Introduction
Meta AI (previously Fb AI) has launched a revolutionary AI mannequin referred to as SAM (Phase Something Mannequin), representing a major leap ahead in pc imaginative and prescient and picture segmentation know-how. This text explores SAM’s options, capabilities, potential purposes, and implications for numerous industries.

Overview
- Meta AI’s Phase Something Mannequin (SAM) presents groundbreaking flexibility in picture segmentation primarily based on consumer prompts.
- SAM excels in figuring out and segmenting objects throughout various contexts with out extra coaching.
- The Phase Something Dataset (SA-1B) is the most important of its type, designed to foster in depth purposes and analysis.
- SAM’s structure integrates a picture encoder, immediate encoder, and masks decoder for real-time interactive efficiency.
- Future makes use of of SAM span AR, medical imaging, autonomous autos, and extra, democratizing superior pc imaginative and prescient.
Desk of contents
What’s SAM?
SAM, or Phase Something Mannequin, is an AI mannequin developed by Meta AI that may establish and description any object in a picture or video primarily based on consumer prompts. It’s designed to be versatile, environment friendly, and able to generalizing to new objects and conditions with out extra coaching.
The Imaginative and prescient of Phase Something at its core, the Phase Something venture seeks to interrupt down obstacles which have historically restricted the accessibility and applicability of superior picture segmentation strategies. By decreasing the necessity for task-specific modeling experience, in depth computational assets, and customized information annotation, Meta AI is paving the best way for a extra inclusive and versatile strategy to pc imaginative and prescient.
Key Elements of the Phase Something Venture
Right here’s the important thing element of SAM:
- Phase Something Mannequin (SAM) is a basis mannequin for picture segmentation, designed to be promptable and adaptable to a variety of duties. Its key options embrace:
- Generalizability: SAM can establish and phase objects not encountered throughout coaching, demonstrating exceptional zero-shot switch capabilities.
- Versatility: The mannequin can generate masks for any object in pictures or movies, whatever the area or context.
- Promptability: Customers can information SAM utilizing numerous varieties of prompts, making it extremely versatile and user-friendly.
- Phase Something 1-Billion masks dataset (SA-1B) Alongside SAM, Meta AI is releasing the SA-1B dataset, which is:
- The most important segmentation dataset ever created
- Designed to allow a broad set of purposes
- Meant to foster additional analysis into basis fashions for pc imaginative and prescient
- Open Entry Meta AI is making each SAM and the SA-1B dataset obtainable to the analysis neighborhood:
- The SA-1B dataset is out there for analysis functions
- SAM is launched underneath the permissive Apache 2.zero open license
Historic Context of Segmentation Approaches
To know the importance of SAM, it’s essential to look at the historic context of segmentation approaches:
Conventional Segmentation Approaches
- Interactive Segmentation:
- May phase any class of object.
- Required guide steering and iterative refinement.
- Time-consuming and labor-intensive.
- Computerized Segmentation:
- Allowed for automated segmentation of predefined object classes.
- Required substantial manually annotated coaching information (hundreds of examples).
- Wanted important computing assets and technical experience.
- Restricted to particular, pre-trained object classes.
SAM’s Unified and Versatile Method
SAM transcends the restrictions of each interactive and automated segmentation by providing:
- Versatility: A single mannequin able to each interactive and automated segmentation.
- Promptable Interface: It permits for versatile use throughout numerous segmentation duties by engineered prompts (clicks, containers, textual content, and so forth.).pc imaginative and prescient purposes
- Generalization Capabilities:
- Educated on a various dataset of over 1 billion masks
- Can generalize to new object varieties and pictures past its coaching information
- Eliminates the necessity for task-specific information assortment and mannequin fine-tuning typically
Key Benefits of SAM’s Method
Listed below are the benefits:
- Process Generalization: SAM can adapt to numerous segmentation duties with out retraining or fine-tuning.
- Area Generalization: The mannequin can successfully phase objects in new domains or picture varieties not encountered throughout coaching.
- Lowered Limitations: Practitioners can now deal with complicated segmentation duties with out requiring in depth datasets or specialised mannequin coaching.
- Flexibility: SAM’s promptable interface permits for inventive problem-solving in numerous segmentation eventualities.
Implications for the Discipline
SAM’s generalized strategy to segmentation has far-reaching implications:
- Democratization: Makes superior segmentation capabilities accessible to a broader vary of customers and purposes.
- Innovation Catalyst: Permits fast prototyping and growth of latest pc imaginative and prescient purposes.
- Analysis Alternatives: Opens new avenues for exploring basis fashions in pc imaginative and prescient.
- Interdisciplinary Purposes: Facilitates the adoption of superior segmentation strategies in various fields, from medical imaging to environmental monitoring.
How Does SAM Works? [Promptable Segmentation]
SAM’s revolutionary strategy to segmentation is rooted in promptable AI, drawing inspiration from latest developments in pure language processing and pc imaginative and prescient:
Basis Mannequin Method
SAM is designed as a basis mannequin able to zero-shot and few-shot studying for brand new datasets and duties, much like massive language fashions in NLP. This strategy permits SAM to adapt to numerous segmentation duties with out in depth retraining.
