Introduction
DINOv2, created by Meta Analysis, is a brand new methodology of coaching laptop imaginative and prescient fashions that makes use of self-supervised studying. This strategy of coaching doesn’t require labels.
Labeling photographs is without doubt one of the most time consuming elements of coaching a pc imaginative and prescient mannequin: every object you need to establish must be labeled exactly. This isn’t solely a limitation for topic matter-specific fashions, but in addition massive normal fashions that attempt for prime efficiency throughout a wider vary of lessons.
For example, CLIP, OpenAI’s mannequin to “predict essentially the most related textual content snippet given a picture” is immensely helpful. However, the mannequin was educated on 400 million pairs of textual content to picture to coach; a lot of annotations. This comes with limitations, each when it comes to time to collect and label knowledge and the preciseness of the labels in comparison with the wealthy contents of photographs. DINOv2 is a breakthrough development and price researching the way it can enhance your laptop imaginative and prescient pipeline.
On this information, we’re going to speak via:
- What’s DINOv2?
- How does DINOv2 work?
- What are you able to do with DINOv2?
- How will you get began with DINOv2?
With out additional ado, let’s get began!
What’s DINOv2?
DINOv2 is a self-supervised methodology for coaching laptop imaginative and prescient fashions developed by Meta Analysis and launched in April 2023. As a result of DINOv2 is self-supervised, the enter knowledge doesn’t require labels, which suggests fashions primarily based on this structure can study richer details about the contents of a picture.
Meta Analysis has open-sourced the code behind DINOv2 and fashions exhibiting the structure in use for varied process varieties, together with:
- Depth estimation;
- Semantic segmentation, and;
- Occasion retrieval.
The DINOv2 coaching strategy is documented within the accompanying venture paper launched by Meta Analysis, DINOv2: Studying Sturdy Visible Options with out Supervision.
How Does DINOv2 Work?
DINOv2 leverages a method known as self-supervised studying, the place a mannequin is educated utilizing photographs with out labels. There are two main advantages of a mannequin not requiring labels.
First, a mannequin will be educated with out investing the numerous time and assets to label knowledge. Second, the mannequin can derive extra significant and wealthy representations of the picture enter knowledge for the reason that mannequin is educated straight on the picture.
By coaching a mannequin straight on the photographs, the mannequin can study all of the context within the picture. Contemplate the next picture of photo voltaic panels:

We might assign this picture a label akin to “an aerial {photograph} of photo voltaic panels” however this misses out on loads of the data within the picture; documenting deeper data for a big dataset is tough. However, DINOv2 exhibits that labels usually are not needed for a lot of duties akin to classification: as an alternative, you may prepare on the unlabelled photographs straight.
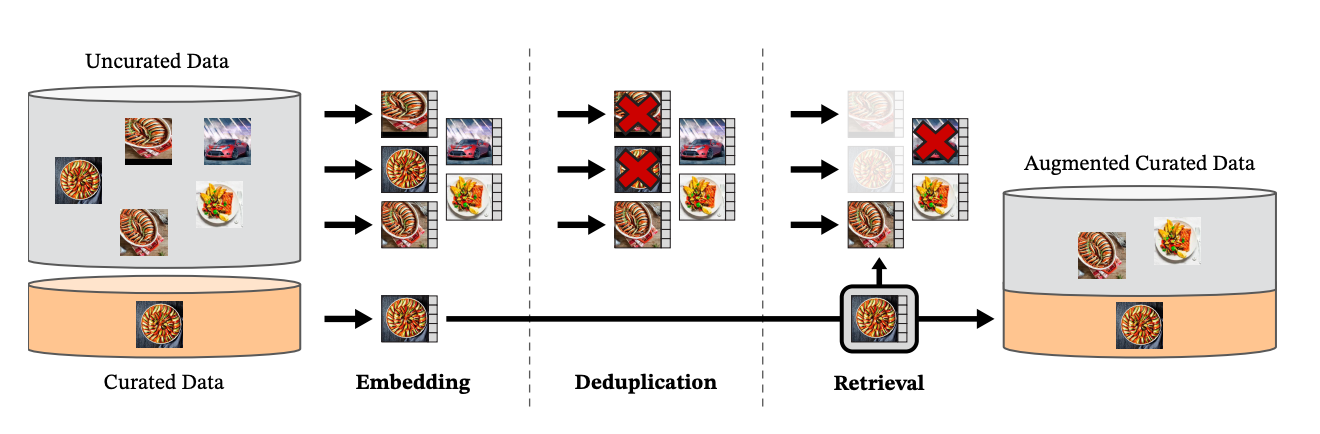
To arrange knowledge for the mannequin, Meta researchers used knowledge from curated and uncurated knowledge sources. These photographs had been then embedded. The uncurated photographs had been deduplicated, then the deduplicated photographs had been mixed with the curated photographs to create the preliminary dataset used for coaching the mannequin.
