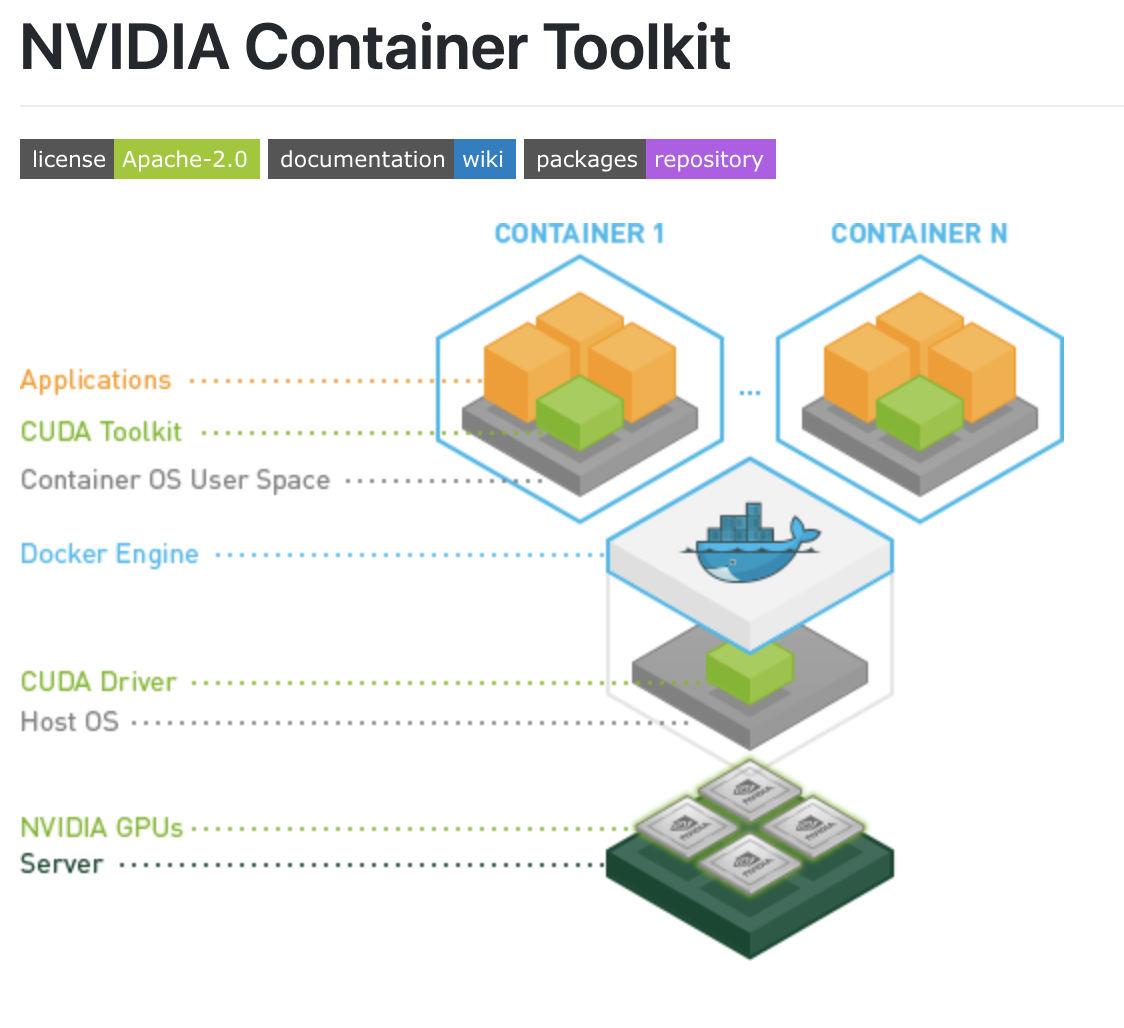
Configuring the GPU in your machine might be immensely troublesome. The configuration steps change based mostly in your machine’s working system and the form of NVIDIA GPU that your machine has. So as to add one other layer of issue, when Docker begins a container – it begins from nearly scratch.
