RT-DETR, quick for “Actual-Time DEtection TRansformer”, is a pc imaginative and prescient mannequin developed by Peking College and Baidu. Of their paper, “DETRs Beat YOLOs on Actual-time Object Detection” the authors declare that RT-DETR can outperform YOLO fashions in object detection, each in velocity and accuracy. The mannequin has been launched beneath the Apache 2.Zero license, making it an important choice, particularly for enterprise tasks.
Just lately, RT-DETR was added to the `transformers` library, considerably simplifying its fine-tuning course of. On this tutorial, we’ll present you find out how to practice RT-DETR on a customized dataset. Go right here to instantly entry the Colab Pocket book. Let’s dive in!
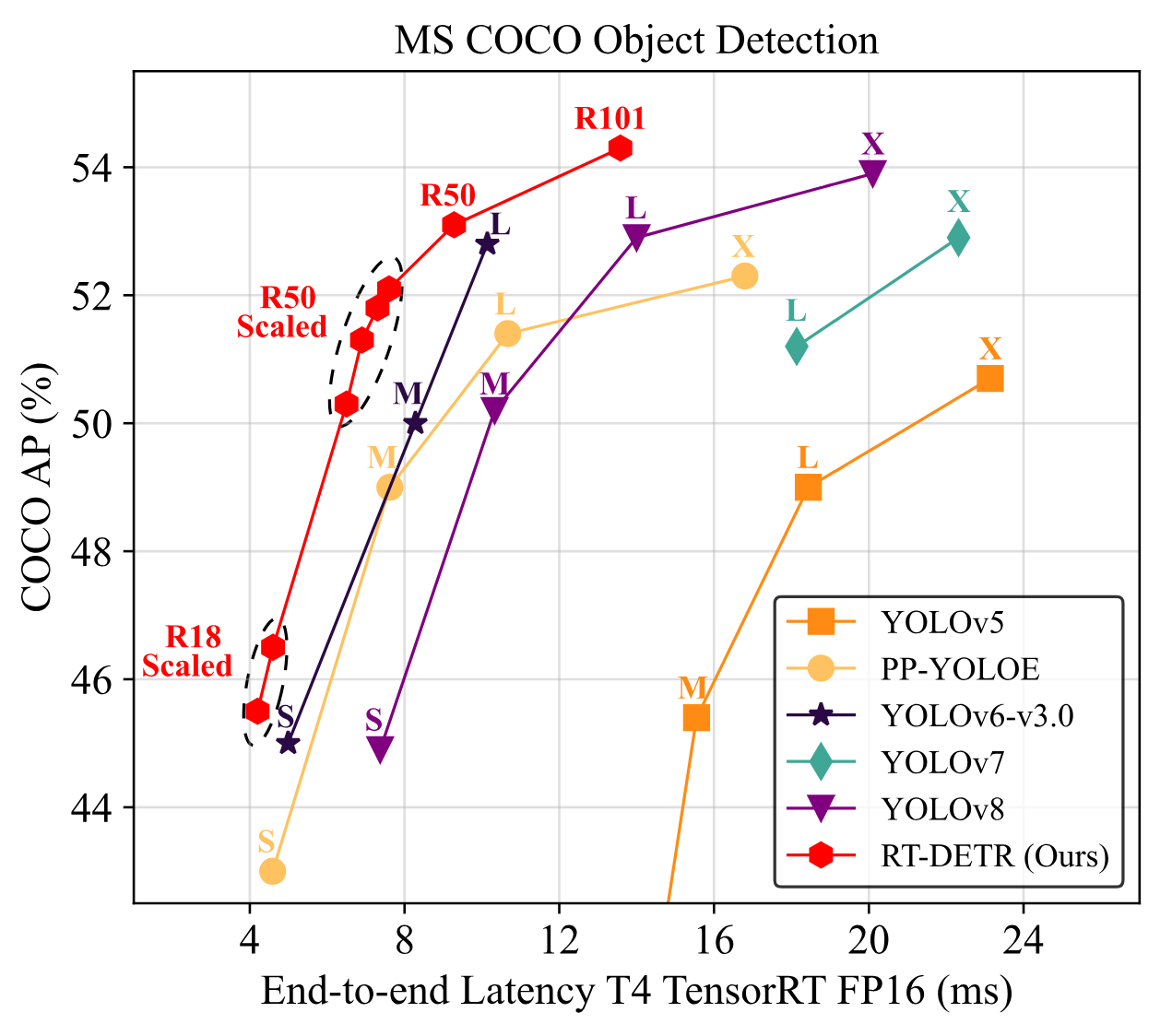
Overview of RT-DETR
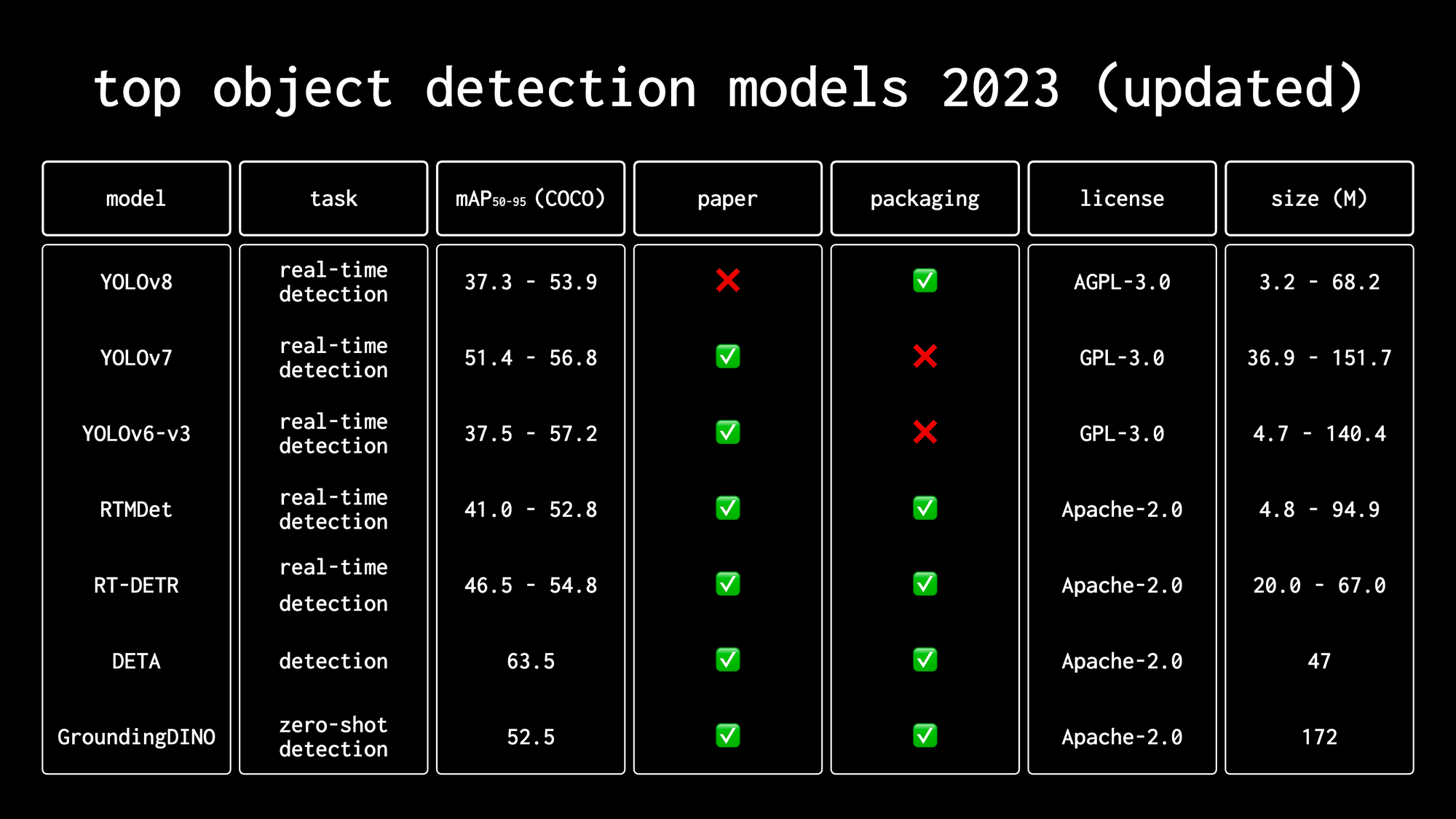
We talked about RT-DETR in our video, “High Object Detection Fashions in 2023“. Test it out if you wish to see a comparability of RT-DETR with different fashionable object detection fashions like completely different variations of YOLO, RTMDet, or GroundingDINO.
RT-DETR builds upon the DETR mannequin developed by Meta AI in 2020, which was the primary to efficiently leverage the transformer structure for object detection. DETR revolutionized object detection by eliminating the necessity for hand-designed elements like non-maximum suppression and anchor era, streamlining the detection pipeline.
Earlier than you begin
To coach RT-DETR on a customized dataset, we have to correctly configure our surroundings. This tutorial is accompanied by a pocket book which you can open in a separate tab and comply with alongside.
💡
GPU Acceleration
If you’re utilizing our Google Colab, guarantee you may have entry to an NVIDIA T4 GPU by working the nvidia-smi command. If you happen to encounter any points, navigate to Edit -> Pocket book settings -> {Hardware} accelerator, set it to T4 GPU, after which click on Save.
