Optical character recognition (OCR) permits textual content in photographs to be comprehensible by machines, permitting applications and scripts to course of the textual content. OCR is often seen throughout a variety of purposes, however primarily in document-related eventualities, together with doc digitization and receipt processing.
Whereas options for doc OCR have been closely investigated, the present state-of-the-art for OCR options on non-document OCR purposes, often known as “scene OCR”, like studying license plates or logos, is much less clear.
On this weblog put up, we evaluate seven completely different OCR options and evaluate their efficacy in ten completely different areas of commercial OCR purposes.
OCR Options
We are going to take a look at seven completely different OCR fashions::
- Tesseract (domestically through PyTesseract)
- EasyOCR (native)
- Surya (native)
- DocTR (through Roboflow Hosted API)
- OpenAI GPT-Four with Imaginative and prescient
- Google Gemini Professional 1.0
- Anthropic Claude three Opus
Along with 4 open-source OCR-specific packages, we additionally take a look at three Massive Multimodal Fashions (LMMs), GPT-Four with Imaginative and prescient, Gemini Professional 1.0, and Claude three Opus, which have all beforehand proven effectiveness in OCR duties.
OCR Testing Methodology
Most OCR options, in addition to benchmarks, are primarily designed for studying whole pages of textual content. Knowledgeable by our experiences deploying laptop imaginative and prescient fashions in bodily world environments, we’ve got seen the advantage of omitting a “textual content detection” or localization step throughout the OCR mannequin in favor of a custom-trained object detection mannequin, cropping the results of the detection mannequin to be handed onto an OCR mannequin.
Our objective, and the scope of this experiment, is to check as many non-document use case domains as doable with localized textual content examples. With the affect of what we’ve got seen from our personal experiences and our buyer’s use circumstances, we outlined ten completely different domains to check.

For every area, we chosen an open-source dataset from Roboflow Universe and imported ten photographs from every area dataset at random. If the picture could possibly be fairly learn by a human, it was included.
💡
Usually, the area photographs had been cropped akin to object detection annotations made throughout the unique Universe dataset. In circumstances the place there have been both no detections to crop from or the detections contained additional textual content that might introduce variability in our testing, we manually cropped photographs.
For instance, with license plates, the dataset we used contained your entire license plate, which within the circumstances of U.S. license plates included the state, taglines, and registration stickers. On this case, we cropped the picture solely to incorporate the first figuring out numbers and letters.
To create a floor reality to match OCR predictions in opposition to, every picture was manually learn and annotated with the textual content within the picture because it appeared.
As soon as we ready the dataset, we evaluated every OCR resolution. A Levenshtein distance ratio, a metric used for measuring the distinction between two strings, was calculated and used for scoring.
Outcomes
Our testing gave us a number of insights into the varied OCR options and when to make use of them. We look at the accuracy, velocity, and value facets of the outcomes.
Accuracy
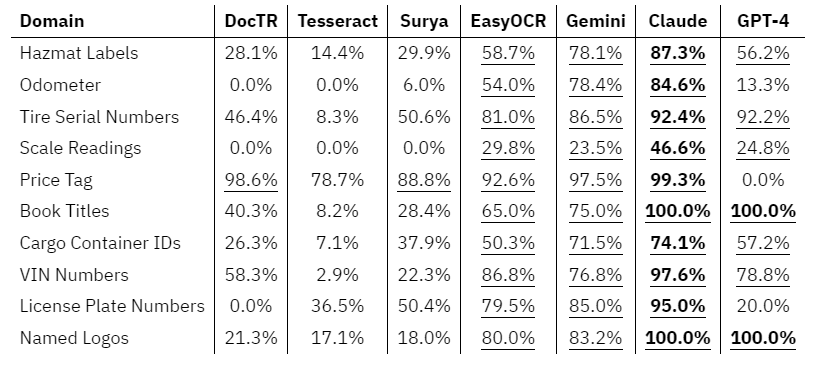
Throughout the board, contemplating all domains, two multimodal LLMs, Gemini and Claude carried out one of the best, adopted by EasyOCR and GPT-4.