Sure issues just like the CPU drivers are pre-configured for you, however the GPU is just not configured if you run a docker container. Fortunately, you’ve got discovered the answer defined right here. It’s referred to as the NVIDIA Container Toolkit.
On this submit, we stroll via the steps required to entry your machine’s GPU inside a Docker container. Roboflow makes use of this methodology to allow you to simply deploy to NVIDIA Jetson units.
Docker GPU Errors
While you try to run your container that wants the GPU in Docker, you would possibly obtain any of the errors listed beneath. These errors are indicative of a problem the place Docker and Docker compose is unable to connect with your GPU.
Listed here are just a few of the errors you might encounter:
docker: Error response from daemon: Container command 'nvidia-smi' not discovered or doesn't exist..
Error: Docker doesn’t discover Nvidia drivers
I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:150] kernel reported model is: 352.93
I tensorflow/core/common_runtime/gpu/gpu_init.cc:81] No GPU units obtainable on machine.tensorflow can not entry GPU in Docker
RuntimeError: cuda runtime error (100) : no CUDA-capable system is detected at /pytorch/aten/src/THC/THCGeneral.cpp:50pytorch can not entry GPU in Docker
The TensorFlow library wasn't compiled to make use of FMA directions, however these can be found in your machine and will pace up CPU computations.keras can not entry the GPU in Docker
Enabling Docker to Use Your GPU
You probably have encountered any errors that seem like the above ones listed above, the steps beneath will get you previous them. Let’s speak via what you must do to permit Docker to make use of your GPU step-by-step.
Set up NVIDIA GPU Drivers in your Base Machine
First, you could set up NVIDIA GPU drivers in your base machine earlier than you may make the most of your GPU in Docker.
As beforehand talked about, this may be troublesome given the plethora of distribution of working techniques, NVIDIA GPUs, and NVIDIA GPU drivers. The precise instructions you’ll run will range based mostly on these parameters.
