Google Cloud Imaginative and prescient is a set of APIs made by Google for a wide range of vision-based duties designed to be simply built-in to allow visible intelligence for apps. They provide object detection of generic objects, optical character recognition (OCR), doc detection/recognition, and the flexibility to coach {custom} detection fashions.
On this information, we are going to go over how one can consider how properly Google’s Cloud Imaginative and prescient generic object detection API (additionally referred by Google as object localization) performs towards different accessible fashions and APIs. That is useful to ensure you are selecting the most effective mannequin on your use case. We’ll use a custom-trained mannequin in Roboflow Universe in detecting individuals for our instance comparability.
Step 1: Discovering an analysis dataset
For this instance, we are going to say that we need to detect individuals and we wish a mannequin that can carry out properly at detecting individuals in all kinds of eventualities. To discover a good dataset, we will search Roboflow Universe for a skilled object detection mannequin.
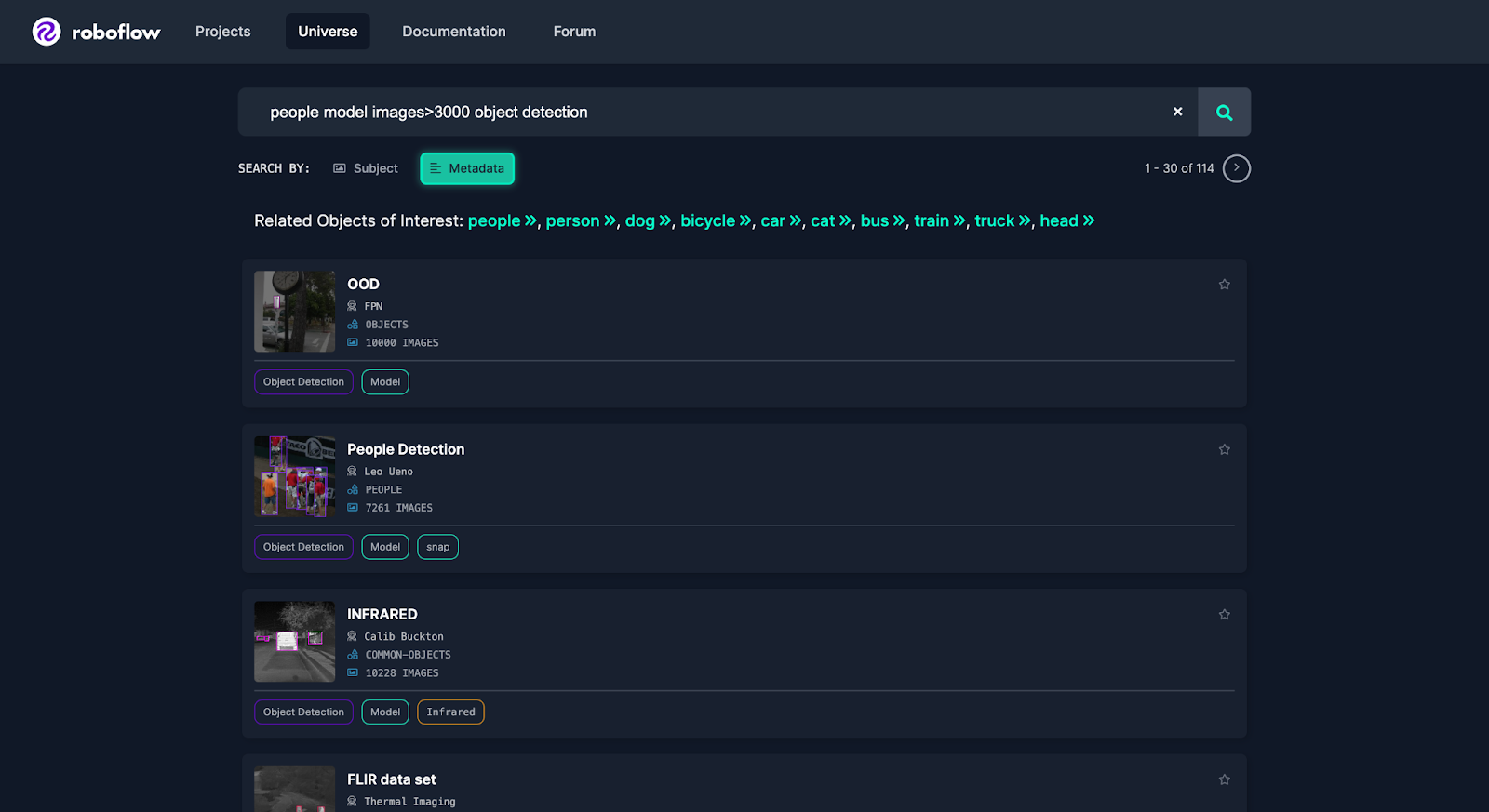
On this case, to judge how the fashions will carry out in a wide range of settings we are going to use a big, generalized, numerous dataset like COCO. For this instance, we’ll use a Universe dataset of a subset of COCO restricted to individuals.
