On December sixth, 2023, Google introduced Gemini, a brand new Massive Multimodal Mannequin (LMM) that works throughout textual content, photographs, and audio. Gemini’s textual content capabilities have been launched into Bard on the identical day, with an announcement that multimodality could be coming to Bard quickly.
On December 13th, Google launched an API for Gemini, permitting you to combine the Gemini mannequin straight into your functions.
The Roboflow crew has analyzed Gemini throughout a spread of commonplace prompts that we’ve used to guage different LMMs, together with GPT-Four with Imaginative and prescient, LLaVA, and CogVLM. Our aim is to higher perceive what Gemini can and can’t do effectively on the time of penning this piece.
Right here is how Gemini carried out, the place inexperienced cells denote a mannequin returned an correct response, yellow denote virtually full accuracy, pink denotes a mannequin was unsuitable, and blue means there was a technical challenge stopping us from working a check that was out of our management.
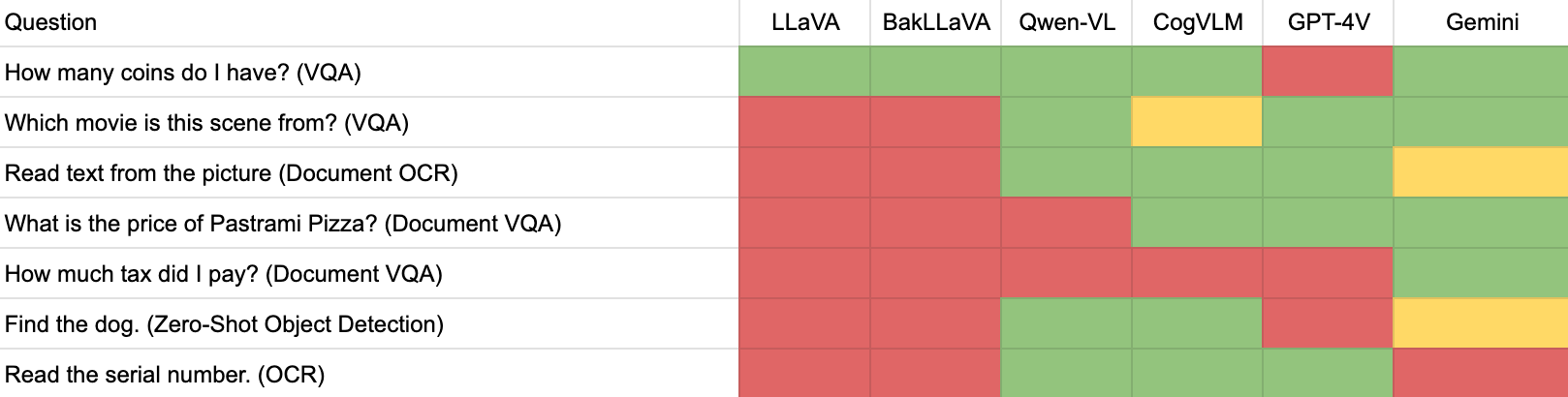
On this information, we’re going to focus on what Gemini is and analyze how Gemini performs throughout a spread of laptop imaginative and prescient duties. We can even share the sources you might want to begin constructing with Gemini. With out additional ado, let’s get began!
What’s Gemini?
Gemini is a Massive Multimodal Mannequin (LMM) developed by Google. LMMs are giant language fashions which might be capable of work with extra “modalities” than textual content. Gemini is able to answering questions on textual content, photographs, and audio.
Gemini launched with demos that present Gemini writing code, explaining math issues, discovering similarities between two photographs, turning photographs into code, understanding “uncommon” emojis, and extra. With that mentioned, there have been claims as to the extent to which a number of demos have been edited, with TechCrunch reporting that their “finest demo was faked.”
Gemini has three variations, designed for various functions:
- Extremely: The biggest mannequin, helpful for conducting complicated duties.
- Professional: A process that may scale throughout a spread of duties.
- Nano: A mannequin to be used in your units (i.e. on cellphones).
A restricted model of Gemini’s textual content capabilities is accessible in Bard on the time of writing this text.
In keeping with Google, the Extremely mannequin, presently unavailable, “exceeds present state-of-the-art outcomes on 30 of the 32 widely-used educational benchmarks utilized in giant language mannequin (LLM) analysis and improvement.” With that mentioned, we’re unable to get arms on with the Extremely mannequin on the time of writing this text.
Gemini is considered one of many LMMs accessible in the present day. GPT-Four with Imaginative and prescient, OpenAI’s multimodal mannequin, launched in September 2023. Different open supply fashions have since launched, together with LLaVA, BakLLaVA, and CogVLM. Thus, there are numerous choices you’ve got accessible if you wish to combine multimodal fashions into your functions.
