The article beneath was contributed by Timothy Malche, an assistant professor within the Division of Laptop Functions at Manipal College Jaipur.
Picture matching in pc imaginative and prescient refers back to the means of discovering correspondences between completely different pictures or components of pictures. This could contain figuring out objects, options, or patterns in a single picture which can be much like these in one other picture.
The purpose is to determine relationships between completely different pictures or components of pictures, which can be utilized for duties equivalent to object recognition, picture registration, and augmented actuality.
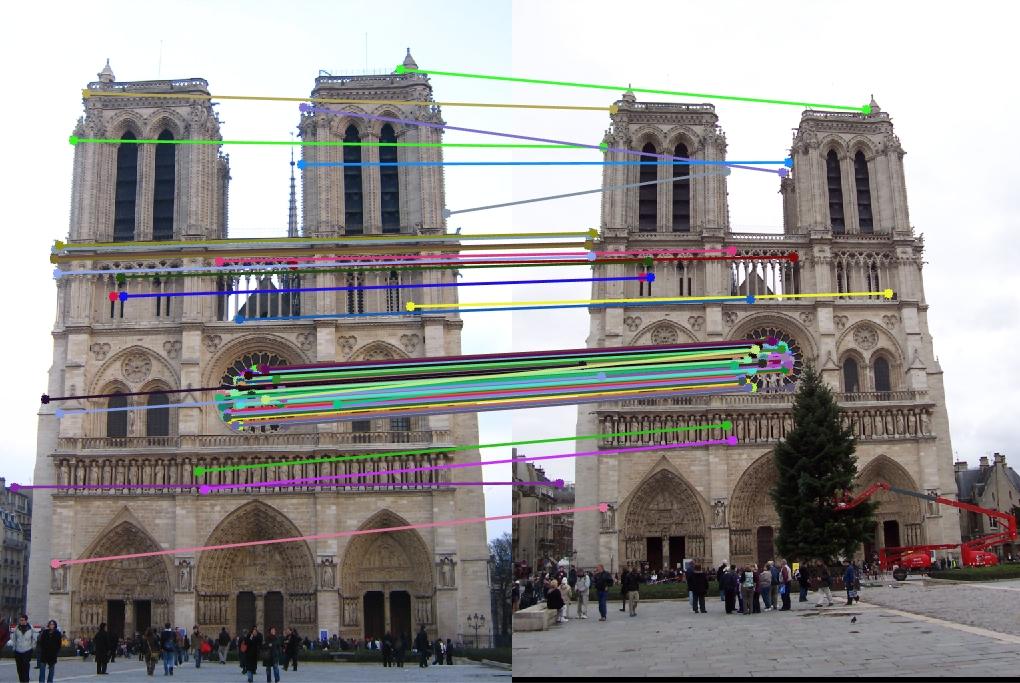
The next picture reveals an instance of picture matching through which identical object in two completely different pictures, taken from completely different perspective, is matched based mostly on keypoints.
Functions of Picture Matching
Picture matching has varied real-world functions throughout completely different domains. On this part we focus on among the key functions.
Picture Stitching
Picture stitching is the method of mixing a number of pictures right into a single panoramic picture by aligning overlapping areas and mixing them collectively seamlessly. Picture stitching is often utilized in varied functions equivalent to:
- Creating panoramic images
- Creating wide-angle or 360-degree pictures for digital excursions
- Merging satellite tv for pc pictures or aerial images
- Stitching collectively medical pictures for evaluation or prognosis
- Creating high-resolution pictures from a number of lower-resolution pictures

Object Recognition and Monitoring
Object recognition and monitoring confer with the processes of detecting and figuring out objects in pictures or video streams, after which monitoring their motion over time.

Object recognition and monitoring are important parts of many pc imaginative and prescient functions, together with:
- Surveillance: Monitoring folks or automobiles in video feeds for safety functions.
- Augmented Actuality: Overlaying digital info or objects onto real-world scenes.
- Autonomous Automobiles: Monitoring different automobiles, pedestrians, and obstacles for navigation and collision avoidance.
- Robotics: Figuring out and monitoring objects for robotic manipulation duties.