Previous to DINOv2, a typical methodology of constructing normal laptop imaginative and prescient fashions that embed semantics of a whole picture has been utilizing a pre-training step with image-text pairs. For instance, OpenAI’s CLIP mannequin, which may work on duties from picture retrieval to classification, was educated on 400 million image-text pairs. CLIP discovered semantic details about the contents of photographs primarily based on the textual content pairs. DINO, in distinction, was educated on 140 million photographs with out textual content labels.
DINOv2 circumvents the requirement to have these labels, enabling researchers and practitioners to construct massive fashions with out requiring a labeling section.
What Can You Do With DINOv2?
On account of the elevated data DINOv2 learns by coaching straight on photographs, the mannequin has been discovered to carry out successfully on many picture duties, together with depth estimation, a process for which separate fashions are often employed.
Meta AI researchers wrote customized mannequin heads to perform depth estimation, picture classification (utilizing linear classification and KNN), picture segmentation, and occasion retrieval. There aren’t any out-of-the-box heads out there for depth estimation or segmentation, which suggests one would want to put in writing a customized head to make use of them.
Let’s discuss via a number of of the use instances of the DINOv2 mannequin.
Depth Estimation
DINOv2 can be utilized for predicting the depth of every pixel in a picture, attaining state-of-the-art efficiency when evaluated on the NYU Depth and SUN RGB-D depth estimation benchmark datasets. Meta Analysis created a depth estimation mannequin with a DPT decoder to be used of their repository, though this isn’t open supply. Thus, it’s needed to put in writing the code that makes use of the mannequin spine to assemble a depth estimation mannequin.

The depth estimation capabilities of DINOv2 are helpful for fixing many issues. For example, contemplate a situation the place you need to perceive how shut a forklift is to a parking dock. You would place a digicam on the dock and use DINOv2 to estimate how shut the forklift is to the dock. This might then be added to an alarm to inform somebody that they’re about to get too near the top of the parking dock and hit a wall.