If you’re working the code regionally, additionally, you will want an NVIDIA GPU with roughly 11GB VRAM assuming a batch measurement of 16. Relying on the quantity of reminiscence in your GPU, you could want to decide on completely different hyperparameter values throughout coaching.
Secrets and techniques
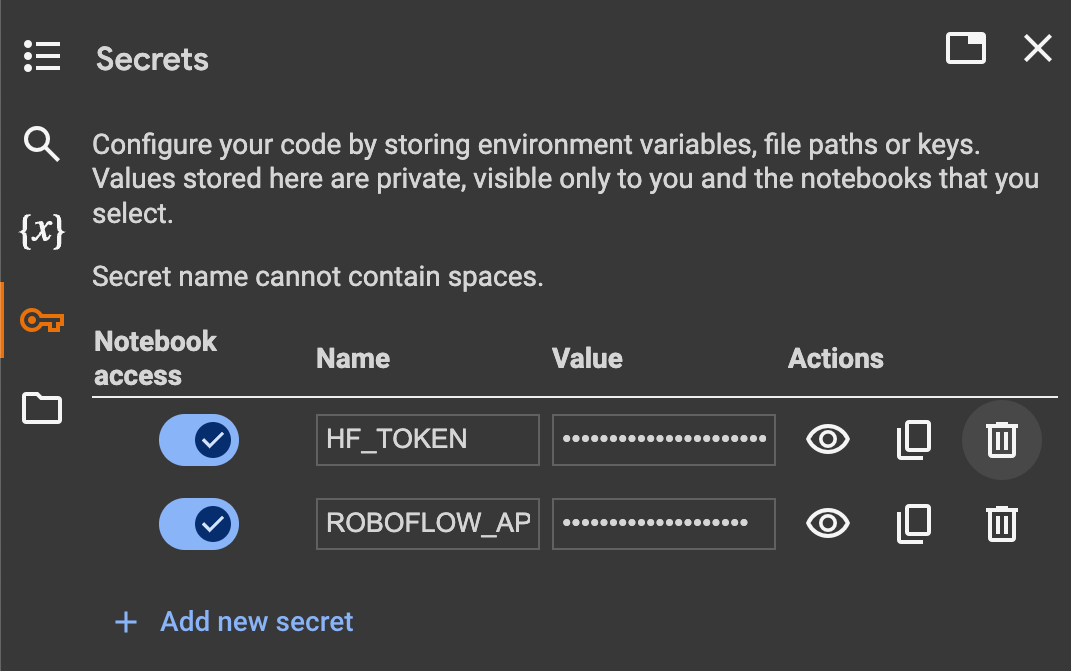
Moreover, we might want to set the values of two secrets and techniques: the HuggingFace token, to obtain the pre-trained mannequin, and the Roboflow API key, to obtain the thing detection dataset.
Open your HuggingFace settings web page, click onEntry Tokens, then New Token to generate a brand new token. To get the Roboflow API key, go to your Roboflow settings web page, click on Copy. It will place your personal key within the clipboard. If you’re utilizing Google Colab, go to the left pane and click on on Secrets and techniques (🔑).
Then retailer the HuggingFace Entry Token beneath the title HF_TOKEN and retailer the Roboflow API Key beneath the title ROBOFLOW_API_KEY. If you’re working the code regionally, merely export the values of those secrets and techniques as setting variables.
The final step earlier than we start is to put in all the mandatory dependencies. We are going to want transformers and speed up to coach the mannequin, roboflow to obtain the dataset from Roboflow Universe, albumentations and supervision to enhance our dataset and feed it to our mannequin throughout coaching. Lastly, we’ll use torchmetrics to benchmark the mannequin and measure its efficiency on the validation dataset throughout coaching.
pip set up -q git+https://github.com/huggingface/transformers.git
pip set up -q git+https://github.com/roboflow/supervision.git
pip set up -q speed up roboflow torchmetrics
pip set up -q "albumentations>=1.4.5"Load pre-trained RT-DETR mannequin
Earlier than we begin, let’s load our pre-trained mannequin into reminiscence and carry out a take a look at inference. This is without doubt one of the best methods to substantiate that our surroundings is about up accurately and every little thing is working as anticipated.