- Human-Laptop Interplay: Monitoring hand gestures or facial expressions for person interplay.
- Medical Imaging: Monitoring the motion of organs or tumors in medical pictures for prognosis and therapy planning.
Picture Registration
Picture registration refers back to the means of aligning two or extra pictures in order that corresponding options or factors within the pictures are spatially aligned. The purpose is to discover a transformation that maps factors from one picture to corresponding factors in one other picture.
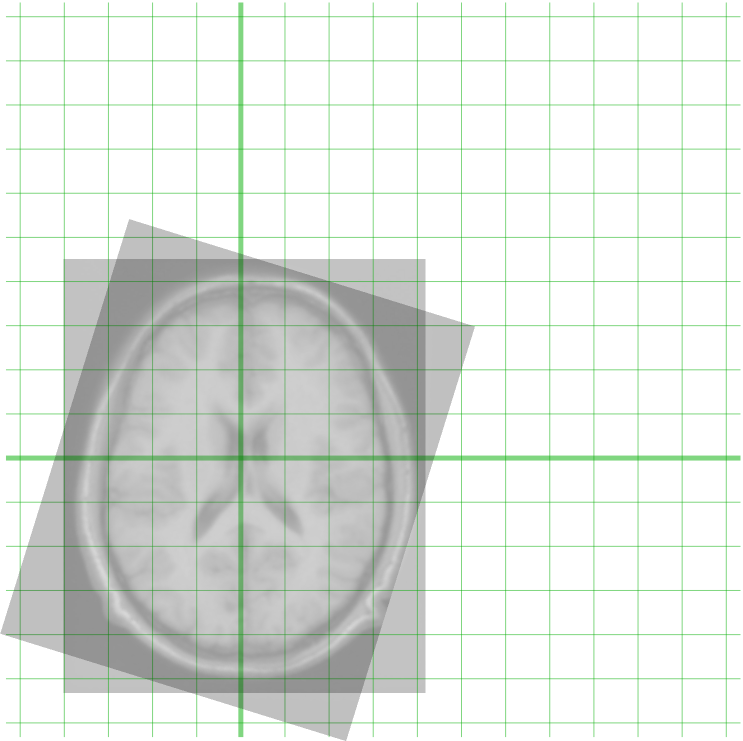
Picture Registration of two MRI pictures of mind (Supply)
Picture Matching Strategies
There are a number of approaches to picture matching. We’ll focus on two of the commonest approaches right here.
- Function-based matching
- Template Matching
Function-based matching
This technique entails figuring out distinctive options (equivalent to corners, edges, or blobs) within the pictures and matching them based mostly on their descriptors. Some frequent and in style algorithms used for feature-based matching embrace SIFT (Scale-Invariant Function Remodel), SURF (Speeded-Up Sturdy Options), ORB (Oriented FAST and Rotated BRIEF), AKAZE (Accelerated-KAZE), BRISK (Binary Sturdy Invariant Scalable Keypoints), and FREAK (Quick Retina Keypoint).
Function based mostly matching entails following two necessary steps.
- Detect keypoints and descriptors: Detect distinctive factors or areas in each pictures which can be more likely to be matched and extract numerical descriptors or function vectors round every keypoint to explain its native neighborhood. These descriptors must be distinctive and invariant to modifications in scale, rotation, and illumination. Algorithms equivalent to SIFT used for this course of.
- Match keypoints: Evaluate the descriptors of keypoints between the 2 pictures to search out correspondences. We could apply filtering strategies to take away incorrect matches and retain solely dependable correspondences. Completely different function matcher equivalent to Brute-Power matcher, FLANN matcher are used for this course of.
We’ll now see some examples of function based mostly matching.
Instance #1: Picture Stitching
On this instance we’ll mix the next two pictures to make it one wider picture containing scene from each pictures.

After stitching each the photographs, the ultimate output picture will appear like following.

