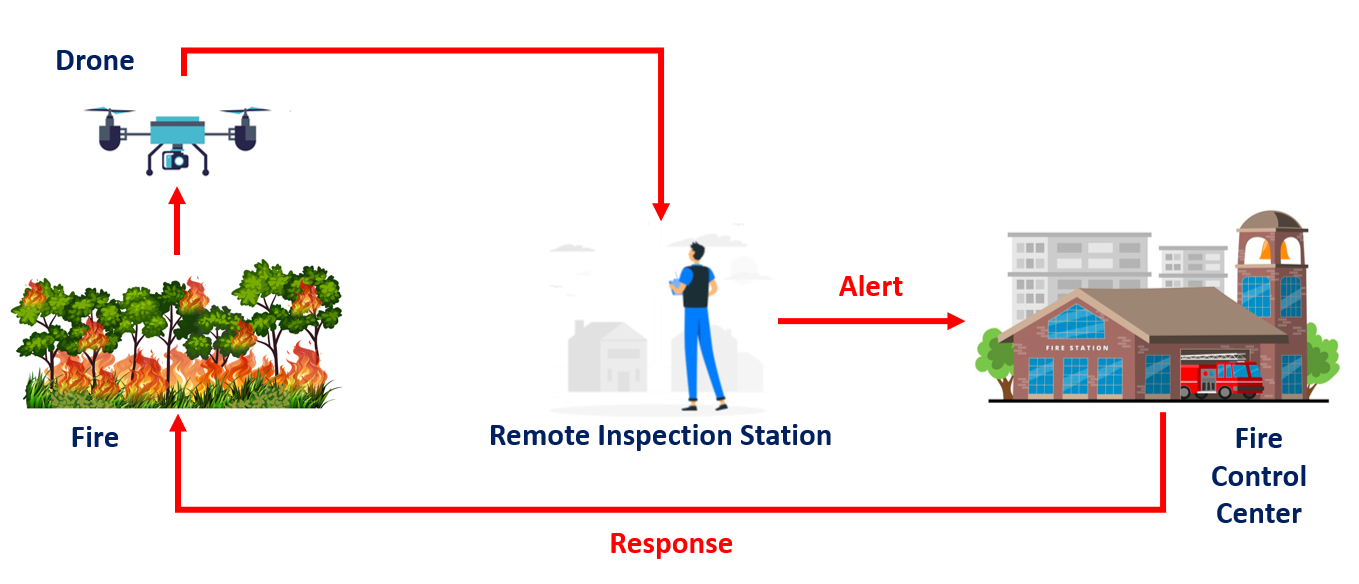
This undertaking makes use of a drone geared up with a digicam module for fireplace detection, involving distant monitoring and response by means of pc imaginative and prescient and coordination with a Hearth Management Heart. Here’s a step-by-step description of this operation:
- Deployment of the Drone: The drone geared up with a digicam module is deployed to the world that must be inspected for potential fireplace hazards. Drones are well-suited for this activity as it will possibly rapidly cowl massive areas and could be accessed remotely.
- Distant Inspection Station: The drone is remotely managed from an inspection station, usually operated by educated personnel.
- Pc Imaginative and prescient Evaluation: The video stream or pictures captured by the drone’s digicam are despatched to a pc imaginative and prescient mannequin for evaluation.
- Hearth Detection: The pc imaginative and prescient mannequin repeatedly processes the incoming information from the drone’s digicam. It seems for visible cues that point out the presence of a hearth, similar to the looks of flames, smoke, or modifications in temperature patterns.
- Alert to Hearth Management Heart: Upon detecting a hearth, the pc imaginative and prescient mannequin sends a right away alert to the Hearth Management Heart.
- Hearth Management Heart Response: The Hearth Management Heart receives the alert and assesses the data supplied by the pc imaginative and prescient mannequin. Based mostly on this data, the middle could make knowledgeable selections concerning the acceptable response.
- Response Workforce Motion: The response group, which is educated and geared up to deal with firefighting and emergency conditions, is dispatched to the placement of the detected fireplace.
To construct this undertaking, we are going to comply with these steps:
- Put together a dataset
- Label a dataset and generate a snapshot to be used in mannequin coaching
- Practice a mannequin
- Take a look at the mannequin
Step #1: Dataset Preparation
The dataset for this undertaking is obtained from The FLAME dataset: Aerial Imagery Pile burn detection utilizing drones (UAVs), IEEE Dataport.