Immediate-Primarily based Segmentation
SAM is educated to return a sound segmentation masks for any immediate. Prompts will be foreground/background factors, a tough field or masks, freeform textual content, or any data indicating what to phase in a picture. Even when a immediate is ambiguous and will check with a number of objects, the output is an affordable masks for a type of objects.
Mannequin Structure and Constraints
SAM’s design is optimized for real-time efficiency and broad accessibility. It’s designed to run in real-time on a CPU in an internet browser, enabling interactive use by annotators for environment friendly information assortment. The mannequin balances segmentation high quality with runtime efficiency, yielding efficient leads to apply.
Technical Elements
SAM’s structure consists of a picture encoder, a immediate encoder, and a masks decoder. The picture encoder produces a one-time embedding for the enter picture. The light-weight immediate encoder converts any immediate into an embedding vector in real-time. The masks decoder combines these embeddings to foretell segmentation masks.
Efficiency Metrics
After the preliminary picture embedding computation, SAM can produce a phase in simply 50 milliseconds for any given immediate, working inside an internet browser surroundings.
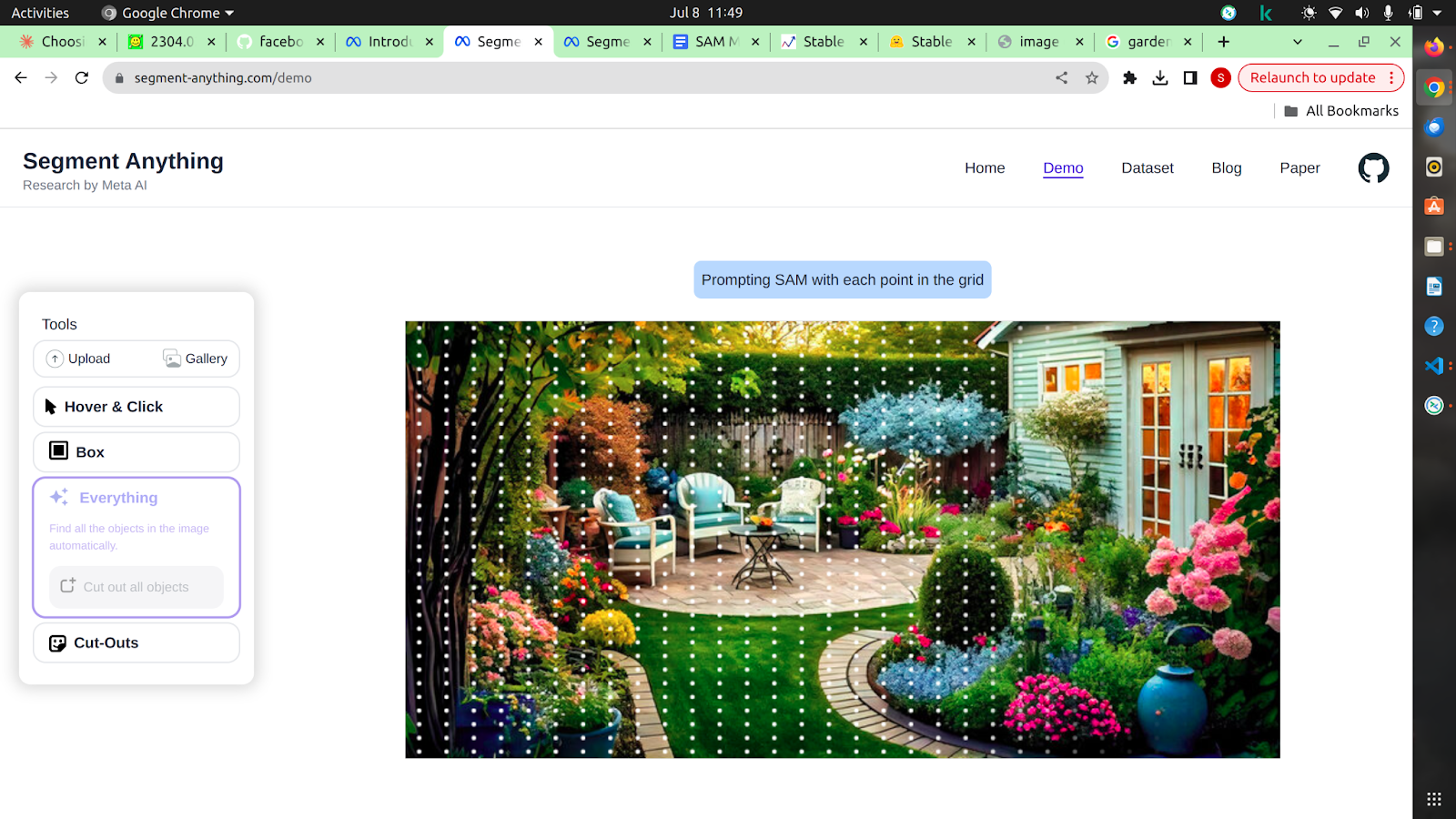
Right here is an instance of implementation of the SAM mannequin on a given image, You possibly can merely hover and phase objects, or field out the whole lot.