The next is the code for picture stitching.
import cv2
import numpy as np # Load pictures
image1 = cv2.imread('image1.jpg')
image2 = cv2.imread('image2.jpg') # Convert pictures to grayscale
gray1 = cv2.cvtColor(image1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(image2, cv2.COLOR_BGR2GRAY) # Initialize SIFT detector
sift = cv2.SIFT_create() # Detect keypoints and descriptors
keypoints1, descriptors1 = sift.detectAndCompute(gray1, None)
keypoints2, descriptors2 = sift.detectAndCompute(gray2, None) # Initialize Brute Power matcher
bf = cv2.BFMatcher() # Match descriptors
matches = bf.knnMatch(descriptors1, descriptors2, okay=2) # Ratio take a look at to search out good matches
good_matches = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good_matches.append(m) # Extract keypoints of fine matches
src_pts = np.float32([keypoints1[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2)
dst_pts = np.float32([keypoints2[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2) # Discover homography
H, _ = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0) # Warp image1 to image2
stitched_image = cv2.warpPerspective(image1, H, (image2.form[1] + image1.form[1], image2.form[0]))
stitched_image[:, :image2.form[1]] = image2 # Show the stitched picture
cv2.imshow('Stitched Picture', stitched_image)
cv2.waitKey(0)
cv2.destroyAllWindows()Instance #2: Object Monitoring
On this instance, we detected keypoints and their descriptors of an object of our alternative to trace the thing in subsequent video frames and calculate the transformation (translation, rotation, scale) between the keypoints within the reference picture and the keypoints within the present video body. Then, apply the transformation to the reference picture to align it with the present body and at last draw the tracked object on the body. Following is the code. The code will first load the reference picture and permit person to pick out the area of curiosity (ROI) within the reference picture utilizing mouse, it’s going to then observe the chosen area of curiosity within the video body.

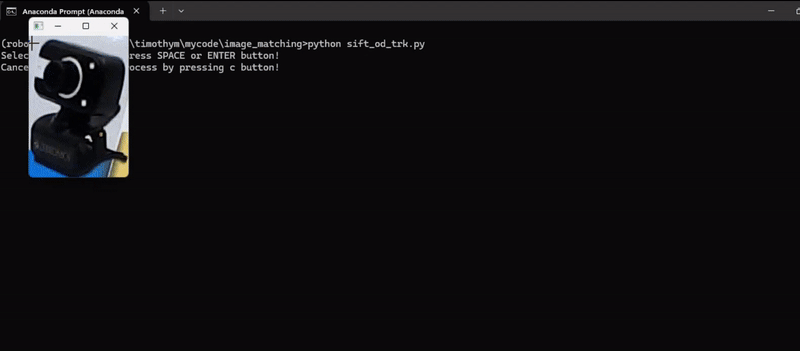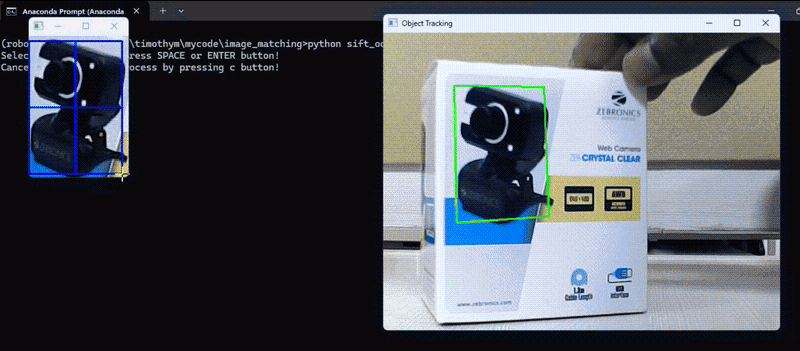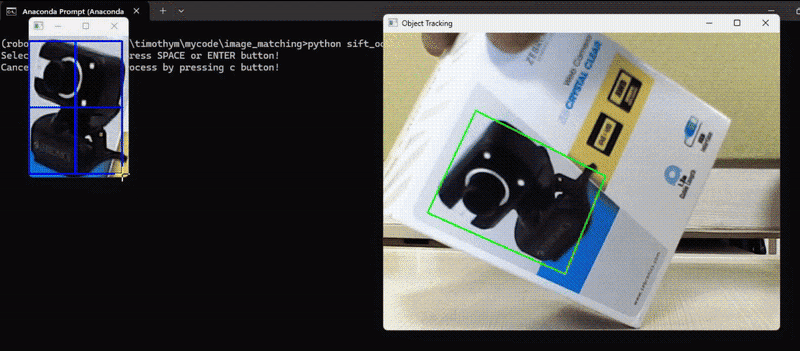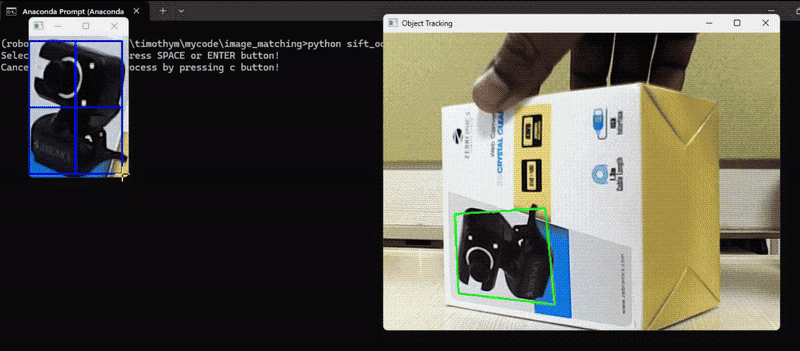
Right here’s the code to realize above output.