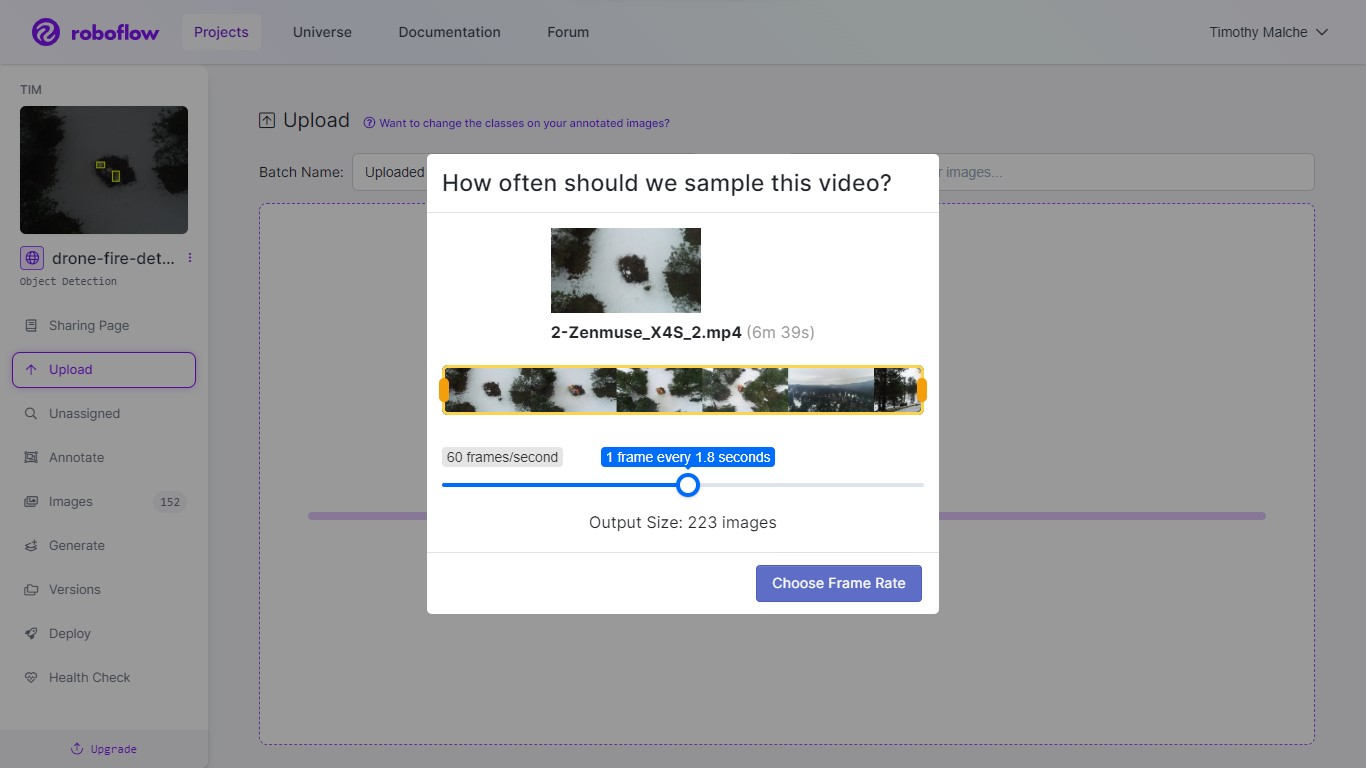
The dataset was first downloaded, then uploaded to our personal Roboflow account. Within the context of our fireplace detection undertaking, the dataset is collected in video format (.mp4). Roboflow has a helpful characteristic that permits customers to effortlessly add movies, subsequently automating the extraction of particular person frames from the video and reworking them into distinct pictures.
Roboflow gives a user-friendly interface to specify the specified body charge. This simple interface dictates what number of pictures are to be generated from the video, streamlining the method significantly. A visible illustration of this interface is depicted within the determine under. The utilization of Roboflow’s software drastically simplifies the complicated activity of gathering datasets and changing them into usable pictures.
Step #2: Dataset Labelling and Technology
After pictures have been efficiently uploaded, they are often annotated utilizing Roboflow’s annotation software. Within the context of this undertaking, object detection bounding containers are used to label these pictures. The label fireplace is used to annotate all occurrences of fireside throughout the dataset. The labeling course of is a crucial step in making ready the dataset for coaching, in addition to enabling the pc imaginative and prescient mannequin to precisely establish and classify cases of fireside throughout the pictures.

As soon as all the pictures within the dataset have been labeled with the ‘Hearth’ class, the dataset model is generated. The settings used to generate this dataset model is illustrated within the following picture.