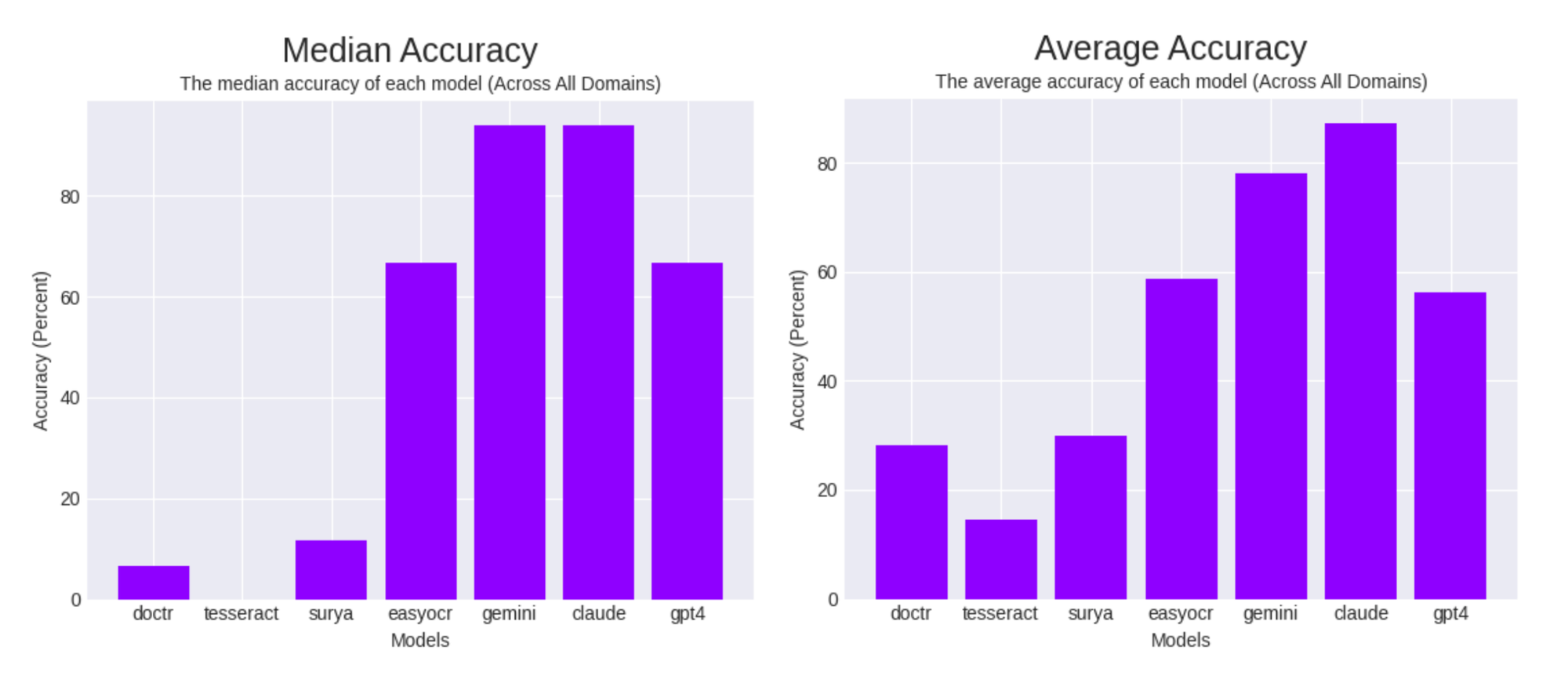
The overall development of the median and imply accuracy continued throughout most domains.