import cv2
import numpy as np # Load the reference picture
reference_image = cv2.imread('reference_image.jpg') # Convert reference picture to grayscale
gray_reference = cv2.cvtColor(reference_image, cv2.COLOR_BGR2GRAY) # Initialize SIFT detector
sift = cv2.SIFT_create() # Detect keypoints and compute descriptors for the reference picture
keypoints_reference, descriptors_reference = sift.detectAndCompute(gray_reference, None) # Convert descriptors to CV_32F sort
descriptors_reference = descriptors_reference.astype(np.float32) # Initialize the digicam or video stream
cap = cv2.VideoCapture(1) # Choose ROI on the reference picture
bbox = cv2.selectROI('Choose ROI', reference_image, fromCenter=False, showCrosshair=True)
x, y, w, h = bbox # Extract keypoints and descriptors from the chosen area
roi = gray_reference[y:y+h, x:x+w]
keypoints_roi, descriptors_roi = sift.detectAndCompute(roi, None) # Convert descriptors to CV_32F sort
descriptors_roi = descriptors_roi.astype(np.float32) # Initialize the BFMatcher
bf = cv2.BFMatcher() whereas True:
# Seize frame-by-frame
ret, body = cap.learn()
gray_frame = cv2.cvtColor(body, cv2.COLOR_BGR2GRAY) # Detect keypoints and compute descriptors for the body
keypoints_frame, descriptors_frame = sift.detectAndCompute(gray_frame, None) # Convert descriptors to CV_32F sort
descriptors_frame = descriptors_frame.astype(np.float32) # Match descriptors between the body and the reference area
matches = bf.knnMatch(descriptors_roi, descriptors_frame, okay=2) # Apply ratio take a look at to search out good matches
good_matches = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good_matches.append(m) # Calculate homography
if len(good_matches) > 10:
src_pts = np.float32([keypoints_roi[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2)
dst_pts = np.float32([keypoints_frame[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2)
M, _ = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
if M isn't None:
# Calculate bounding field for the tracked object
pts = np.float32([[0, 0], [0, h - 1], [w - 1, h - 1], [w - 1, 0]]).reshape(-1, 1, 2)
dst = cv2.perspectiveTransform(pts, M)
body = cv2.polylines(body, [np.int32(dst)], True, (0, 255, 0), 2) # Show the body with the tracked object
cv2.imshow('Object Monitoring', body) # Exit if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord('q'):
break # Launch the seize
cap.launch()
cv2.destroyAllWindows()Instance #2: Augmented Actuality Instance
On this instance we detect keypoints and match them between the reference picture and the frames from the digicam. Then, calculate the homography matrix utilizing the matched keypoints and warp the digital object (one other picture) or info utilizing the homography matrix to align it with the reference picture within the digicam body. Lastly, overlay the digital object or info onto the digicam body.
Within the code we overlay the next reference picture with the PNG picture of digicam beneath.