Find out how to Run Gemini
You possibly can run Gemini utilizing the Google Cloud Vertex AI Multimodal playground. This playground affords an online interface by which you’ll work together with Gemini Professional Imaginative and prescient, which has help for asking questions on photographs. You can even ship requests to the Gemini API by offering a multimodal immediate over HTTP. Learn the Gemini API documentation to study extra.
Evaluating Gemini on Laptop Imaginative and prescient Duties
We have now evaluated Gemini throughout 4 separate imaginative and prescient duties:
- Visible Query Answering (VQA)
- Optical Character Recognition (OCR)
- Doc OCR
- Object Detection
We have now used the identical photographs and prompts we used to guage different LMMs in our GPT-Four with Imaginative and prescient Alternate options publish. That is our commonplace set of benchmarks to be used with studying extra concerning the breadth of capabilities related to key laptop imaginative and prescient duties.
Our assessments have been run within the Gemini net interface.
Check #1: Visible Query Answering (VQA)
We began with a coin check, asking Gemini “What number of cash do I’ve?”:
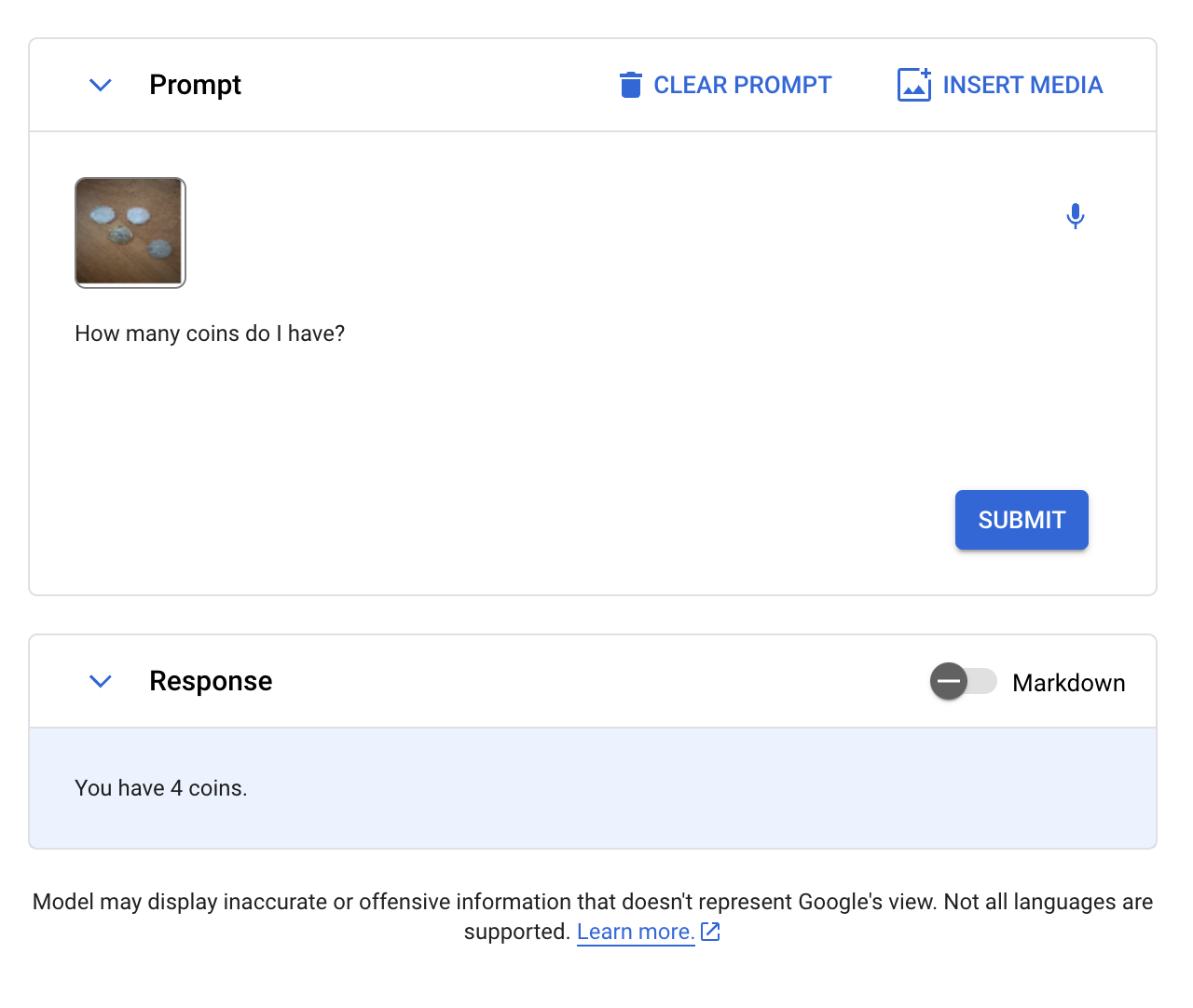
Gemini efficiently counted the variety of cash within the picture. LLaVA, BakLLaVA, Qwen-VL, and CogVLM have been all capable of cross this check, too. GPT-Four with Imaginative and prescient didn’t return an correct response after we examined GPT-Four with Imaginative and prescient with the identical immediate.