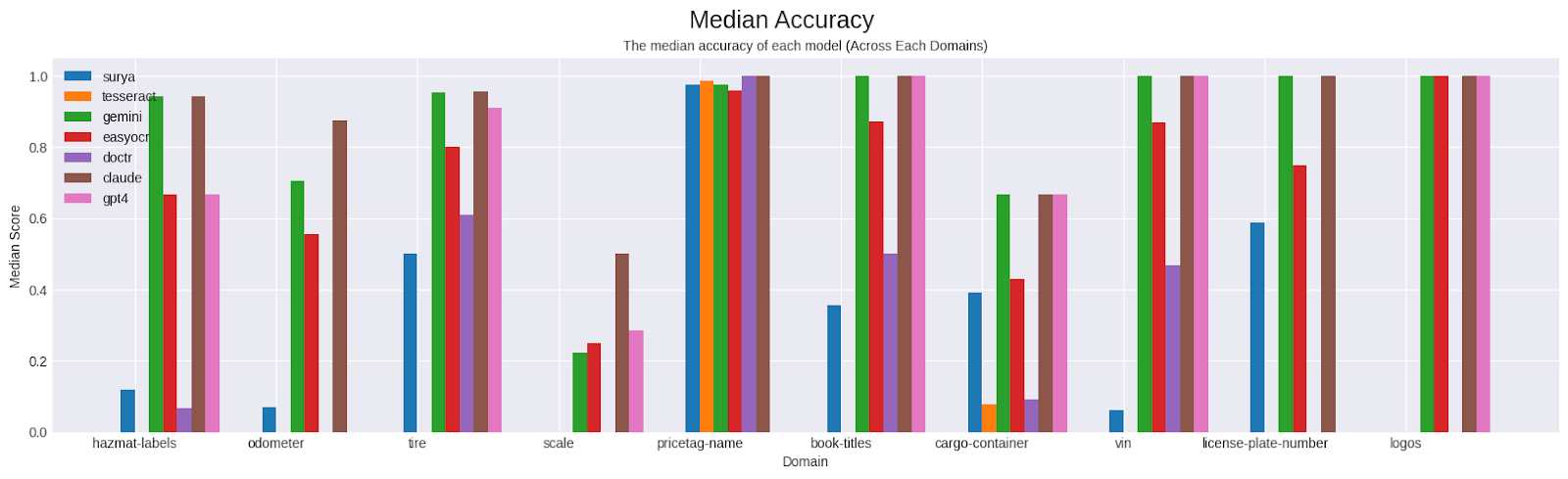
Throughout all domains, Claude achieved the very best accuracy rating probably the most occasions, adopted by GPT-Four and Gemini. EasyOCR carried out usually properly throughout most domains and much surpassed its specialized-package counterparts, however underperformed in comparison with LLMs.
A surprisingly notable facet was GPT-4’s refusal charge which produced outcomes that had been unusable and repeated makes an attempt didn’t resolve this concern. We handled this as a zero rating and it considerably lowered or