We select the checkpoint we wish to use after which initialize the mannequin and processor. Within the transformers library, the mannequin encapsulates the structure and realized parameters, whereas the processor handles the preprocessing of enter information (photographs in our case) and postprocessing of mannequin outputs to acquire the ultimate predictions.
import torch
from transformers import AutoModelForObjectDetection, AutoImageProcessor CHECKPOINT = "PekingU/rtdetr_r50vd_coco_o365"
DEVICE = torch.gadget("cuda" if torch.cuda.is_available() else "cpu") mannequin = AutoModelForObjectDetection.from_pretrained(CHECKPOINT).to(DEVICE)
processor = AutoImageProcessor.from_pretrained(CHECKPOINT)To carry out inference, we load our picture utilizing the Pillow library – it’s obtainable out of the field in Google Colab, however in case you are working the code regionally additionally, you will want to put in it individually.
Subsequent, we move it by means of the processor, which performs normalization and resizing of the picture. The ready enter is then handed by means of the mannequin. You will need to word that the inference is enclosed inside the torch.no_grad context supervisor.
This context supervisor quickly disables gradient calculations, which is crucial for inference because it reduces reminiscence consumption and quickens computations since gradients should not wanted throughout this part.
import requests
from PIL import Picture URL = "https://media.roboflow.com/notebooks/examples/canine.jpeg" picture = Picture.open(requests.get(URL, stream=True).uncooked)
inputs = processor(picture, return_tensors="pt").to(DEVICE) with torch.no_grad(): outputs = mannequin(**inputs) w, h = picture.measurement
outcomes = processor.post_process_object_detection( outputs, target_sizes=[(h, w)], threshold=0.3)The simplest option to visualize the outcomes of RT-DETR, in addition to any object detection and segmentation mannequin within the transformers library is to make use of the from_transformers connector obtainable within the supervision bundle. It lets you convert the uncooked mannequin output to the widespread sv.Detections format.
Now you may benefit from a variety of annotators and instruments obtainable in supervision. You may as well simply apply non-max suppression (NMS).
detections = sv.Detections.from_transformers(outcomes[0]).with_nms(threshold=0.1)
labels = [ model.config.id2label[class_id] for class_id in detections.class_id
] annotated_image = picture.copy()
annotated_image = sv.BoundingBoxAnnotator().annotate( annotated_image, detections)
annotated_image = sv.LabelAnnotator().annotate( annotated_image, detections, labels=labels)
Put together Dataset for Coaching RT-DETR
Obtain the dataset from Roboflow Universe
To coach RT-DETR, you have to an object detection dataset. For this tutorial, we’ll use a dataset in COCO format. You’ll be able to simply use datasets in PASCAL VOC and YOLO codecs by making minimal modifications to the code, which I’ll point out shortly.
To obtain a dataset from Roboflow Universe, click on the `Export Dataset` button, and when the popup opens, choose your required output format from the dropdown – in our case, COCO. Additionally, test the “Present obtain code” choice. After just a few seconds, a code snippet might be generated which you can copy into your Google Colab pocket book or coaching script.
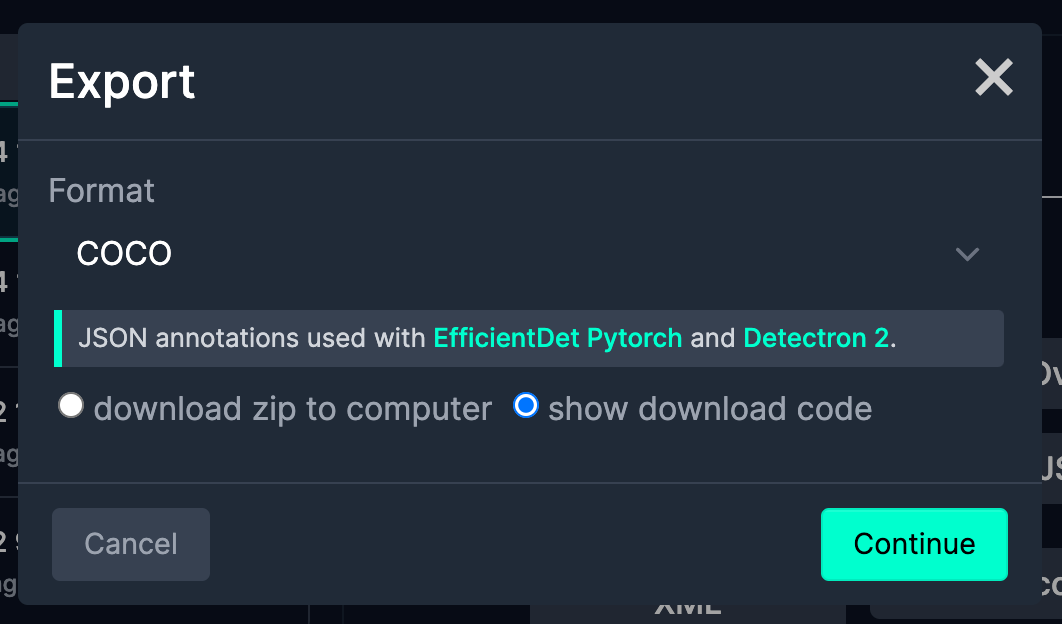
from roboflow import Roboflow
from google.colab import userdata ROBOFLOW_API_KEY = userdata.get('ROBOFLOW_API_KEY')
rf = Roboflow(api_key=ROBOFLOW_API_KEY) undertaking = rf.workspace("roboflow-jvuqo").undertaking("poker-cards-fmjio")
model = undertaking.model(4)
dataset = model.obtain("coco")Load Dataset
As soon as now we have the dataset on disk, it is time to load it into reminiscence. The supervision bundle affords easy-to-use DetectionDataset utilities that assist you to simply load annotations in numerous codecs.