We then went on to ask if Gemini might determine which film was featured in a picture. Right here is the picture we despatched to Gemini:

The mannequin efficiently recognized that the film featured was “Dwelling Alone”.
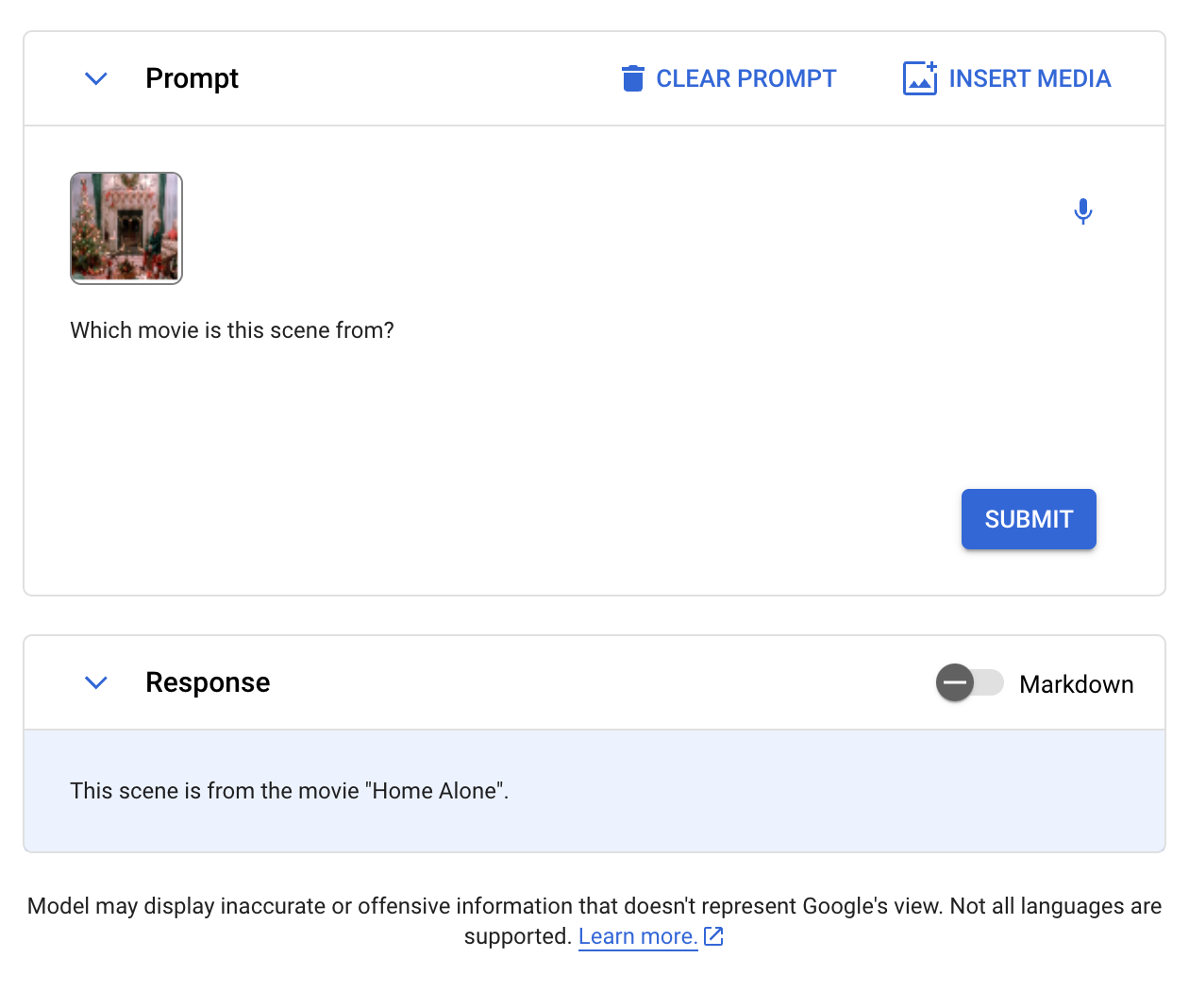
Qwen-VL and GPT-Four with Imaginative and prescient have been each capable of reply this immediate efficiently. LLaVA, BakLLaVA, and CogVLM failed the Dwelling Alone scene check above.
