Mannequin accuracy is a well known metric to gauge a mannequin’s predictive energy. Nonetheless, it may be deceptive and trigger disastrous penalties. Right here is the place precision vs recall is available in.
Think about a pc imaginative and prescient (CV) mannequin for diagnosing cancerous tumors with 99% accuracy. Whereas the mannequin’s efficiency appears spectacular, it’s nonetheless prone to miss 1% of tumor instances, resulting in extreme problems for particular sufferers.
This is the reason we want a toolset of strategies to higher perceive and analyze mannequin efficiency. Recall vs precision are two helpful metrics that permit for higher mannequin analysis. Each additionally function the inspiration for deriving different important metrics, such because the F1 rating and the ROC-AUC metric.
On this article, we’ll talk about:
- Accuracy and its limitations
- Precision, recall, and their trade-off
- F1-score, precision-recall curve, and ROC-AUC
- Multi-class precision and recall
- Use-cases and examples
About us: Viso.ai offers a sturdy end-to-end no-code pc imaginative and prescient answer – Viso Suite. Our software program allows ML groups to coach deep studying and machine studying fashions, and deploy them in pc imaginative and prescient purposes – fully end-to-end. Get a demo.
What’s Accuracy?
Accuracy measures how usually a mannequin predicts the end result accurately relative to the full variety of predictions. The metric has widespread use for measuring mannequin efficiency in pc imaginative and prescient duties, together with classification, object detection, and segmentation.
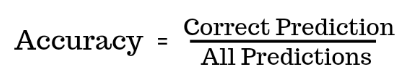
Whereas accuracy is intuitive and simple to implement, it’s only appropriate for situations the place the coaching and validation datasets are comparatively balanced. For skewed datasets, accuracy scores will be unrealistically excessive.
For instance, a CV mannequin for classifying cats can have 95% accuracy if the coaching dataset consists of 95 cat pictures and solely 5 canine pictures. The reason being the mannequin can preserve classifying each picture as a cat and nonetheless be proper 95% of the time because the dataset has only a few canine pictures.
A greater measure ought to acknowledge these prediction inconsistencies and spotlight the variety of incorrect predictions to information the model-building course of accurately.
That’s the place precision and recall come into play. Nonetheless, let’s first talk about the important thing ideas earlier than understanding how precision and recall work.


The Confusion Matrix
A confusion matrix is a desk that gives an in depth breakdown of the mannequin’s predictions by evaluating its output to the precise targets. It visually represents the variety of right and incorrect predictions throughout all courses in optimistic and damaging assignments.
The proper predictions in a confusion matrix are known as true positives (TP) and true negatives (TN). For example, in our cat classification mannequin, true positives are cat pictures that the mannequin accurately labels as “cat,” and true negatives are canine pictures that the mannequin accurately identifies as “canine” or “not cat.”
The inaccurate predictions are known as false positives (FP) and false negatives (FN). For instance, false positives can be canine pictures predicted as cats, and false negatives can be cat pictures predicted as canine.
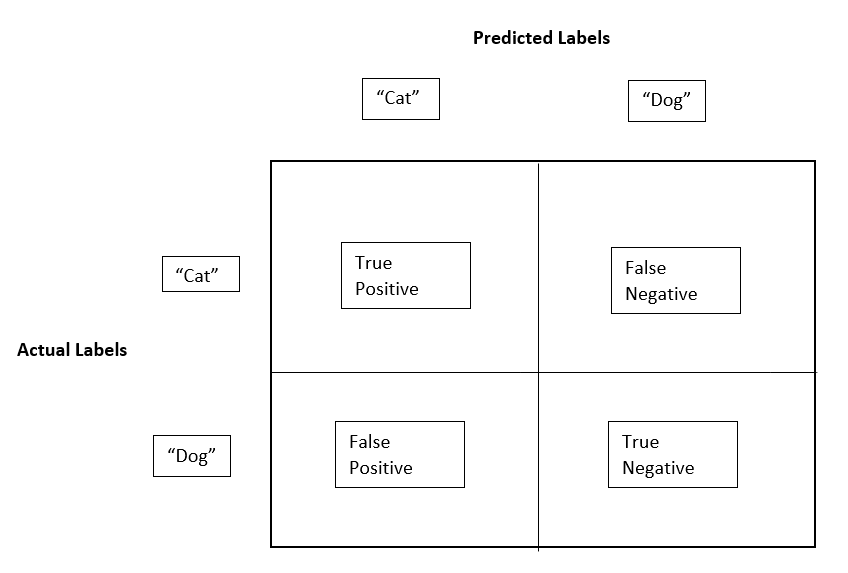
Confusion matrices are important for calculating precision and recall, that are essential metrics for assessing the standard of the classification mannequin.
Precision vs. Recall
The confusion matrix varieties the premise for calculating the precision and recall metrics. The next explains the 2 strategies intimately.
Precision
Precision is a metric that measures the proportion of true positives (right predictions) towards the mannequin’s complete optimistic predictions. The formulation under summarizes the idea.