In our case, we usefrom_coco, however from_pascal_voc and from_yolo are additionally obtainable, as you may learn within the documentation. `DetectionDataset` additionally lets you simply cut up, merge, and filter detection datasets. It additionally simply integrates with PyTorchDataset, which you will notice shortly. PyTorch Dataset is an summary class that gives a handy option to entry and course of information samples in a standardized format, making it a basic constructing block for coaching machine studying fashions.
ds_train = sv.DetectionDataset.from_coco( images_directory_path=f"{dataset.location}/practice", annotations_path=f"{dataset.location}/practice/_annotations.coco.json",
)
ds_valid = sv.DetectionDataset.from_coco( images_directory_path=f"{dataset.location}/legitimate", annotations_path=f"{dataset.location}/legitimate/_annotations.coco.json",
)
ds_test = sv.DetectionDataset.from_coco( images_directory_path=f"{dataset.location}/take a look at", annotations_path=f"{dataset.location}/take a look at/_annotations.coco.json",
)
Knowledge Augmentations for Coaching RT-DETR
Knowledge augmentation is without doubt one of the easiest methods to enhance the accuracy of a fine-tuned mannequin. In laptop imaginative and prescient tasks, information augmentation includes making use of numerous transformations to the coaching photographs, comparable to rotations, flips, crops, and coloration changes. This method artificially will increase the dimensions and variety of the coaching dataset, serving to the mannequin generalize higher and turn out to be extra sturdy to variations in real-world information.
A well-liked option to apply augmentation is to make use of the albumentations bundle. Step one is to outline the transformations we wish to apply. Albumentations affords dozens of them, however for the needs of this tutorial, we’ll solely use 4.
import albumentations as A augmentation_train = A.Compose( [ A.Perspective(p=0.1), A.HorizontalFlip(p=0.5), A.RandomBrightnessContrast(p=0.5), A.HueSaturationValue(p=0.1), ], bbox_params=A.BboxParams( format="pascal_voc", label_fields=["category"], clip=True, min_area=25 ),
) augmentation_valid = A.Compose( [A.NoOp()], bbox_params=A.BboxParams( format="pascal_voc", label_fields=["category"], clip=True, min_area=1 ),
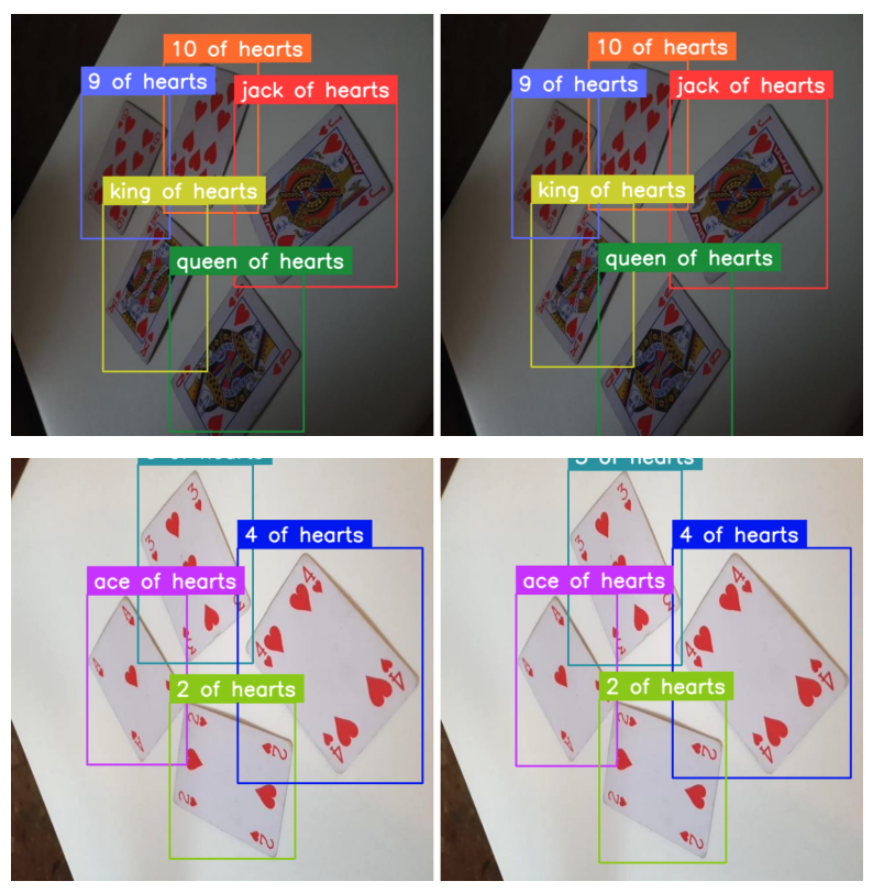
)Now we are able to simply apply these transformations to the supervision DetectionDataset entries. Here’s a comparability of some pairs – authentic and augmented photographs.