We additionally requested Gemini a query a few menu. Given the menu under, we requested Gemini “What’s the worth of Pastrami Pizza?”

Gemini efficiently answered the query, noting that Pastrami Pizza prices $27:
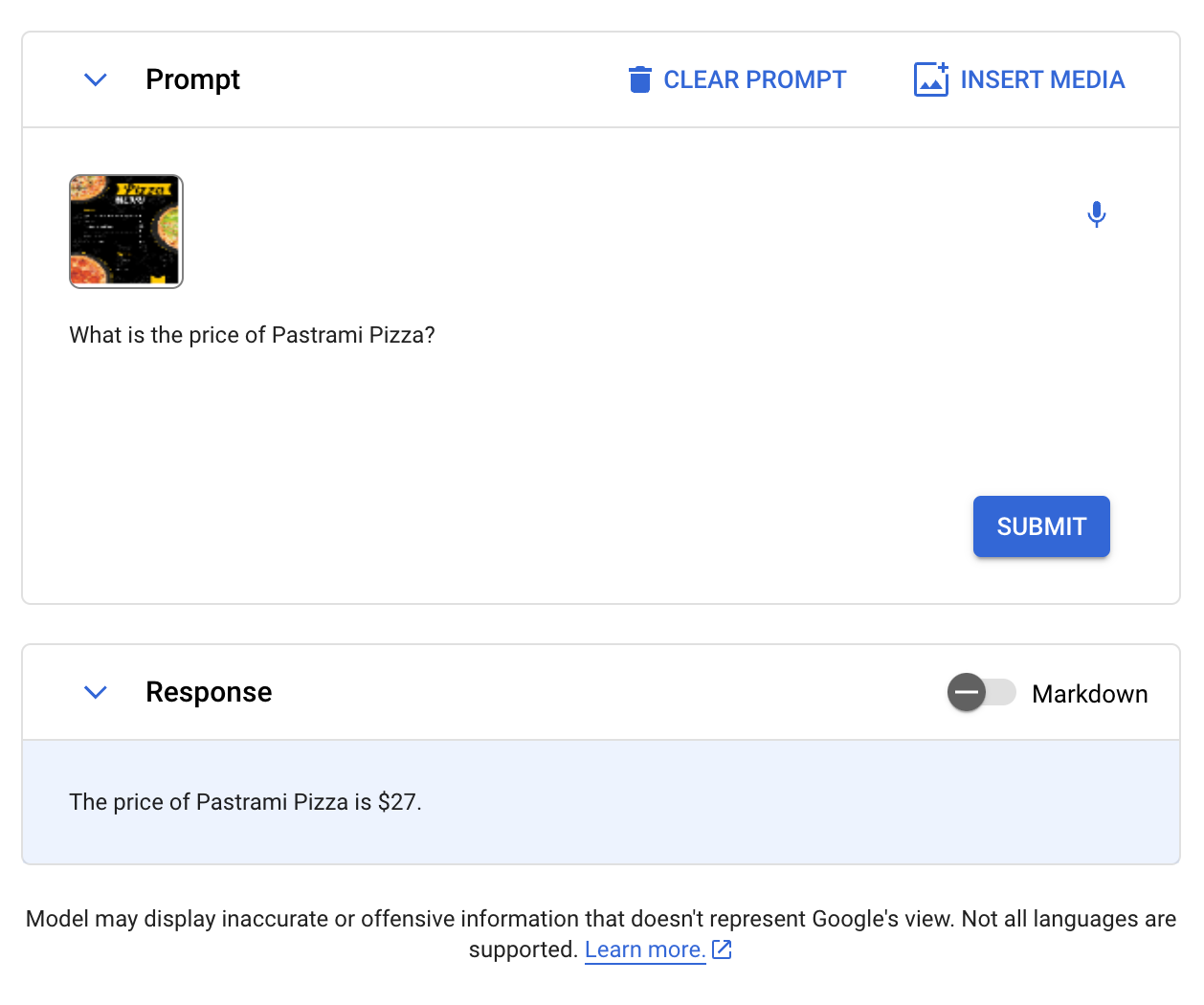
CogVLM, Gemini and GPT-Four with Imaginative and prescient handed this check. LLaVA, BakLLaVA, and Qwen-VL failed the check.