Enter Picture
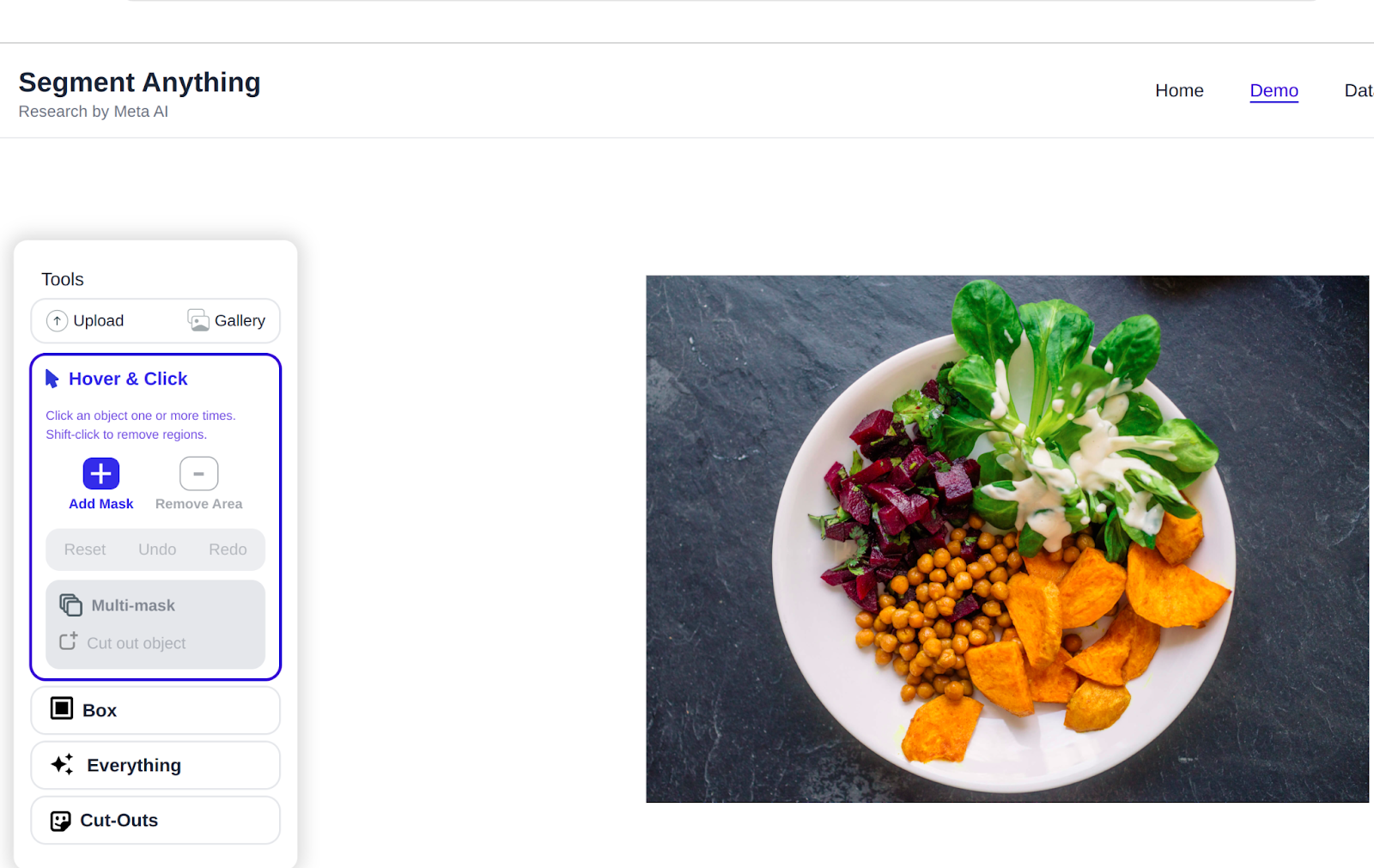
Output:
Right here, you possibly can take a look at the demo your self for a given picture.
There are a number of choices offered UI to take a look at the options offered by the segmentation mannequin,
You possibly can add an image or select one from their gallery of pictures.
Right here, we uploaded an image

After importing an image,
One can find many choices to play with the mannequin, you can begin by hovering and clicking on any object to see how exactly it segments.