In case you’re utilizing the NVIDIA TAO Toolkit, we now have a information on learn how to construct and deploy a customized mannequin.
The sources beneath could also be helpful in serving to your configure the GPU in your laptop:
Upon getting labored via these steps, run the the nvidia-smi command. If the command lists details about your GPU, that your GPU has been efficiently recognized and recognised by your laptop. You might even see an output that appears like this:
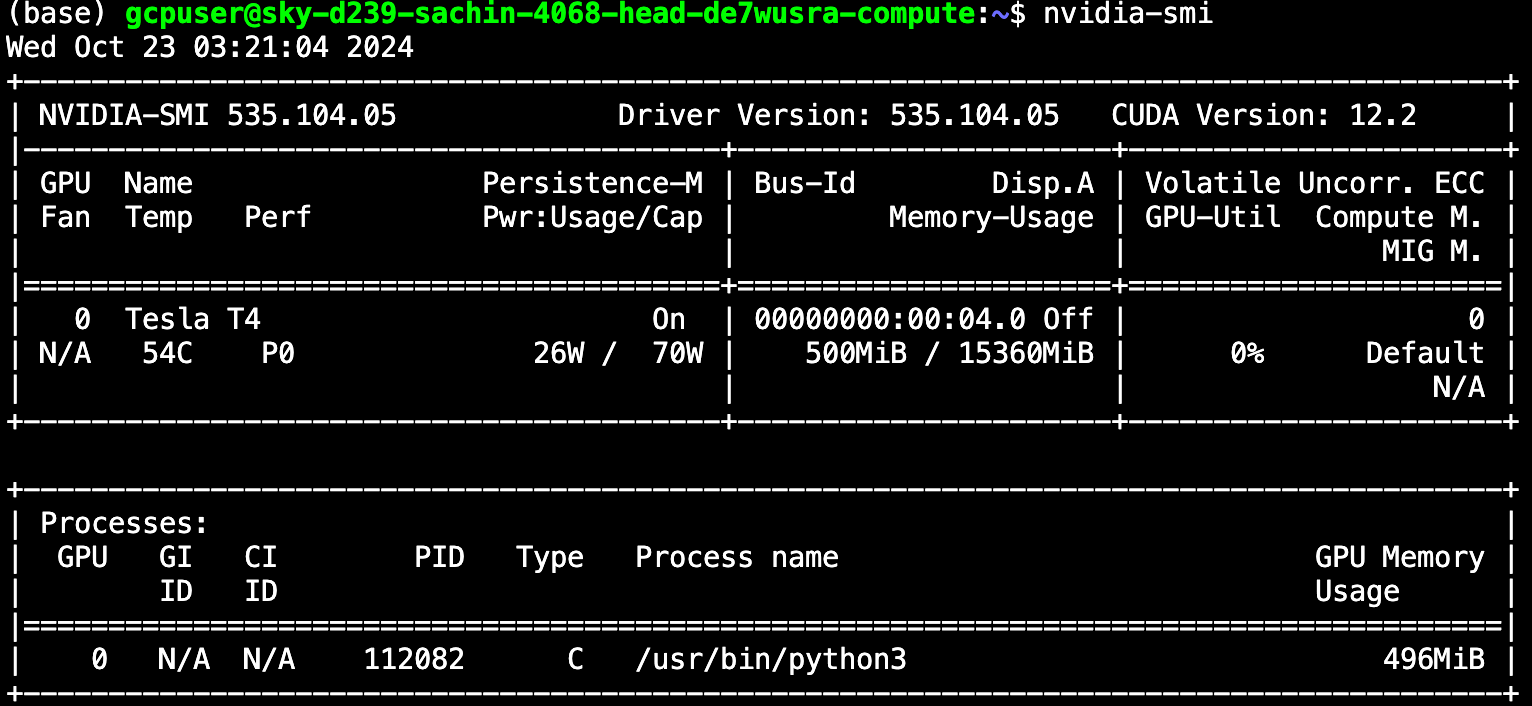
Now that we all know the NVIDIA GPU drivers are put in on the bottom machine, we will transfer one layer deeper to the Docker container. See Roboflow’s Docker repository for examples of how Docker containers are used to deploy laptop imaginative and prescient fashions.
Exposing GPU Drivers to Docker utilizing the NVIDIA Toolkit
The perfect method is to make use of the NVIDIA Container Toolkit. The NVIDIA Container Toolkit is a docker picture that gives assist to robotically acknowledge GPU drivers in your base machine and move those self same drivers to your Docker container when it runs.
If you’ll be able to run nvidia-smi in your base machine, additionally, you will be capable of run it in your Docker container (and your whole applications will be capable of reference the GPU). As a way to use the NVIDIA Container Toolkit, you pull the NVIDIA Container Toolkit picture on the high of your Dockerfile like so:
FROM nvidia/cuda:12.6.2-devel-ubuntu22.04
CMD nvidia-smiThe code you must expose GPU drivers to Docker
In that Dockerfile we now have imported the NVIDIA Container Toolkit picture for 10.2 drivers after which we now have specified a command to run once we run the container to test for the drivers. You would possibly need to replace the bottom picture model (on this case, 10.2) as new variations come out.
Now we construct the picture with the next command:
docker construct . -t nvidia-test
Now, we will run the container from the picture through the use of this command:
docker run --gpus all nvidia-testTake into account, we want the –gpus all flag or else the GPU won’t be uncovered to the operating container.