import cv2
import numpy as np # Load the reference picture
reference_image = cv2.imread('reference_image.jpg') # Load the picture to wrap onto the reference picture
image_to_wrap = cv2.imread('cam.png') # Resize the picture to match the scale of the reference picture
image_to_wrap_resized = cv2.resize(image_to_wrap, (reference_image.form[1], reference_image.form[0])) # Convert reference picture to grayscale
gray_reference = cv2.cvtColor(reference_image, cv2.COLOR_BGR2GRAY) # Initialize SIFT detector
sift = cv2.SIFT_create() # Detect keypoints and compute descriptors for the reference picture
keypoints_reference, descriptors_reference = sift.detectAndCompute(gray_reference, None) # Initialize the digicam or video stream
cap = cv2.VideoCapture(1) whereas True:
# Seize frame-by-frame
ret, body = cap.learn() # Convert body to grayscale
gray_frame = cv2.cvtColor(body, cv2.COLOR_BGR2GRAY) # Detect keypoints and compute descriptors for the body
keypoints_frame, descriptors_frame = sift.detectAndCompute(gray_frame, None) if descriptors_frame isn't None:
# Match descriptors between the body and the reference picture
bf = cv2.BFMatcher()
matches = bf.knnMatch(descriptors_reference, descriptors_frame, okay=2) # Apply ratio take a look at to search out good matches
good_matches = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good_matches.append(m) if len(good_matches) > 10:
# Get the matched keypoints
src_pts = np.float32([keypoints_reference[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2)
dst_pts = np.float32([keypoints_frame[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2) # Calculate homography
M, _ = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
if M isn't None:
# Warp the picture to suit the attitude of the reference picture
warped_image = cv2.warpPerspective(image_to_wrap_resized, M, (body.form[1], body.form[0])) # Overlay the warped picture onto the body
frame_with_overlay = body.copy()
frame_with_overlay[np.where(warped_image[:, :, 0] != 0)] = warped_image[np.where(warped_image[:, :, 0] != 0)] # Show the body with overlay
cv2.imshow('Augmented Actuality', frame_with_overlay)
else:
cv2.imshow('Augmented Actuality', body) else:
cv2.imshow('Augmented Actuality', body) else:
cv2.imshow('Augmented Actuality', body) # Exit if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord('q'):
break # Launch the seize
cap.launch()
cv2.destroyAllWindows()Template matching
Template matching is a way utilized in picture processing and pc imaginative and prescient to discover a template picture inside a bigger picture. It entails sliding the template picture over the bigger picture and evaluating their pixel values or options to search out the most effective match. Here is the way it works intimately:
- Enter Pictures: You might have a template picture and a bigger picture inside which you wish to discover occurrences of the template.
- Sliding Window: The template picture is moved (or “slid”) over the bigger picture in a scientific manner, often pixel by pixel or in bigger strides.
- Comparability: At every place of the template, a similarity measure is computed between the template and the corresponding area within the bigger picture. This measure might be based mostly on pixel-wise variations, correlation coefficients, or different metrics relying on the applying.
- Greatest Match: The place with the best similarity measure signifies the most effective match of the template inside the bigger picture.
OpenCV gives matchTemplate() operate for template matching. There are the completely different comparability strategies utilized in template matching. Every technique has its personal manner of computing the similarity between the template and the goal picture. These are following:
- TM_CCOEFF: This technique computes the correlation coefficient between the template and the goal pictures.
- TM_CCOEFF_NORMED: This technique computes the normalized correlation coefficient.
- TM_CCORR: It calculates the cross-correlation between the template and the picture.
- TM_CCORR_NORMED: Much like TM_CCORR however normalized.
- TM_SQDIFF: This technique computes the sum of squared variations between the template and the goal pictures.
- TM_SQDIFF_NORMED: This technique computes the normalized sum of squared variations between the template and the goal pictures.
One sensible instance of utilizing template matching in picture processing is in automated high quality management in manufacturing. Let’s think about a situation the place you could have a manufacturing line manufacturing circuit boards. Every board ought to have a selected configuration of parts positioned precisely on it. Nevertheless, as a result of varied causes equivalent to machine error or element defects, generally these parts could be misplaced or lacking. Template matching can be utilized to detect these defects. Here is the way it works:
- Template Creation: First, you create a template picture that represents the right configuration of parts on the circuit board. This template could possibly be a high-resolution picture of a great circuit board.