Non-obligatory: Create your individual mannequin or analysis dataset
When you have your individual use case that you simply wish to evaluate towards Google Cloud Imaginative and prescient, you may create your individual dataset and prepare a mannequin, then evaluate that custom-trained mannequin towards how Google Cloud Imaginative and prescient performs.
For instance, you possibly can seize round 100 pictures or movies from the place you’d wish to deploy your mannequin after which add the photographs to Roboflow.
You possibly can shortly annotate them and even have Autodistill label the photographs for you.
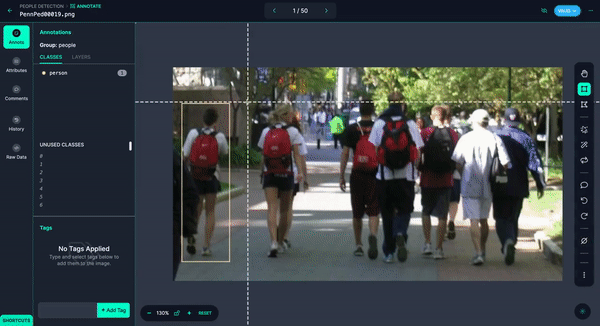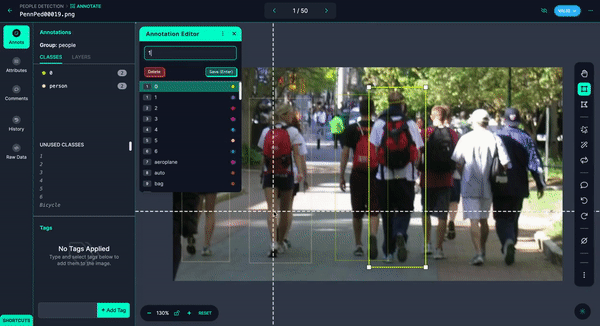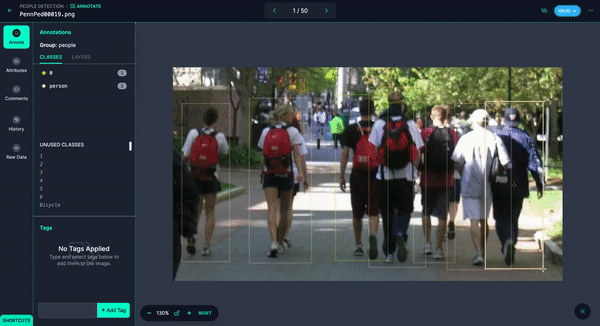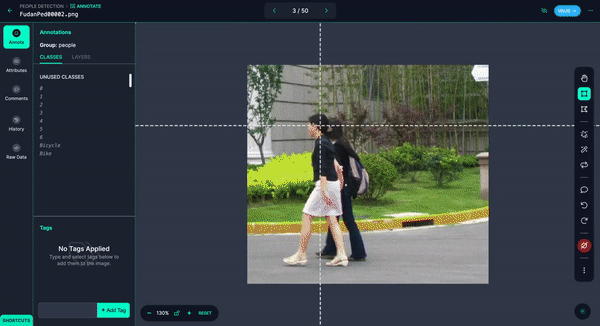
Upon getting your pictures annotated, you may add and modify preprocessing and augmentations, then generate a model.

After making a model, you may prepare your mannequin with one click on.