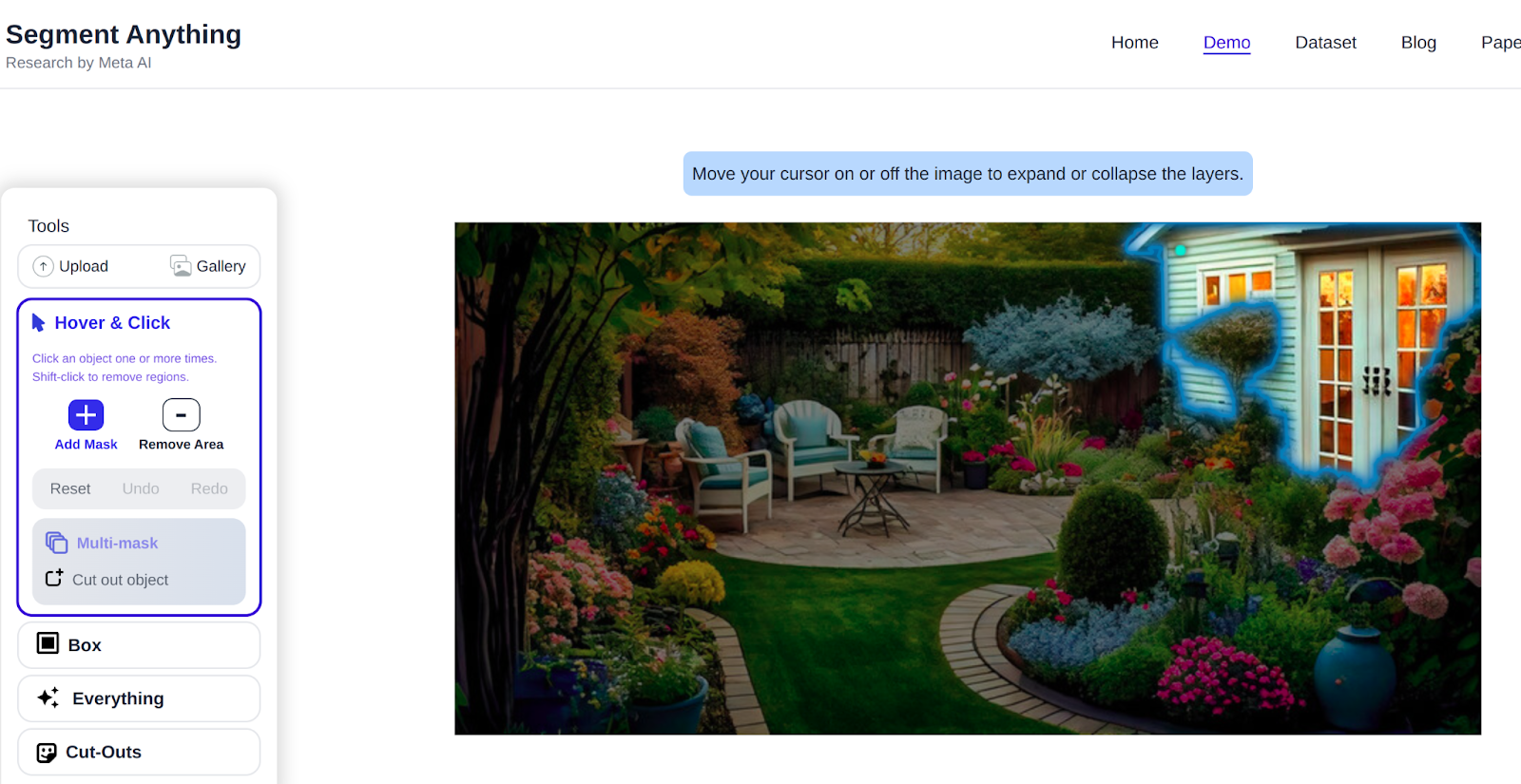
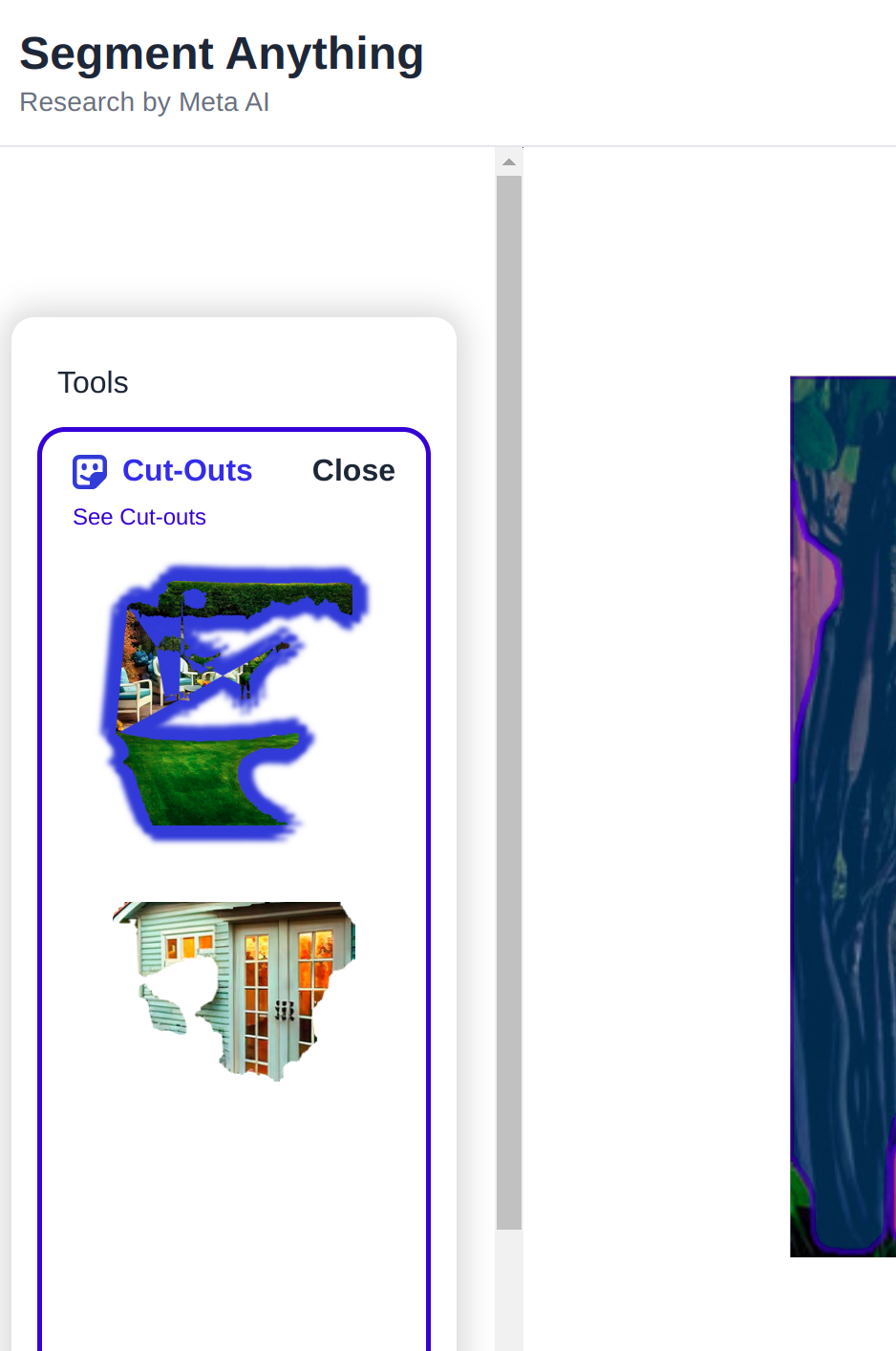
Then Subsequent you possibly can field any object within the image, Utilizing your mouse cursor, you drag a ractangular field within the image to phase object after which hold the reduce outs as nicely.

Within the Reduce Outs choices, you’ll find your cutouts:
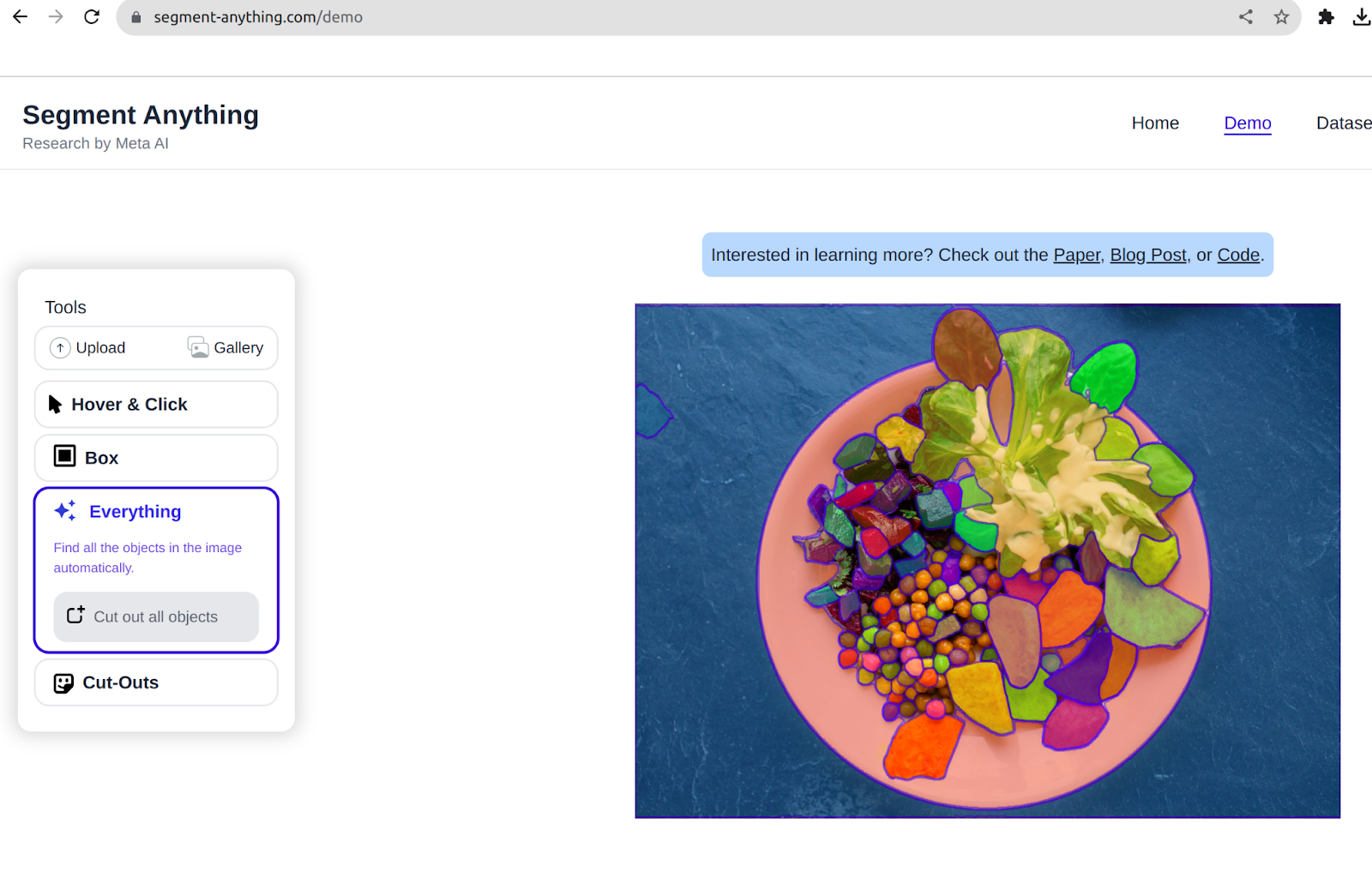
Or you possibly can click on on the whole lot to take a look at every object well-segmented:
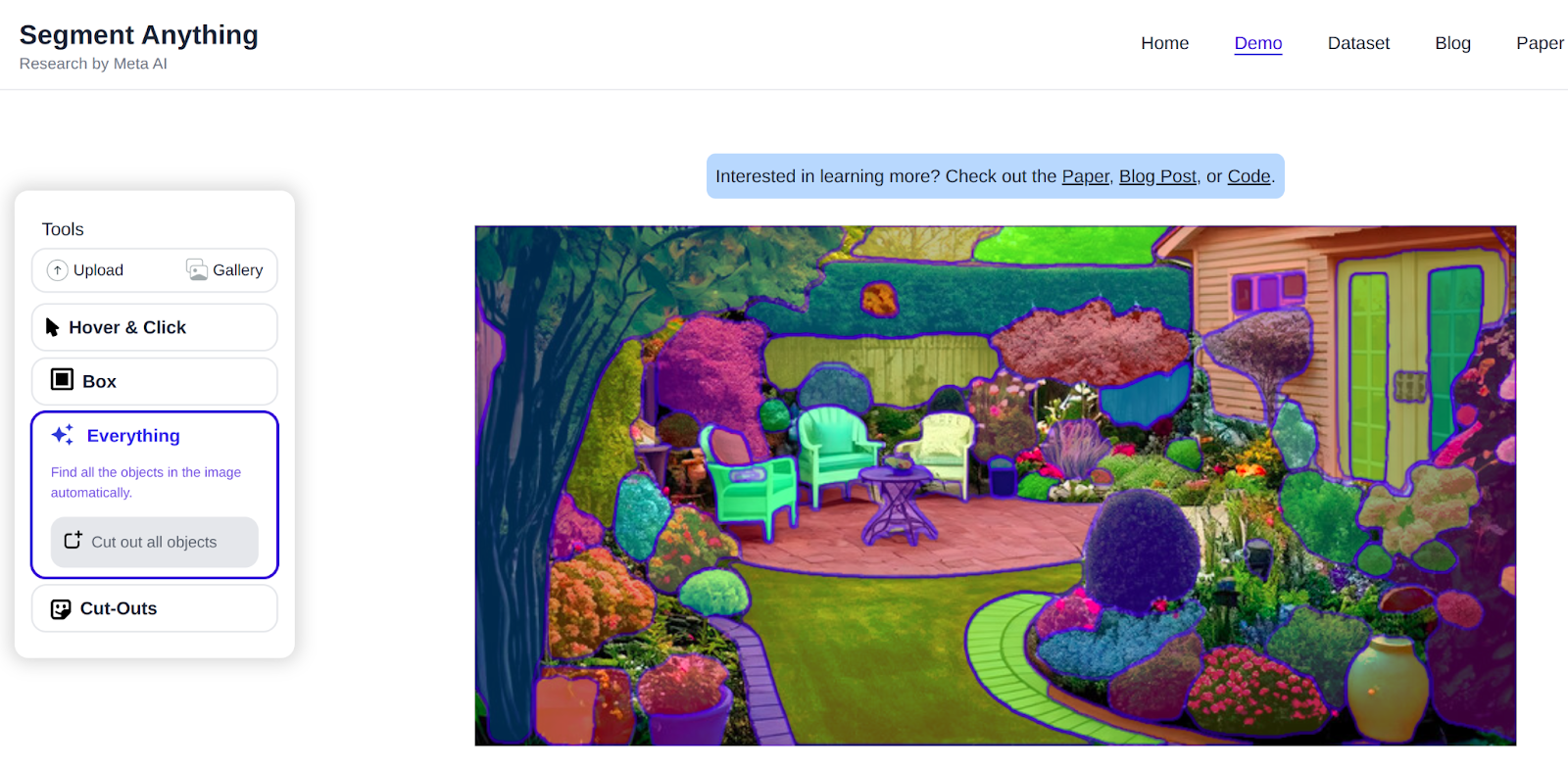
Additionally learn: Introduction to Picture Segmentation
The Analysis on this Mannequin
The Phase Something venture introduces a brand new job, mannequin, and dataset for picture segmentation. The important thing elements are:
- Process: Promptable segmentation, the place the mannequin returns a sound segmentation masks for any given immediate (e.g., factors, containers, textual content) indicating what to phase in a picture.