from dataclasses import substitute IMAGE_COUNT = 5 for i in vary(IMAGE_COUNT): _, picture, annotations = ds_train[i] output = augmentation_train( picture=picture, bboxes=annotations.xyxy, class=annotations.class_id ) augmented_image = output["image"] augmented_annotations = substitute( annotations, xyxy=np.array(output["bboxes"]), class_id=np.array(output["category"]) )
Outline PyTorch Dataset
The processor expects the annotations to be within the following format: {'image_id': int, 'annotations': Listing[Dict]}, the place every dictionary is a COCO object annotation. Let’s outline a PyTorch Dataset that can load annotations from disk, increase them, and return them within the format anticipated by the RT-DETR processor. The next code snippet might look intimidating, but when we glance nearer, there’s nothing new right here aside from the conversion of annotations to COCO format.
class AugmentedDetectionDataset(Dataset): def __init__(self, dataset, processor, rework): self.dataset = dataset self.processor = processor self.rework = rework @staticmethod def annotations_as_coco(image_id, classes, bins): ... def __len__(self): return len(self.dataset) def __getitem__(self, idx): _, picture, annotations = self.dataset[idx] picture = picture[:, :, ::-1] reworked = self.rework( picture=picture, bboxes=annotations.xyxy, class=annotations.class_id ) picture = reworked["image"] bins = reworked["bboxes"] classes = reworked["category"] formatted_annotations = self.annotations_as_coco( image_id=idx, classes=classes, bins=bins ) end result = self.processor( photographs=picture, annotations=formatted_annotations, return_tensors="pt" ) return {okay: v[0] for okay, v in end result.objects()}Now all now we have to do is initialize the datasets for the practice, take a look at, and legitimate subsets. Take note of making use of completely different augmentations for the coaching set and completely different ones for the validation and take a look at units.
augmented_dataset_train = AugmentedDetectionDataset( ds_train, processor, rework=augmentation_train)
augmented_dataset_valid = AugmentedDetectionDataset( ds_valid, processor, rework=augmentation_valid)
augmented_dataset_test = AugmentedDetectionDataset( ds_test, processor, rework=augmentation_valid)The very last thing we have to do is outline the collect_fn callback. In PyTorch, the collect_fn is a operate that’s handed to the DataLoader to customise how the person information samples are collated right into a batch. In our case, we’d like it to pad the photographs and labels to the identical measurement, because the RT-DETR mannequin expects a fixed-size enter.
def collate_fn(batch): information = {} information["pixel_values"] = torch.stack([ x["pixel_values"] for x in batch] ) information["labels"] = [x["labels"] for x in batch] return informationSuperb-tuning RT-DETR – Code Overview
A lot of the heavy lifting is behind us, and we at the moment are prepared to coach the mannequin. Let’s begin by loading the mannequin with AutoModelForObjectDetection utilizing the identical checkpoint as within the preprocessing step.
id2label = {id: label for id, label in enumerate(ds_train.lessons)}
label2id = {label: id for id, label in enumerate(ds_train.lessons)} mannequin = AutoModelForObjectDetection.from_pretrained( CHECKPOINT, id2label=id2label, label2id=label2id, anchor_image_size=None, ignore_mismatched_sizes=True,
)Within the TrainingArguments use output_dir to specify the place to save lots of your mannequin, then configure hyperparameters as you see match. For num_train_epochs=20 coaching will take about 30 minutes in Google Colab T4 GPU, enhance the variety of epochs to get higher outcomes.