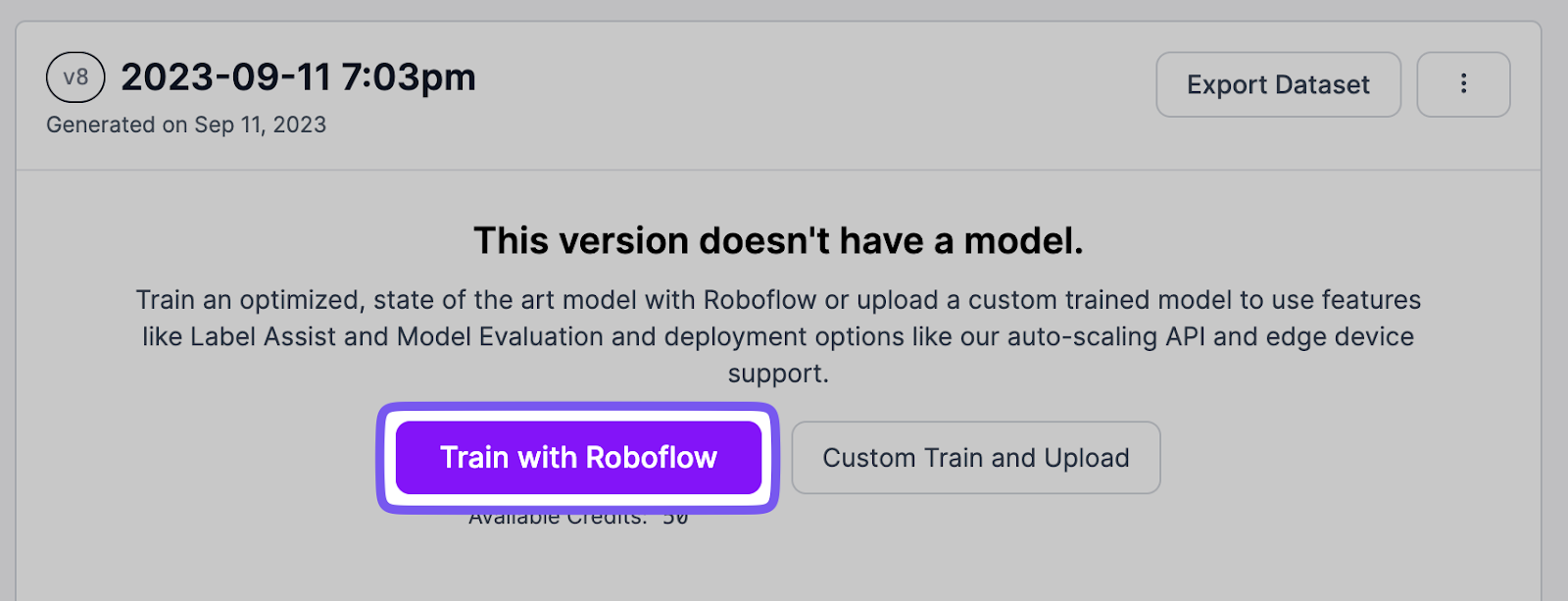
Then, proceed by way of this information the identical means, however exchange the mannequin with your individual to obtain your venture.
Step 2: Consider mannequin efficiency
As soon as we’ve got our fashions and an analysis dataset, we will take a look at the fashions and produce the mAP for each fashions utilizing supervision’s mAP benchmark characteristic.
First, we’ll import the `roboflow` and `supervision` packages.
!pip set up supervision roboflow
Obtain the Analysis Dataset
Now, we’ll obtain our analysis dataset and use the `DetectionDataset.from_coco()` technique to get it into supervision.
from roboflow import Roboflow
rf = Roboflow(api_key="**YOUR API KEY HERE**")
venture = rf.workspace("shreks-swamp").venture("coco-dataset-limited--person-only")
dataset = venture.model(1).obtain("coco")To do that by yourself or with your individual dataset, click on on the Obtain this Dataset button on any object detection dataset on Universe and export in COCO format.
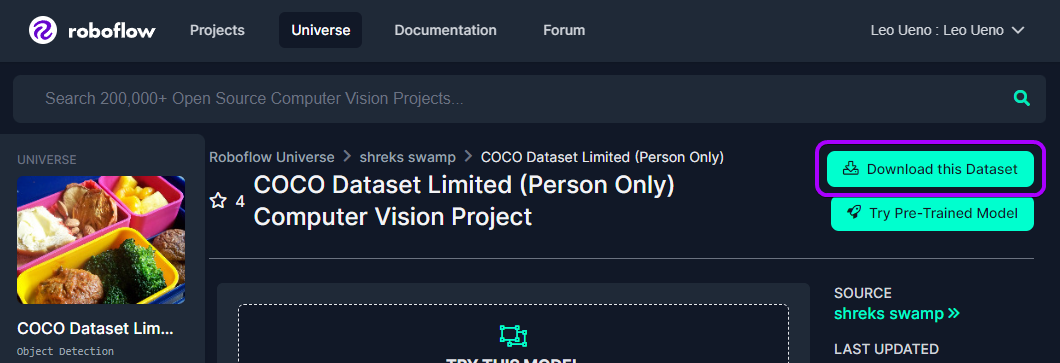
Testing the Cloud Imaginative and prescient Mannequin
First, we might want to get arrange authenticating with Google. In the event you haven’t used Google Cloud’s APIs earlier than, follow this information from Google to create a service account JSON file for the Google Cloud Imaginative and prescient API, then proceed with this information.
