Convey this undertaking to life
On this weblog, we now have lengthy espoused the utility of Secure Diffusion for all kinds of pc imaginative and prescient duties, not simply textual content to picture synthesis. Specifically, Secure Diffusion has additionally confirmed to be a particularly succesful instrument for picture modifying, 3D modeling, and way more.
Moreover, picture upscaling and blind picture restoration stay some of the seen and utilitarian functions of AI accessible to a client in the present day. Since final years GFPGAN and Actual ESRGAN, efforts on this area have confirmed extraordinarily succesful in duties like background element restoration and face upscaling. Blind Picture Restoration is the area of AI that seeks to deal with these and comparable duties.
On this weblog submit, we’ll take a look at one of many newest and best efforts to deal with this job: DiffBIR. By leveraging the intense functionality of the Secure Diffusion mannequin, DiffBIR allows simplistic and simple to implement picture restoration for each common picture restoration and faces. Readers can count on to be taught the fundamentals of how the mannequin works and was skilled, and we’ll then bounce right into a stroll by way of of the Gradio software the authors supplied. We’ll end with just a few examples we made utilizing the brand new know-how to upscale our photos.
DiffBIR Mannequin Structure

DiffBIR is comprised of two stage pipeline. Within the first Stage, a sequence of operations are carried out on the picture to first generate a degraded illustration of the unique top quality picture in low high quality. The blur-resize-noise course of happens 3 times. The pretrained restoration mannequin then works to first take away the degradations within the low high quality photos. The generative mannequin then reproduces the misplaced data, which forces the latent diffusion mannequin’s restoration course of to give attention to the feel and element era with out being affected by noise. This promotes a way more sturdy reconstruction.
To attain this, they use a modified SwinIR because the restoration mannequin. Particularly, they made a number of adjustments to make the most of the pixel unshuffle operation to downsample the enter ILQ by an element of 8. Subsequent, a 3 × Three convolutional layer is adopted to enhance shallow characteristic extraction. All the next transformer operations are carried out in low decision house, which has similarities to latent diffusion modeling. The deep characteristic extraction adopts a number of Residual Swin Transformer Blocks
(RSTB), and every RSTB has a number of Swin Transformer Layers (STL). Take a look at this weblog submit for a particulars breakdown on SwinIR for extra details about what this entails. The shallow and deep options are added in an effort to keep each the low-frequency and high-frequency data. To upsample the deep options again to the unique picture house, the mannequin performs nearest interpolation 3 times. Every interpolation is adopted by one convolutional layer in addition to one Leaky ReLU activation layer. Additionally they optimized the parameters of the restoration module by minimizing the L2 pixel loss. This course of might be represented by the equation under:
For Stage 2, the pipeline makes use of the output from stage 1 obtained by regression studying and to make use of for the fine-tuning of the latent diffusion mannequin. This is named the situation latent when the diffusion mannequin’s VAE maps this into the latent house. This follows the usual diffusion mannequin course of, the place the diffusion and denoising processes are carried out within the latent house by including Gaussian noise with variance at every step t to the encoded latent z = E(x) for
producing the noisy latent, as represented by:
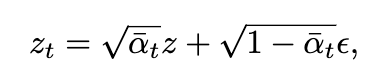
A community ϵθ is realized by predicting the noise ϵ conditioned on c (i.e., textual content prompts) at a randomly picked time-step t. The optimization of latent diffusion mannequin is outlined as follows:
For the reason that stage 1 restoration course of tends to go away a very smoothed picture, the pipeline then works to leverage the pre-trained Secure Diffusion for picture reconstruction with the obtained Ireg –IHQ pairs. First, they make the most of the encoder of Secure Diffusion’s pretrained VAE to map Ireg into the latent house, and procure the situation latent E (equal to Ireg ). Then, the UNet runs typical latent diffusion. In parallel, there may be a further path that accommodates the identical encoder and center block because the UNet denoiser. There, it concatenates the situation latent E (Ireg ) with the randomly sampled noisy zt because the enter for the
parallel module. The outputs of the parallel module are added to the unique UNet decoder. Furthermore, one 1 × 1 convolutional layer is utilized earlier than the addition operation for every scale.
Throughout fine-tuning, the parallel module and these 1 × 1 convolutional layers are optimized concurrently, the place the immediate situation is ready to empty. The mannequin goals to reduce the next latent diffusion goal. The obtained consequence on this stage is denoted as Idiff, and represents the ultimate restored output. Collectively, this course of is named LAControlNet by the unique authors.