brought about a complete zero rating for some domains, whereas different LMMs didn’t expertise refusals in any respect.
Velocity
Whereas correct OCR is necessary, velocity can also be a consideration when utilizing OCR.
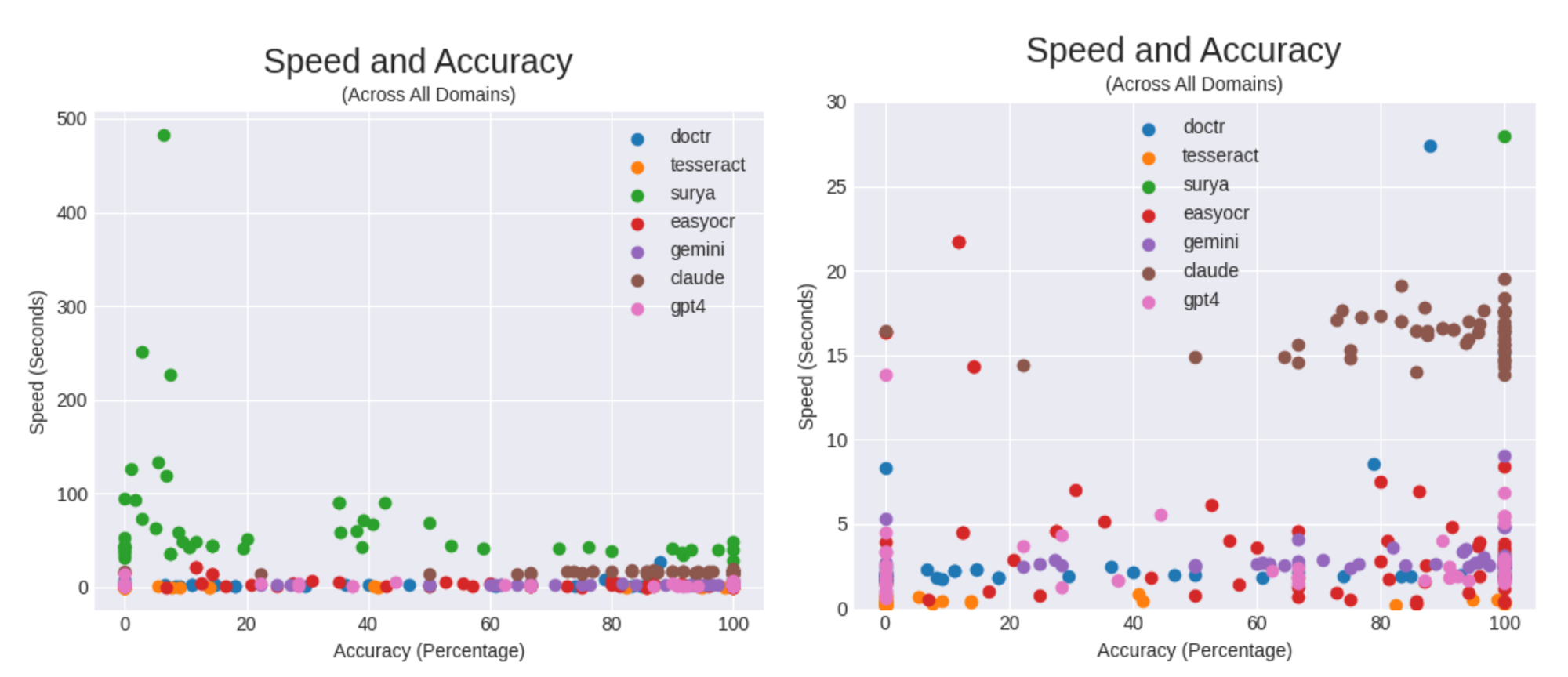
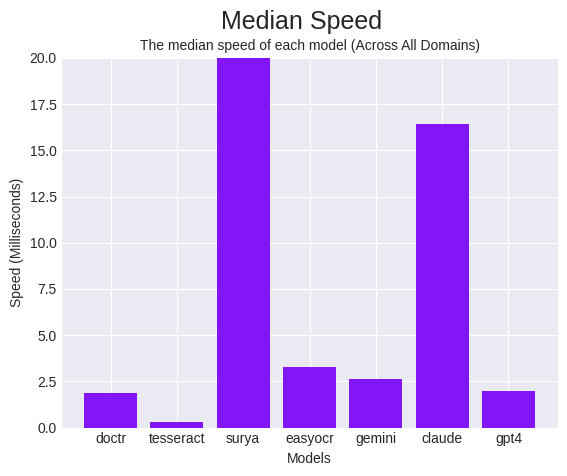
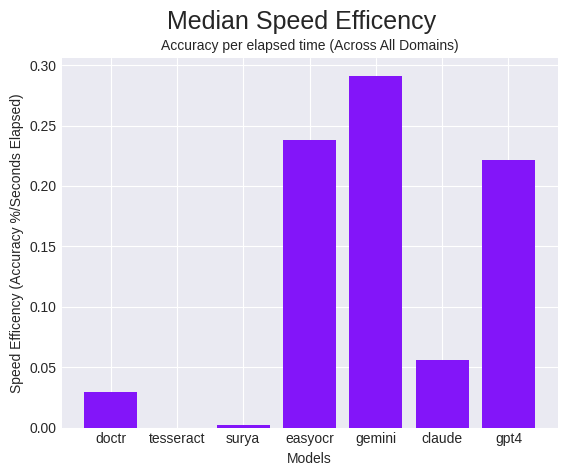
Velocity, nevertheless, doesn’t present your entire image since a quick mannequin with horrible accuracy just isn’t helpful. So, we calculate a metric, “velocity effectivity”, which we outline as accuracy over the elapsed time.