Picture Segmentation
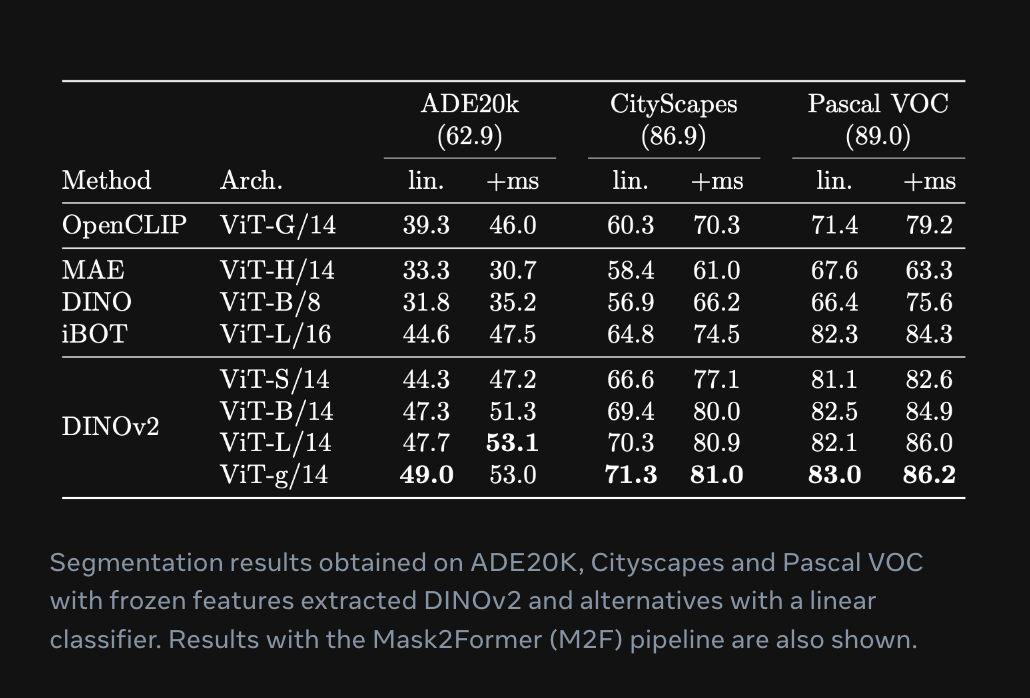
DINOv2 is able to segmenting objects in a picture. Meta Analysis evaluated DINOv2 towards the ADE20Ok and Cityscapes benchmarks and achieved “aggressive outcomes” with none fine-tuning when in comparison with different related fashions, based on the occasion segmentation instance within the mannequin playground. There isn’t a official picture segmentation head that accompanies the repository.
Such code would should be written manually in an effort to use DINOv2 for segmentation duties.
Classification
DINOv2 is appropriate to be used in picture classification duties. In response to Meta Analysis, the efficiency of DINOv2 is “aggressive or higher than the efficiency of text-image fashions akin to CLIP and OpenCLIP on a big selection of duties”.
For example, contemplate a situation the place you need to classify photographs of autos on a building website. You would use DINOv2 to categorise autos into specified lessons utilizing a nearest neighbor strategy or linear classification.
With that mentioned, a customized classifier head is required to work with the DINOv2 embeddings.
Occasion Retrieval
DINOv2 can be utilized as a part of a picture data retrieval system that accepts photographs and returns associated photographs. To take action, one would embed the entire photographs in a dataset. For every search, the offered picture can be embedded after which photographs with a excessive cosine similarity to the embedded question picture can be returned.
Within the Meta Analysis playground accompanying DINOv2, there’s a system that retrieves photographs associated to landmarks. That is used to search out artwork items which can be just like a picture.