To summarize the method, solely the skip-connected options within the UNet denoiser are tuned for our particular job. This technique alleviates overfitting when coping with our small coaching dataset, whereas permitting inheritance of the potential for high-quality era from Secure Diffusion. The conditioning mechanism is extra simple and efficient for picture reconstruction job
in comparison with different strategies like ControlNet, which makes use of a further situation community skilled from scratch for encoding the situation data.
In DiffBIR’s LAControlNet, the well-trained VAE’s encoder is ready to undertaking the situation photos into the identical illustration house because the latent variables. This
technique considerably alleviates the burden on the alignment between the inner data in latent diffusion mannequin and the exterior situation data. In observe, instantly using ControlNet for picture reconstruction results in extreme colour shifts as proven within the ablation research. In observe, this full pipeline course of permits for the extraordinarily top quality blind picture restoration that the mannequin boasts.
Run DiffBIR in a Paperspace Pocket book
Convey this undertaking to life
Now that we went over the underlying ideas behind DiffBIR, lets check out the mannequin in motion. To do that, we’re going to run the DiffBIR demo supplied by the unique repo authors in a Paperspace Pocket book. Click on the hyperlink above, and the demo will open in a brand new browser tab. Click on the beginning button within the high left to begin up the pocket book, and navigate to the DiffBIR.ipynb pocket book.
We ran our checks for this demo on a single A100-80GB machine. Customers can click on the hyperlink above to get entry to this demo on a Free GPU. Contemplate upgrading to our development or professional plans for entry to a greater diversity of free machines at the price of a single month-to-month fee! This will speed up your course of enormously compared to the M4000 utilized by the Free GPUs.
Setup
As soon as our pocket book is spun up and we’re within the demo Ipython pocket book, we will start by operating the primary 2 code cell. The primary will set up the required packages to run the demo, and the second will obtain all of the mannequin checkpoints required. We advocate skipping the second cell on subsequent runs to keep away from the roughly 5 minute obtain. The code for this cell could also be discovered under:
!pip set up -r necessities.txt !pip set up -U gradio Then to obtain the fashions from HuggingFace, we run the subsequent cell:
!mkdir weights
%cd weights
!wget https://huggingface.co/lxq007/DiffBIR/resolve/important/general_swinir_v1.ckpt
!wget https://huggingface.co/lxq007/DiffBIR/resolve/important/general_full_v1.ckpt
!wget https://huggingface.co/lxq007/DiffBIR/resolve/important/face_swinir_v1.ckpt
!wget https://huggingface.co/lxq007/DiffBIR/resolve/important/face_full_v1.ckpt
%cd ..Working the demo
Now that we now have all the things setup, we will get began. Within the subsequent code cell, all we have to do is run the cell to get our demo spun up. Click on the shared hyperlink to open the Gradio demo in your browser
!python gradio_diffbir.py
--ckpt weights/general_full_v1.ckpt