Arrange the service account JSON you bought with this code:
from google.oauth2.service_account import Credentials credentials = Credentials.from_service_account_file( filename="tester-1490046330330-d33ad7bf6f84.json" # Change with the file identify of your service account file
)Then, we arrange a callback operate in order that supervision can run the mannequin towards the photographs in our analysis dataset.
def callback(np_image): img = Picture.fromarray(np_image) buffer = io.BytesIO() img.save(buffer, format='PNG') # You'll be able to change the format as wanted, e.g., JPEG buffer.search(0) image_bytes = buffer.learn() picture = imaginative and prescient.Picture(content material=image_bytes) objects = shopper.object_localization(picture=picture).localized_object_annotations sv_result = sv.Detections.from_gcp_vision(gcp_results=objects, measurement=(img.peak,img.width)) picture = cv2.cvtColor(np_image, cv2.COLOR_RGB2BGR) bounding_box_annotator = sv.BoundingBoxAnnotator(coloration=sv.Shade.from_hex("#FF0000")) annotated_frame = bounding_box_annotator.annotate( scene=picture, detections=sv_result ) sv.plot_image(picture=picture, measurement=(3, 3)) return sv_resultNow we calculate the mannequin’s mAP for our dataset by passing it to supervision’s mAP benchmark operate.
mean_average_precision = sv.MeanAveragePrecision.benchmark(
dataset = sv_dataset,
callback = callback
)Then, we ran the Cloud Imaginative and prescient API towards the analysis dataset and bought a results of 64.7%.

Testing the Roboflow Universe Mannequin
Subsequent, we’ll evaluate the opposite mannequin. We will consider that mannequin by finishing the identical course of we simply did, however by modifying the callback and filling in our mannequin information.
We’ll load our first mannequin utilizing our API key and venture ID of the mannequin.
api_key = "YOUR API KEY HERE"
project_id = "people-detection-o4rdr"
rf = Roboflow(api_key)
venture = rf.workspace().venture(project_id)
mannequin = venture.model(1).mannequinThen, we arrange a callback operate once more.
def callback(np_image): picture = cv2.cvtColor(np_image, cv2.COLOR_RGB2BGR) outcome = mannequin.predict(picture, confidence=45, overlap=50).json() sv_result = sv.Detections.from_roboflow(outcome) bounding_box_annotator = sv.BoundingBoxAnnotator(coloration=sv.Shade.from_hex("#FF0000")) annotated_frame = bounding_box_annotator.annotate( scene=picture, detections=sv_result ) sv.plot_image(picture=picture, measurement=(3, 3)) return sv_resultThen, we calculate the mAP once more utilizing supervision’s mAP benchmark.
mean_average_precision = sv.MeanAveragePrecision.benchmark(
dataset = sv_dataset,