training_args = TrainingArguments( output_dir=f"{dataset.title.substitute(' ', '-')}-finetune", num_train_epochs=20, max_grad_norm=0.1, learning_rate=5e-5, warmup_steps=300, per_device_train_batch_size=16, dataloader_num_workers=2, metric_for_best_model="eval_map", greater_is_better=True, load_best_model_at_end=True, eval_strategy="epoch", save_strategy="epoch", save_total_limit=2, remove_unused_columns=False, eval_do_concat_batches=False,
)Lastly, we’re prepared to begin coaching. All we have to do is move the coaching arguments to the Coach together with the mannequin, dataset, picture processor, and information collator. The Coach class orchestrates the whole coaching course of, dealing with optimization, analysis, and checkpointing.
coach = Coach( mannequin=mannequin, args=training_args, train_dataset=pytorch_dataset_train, eval_dataset=pytorch_dataset_valid, tokenizer=processor, data_collator=collate_fn, compute_metrics=eval_compute_metrics_fn,
) coach.practice()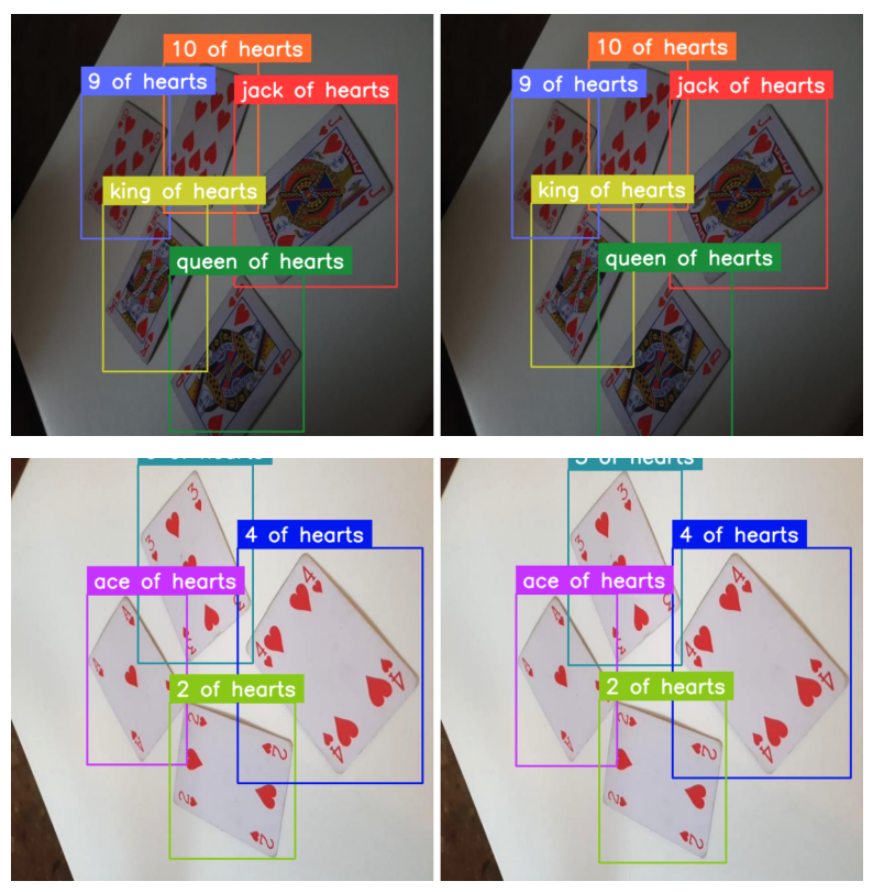
Skilled RT-DETR Mannequin Analysis
As soon as the coaching is full, it is time to benchmark our mannequin on the take a look at subset. We start by amassing two lists: goal annotations and mannequin predictions. To do that, we loop over our take a look at dataset and carry out inference utilizing our newly skilled mannequin.
import supervision as sv targets = []
predictions = [] for i in vary(len(ds_test)): path, sourece_image, annotations = ds_test[i] picture = Picture.open(path) inputs = processor(picture, return_tensors="pt").to(DEVICE) with torch.no_grad(): outputs = mannequin(**inputs) w, h = picture.measurement outcomes = processor.post_process_object_detection( outputs, target_sizes=[(h, w)], threshold=0.3) detections = sv.Detections.from_transformers(outcomes[0]) targets.append(annotations) predictions.append(detections)Imply Common Precision (mAP) is a broadly used metric for evaluating object detection fashions. It considers each the accuracy of object localization (bounding bins) and classification, offering a single complete efficiency measure. Calculating mAP utilizing the supervision bundle could be very easy. In consequence, our mannequin achieved virtually 0.89 mAP, on par with different high real-time object detectors like YOLOv8.
