OpenAI’s imaginative and prescient fashions equivalent to GPT-4o carry out properly at a variety of duties, from visible query answering to picture classification. One of the vital thrilling purposes of those capabilities is optical character recognition (OCR), which permits the mannequin to interpret and convert photographs of handwritten or printed textual content into digital textual content.
This tutorial will information you thru organising GPT-4’s imaginative and prescient mannequin to translate paper notes and save the contents in a Google Doc. We’ll use Roboflow Workflows, a low-code pc imaginative and prescient utility builder, to create our utility. Let’s get began! By leveraging the Google API and Roboflow Workflow, you possibly can seamlessly combine AI-driven textual content recognition into your doc creation course of.
Step #1: Arrange a Workflow
Roboflow Workflows is a web-based, interactive pc imaginative and prescient utility builder. You should utilize Workflows to outline multi-stage pc imaginative and prescient purposes that may be run within the cloud or by yourself {hardware}.
Workflows may also name exterior vision-capable APIs equivalent to GPT-4o, a function we are going to leverage in our utility.
To get began, first go to Workflows within the Roboflow utility:

Then, click on lick on “Create Workflow”.

Subsequent, click on “Customized Workflow” and click on “Create”:

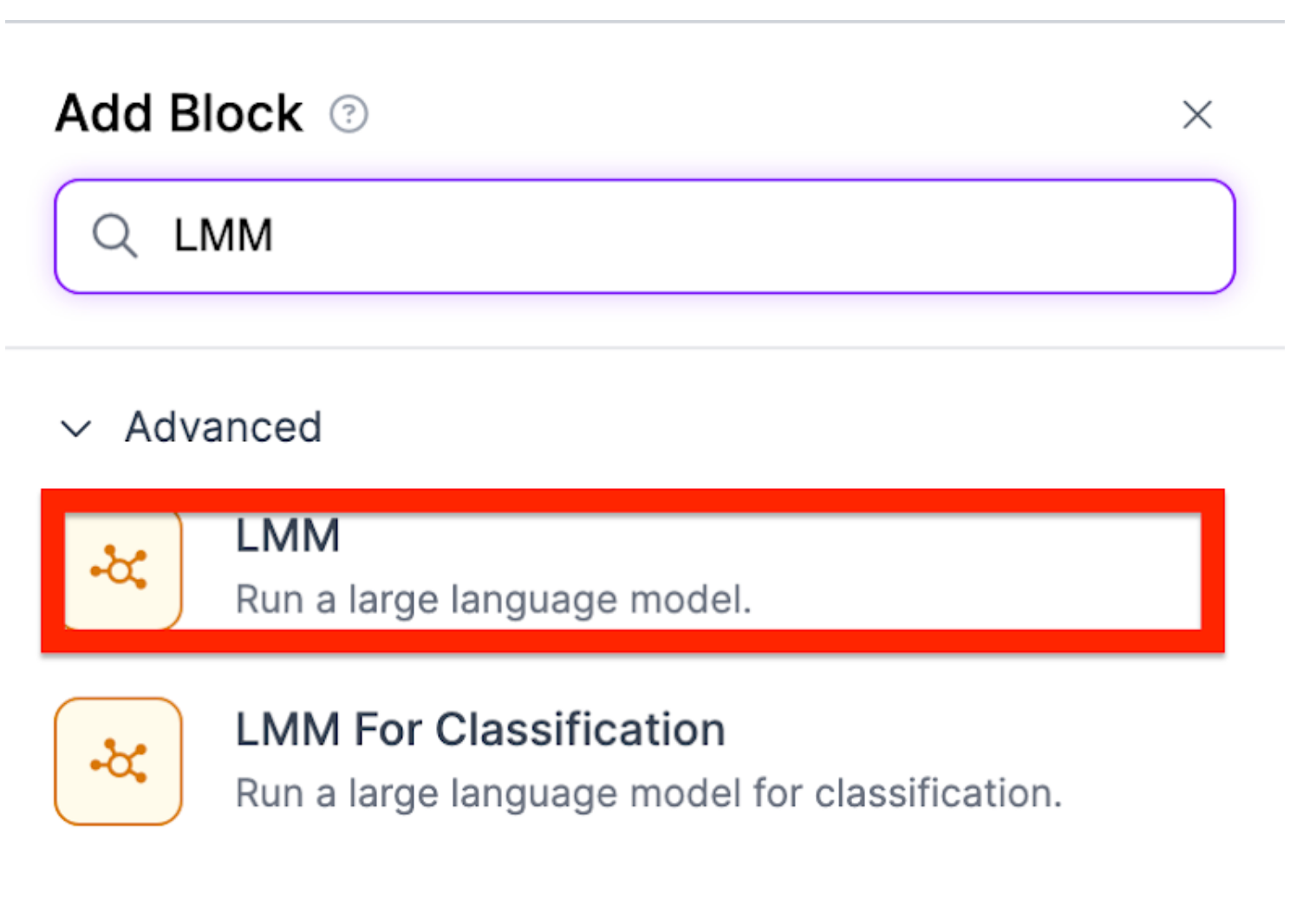
Subsequent, navigate so as to add block and seek for “LMM”:

Add the LMM block:
6. Add your immediate. That is the immediate that shall be despatched to GPT with our picture. A immediate we now have discovered to work properly is:
“Flip this into textual content. Make it the identical format because it was written in. For instance, if there are areas to divide completely different sections, add areas. If some textual content is bolded, add the bolded textual content.” This immediate works since we’re creating an OCR mannequin.
Then open the non-compulsory properties tab and add your OpenAI API-Key:

Subsequent, we have to join the blue Reponse block to the LMM block. Add the output by first clicking the response block and including output within the decrease proper nook.