Step #3: Coaching the Mannequin
Following the annotation course of, we proceeded to coach the Ultralytics YOLOv8 object detection mannequin utilizing a Jupyter Pocket book. You may simply comply with every step of this course of by accessing and downloading the pocket book by means of this hyperlink. The dataset obligatory for coaching the YOLOv8 mannequin for this undertaking, could be acquired utilizing the supplied code snippet under.
from roboflow import Roboflow
rf = Roboflow(api_key="YOUR_API_KEY")
undertaking = rf.workspace("YOUR_WORKSPACE").undertaking("drone-fire-detection-byija")
dataset = undertaking.model(1).obtain("yolov8")
Learn to retrieve your Roboflow API key.
As soon as the dataset is efficiently obtained from Roboflow universe, the mannequin coaching course of could be initiated utilizing the next command.
yolo activity=detect mode=practice mannequin=yolov8m.pt information={dataset.location}/information.yaml epochs=50 imgsz=800 plots=TrueBeneath, we are able to see how our mannequin performs at detecting the `Hearth` class. Our mannequin achieves a 0.95% recall charge, a 0.99% mAP50 rating, and a 0.63% mAP50-95.

After the profitable coaching of the YOLOv8 mannequin, the educated weights are then deployed again to Roboflow. This deployment course of renders the educated mannequin accessible for inference by means of Roboflow’s hosted inference API.
Step #4: Deploying and Testing the Mannequin
Roboflow gives a user-friendly interface for importing and making ready the educated mannequin for instant use. You may deploy the mannequin from Python code on to the Roboflow platform, or on a tool with https://github.com/roboflow/inference. However on this information, we are going to load our mannequin straight in a pocket book for testing.
We are going to export the educated YOLOv8 mannequin right into a .pth file and subsequently incorporate it right into a Python script for inferencing functions. This part illustrates how Roboflow’s Supervision could be employed to judge the efficiency of the educated mannequin.
To acquire the weights of the educated YOLOv8 mannequin, you should use the supplied code snippet for downloading.
# Export your mannequin weights for future use from google.colab import recordsdata
recordsdata.obtain('/content material/runs/detect/practice/weights/greatest.pt')Operating Inference on Photographs
The “greatest.pt” weight file might be utilized along side Supervision to create a {custom} detector. Initially, we are going to use Supervision to execute inference on a picture. You may discuss with this pocket book for a step-by-step walkthrough.
The take a look at picture could be specified with the next code:
import cv2 IMAGE_PATH = "/content material/fireplace.png"
picture = cv2.imread(IMAGE_PATH)Following that, we have to load our {custom} mannequin and carry out inference on the desired picture utilizing the {custom} mannequin.
from ultralytics import YOLO
import supervision as sv mannequin = YOLO('greatest.pt')
consequence = mannequin(picture, verbose=False)[0]
detections = sv.Detections.from_ultralytics(consequence)The supervision BoxAnnotator is used to label objects throughout the picture and the plot_image() operate to showcase the detection outcomes.
box_annotator = sv.BoxAnnotator() labels = [ f"{model.model.names[class_id]} {confidence:.2f}" for class_id, confidence in zip(detections.class_id, detections.confidence)
] annotated_image = box_annotator.annotate(picture.copy(), detections=detections, labels=labels) sv.plot_image(picture=annotated_image, dimension=(8, 8))The above code takes the outcomes of object detection from a {custom} mannequin, generates labels for every detected object, annotates the enter picture with bounding containers and labels, after which shows the annotated picture for visualization. The next reveals the output generated after working the above code:

Operating Inference on Video
Subsequent, we make the most of Supervision for performing inference on a captured video. To attain this, each the supply video which we’ve got captured and goal video that we want to generate as output.
SOURCE_VIDEO_PATH = f"{HOME}/fireplace.mp4"
TARGET_VIDEO_PATH = f"{HOME}/fire_result.mp4"In our video inference utility, we are going to incorporate BYTETrack, a multi-object monitoring framework. BYTETrack performs a vital position in enhancing monitoring consistency by preserving related bounding containers which may in any other case be discarded as a result of low confidence scores, typically brought on by occlusion or look modifications. You may discuss with this accompanying pocket book for steering all through this course of.