- Picture Acquisition: As every circuit board strikes alongside the manufacturing line, a digicam takes a picture of it.
- Template Matching: The acquired picture is then in contrast with the template utilizing template matching algorithms.
- Defect Detection: If the similarity rating falls beneath a sure threshold, it signifies that the parts on the circuit board aren’t within the appropriate place or are lacking. This alerts the system to a possible defect, and acceptable motion might be taken, equivalent to marking the faulty board for guide inspection or rejection.
We’ll now see this by means of an instance. I’m utilizing following pictures as a template to be examined in the primary circuit board picture.
|
|
|
|
|
Led |
Wifi Module |
Microcontroller |


Template Pictures
And following is my essential circuit picture to be examined for whether or not it has all of those parts.

Following is the output of this system.
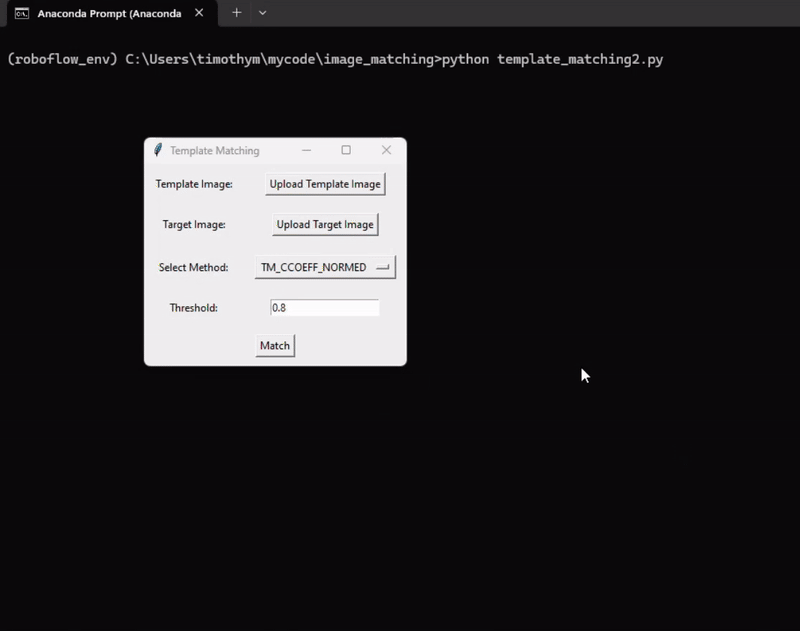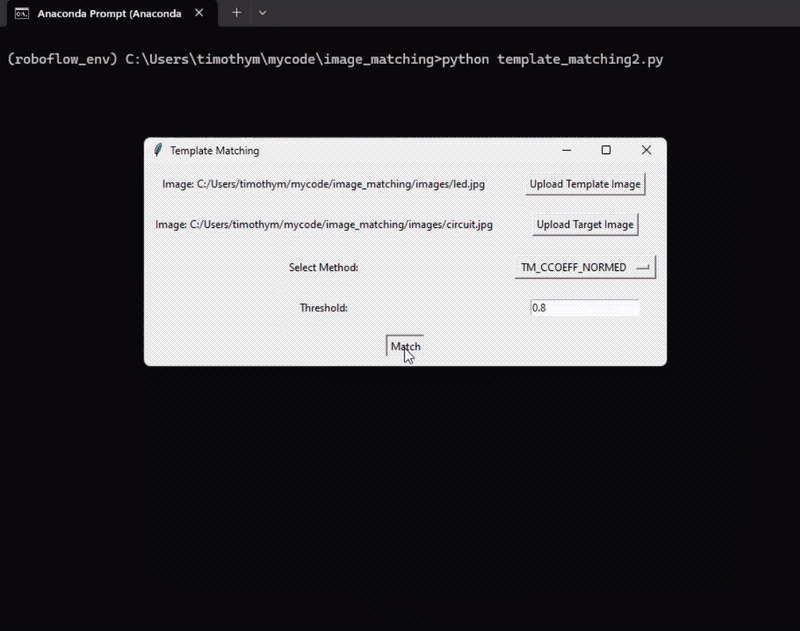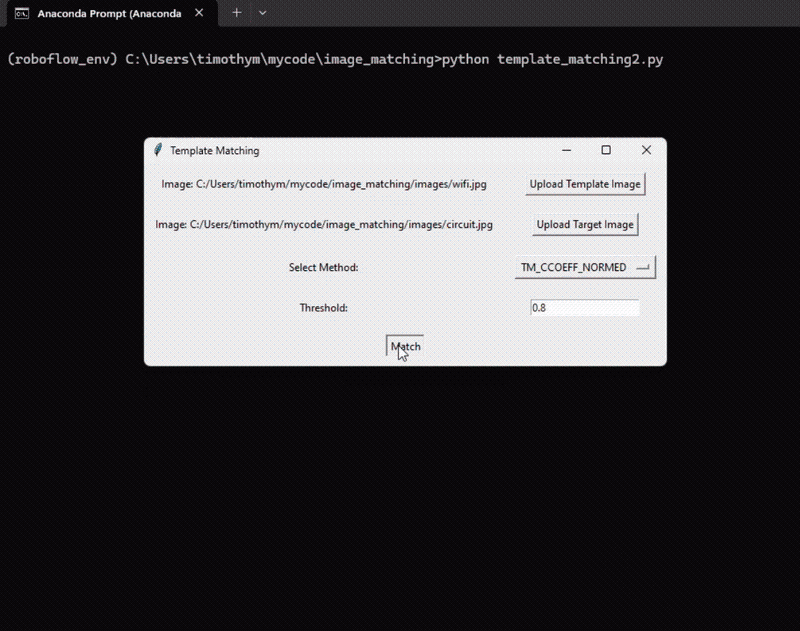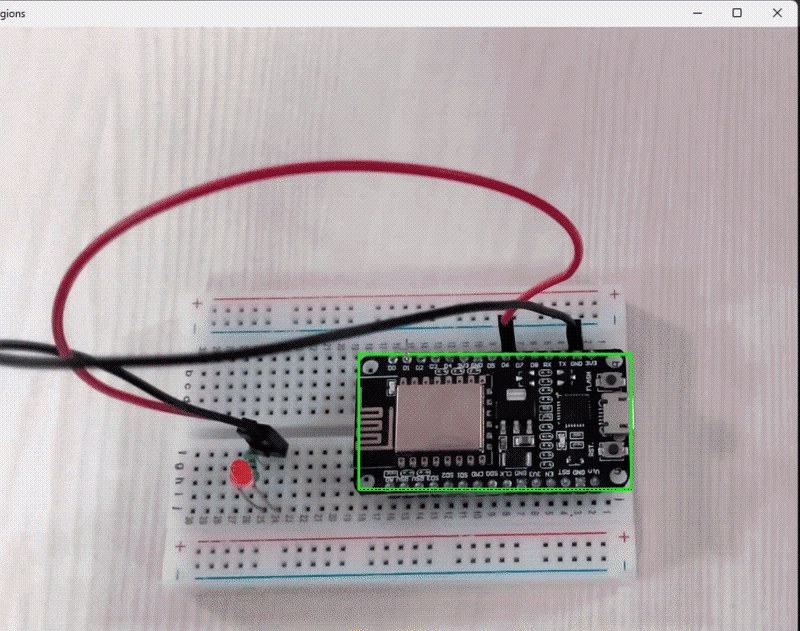
Right here’s the code for the template matching instance:
import cv2
import numpy as np
import tkinter as tk
from tkinter import filedialog def template_match(template, goal, technique=cv2.TM_CCOEFF_NORMED, threshold=0.8):
"""
Carry out template matching
"""
template_gray = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY)
target_gray = cv2.cvtColor(goal, cv2.COLOR_BGR2GRAY) consequence = cv2.matchTemplate(target_gray, template_gray, technique)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(consequence) if max_val >= threshold:
template_height, template_width = template_gray.form[:2]
if technique in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc bottom_right = (top_left[0] + template_width, top_left[1] + template_height)
return [(top_left, bottom_right, 0)]
else:
return [] def upload_image(label):
filename = filedialog.askopenfilename()