--config configs/mannequin/cldm.yaml
--reload_swinir
--swinir_ckpt weights/general_swinir_v1.ckpt
--device cudaTesting with the demo
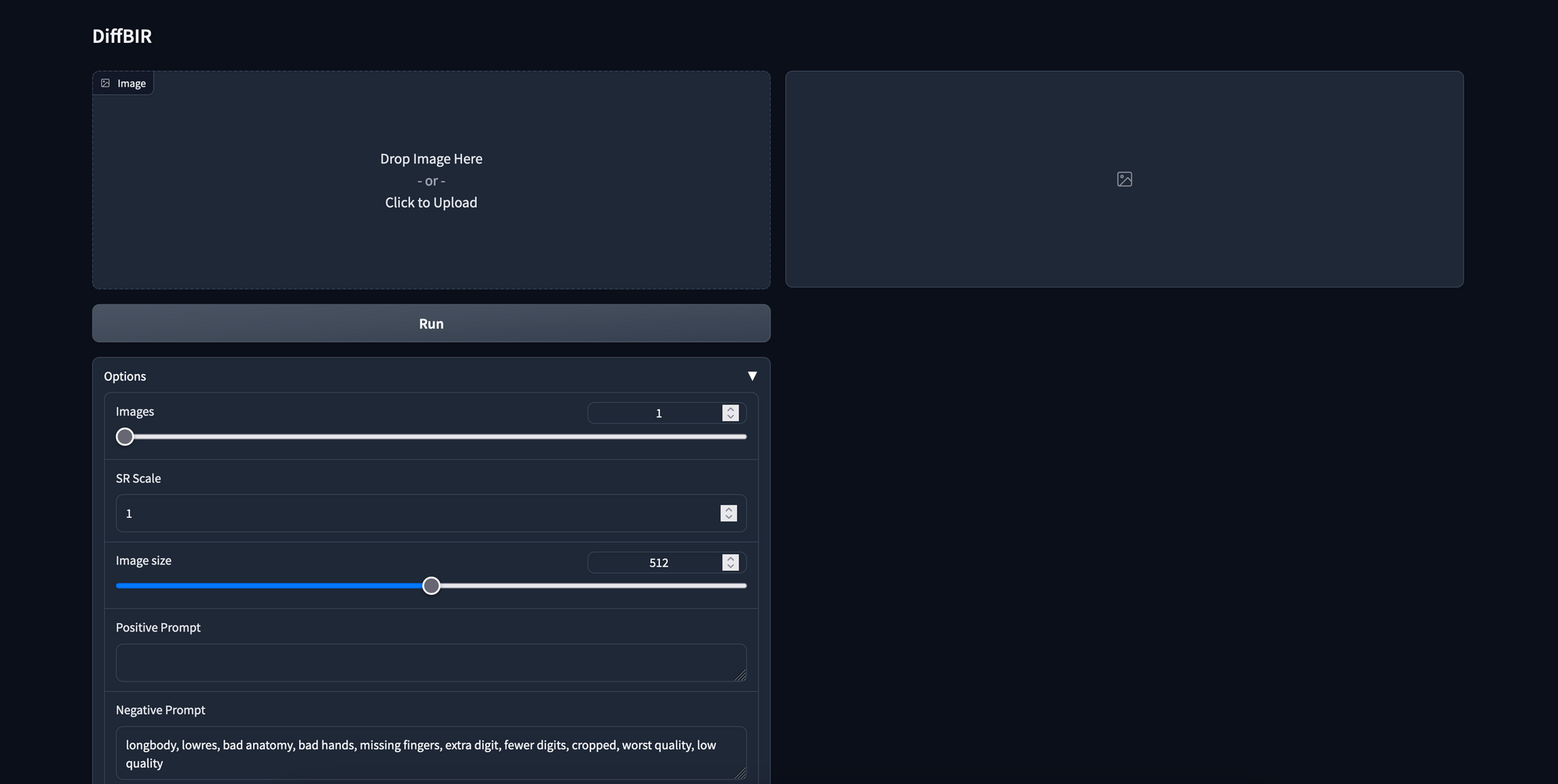
To check out the demo, we discovered a free icon picture of a metropolis with a mountainous background. We advocate recreating the demo to get a really feel for the way the mannequin works. There’s a copy of the picture we used and its immediate under:

We ran our Blind Picture Restoration take a look at on the above picture with the next settings:
- SR Scale (what number of instances bigger to make the picture): 4
- Picture dimension (output dimension earlier than scaling, in pixels): 512
- Optimistic immediate (for Secure Diffusion steering): a metropolis with tall buildings, forest bushes, snowy mountain background
- Damaging immediate: longbody, lowres, unhealthy anatomy, unhealthy arms, lacking fingers, further digit, fewer digits, cropped, worst high quality, low high quality
- Immediate Steerage Scale (how a lot impact the immediate has on upscaling, zero will take away impact): 1
- Management Power (how a lot unique picture guides reconstruction for LAControlNet): 1
- Steps: 50
- Seed: 231

As we will see, the mannequin succeeds in engaging in a substantial amount of upscaling. For effective particulars, we will see proof of the fashions efficacy particularly by zooming in on the snowcaps of the mountains and the workplace home windows. The extent of element there may be very full. In fact, it is not good. Discover the pointed roof buildings in the direction of the left of the picture. Within the blind picture restoration model on the proper, the roofs have taken on a wierd slope and mixing impact with the constructing behind it.
As for extra coarse particulars, the shadows on the aspect of the mountain and contiguity of the blue sky are nice proof for the fashions efficacy. Once more, the other might be seen within the forest greenery under the buildings. These seem virtually like bushes quite than units of full bushes.
All in all, from a qualitative perspective, there’s a minimal uncanny valley impact. The one actual presence we will see of it’s with these curved roofs. In any other case, from our perspective, this looks as if a superb instrument for fast picture upscaling. When mixed with different instruments like Actual ESRGAN and GFPGAN, we might even see these capabilities taken even additional.
We advocate testing the complete face and full fashions on quite a lot of take a look at photos with totally different parameters to get higher outcomes. We hope this instrument generally is a nice new addition to customers arsenals for picture manipulation with AI.
Closing Ideas
DiffBIR provides a extremely useful new instrument for picture restoration with AI. For each faces and common photos, the method exhibits unimaginable promise. Within the coming weeks, we plan to check this method out on previous household photographs to see how its capabilities stack up.
For some inspiration, we advocate utilizing the icon dimension search in google photos. This mannequin works greatest on smaller photos. Something bigger than 720p will doubtless exceed the GPUs reminiscence capability. Get pleasure from utilizing DiffBIR with Paperspace!