The precision metric is essential as a result of it focuses on the variety of true positives, that are the right predictions of the optimistic class.
Precision is appropriate in instances the place false positives are pricey. For example, a suggestion system that flags unsafe movies for youths ought to have excessive precision. The mannequin mustn’t classify unsafe movies (true negatives) as secure (false positives). On this case, the mannequin shall be acceptable even when it flags most secure movies as unsafe.
Nonetheless, precision just isn’t appropriate the place you need to reduce false negatives. So, within the instance highlighted earlier, a tumor detection mannequin wouldn’t be acceptable if it has decrease false positives (excessive precision) however misclassifies many precise tumor instances as regular (false negatives).
Recall
Recall, also called sensitivity or true optimistic price, is a metric that measures the proportion of true positives accurately recognized by a mannequin.
It measures the variety of right class predictions relative to the variety of samples within the corresponding class. For example, out of 95 cat pictures, what number of cats did the mannequin predict accurately?
The formulation under illustrates the idea.

Not like accuracy, which calculates the general price of right predictions, recall zooms in on avoiding false negatives.
The recall metric is significant in ML use instances the place lacking true optimistic cases can have important penalties. For instance, a suitable tumor detection mannequin could have excessive recall – it should predict most instances as tumorous (excessive false positives), however won’t label a cancerous tumor as regular (false damaging).
Precision vs. Recall Commerce-off
From the definition of each precision and recall, we will see an inherent trade-off between the 2 metrics. For example, a sturdy tumor detection mannequin can have excessive recall, however low precision, because the mannequin will predict virtually each case as tumorous (excessive false positives).
In distinction, the advice mannequin for flagging unsafe movies can have low recall however excessive precision, as it should predict virtually each video as unsafe (excessive false negatives).
As such, utilizing precision and recall in isolation doesn’t present the entire image. You should use them collectively and choose a mannequin that offers an optimum outcome for each.
F1 Rating, Precision-Recall Curve, and ROC-AUC
The F1 rating, precision-recall curve, and receiver working attribute (ROC) curve are useful measures that will let you choose a mannequin with appropriate precision and recall scores.
F1 Rating
The F1 rating is the harmonic imply of precision and recall scores. The formulation under illustrates the idea.
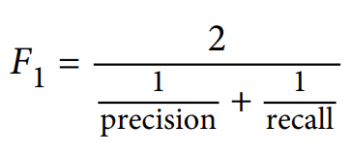
Because the formulation exhibits, the F1 rating offers equal weightage to precision and recall. So, a mannequin with 70% precision and 50% recall could have an total F1 rating of 58%. You’ll be able to evaluate the F1 scores of a number of fashions to evaluate which is probably the most optimum.
Precision-Recall Curve
Precision and recall scores can change with totally different thresholds. The edge is the minimal likelihood for categorizing a prediction as optimistic. For a cat classification mannequin, a threshold of 0.5 means the mannequin will label a picture as a cat (optimistic) if the prediction likelihood is bigger than or equal to 0.5.
Usually, setting a better threshold can lead the mannequin to have larger precision however low recall. For example, a threshold of 0.eight would imply the mannequin needs to be 80% assured that the picture is a cat to label it as a “cat.”
Elevating the brink to 0.7 means the mannequin will label a picture as a cat provided that the prediction likelihood is bigger than or equal to 0.7.
Nonetheless, most pictures could have decrease prediction possibilities, inflicting the mannequin to categorise a number of cat pictures as canine (excessive false negatives), resulting in a decrease recall. The diagram under exhibits how precision and recall could fluctuate with totally different threshold values.