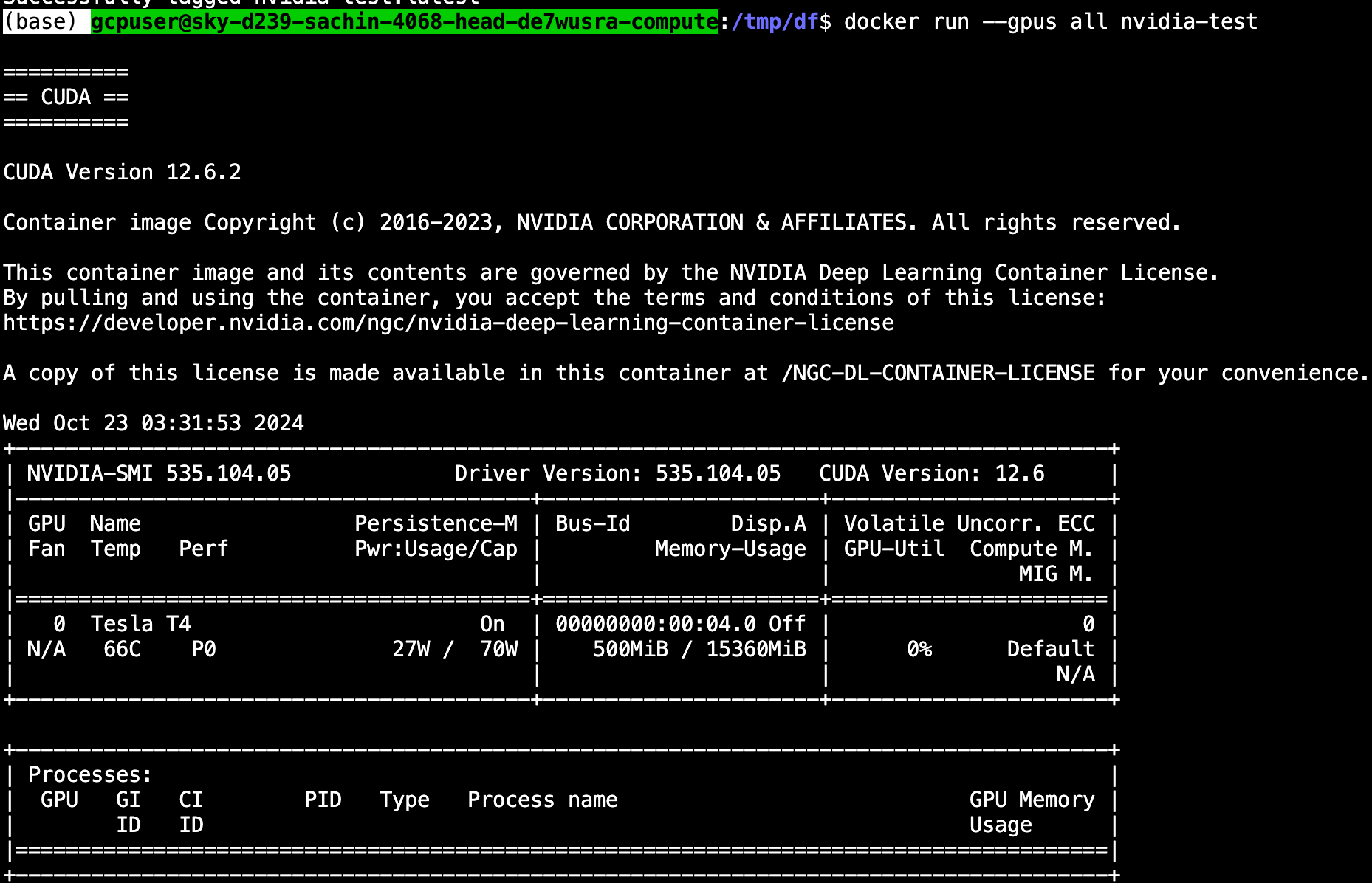
From this state, you may develop your app. In our instance case, we use the NVIDIA Container Toolkit to energy experimental deep studying frameworks. The format of a completely constructed Dockerfile would possibly look one thing like the next (the place /app/ incorporates all the python recordsdata):
FROM nvidia/cuda:12.6.2-devel-ubuntu22.04
CMD nvidia-smi #arrange atmosphere
RUN apt-get replace && apt-get set up --no-install-recommends --no-install-suggests -y curl
RUN apt-get set up unzip
RUN apt-get -y set up python3
RUN apt-get -y set up python3-pip COPY app/requirements_verbose.txt /app/requirements_verbose.txt RUN pip3 set up -r /app/requirements_verbose.txt #copies the applicaiton from native path to container path
COPY app/ /app/
WORKDIR /app ENV NUM_EPOCHS=10
ENV MODEL_TYPE='EfficientDet'
ENV DATASET_LINK='HIDDEN'
ENV TRAIN_TIME_SEC=100 CMD ["python3", "train_and_eval.py"]A full python utility utilizing the NVIDIA Container Toolkit
The above Docker container trains and evaluates a deep studying mannequin based mostly on specs utilizing the bottom machines GPU.