After putting in YOLOv8, obtain BYTETrack and set up it with the next command:
%cd {HOME}
!git clone https://github.com/ifzhang/ByteTrack.git
%cd {HOME}/ByteTrack # workaround associated to https://github.com/roboflow/notebooks/points/80
!sed -i 's/onnx==1.8.1/onnx==1.9.0/g' necessities.txt
!pip3 set up -q -r necessities.txt
!python3 setup.py -q develop
!pip set up -q cython_bbox
!pip set up -q onemetric
# workaround associated to https://github.com/roboflow/notebooks/points/112 and https://github.com/roboflow/notebooks/points/106
!pip set up -q loguru lap thopWe additionally want to put in supervision:
!pip set up supervision==0.1.0Subsequent, import the dependencies to be used in your undertaking:
from IPython import show
show.clear_output() import sys
sys.path.append(f"{HOME}/ByteTrack") import yolox
print("yolox.__version__:", yolox.__version__) from yolox.tracker.byte_tracker import BYTETracker, STrack
from onemetric.cv.utils.iou import box_iou_batch
from dataclasses import dataclass @dataclass(frozen=True)
class BYTETrackerArgs: track_thresh: float = 0.25 track_buffer: int = 30 match_thresh: float = 0.Eight aspect_ratio_thresh: float = 3.Zero min_box_area: float = 1.Zero mot20: bool = False from IPython import show
show.clear_output() import supervision
print("supervision.__version__:", supervision.__version__) from supervision.draw.shade import ColorPalette
from supervision.geometry.dataclasses import Level
from supervision.video.dataclasses import VideoInfo
from supervision.video.supply import get_video_frames_generator
from supervision.video.sink import VideoSink
from supervision.pocket book.utils import show_frame_in_notebook
from supervision.instruments.detections import Detections, BoxAnnotatorWe are able to use the packages above to construct an object detection and monitoring pipeline, the place detections from an object detection mannequin are matched with present tracked objects. The result’s an inventory of tracker IDs related to every detection. It is a crucial step in multi-object monitoring techniques.
The subsequent step includes loading our custom-trained mannequin, particularly designed for detecting cases of fireside. We are going to accomplish this by loading the mannequin from the “greatest.pt” file.
MODEL = "/content material/greatest.pt"
from ultralytics import YOLO mannequin = YOLO(MODEL)
mannequin.fuse()
Outline the lessons utilized within the mannequin. In our case, there is just one class.
# dict maping class_id to class_name
CLASS_NAMES_DICT = ['fire'] #mannequin.mannequin.names
# class_ids of curiosity
CLASS_ID = [0] Lastly, we are able to run inference on a video.
The next code processes the frames from a supply video specified by SOURCE_VIDEO_PATH and are processed utilizing a {custom} object detection mannequin and probably tracked utilizing the BYTETracker. Annotations are then added to the frames, and the processed frames are written to a brand new video file specified by TARGET_VIDEO_PATH.
from tqdm.pocket book import tqdm # create BYTETracker occasion
byte_tracker = BYTETracker(BYTETrackerArgs())
# create VideoInfo occasion
video_info = VideoInfo.from_video_path(SOURCE_VIDEO_PATH)
# create body generator
generator = get_video_frames_generator(SOURCE_VIDEO_PATH)
# create occasion of BoxAnnotator
box_annotator = BoxAnnotator(shade=ColorPalette(), thickness=2, text_thickness=2, text_scale=1) # open goal video file
with VideoSink(TARGET_VIDEO_PATH, video_info) as sink: # loop over video frames for body in tqdm(generator, complete=video_info.total_frames): # mannequin prediction on single body and conversion to supervision Detections outcomes = mannequin(body) detections = Detections( xyxy=outcomes[0].containers.xyxy.cpu().numpy(), confidence=outcomes[0].containers.conf.cpu().numpy(), class_id=outcomes[0].containers.cls.cpu().numpy().astype(int) ) # format {custom} labels labels = [ f"{CLASS_NAMES_DICT[class_id]} {confidence:0.2f}" for _, confidence, class_id, tracker_id in detections ] # annotate and show body body = box_annotator.annotate(body=body, detections=detections, labels=labels) sink.write_frame(body)Within the code given above, an occasion of the BYTETracker class is created. Then, a VideoInfo occasion is created by extracting frames from a supply video positioned at SOURCE_VIDEO_PATH. The subsequent line units up a body generator utilizing a operate known as get_video_frames_generator. This generator is probably going used to iterate by means of frames of the supply video one after the other.
We additionally created an occasion of BoxAnnotator. This object is used for annotating frames, probably including bounding containers and textual content to spotlight objects or options within the video frames.
Subsequent, we create an occasion of the VideoSink class. TARGET_VIDEO_PATH is the trail the place the processed video might be saved, and video_info accommodates details about the video to be saved. The with assertion means that this object handles the writing of processed frames to the goal video file.