Visualizing the precision and recall trade-off along with totally different threshold values is useful. The diagram under illustrates the precision-recall curve based mostly on the graph above.
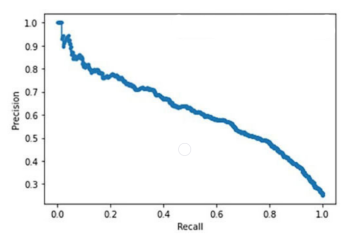
Right here, recall falls virtually linearly with precision. You need to use this to pick an acceptable precision-recall rating on your undertaking. For example, you’ll doubtless need excessive recall for the tumor recognition system (low false negatives).
Let’s say you need a recall rating of 90%. This implies your precision rating shall be roughly 40%.
Primarily based on this, you’ll be able to configure the brink worth as 0.2 by wanting on the graph above. On this case, the mannequin will classify a case as tumorous even when there’s a 20% likelihood {that a} tumor is current.
Nonetheless, you’ll be able to develop one other mannequin with a greater precision-recall trade-off. Such a mannequin’s precision-recall curve shall be additional to the top-right nook.
ROC Curve and AUC
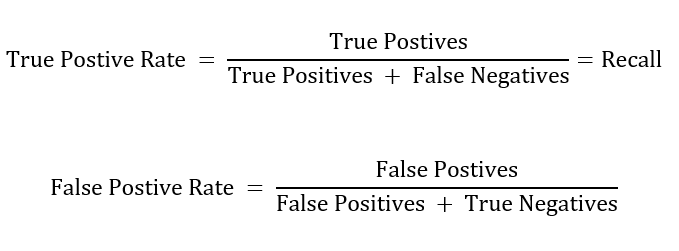
One other helpful visualization is the ROC curve. Much like the PR curve, it illustrates the trade-off between the true optimistic price (recall) and the false optimistic price at totally different classification thresholds. The next exhibits the calculation for true and false optimistic charges.
The diagram under exhibits the ROC for a specific mannequin towards a number of threshold values.
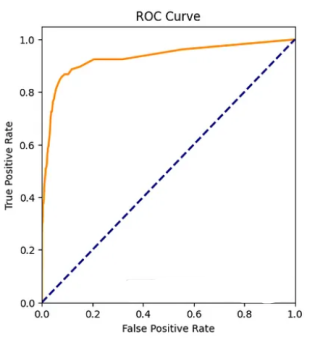
Once more, the diagram highlights the trade-off – excessive recall means a excessive false optimistic price, which suggests decrease precision.
Growing recall (excessive true optimistic price) for the tumor classification mannequin means capturing as many precise tumorous instances as attainable. Nonetheless, this may increasingly result in low precision (excessive false optimistic price) because the mannequin will classify many non-tumorous instances as tumorous.
Deciding on a mannequin based mostly on ROC requires you to compute the world underneath the curve (AUC). A totally random mannequin with no predictive energy could have an AUC rating of 0.5 – the world of the triangle shaped by the diagonal dotted line within the picture – and an ideal mannequin could have an AUC rating of 1 – the orange line shall be additional to the left.
Multi-Class Precision-Recall
Up to now, the definitions we seemed for Precision and Recall are for binary classifications – fashions that solely distinguish between two courses. Nonetheless, you should utilize the 2 metrics for multi-class classifications.
Since a number of courses exist in multi-class fashions, we will compute precision and recall scores for every class as follows.