- Mannequin: The Phase Something Mannequin (SAM) is designed to be promptable and environment friendly. It consists of a picture encoder, a immediate encoder, and a masks decoder, and it could possibly generate masks in real-time (∼50ms) in an internet browser.
- Dataset: SA-1B, the most important segmentation dataset thus far, comprises over 1 billion masks on 11 million licensed and privacy-respecting pictures.
The researchers developed a “information engine” to create this large dataset, involving assisted-manual, semi-automatic, and absolutely automated annotation levels.
SAM demonstrates spectacular zero-shot efficiency on numerous duties, typically aggressive with or superior to prior absolutely supervised outcomes. The mannequin can generalize to new picture distributions and duties with out extra coaching.
The paper additionally addresses accountable AI issues, finding out potential equity points and biases within the mannequin and dataset.
The researchers are releasing each SAM and SA-1B to foster additional analysis into basis fashions for pc imaginative and prescient. They consider SAM on quite a few duties, together with edge detection, object proposal era, and occasion segmentation, showcasing its versatility and effectiveness in zero-shot switch eventualities
Additionally Learn: Deep Studying for Picture Segmentation with TensorFlow
Phase Something Venture
The Phase Something venture introduces a brand new job, mannequin, and dataset for picture segmentation. Key elements embrace:
- Process: Promptable segmentation, impressed by subsequent token prediction in NLP. The mannequin returns a sound segmentation masks for any given immediate (e.g., factors, containers, textual content, masks), indicating what to phase in a picture, even when prompts are ambiguous.
- Mannequin: The Phase Something Mannequin (SAM) consists of:
- A picture encoder (pre-trained Imaginative and prescient Transformer)
- A versatile immediate encoder for sparse and dense prompts
- A quick masks decoder
SAM can generate a number of output masks for ambiguous prompts and predicts confidence scores for every masks. It’s designed for effectivity, with the immediate encoder and masks decoder operating in an internet browser on CPU in ~50ms.

- Pre-training: SAM is educated utilizing a simulated sequence of prompts for every pattern, evaluating predictions towards floor fact.
- Zero-shot switch: The mannequin can adapt to numerous segmentation duties by immediate engineering with out extra coaching.
- Effectivity and real-time efficiency: SAM’s design permits for real-time interactive prompting, making it appropriate for numerous purposes and integration into bigger methods.
- Coaching: The mannequin is educated utilizing a mixture of focal loss and cube loss, with a simulated interactive setup utilizing randomly sampled prompts in a number of rounds per masks.
The researchers emphasize the facility of prompting and composition in enabling a single mannequin to perform a variety of duties, probably even these unknown on the time of mannequin design. This strategy is in comparison with different basis fashions like CLIP and its position within the DALL·E picture era system.
Phase Something Information Engine
Phase Something Information Engine, which was used to create the SA-1B dataset containing 1.1 billion masks. The info engine operated in three levels:
Assisted-manual Stage
- Skilled annotators used a browser-based software powered by SAM to label masks interactively.
- Annotators labeled each “stuff” and “issues” with out semantic constraints.
- SAM was retrained 6 occasions as extra information was collected, enhancing effectivity.
- 4.3M masks have been collected from 120ok pictures.
- Annotation time decreased from 34 to 14 seconds per masks.
Semi-automatic stage
- Aimed to extend masks variety.
- A bounding field detector was used to detect assured masks routinely.
- Annotators targeted on labeling extra unannotated objects.
- 5.9M extra masks have been collected from 180ok pictures.
- The mannequin was retrained 5 occasions throughout this stage.
- The typical variety of masks per picture elevated from 44 to 72.
Totally automated stage
- Annotation grew to become absolutely automated resulting from mannequin enhancements.
- An ambiguity-aware mannequin was used to foretell legitimate masks for ambiguous instances.
- Prompted the mannequin with a 32×32 common grid of factors.
- Chosen assured and steady masks, then utilized non-maximal suppression.
- Processed a number of overlapping zoomed-in picture crops for smaller masks.
- Utilized to all 11M pictures within the dataset, producing 1.1B high-quality masks.
This information engine strategy allowed the researchers to create an enormous, various dataset of segmentation masks, which was essential for coaching the extremely succesful Phase Something Mannequin (SAM).
Additionally Learn: Semantic Segmentation: Introduction to the Deep Studying Method Behind Google Pixel’s Digital camera!