A loop iterates by means of the frames of the supply video and visually tracks the progress of body processing. For every body, our pc imaginative and prescient mannequin is utilized to retrieve predictions of the placement of fireside. The body is handed as enter to the mannequin, and the outcomes are saved. These outcomes embrace details about detected objects, and its confidence scores.
Whereas the above code is working and writing the outcomes file, this system shows the variety of objects detected in every body that’s being created.
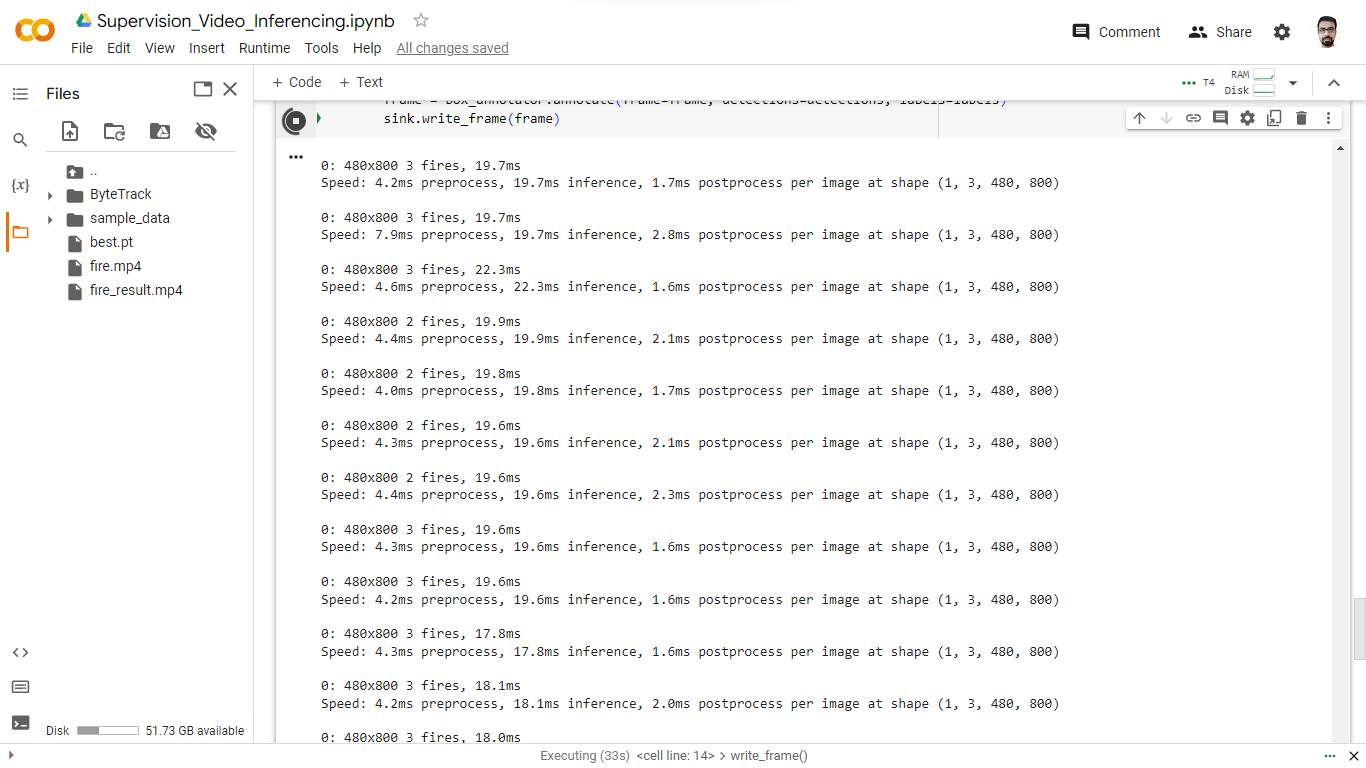
The resultant video under, present the detected class with bounding field.

Conclusion
On this undertaking, we developed a hearth detection system utilizing pc imaginative and prescient methods and a custom-trained YOLOv8 mannequin. This technique is designed to establish cases of fireside in each pictures and video streams, enabling early detection and speedy response to mitigate potential disasters.
By means of the described project-building steps on this weblog, a hearth detection system could be created that leverages pc imaginative and prescient, object detection, and monitoring methods. This technique contributes to early fireplace detection, offering beneficial time for response groups to take obligatory actions, in the end enhancing security and decreasing the impression of wildfires.
All code for this undertaking is offered at github. The dataset used for this undertaking is offered on Roboflow Universe.