Exposing GPU Drivers to Docker by Brute Power
As a way to get Docker to acknowledge the GPU, we have to make it conscious of the GPU drivers. We do that within the picture creation course of. That is once we run a sequence of instructions to configure the atmosphere wherein our Docker container will run.
The “brute drive method” to make sure Docker can recognise your GPU drivers is to incorporate the identical instructions that you simply used to configure the GPU in your base machine. When docker builds the picture, these instructions will run and set up the GPU drivers in your picture and all needs to be properly.
There are downsides to the brute drive method. Each time you rebuild the docker picture, you’ll have to reinstall the picture. This may decelerate your improvement pace.
As well as, for those who resolve to elevate the Docker picture off of the present machine and onto a brand new one which has a special GPU, working system, or you desire to new drivers – you’ll have to re-code this step each time for every machine.
This sort of defeats the aim of construct a Docker picture. Additionally, you won’t bear in mind the instructions to put in the drivers in your native machine, and there you’re again at configuring the GPU once more within Docker.
The brute drive method will look one thing like this in your Dockerfile:
FROM ubuntu:22.04
MAINTAINER Regan <http://stackoverflow.com/questions/25185405/using-gpu-from-a-docker-container> RUN apt-get replace && apt-get set up -y build-essential
RUN apt-get --purge take away -y nvidia* ADD ./Downloads/nvidia_installers /tmp/nvidia > Get the set up recordsdata you used to put in CUDA and the NVIDIA drivers in your host
RUN /tmp/nvidia/NVIDIA-Linux-x86_64-331.62.run -s -N --no-kernel-module > Set up the driving force.
RUN rm -rf /tmp/selfgz7 > For some motive the driving force installer left temp recordsdata when used throughout a docker construct (i haven't got any reason) and the CUDA installer will fail if there nonetheless there so we delete them.
RUN /tmp/nvidia/cuda-linux64-rel-6.0.37-18176142.run -noprompt > CUDA driver installer.
RUN /tmp/nvidia/cuda-samples-linux-6.0.37-18176142.run -noprompt -cudaprefix=/usr/native/cuda-6.0 > CUDA samples remark if you don't need them.
RUN export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/native/cuda/lib64 > Add CUDA library into your PATH
RUN contact /and so forth/ld.so.conf.d/cuda.conf > Replace the ld.so.conf.d listing
RUN rm -rf /temp/* > Delete installer recordsdata.Code credit score to stack overflow
This method requires you to have your NVIDIA drivers in an area folder. You may exchange the “./Downloads” folder within the instance above with the listing the place you’ve got saved your GPU drivers.
What if I want a special base picture in my Dockerfile?
For instance you’ve got been counting on a special base picture in your Dockerfile. Then, you must think about using the NVIDIA Container Toolkit alongside the bottom picture that you simply presently have through the use of Docker multi-stage builds.
Now that you’ve you written your picture to move via the bottom machine’s GPU drivers, it is possible for you to to elevate the picture off the present machine and deploy it to containers operating on any occasion that you simply want.
The Energy of Metrics: Understanding GPU Utilization in your operating Docker Container
Monitoring your GPU’s efficiency metrics is essential for optimizing your functions and maximizing the worth you get out of your {hardware}. Metrics like GPU utilization, reminiscence utilization, and thermal traits present invaluable insights into how effectively your containerized workloads are using the GPU sources. These insights will help you establish bottlenecks, fine-tune utility configurations, and in the end cut back prices.
Introducing DCGM: A Suite for GPU Monitoring
NVIDIA’s Information Middle GPU Supervisor (DCGM) is a robust suite of instruments particularly designed for managing and monitoring NVIDIA datacenter GPUs in clustered environments. It presents complete options like:
- Energetic well being monitoring to proactively establish potential points earlier than they influence your workloads.