if filename:
img = cv2.imread(filename)
label.config(textual content=f"Picture: {filename}")
return img def display_matched_result():
template_img = template_image_label.cget("textual content").break up(": ")[1]
target_img = target_image_label.cget("textual content").break up(": ")[1]
technique = method_var.get()
threshold = float(threshold_entry.get()) if template_img and target_img:
template = cv2.imread(template_img)
goal = cv2.imread(target_img) method_dict = {
"TM_CCOEFF": cv2.TM_CCOEFF,
"TM_CCOEFF_NORMED": cv2.TM_CCOEFF_NORMED,
"TM_CCORR": cv2.TM_CCORR,
"TM_CCORR_NORMED": cv2.TM_CCORR_NORMED,
"TM_SQDIFF": cv2.TM_SQDIFF,
"TM_SQDIFF_NORMED": cv2.TM_SQDIFF_NORMED
}
selected_method = method_dict[method] matches = template_match(template, goal, selected_method, threshold) for match in matches:
top_left, bottom_right, _ = match
cv2.rectangle(goal, top_left, bottom_right, (0, 255, 0), 2) cv2.imshow('Matched Areas', goal)
cv2.waitKey(0)
cv2.destroyAllWindows() # GUI
root = tk.Tk()
root.title("Template Matching") # Template Picture
template_image_label = tk.Label(root, textual content="Template Picture:")
template_image_label.grid(row=0, column=0, padx=10, pady=10)
template_image_button = tk.Button(root, textual content="Add Template Picture", command=lambda: upload_image(template_image_label))
template_image_button.grid(row=0, column=1, padx=10, pady=10) # Goal Picture
target_image_label = tk.Label(root, textual content="Goal Picture:")
target_image_label.grid(row=1, column=0, padx=10, pady=10)
target_image_button = tk.Button(root, textual content="Add Goal Picture", command=lambda: upload_image(target_image_label))
target_image_button.grid(row=1, column=1, padx=10, pady=10) # Technique Choice
method_label = tk.Label(root, textual content="Choose Technique:")
method_label.grid(row=2, column=0, padx=10, pady=10)
method_options = ["TM_CCOEFF", "TM_CCOEFF_NORMED", "TM_CCORR", "TM_CCORR_NORMED", "TM_SQDIFF", "TM_SQDIFF_NORMED"]