Check #2: Optical Character Recognition (OCR)
We then went on to guage Gemini’s OCR talents. We offered a picture of a tire, asking the mannequin to learn the serial quantity. Right here is the picture we despatched to Gemini:

With our commonplace immediate, “Learn the serial quantity.”, Gemini offered an incorrect response, including letters that weren’t current to the serial quantity. We then revised our immediate to be extra particular, asking “What’s the serial quantity within the picture?”
In each instances, the mannequin was unsuitable.
The bottom fact serial quantity is 3702692432. Gemini mentioned it was 11020422.
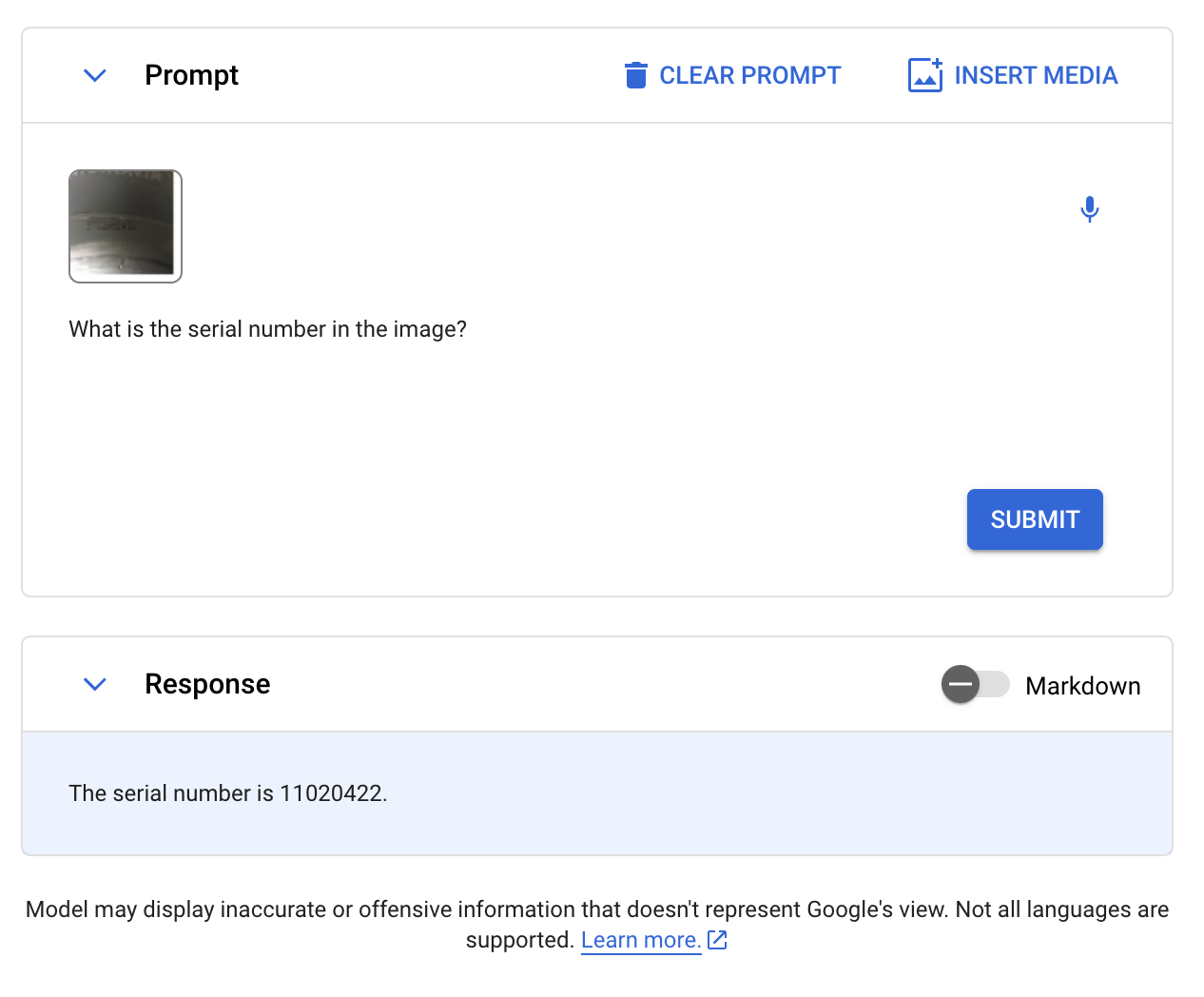
Qwen-VL, CogVLM, and GPT-Four with Imaginative and prescient all answered this query precisely. LLaVA, BakLLaVA, and Gemini did not reply the query precisely.