mean_average_precision = sv.MeanAveragePrecision.from_detections( predictions=predictions, targets=targets,
) print(f"map50_95: {mean_average_precision.map50_95:.2f}")
print(f"map50: {mean_average_precision.map50:.2f}")
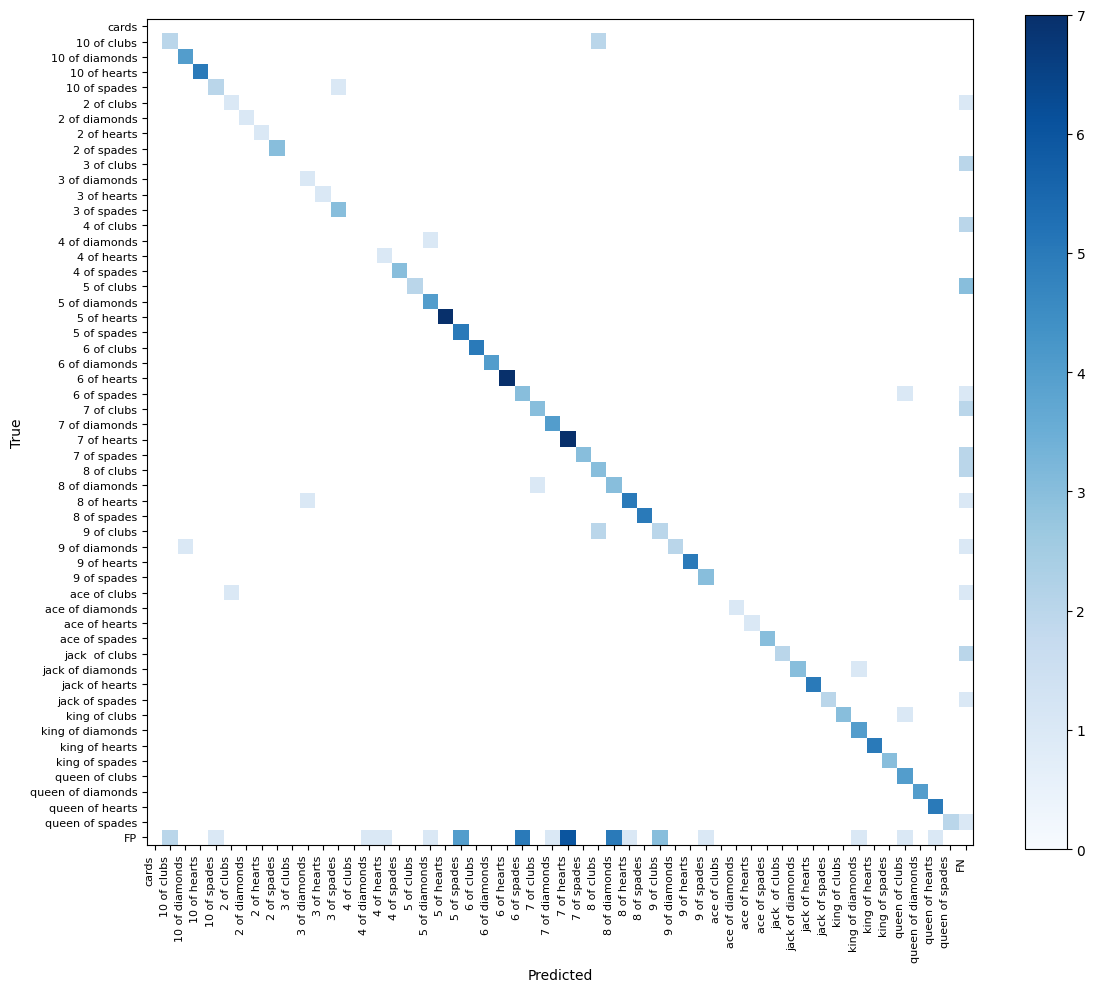
print(f"map75: {mean_average_precision.map75:.2f}")A confusion matrix is a desk summarizing the efficiency of a classification algorithm, displaying the variety of right and incorrect predictions for every class. Within the context of object detection, it reveals the distribution of true positives, false positives, true negatives, and false negatives. The overwhelming majority of detections are on the diagonal of our confusion matrix, which means each the bounding field and the category of our detection are right. The one weak level of our mannequin is a big variety of false negatives, that are objects which can be current within the floor fact however not detected by the mannequin. That is most definitely on account of class imbalance within the dataset.
Conclusion
RT-DETR is without doubt one of the high object detectors. Its distinctive mixture of state-of-the-art velocity and accuracy, together with a completely open-source license, makes it a wonderful alternative, particularly for open-source tasks.
With its current integration into the Transformers library, fine-tuning RT-DETR on customized datasets has turn out to be extra accessible than ever earlier than, opening up new potentialities for object detection purposes.
Discover the accompanying pocket book for a extra hands-on expertise and to experiment with completely different datasets and configurations.