- Detailed diagnostics to supply deep evaluation of GPU efficiency.
- System alerts to inform you of any crucial occasions associated to your GPUs.
Working a Pattern GPU Inference Container
Now, let’s put idea into follow. We’ll use Roboflow’s GPU inference server docker picture for instance GPU workload and monitor its GPU utilization utilizing DCGM, Prometheus and Grafana. This is learn how to pull and run the Roboflow GPU inference container:
Bash
docker pull roboflow/roboflow-inference-server-gpu
docker run -it --net=host --gpus all roboflow/roboflow-inference-server-gpu:newest
Unified Monitoring with Prometheus, Grafana, and DCGM
To simplify GPU metrics assortment and visualization, we’ll leverage a superb open-source challenge that integrates Prometheus, Grafana, and DCGM from right here. This challenge offers a pre-configured Docker Compose file that units up all the mandatory parts:
- DCGM Exporter: This container scrapes uncooked metrics out of your NVIDIA GPUs.
- Prometheus: This container serves because the central repository for gathering and storing metrics.
- Grafana: This container offers a user-friendly interface for visualizing and analyzing your collected metrics.
The offered Docker Compose file defines the configurations for every part, together with useful resource allocation, community settings, and atmosphere variables. By deploying this Docker Compose stack, you may have an entire monitoring system up and operating very quickly.
To get your monitoring stack setup:
git@github.com:hongshibao/gpu-monitoring-docker-compose.git
docker compose upThis could carry up the DCGM exporter, Prometheus and Grafana pods.
Clarification of the Docker Compose File:
The repository-provided Docker Compose file compose.yaml defines numerous companies and configurations:
- Providers:
dcgm_exporter: This service runs the DCGM exporter container to gather GPU metrics. It makes use of thenvidiasystem driver and requests entry to all obtainable GPUs with GPU capabilities.prometheus: This service runs the Prometheus container to retailer and serve the collected metrics. You may customise storage parameters like retention time.grafana: This service runs the Grafana container for visualizing the metrics. You may configure consumer credentials for entry management.