Our objective with this metric is to point out how correct the mannequin is, contemplating the time it took. On this class, Gemini wins by a notable margin, with EasyOCR, and GPT-Four as runner-ups. Regardless of Calude’s excessive efficiency, its gradual response time, negatively impacted its scores on this class.
Price
A 3rd issue to contemplate is the precise worth it takes to carry out every request. In excessive quantity use circumstances, prices can add up rapidly and having a way of the monetary impression it’ll have is necessary.
The calculations for these prices had been completed in one in all two separate strategies relying on the mannequin. For LMMs, which don’t supply a neighborhood inference possibility, we calculated the prices instantly from the variety of tokens (or characters within the case of Gemini) that had been used and the respective mannequin’s pricing.
For domestically run OCR fashions, we calculated the price of the OCR request because the time it took to foretell multiplied by the price of the digital machine on Google Cloud. (The assessments had been run on a Google Colab CPU setting which we equated to a Laptop Engine E2 occasion with 2 vCPUs and 13 GB of reminiscence).
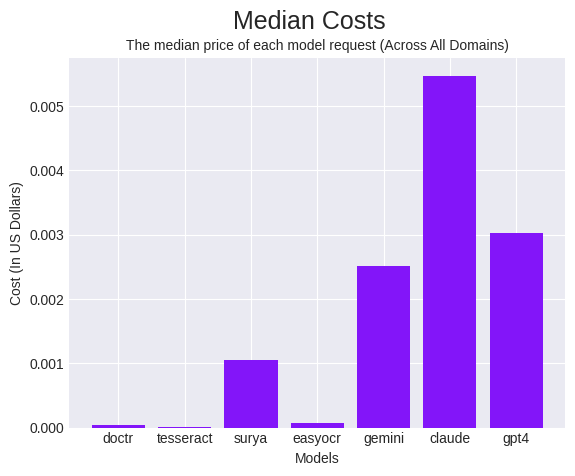
DocTR, Tesseract, Surya, and EasyOCR had been considerably cheaper to run in comparison with LMMs. As with the velocity, worth in isolation just isn’t a helpful indicator of the way it will carry out within the discipline.
Much like how we calculated velocity effectivity, we calculated a price effectivity metric, outlined as proportion accuracy over the value value. This relates how performant a mannequin is to the value of operating the mannequin. It’s calculated by dividing the rating achieved by the price of the request.
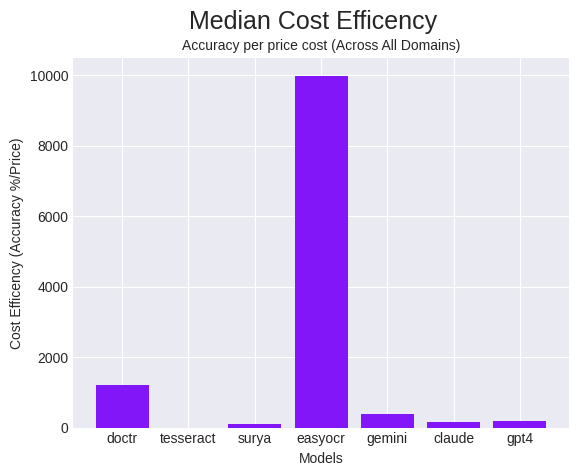
EasyOCR had one of the best value effectivity, with DocTR and Gemini being considerably decrease runner-ups. The explanation for this drastic distinction originates from EasyOCR’s comparatively spectacular efficiency by way of accuracy, whereas being a considerably cheaper various to its important competitors, LMMs.
Conclusion
On this weblog put up, we explored how completely different OCR options carry out throughout domains which are generally present in industrial imaginative and prescient use circumstances, evaluating LMMs and open-source options on velocity, accuracy, and value.
All through testing, we discover that operating EasyOCR domestically produces probably the most cost-efficient OCR outcomes whereas sustaining aggressive accuracy, whereas Anthropic’s Claude three Opus carried out one of the best throughout the widest array of domains, and Google’s Gemini Professional 1.Zero performs one of the best by way of velocity effectivity.
When evaluating in opposition to native, open-source OCR options, EasyOCR far outperformed its counterparts in all metrics, acting at ranges close to or above different LMMs.