Check #3: Doc OCR
Subsequent, we evaluated Gemini on doc OCR. We offered the next picture, with the immediate “Learn textual content from the image.”

Gemini was virtually appropriate, however missed a “‘s” within the first sentence compared towards floor fact:
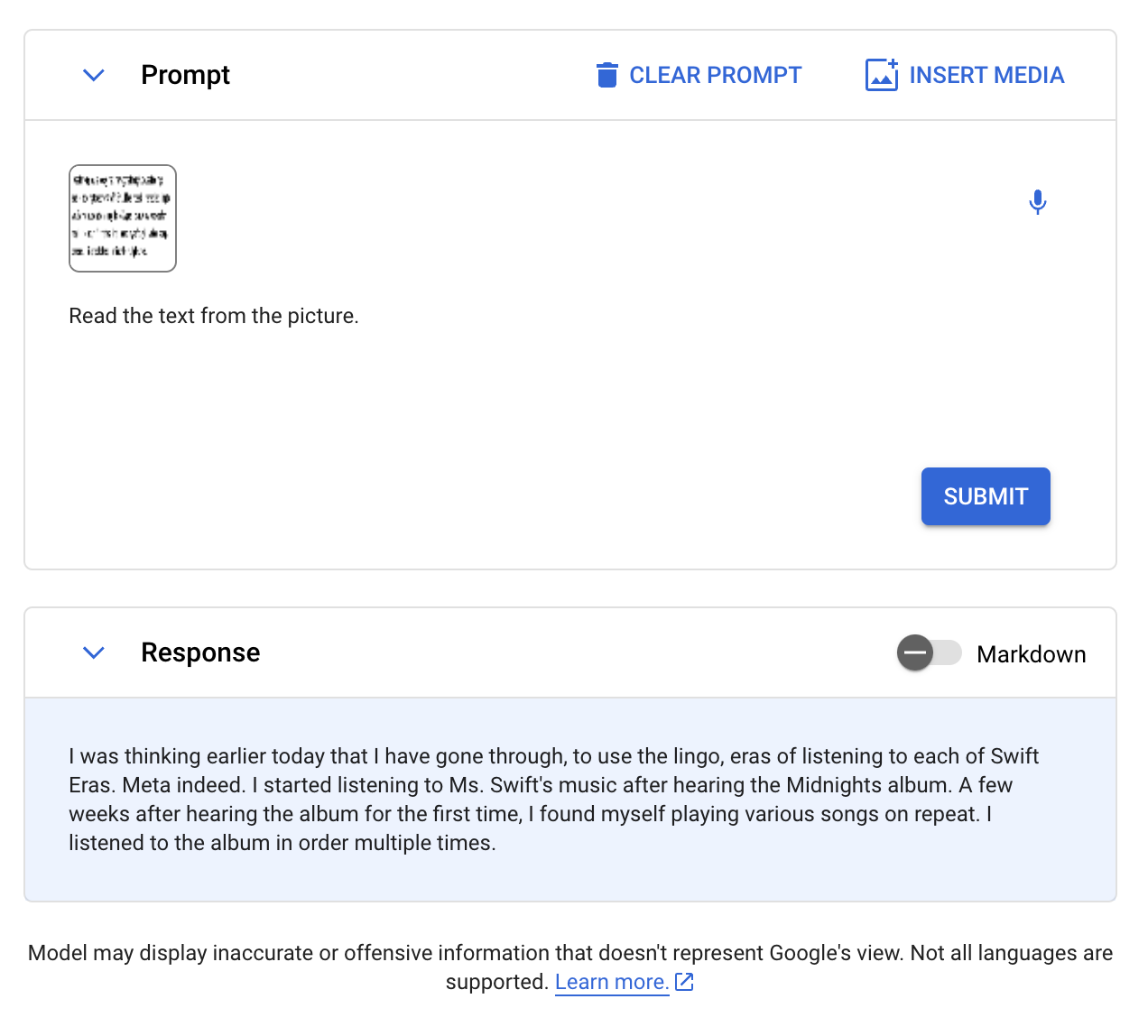
Qwen-VL, CogVLM, and GPT-Four with Imaginative and prescient all handed this check with full accuracy.
We then requested Gemini to retrieve the quantity of tax a receipt states was paid on a meal. Our immediate was “How a lot tax did I pay?” Right here is the picture we despatched to Gemini:

Gemini efficiently answered the query, noting that $2.30 was paid in tax.