- Volumes:
- Persistent volumes are outlined for Prometheus knowledge and Grafana knowledge to make sure knowledge persistence even after container restarts.
- Networks:
- A customized community named
gpu_metricsis created to facilitate communication between the companies.
- A customized community named
Opening http://localhost:3000 will present the Grafana interface (comply with the directions within the repository README about learn how to log into Grafana). You must see a dashboard just like the one beneath:
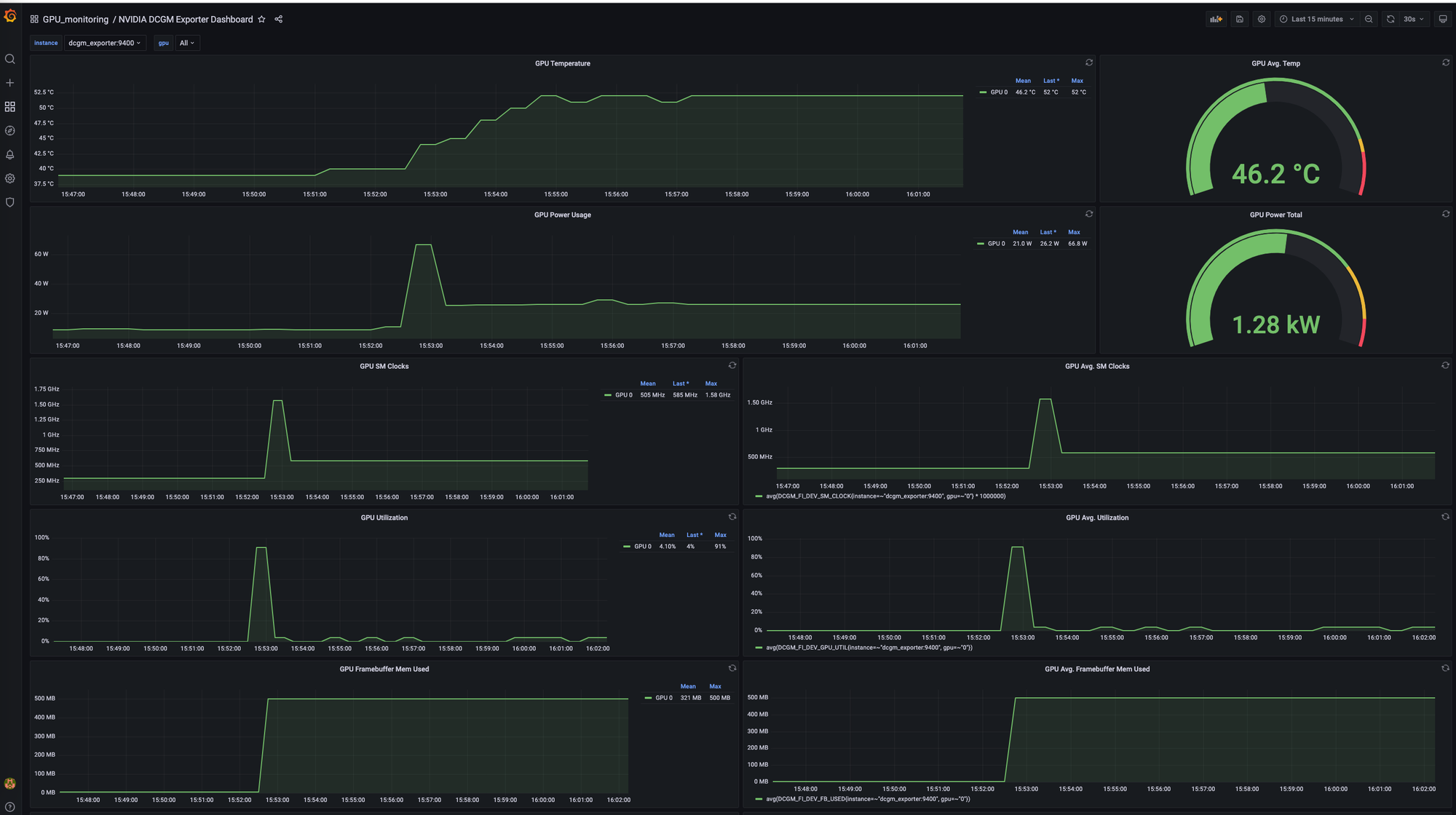
💡
docker run -d --gpus all --rm -p 9400:9400 nvcr.io/nvidia/k8s/dcgm-exporter:3.3.8-3.6.0-ubuntu22.04
Then you will note this error:Failed to look at metrics: Error watching fields: Host engine is operating as non-root"
As an alternative you must give the docker container admin functionality and run the command like so docker run --gpus all --cap-add SYS_ADMIN -p 9400:9400 nvcr.io/nvidia/k8s/dcgm-exporter:3.3.8-3.6.0-ubuntu22.04
Conclusion: Optimizing Efficiency and Value with GPU-Conscious Docker
By following these steps and leveraging the facility of metrics monitoring, you may guarantee your Docker containers successfully make the most of your NVIDIA GPUs. Effective-tuning your functions based mostly on the insights gleaned from GPU metrics will result in improved efficiency and value financial savings. Keep in mind, optimizing useful resource utilization is essential to maximizing the return in your funding in highly effective GPU {hardware}.
Various to Prepare and Deploy Fashions
Roboflow Prepare handles the coaching and deployment of your laptop imaginative and prescient fashions for you.
Subsequent Steps
Now you know the way to reveal GPU Drivers to your operating Docker container utilizing the NVIDIA Container Toolkit. You must be capable of use your GPU drivers and run Docker compose with out operating into any points.
Wish to use your new Docker capabilities to do one thing superior? You would possibly take pleasure in our different posts on coaching a cutting-edge object detection mannequin, coaching a cutting-edge picture classification mannequin, or just by wanting into some free laptop imaginative and prescient knowledge.