Nonetheless, precision and recall scores for every class don’t assist assess a mannequin’s total efficiency. A mannequin having fifty courses could have fifty precision and recall scores. Judging the mannequin’s predictive energy from these shall be difficult.
The answer is to make use of two strategies, known as micro and macro averaging, that mix the precision and recall scores for every class to offer an mixture metric for analysis.
Micro Averaging
Micro averaging aggregates the true positives, false positives, and false negatives throughout all courses after which calculates precision and recall based mostly on the combination worth. The micro common offers equal weight to every occasion from every class. The next illustrates the formulation.

Whereas microaveraging addresses classification for every occasion, it may be deceptive for skewed datasets.
For example, think about two courses – Class 1 and Class 2, the place Class 1 has 95 samples, and Class 2 has 5 samples.
A mannequin that classifies all samples for Class 1 accurately however misclassifies all for Class 2 could have excessive precision and recall scores based mostly on micro averages. In such situations, it’s extra acceptable to make use of macro-average.
Macro Averaging
Macro averaging calculates precision and recall for every class individually after which takes the common throughout all courses. Macro-averaging offers equal weight to every class, because the formulation under illustrates,
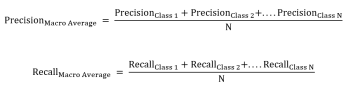
Contemplating the identical instance as above, Class 2’s precision and recall scores shall be low, inflicting macro averages to be low.
Precision vs Recall: Use Circumstances
As highlighted earlier, selecting between recall and precision requires prioritization as favoring one metric causes the opposite to fall. Let’s see just a few CV use instances that can assist you resolve between the 2.
Medical Analysis
In medical prognosis, lacking even one case can have devastating penalties. CV fashions for analyzing medical pictures ought to typically have excessive recall for accurately classifying as many true positives as attainable, even when it results in some false positives or excessive precision.
Safety Techniques
Safety methods contain flagging anomalous conduct to alert authorities relating to potential threats. Once more, excessive recall is fascinating as capturing as many suspects as attainable (excessive false positives) is best than lacking precise culprits.

High quality Assurance
In manufacturing, CV fashions assist detect faulty merchandise on the meeting to make sure they don’t attain the client. These fashions ought to have excessive recall since classifying a defective product as regular (excessive false optimistic) can price an organization its prospects in the event that they get faulty gadgets.

Picture Retrieval Techniques
CV fashions for picture retrieval analyze a consumer’s search question to fetch pictures that match the question’s description. Having a mannequin with excessive precision (low false positives) is essential for producing related outcomes and making certain customers simply discover what they’re looking for.
Facial Recognition
Units utilizing facial recognition fashions to authenticate customers ought to have excessive precision (low false positives) to attenuate unauthorized entry.

Total, the selection between recall and precision is context-specific and based mostly on the implications that false positives or false negatives could cause.
Precision vs. Recall: Key Takeaways
Precision vs. recall machine studying metrics are very important for assessing a mannequin’s predictive efficiency. Under are just a few essential factors to recollect relating to these two measures.
- Precision and recall are fascinating for skewed datasets: Whereas accuracy is acceptable for balanced datasets, precision, and recall provide a greater analysis for fashions educated on imbalanced information.
- Precision and recall trade-off: Growing precision results in low recall and vice versa. You must select a mannequin with optimum precision and recall based mostly on the F1 rating, PR curve, and ROC-AUC.
- Multi-class precision and recall: Macro and micro-averaging are two strategies for computing precision and recall for multi-class classification fashions.
You’ll be able to learn extra about associated subjects within the following blogs:
Utilizing Viso.ai for Mannequin Analysis
Evaluating CV fashions will be difficult as a consequence of their rising prevalence in a number of industrial domains comparable to healthcare, manufacturing, retail, and safety.
Additionally, constructing efficient analysis pipelines from scratch is tedious and vulnerable to errors. Moreover, you require domain-level experience to decide on the correct analysis methodology for assessing mannequin efficiency for a particular activity.
A extra environment friendly methodology is to make use of instruments that assist you construct and consider CV fashions by means of automated options and with minimal guide effort.
And that’s the place the Viso Suite platform is available in. The platform is an end-to-end no-code answer that allows you to construct, consider, and monitor CV fashions by means of strong pipelines and intuitive dashboards.
So, request a demo now to spice up your mannequin efficiency.