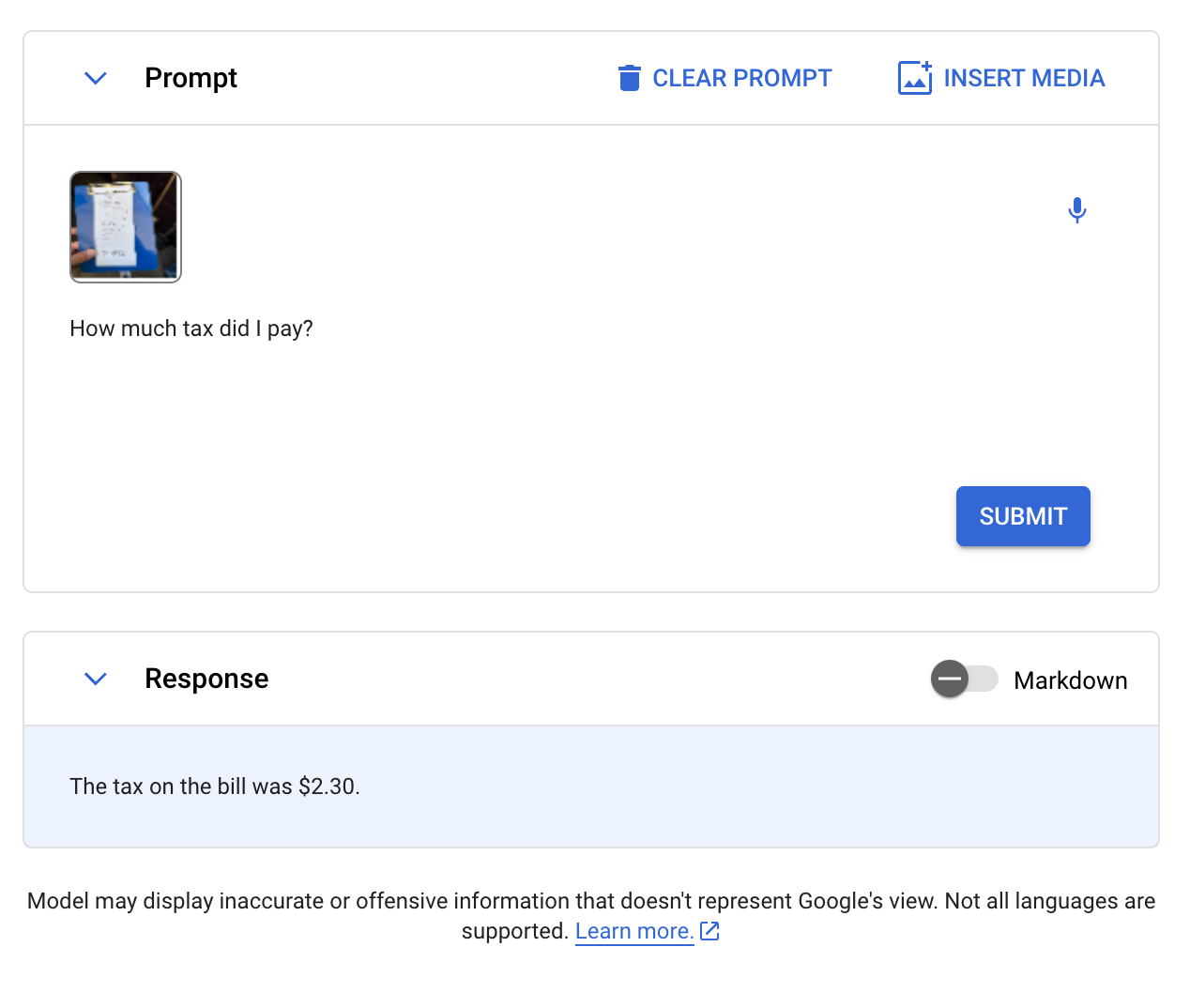
Check #4: Object Detection
Most multimodal fashions we’ve examined battle with object detection. This refers to returning the particular coordinates of an object in a picture. Solely Qwen-VL and CogVLM have been capable of precisely determine the situation of a canine in a picture, our commonplace check.
We prompted Gemini with the textual content “Discover the canine.” and the next picture:

At first, Gemini frequently returned “The mannequin will generate a response after you click on Submit” with this immediate. We are going to replace this publish if we’re capable of get the check working.