Phase Something Dataset (SA-1B)
The SA-1B dataset consists of 11 million various, high-resolution, licensed, and privacy-protecting pictures with 1.1 billion high-quality segmentation masks. Key options embrace:
Photographs
- 11 million licensed pictures
- Excessive decision (3300×4950 pixels on common)
- Downsampled to 1500 pixels on the shortest aspect for launch
- Faces and car license plates blurred
Masks
- 1.1 billion masks, 99.1% generated routinely
- Top quality: 94% of masks have over 90% IoU with professionally corrected variations
- Solely routinely generated masks are included within the closing dataset
Comparability to present datasets
- SA-1B has 11 occasions extra pictures and 400 occasions extra masks than the most important present segmentation dataset
- Higher protection of picture corners in comparison with different datasets
- Extra small and medium-sized masks per picture
Geographic distribution
- Photographs from most international locations worldwide
- The three international locations with probably the most pictures are from totally different elements of the world
The researchers hope that SA-1B will assist their very own work and function a worthwhile useful resource for the broader pc imaginative and prescient analysis neighborhood, fostering new developments in basis fashions and dataset creation.
Future Implications of SAM: A Imaginative and prescient for Superior AI Purposes
The arrival of SAM, facilitated by SA-1B, has revolutionized analysis and opened doorways for additional developments in picture segmentation. This foundational know-how permits different researchers to coach fashions for various purposes, fostering the event of latest datasets with enhanced annotations, together with textual content descriptions related to every masks.
Additionally Learn: Picture Segmentation Algorithms With Implementation in Python – An Intuitive Information
What Lies Forward?
Trying in direction of the longer term, SAM holds the potential to establish on a regular basis objects through AR glasses, offering customers with real-time reminders and directions. Its purposes span a variety of domains, from aiding farmers in agriculture to aiding biologists of their analysis. By sharing their analysis and datasets, the creators goal to speed up developments in segmentation and broader picture and video understanding. The promptable segmentation mannequin, appearing as a element in bigger methods, showcases the facility of composability — enabling a single mannequin to carry out numerous duties, together with these unexpected on the time of its design.
The combination of SAM into composable methods, enhanced by immediate engineering, paves the best way for various purposes throughout AR/VR, content material creation, scientific analysis, and normal AI methods. Researchers foresee a more in-depth integration between pixel-level picture and higher-level semantic understanding, unlocking much more highly effective AI capabilities.
Purposes of SAM
- Picture and Video Modifying: Simplifying object choice and manipulation in picture and video enhancing software program.
- Augmented Actuality: Enhancing AR experiences by precisely figuring out and interacting with real-world objects.
- Medical Imaging: Aiding in analyzing medical scans by exactly outlining organs, tumors, or different buildings.
- Autonomous Automobiles: Enhancing object detection and scene understanding for self-driving vehicles.
- Robotics: Enhancing robots’ capacity to establish and work together with objects of their surroundings.
- Content material Moderation: Automating figuring out and flagging inappropriate content material in pictures and movies.
- E-commerce: Streamlining product cataloging and visible search capabilities.
Implications and Challenges
- Democratization of AI: SAM’s versatility might make superior pc imaginative and prescient capabilities extra accessible to a wider vary of customers and purposes.
- Moral Issues: As with all highly effective AI software, there are issues about potential misuse, reminiscent of in surveillance or deepfake creation.
- Information Privateness: The mannequin’s capacity to establish and phase objects raises questions on private privateness in pictures and movies.
- Integration Challenges: Incorporating SAM into present workflows and methods could require important adaptation and coaching.
Future Developments Meta AI continues to refine and develop SAM’s capabilities. Future developments could embrace:
- Improved real-time efficiency for video purposes
- Enhanced multimodal capabilities, incorporating audio and textual content understanding
- Extra refined zero-shot studying skills
- Integration with different AI fashions for extra complicated duties
Conclusion
SAM represents a major development in pc imaginative and prescient and AI know-how. Its capacity to phase something in pictures and movies with excessive accuracy and adaptability opens up quite a few prospects throughout numerous industries. As know-how evolves, we are able to count on more and more refined purposes that leverage SAM’s capabilities to resolve complicated visible understanding issues.
Whereas challenges stay, significantly concerning moral use and integration, SAM’s potential to remodel how we work together with and analyze visible information is plain. As researchers, builders, and industries proceed exploring its capabilities, SAM will doubtless play an important position in shaping the way forward for AI-powered visible understanding.
Regularly Requested Query
Ans. SAM is a basis mannequin for picture segmentation developed by Meta AI. It’s designed to phase any object in a picture primarily based on numerous varieties of prompts, reminiscent of factors, containers, or textual content descriptions.
Ans. Not like conventional strategies which might be typically task-specific, SAM is a flexible mannequin that may phase just about any object with out retraining. It makes use of a prompt-based interface and might generalize to unseen objects and eventualities.
Ans. SAM can work with various kinds of prompts:
A. Level prompts (clicking on an object)
B. Field prompts (drawing a bounding field round an object)
C. Textual content prompts (describing the article to be segmented)
Ans. SAM has a variety of potential purposes, together with:
A. Medical imaging for organ or anomaly segmentation
B. Autonomous car methods for object detection
C. Augmented actuality for correct object integration
D. Content material creation and enhancing in pictures and videography
E. Scientific analysis for analyzing complicated visible information