method_var = tk.StringVar(root)
method_var.set(method_options[1]) # Default technique
method_dropdown = tk.OptionMenu(root, method_var, *method_options)
method_dropdown.grid(row=2, column=1, padx=10, pady=10) # Threshold
threshold_label = tk.Label(root, textual content="Threshold:")
threshold_label.grid(row=3, column=0, padx=10, pady=10)
threshold_entry = tk.Entry(root)
threshold_entry.insert(tk.END, "0.8") # Default threshold
threshold_entry.grid(row=3, column=1, padx=10, pady=10) # Match Button
match_button = tk.Button(root, textual content="Match", command=display_matched_result)
match_button.grid(row=4, column=0, columnspan=2, padx=10, pady=10) root.mainloop()Conclusion
Picture matching is a strong approach in pc imaginative and prescient that allows varied functions equivalent to object recognition, picture registration, and picture reconstruction.
On this weblog submit, we realized about feature-based matching and template matching by means of examples.
Function-based matching entails figuring out and matching key options or keypoints between two pictures. These keypoints are distinctive factors within the picture, equivalent to corners, edges, or blobs, which can be invariant to modifications in scale, rotation, and illumination.
Template matching, alternatively, entails evaluating a template picture (or sample) with a bigger search picture to find situations of the template inside the search picture. The template is moved throughout the search picture, and a similarity metric is computed at every place to find out the diploma of match.
Each feature-based matching and template matching have their strengths and weaknesses, and the selection between them will depend on elements equivalent to the character of the issue, computational necessities, and the specified stage of robustness. Understanding the rules and traits of those strategies is crucial for successfully fixing varied pc imaginative and prescient duties.