We retried requests and prompts, which we suspect isn’t associated to this process as we’ve skilled points working different prompts. We tried the immediate “Discover the x/y/w/h place of the canine, with xy as the middle level.” and obtained the response:
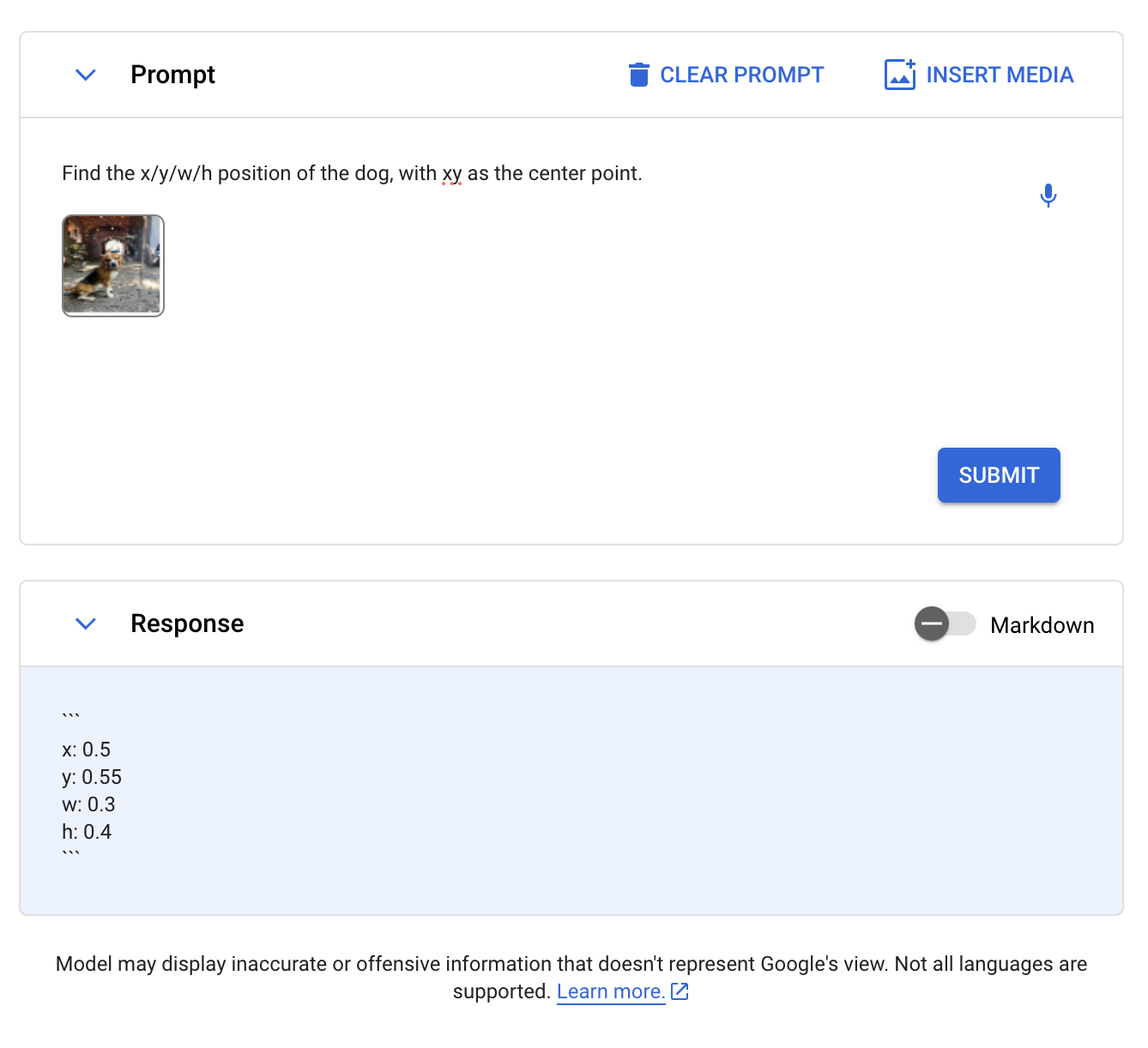
We plotted the coordinates on a picture:

Gemini accurately recognized the overall place of the canine, however the coordinate area solely coated a portion of the canine. It’s unclear if Gemini recognized the middle level or the canine because the canine is within the heart.
We ran one other check, in search of the Christmas tree within the Dwelling Alone picture from earlier on this publish:

The resultant coordinates are invalid.
Conclusion
Gemini is a multimodal mannequin developed by Google. Gemini can work together with textual content, photographs, audio, and code. With Gemini, you possibly can ask questions concerning the contents of photographs, a strong functionality in laptop imaginative and prescient functions.
On this information, we evaluated how Gemini performs throughout a spread of imaginative and prescient duties, from VQA to OCR.
Serious about studying extra about multimodal fashions? Discover our different multimodal content material.