Subsequent, add “$steps.lmm..*” to the trail. This may join the LMM to the response.

Lastly, save the workflow, then click on “Deploy Workflow” to retrieve the code wanted to deploy the Workflow.

Step 2. Arrange Google Docs Entry
As a way to join Google Docs with our utility, we now have to create a venture on Google Console. Here’s a transient video tutorial demonstrating learn how to accomplish this.
After organising our console, create a Google Doc to hyperlink to our textual content. Moreover, get the id of the doc. We discover this by grabbing the part in between “/d/” and “/edit”.

Be sure to share the doc along with your service account. Discover your service account by navigating to IAM. Add them to be an editor in your Google Doc.

Step #3: Arrange the Code
1. Set Up Colab Setting
First, set your Colab to make use of GPU with the next command.
!nvidia-smi
Subsequent, set up inference, opencv-python, roboflow, google-auth, and google-auth-oauthlib.
!pip set up inference opencv-python roboflow google-auth google-auth-oauthlib2. Paste the mannequin code
Get the mannequin code from the “Deploy Workflow” tab within the Roboflow Workflows builder, the place we arrange our workflow.
from inference_sdk import InferenceHTTPClient consumer = InferenceHTTPClient(
api_url="https://detect.roboflow.com",
api_key="YOUR_API_KEY"
) outcome = consumer.run_workflow(
workspace_name="nathan-yan",
workflow_id="pocket book",
photographs={"picture": "/content material/IMG_3566.jpg"},
)3. Retrieve the workflow output
By the outcome, we have to get the uncooked output of the textual content. We will obtain this by getting the primary worth of output and getting the uncooked output worth from the dictionary.
output = outcome[0]
true_result = output["output"]["raw_output"]4. Load the Google Console credentials
Use the next code to load your Google Console credentials.
import re
from google.oauth2 import service_account
from googleapiclient.discovery import construct
import json def load_credentials(service_account_file):
attempt:
with open(service_account_file, 'r') as file:
creds_info = json.load(file)
required_fields = ['type', 'project_id', 'private_key_id', 'private_key', 'client_email', 'client_id', 'auth_uri', 'token_uri', 'auth_provider_x509_cert_url']
for discipline in required_fields:
if discipline not in creds_info:
elevate ValueError(f"Lacking required discipline: {discipline}")
return service_account.Credentials.from_service_account_file(service_account_file, scopes=SCOPES)
besides Exception as e:
elevate ValueError(f"Error loading credentials: {e}")5. Create logic for brand spanking new traces and bolding
We might want to write some processing logic to control the output from our Workflow, which is outlined within the code snippet under.
def parse_input(input_string):
# Cut up enter into sections based mostly on clean traces
sections = input_string.break up('nn')
return sections def generate_requests(sections):
requests = []
index = 1 for part in sections:
traces = part.break up('n')
textual content = ''
is_bold = False if traces[0].startswith('**') and contours[-1].endswith('**'):
is_bold = True
traces[0] = traces[0].substitute('**', '', 1)
traces[-1] = traces[-1].substitute('**', '', 1) for line in traces:
textual content += line + 'n' requests.append({"insertText": {"location": {"index": index}, "textual content": textual content + "n"}}) if is_bold:
requests.append({
"updateTextStyle": {
"vary": {"startIndex": index, "endIndex": index + len(textual content)},
"textStyle": {"daring": True},
"fields": "daring"
}
}) index += len(textual content) + 1 # +1 for the newline character return requestsThe primary perform splits the string into sections by taking a look at what number of traces it skips.
The second perform:
- Additional splits the string into extra sections
- Replaces “**” with nothing and units is_bold to True to establish bolded objects
- Provides line to textual content
- Provides textual content to a listing referred to as requests by storing it in a dictionary
- Checks the textual content to see what has daring options and offers these textual content a distinct dictionary worth
- Returns the listing referred to as requests
6. Run the appliance
Utilizing Google API, we are able to put the entire information onto the doc.
The principle perform:
- Masses the credentials utilizing load_credentialsParse an enter string utilizing parse_input
Generate API requests utilizing generate_requests
Use the Google Docs API to ship the requests and replace the doc
def primary():
# Load the credentials from the JSON file
SCOPES = ['https://www.googleapis.com/auth/documents']
SERVICE_ACCOUNT_FILE = 'ACCOUNT_FILE GOTTEN IN STEP 2' creds = service_account.Credentials.from_service_account_file(
SERVICE_ACCOUNT_FILE, scopes=SCOPES) service = construct('docs', 'v1', credentials=creds) # The ID of the Google Doc you wish to replace
DOCUMENT_ID = 'GOOGLE_DOCUMENT_ID' input_string = true_result
sections = parse_input(input_string)
requests = generate_requests(sections) outcome = service.paperwork().batchUpdate(
documentId=DOCUMENT_ID,
physique={'requests': requests}
).execute() print(f'Up to date doc: {outcome}') if __name__ == "__main__":
primary()
Now that every one the code is written it’s time to try it out. If we enter a picture like this by way of to the our mannequin, the mannequin will have the ability to decipher the textual content, ensuing within the following picture

Conclusion
By following these steps, you possibly can effectively convert handwritten or printed notes into digital textual content utilizing superior AI capabilities from fashions like GPT-4.
On this information, you discovered learn how to use GPT-4 and join it with Google Paperwork. Be at liberty to make use of this information to know learn how to use GPT-Four for optical character recognition duties or join Google API to Google Docs. For extra pc imaginative and prescient initiatives, take a look at our Cookbooks.