callback = callback
)Then, we run our analysis once more on the Roboflow mannequin.
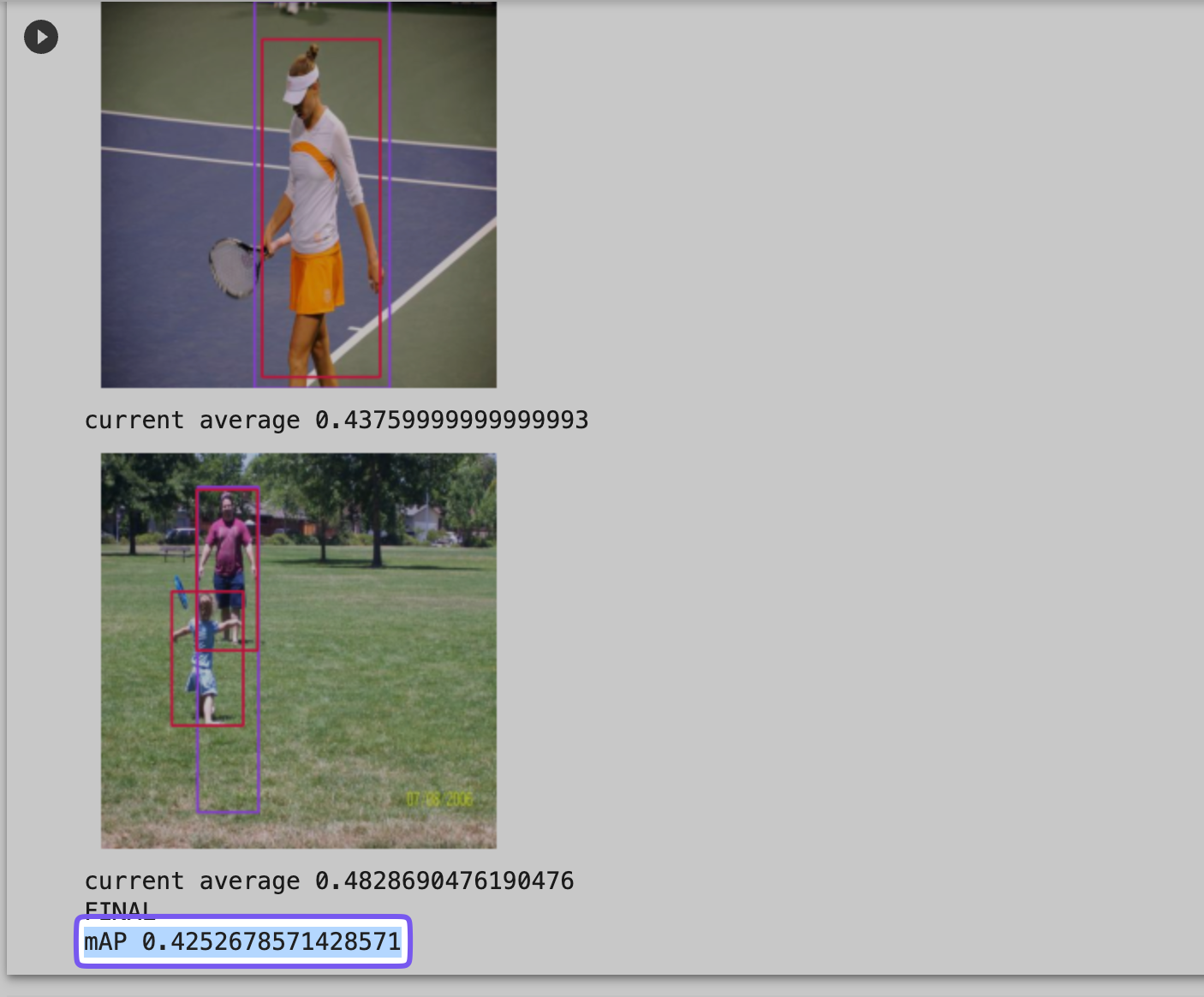
Outcomes
The outcomes from COCO (the dataset we simply used to judge our fashions), and the improved efficiency of GCP Imaginative and prescient’s API in comparison with the Universe mannequin, exceeded our expectations, particularly when contemplating our restricted handbook testing of the API.
So, we carried out three extra experiments to find out three issues:
- Does this efficiency maintain up in different information/datasets?
- Is Google Cloud Imaginative and prescient’s object detection API powered by Microsoft COCO?
- If that’s the case, what was the precise effectiveness of Google’s mannequin
Roboflow Individual Dataset Analysis
To find out whether or not Google’s mannequin efficiency held up in different datasets, we evaluated it on the take a look at dataset of the Universe individual detection mannequin we simply used. We additionally evaluated one other mannequin, an object detection mannequin on Universe skilled on COCO, an add of a notebook-trained YOLOv8n mannequin.

Though these outcomes are removed from definitive that Google Cloud Imaginative and prescient runs on a Microsoft COCO mannequin, the uncanny similarity in efficiency means that they could use related datasets or that Google could have skilled their mannequin from a COCO checkpoint.
This may increasingly clarify the improved efficiency of GCP Imaginative and prescient’s mannequin in our prior take a look at. Fashions fairly often predict with a better accuracy on pictures which have been or are much like these “seen earlier than”/skilled on. This is the reason mAP doesn’t at all times present all the image.
Various Analysis Dataset
To pretty consider all three fashions, we are going to consider these fashions a 3rd and ultimate time on a dataset that every one fashions have probably not seen earlier than. We used one other individual detection dataset from Roboflow Universe. These have been the outcomes of working the prior assessments once more on this new dataset:

Conclusion
Being able to correctly consider completely different fashions throughout completely different platforms could be an efficient device in deciding which mannequin most closely fits any explicit use case. Whereas the ultimate analysis dataset did lead to greater efficiency from one mannequin on Universe, it doesn’t essentially equate to good efficiency in your use case. We encourage you to gather your real-world information to not solely consider how fashions carry out in your information, however to additionally be capable of prepare your individual mannequin.


