Multimodality, which includes combining varied knowledge enter codecs akin to textual content, video, and audio in a single mannequin, will undoubtedly turn out to be one of many important instructions for AI progress within the coming years. Massive Multimodal Fashions (LMMs) skill to course of and interpret the contents of photos is normally restricted. It comes down primarily to Object Character Recognition (OCR), Visible Query Answering (VQA), and Picture Captioning.
Detection and segmentation are out of the query until you employ intelligent prompts. On this publish, I am going to present you increase the vary of LMMs’ capabilities utilizing Multimodal Maestro.
Set-of-Marks
The authors of the Set-of-Mark Prompting Unleashes Extraordinary Visible Grounding in GPT-4V paper found that you may unleash LMM grounding talents by skillful visible prompting. Successfully enabling object detection and even segmentation.
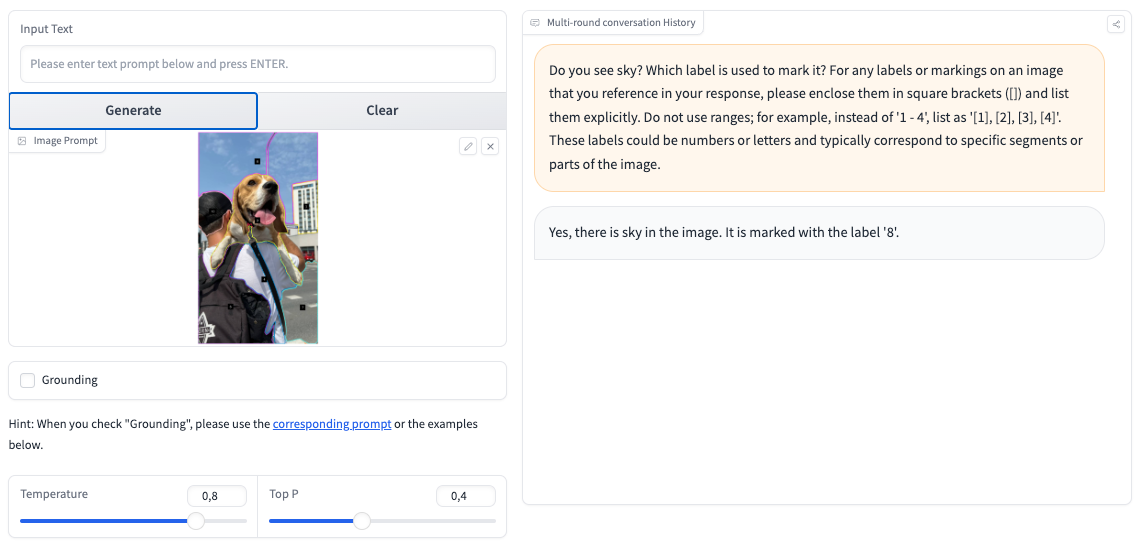
As an alternative of importing the picture on to the LMM, we first improve it with marks generated by GroundingDINO, Phase Something Mannequin (SAM), or Semantic-SAM. Because of this, the LMM can consult with the added marks whereas answering our questions.

Multimodal Maestro
Impressed by Set-of-Mark, we created a library to facilitate the prompting of LMMs. Introducing Multimodal Maestro!
The library consists of superior prompting methods that permit for higher management and, in consequence, a greater consequence from LMMs.

Prompting GPT-Four Imaginative and prescient
Multimodal Maestro can considerably increase GPT-Four Imaginative and prescient’s capabilities and allow detection and/or segmentation. As an experiment, let’s ask GPT-4V to detect the crimson apples within the picture. GPT-4V can not return packing containers or segmentation masks, so it tries to explain the place of the search objects utilizing language.

With Multimodal Maestro, we will create a picture immediate within the Set-of-Mark type and ask the query once more. This time, the output is a lot better.
There are six apples that seem crimson within the picture. These apples are labeled with the next numbers: [1], [3], [5], [6], [8], and [9].
Prompting CogVML
OpenAI’s GPT-Four Imaginative and prescient is probably the most acknowledged amongst LMMs however there are different choices. Our newest weblog publish explored 4 outstanding options to GPT-4V: LLaVA, BakLLaVA, Qwen-VL, and CogVLM. CogVLM emerged as a powerful contender, demonstrating spectacular capabilities in Visible Question Language (VQL), Optical Character Recognition (OCR), and zero-shot detection, rivaling GPT-4.
We determined to check whether or not CogVLM may use marks generated by Multimodal Maestro, and the outcomes exceeded our expectations.
Conclusions
LMMs can do much more than we thought. Nonetheless, there’s a lack of a handy interface for us to speak with them.
Within the coming weeks, we are going to add extra methods to Multimodal Maestro to make use of LMM extra successfully. Keep tuned and star the repository to comply with our progress. New options – and prompts – are coming quickly!