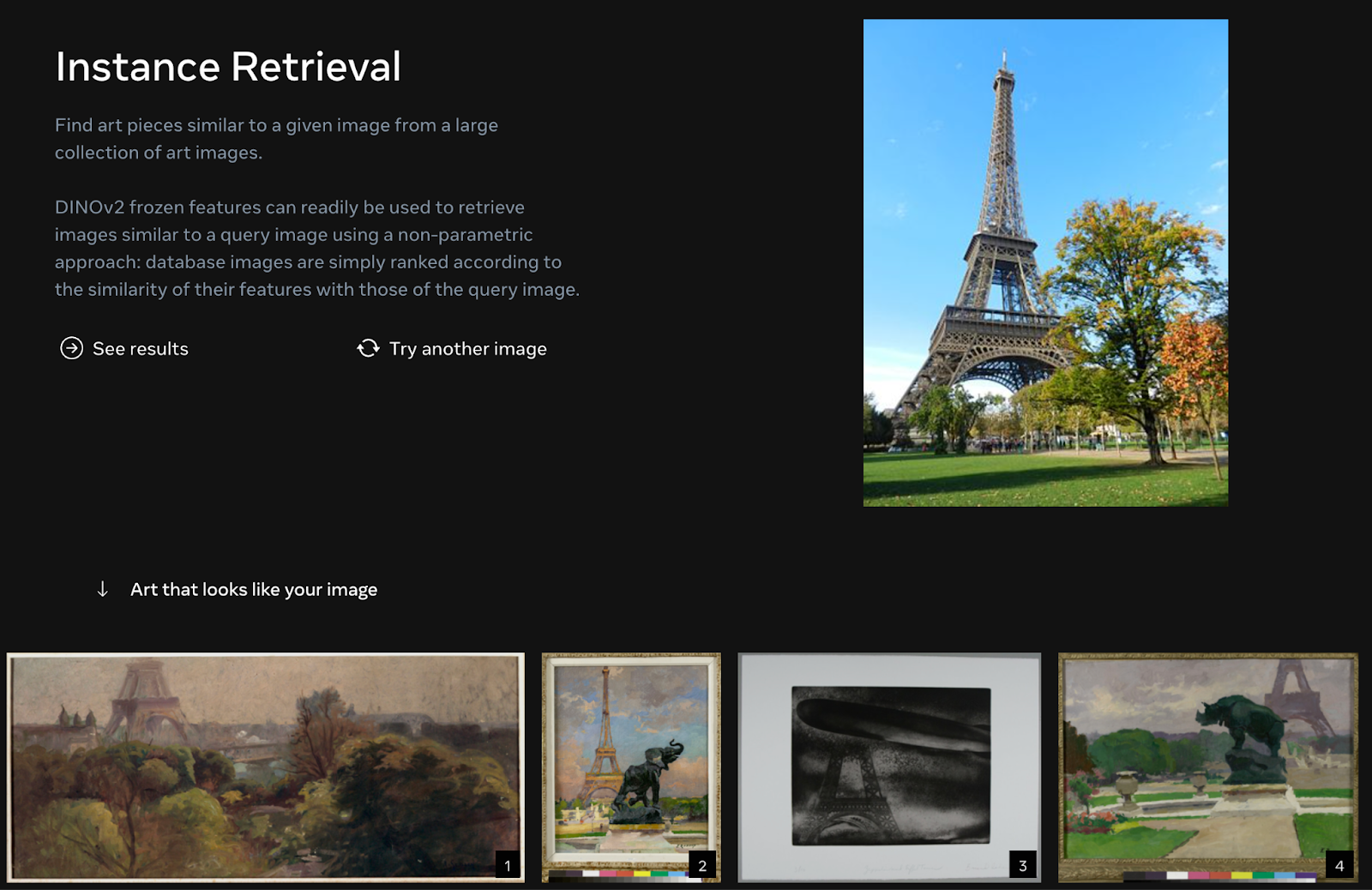
You would construct an image-to-image occasion retrieval system utilizing the out-of-the-box code for loading the mannequin and encoding photographs utilizing the mannequin. Then, you could possibly use a vector retailer like faiss to retailer embeddings for a repository of photographs and a distance measure akin to cosine measure to search out photographs associated to a different picture. See our information on utilizing CLIP to construct a semantic picture search engine for an instance use case of one of these performance.
The way to Get Began
The code behind the DINOv2 paper is on the market on GitHub. 4 checkpoints accompany the code, ranging in measurement from 84 MB for the smallest mannequin to 4.2 GB for the biggest mannequin. There are additionally coaching scripts that you need to use to coach the mannequin on completely different datasets.
The DINOv2 repository is licensed beneath a Artistic Commons Attribution-NonCommercial 4.zero Worldwide license.
Conclusion
DINOv2 is a brand new coaching methodology for laptop imaginative and prescient fashions, leveraging self-supervised studying to permit for a mannequin coaching course of that doesn’t require labels. DINOv2 learns straight from photographs with out textual content pairs, permitting the mannequin to study extra details about the enter picture that can be utilized for varied duties.
The DINOv2 methodology was utilized by Meta Analysis to coach a mannequin able to depth estimation, classification, occasion retrieval, and semantic segmentation. Pre-trained checkpoints can be found to be used with the mannequin so you may construct your personal functions leveraging DINOv2.



