Google Bard Accepts Photos in Prompts
Google’s massive language mannequin (LLM) chatbot Bard just lately unveiled a characteristic to just accept picture prompts, making it multimodal. It strikes comparisons with the same characteristic just lately launched from Microsoft’s Bing chat, powered by OpenAI’s GPT-4.
In our assessment of Bing’s multimodality, we concluded that though it had good picture context and content material consciousness, in addition to captioning and categorization, Bing lacks in its capability to carry out task-specific object localization and detection duties.
On this article, we are going to study how Bard’s picture enter performs, the way it stacks up towards GPT-4, and the way we consider it really works.
Testing Bard’s Picture Capabilities
Utilizing the identical assessments as those carried out on Bing Chat, we requested Bard questions utilizing three completely different datasets from Roboflow Universe to evaluate the efficiency of Bard:
> To see the small print of how we carried out our experiments, check out our assessment of Bing/GPT-4’s multimodal capabilities
Counting Individuals with Google Bard
On this activity, we used the Laborious Hat Employees dataset to ask Bard to depend the variety of folks current in a picture to find out the way it performs in counting duties. Sadly, Bard was unable to depend any picture of individuals
This highlights a notable distinction between Bard’s capabilities and people of Bing in the way it handles people. Each take in depth efforts to make sure human faces aren’t used as enter into the mannequin. Whereas Bing selectively blurs faces, Bard rejects the enter of photographs containing human faces fully.
Google’s care to keep away from responding to human photographs additionally prevents Bard’s usability to some extent. Not solely does Bard refuse any picture with a human as the primary topic determine, however it additionally makes makes an attempt to refuse any picture with a human current, considerably narrowing the variety of photographs that can be utilized with it.
Counting Objects with Bard
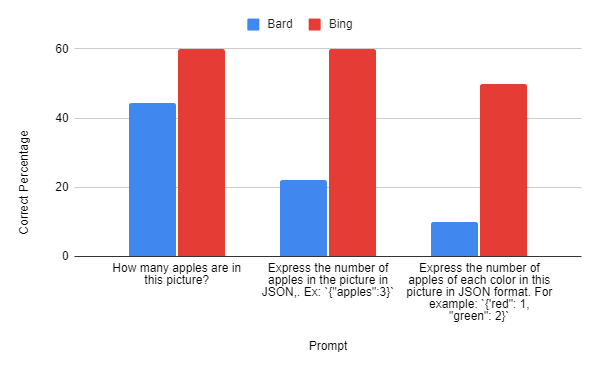
For this activity, we used the apples dataset to ask Bard to depend the variety of apples that exist in a picture. We lengthen this to a few completely different prompts of accelerating problem to evaluate Bard’s quantitative and qualitative deduction expertise, in addition to its capability to format information in a structured means.
Bard was in a position to full this activity however with unimpressive outcomes:

Bard had plenty of problem telling the variety of objects in a picture, which solely bought worse when requested to construction the info or kind it by qualitative traits.
Can Bard Perceive Photos from ImageNet?
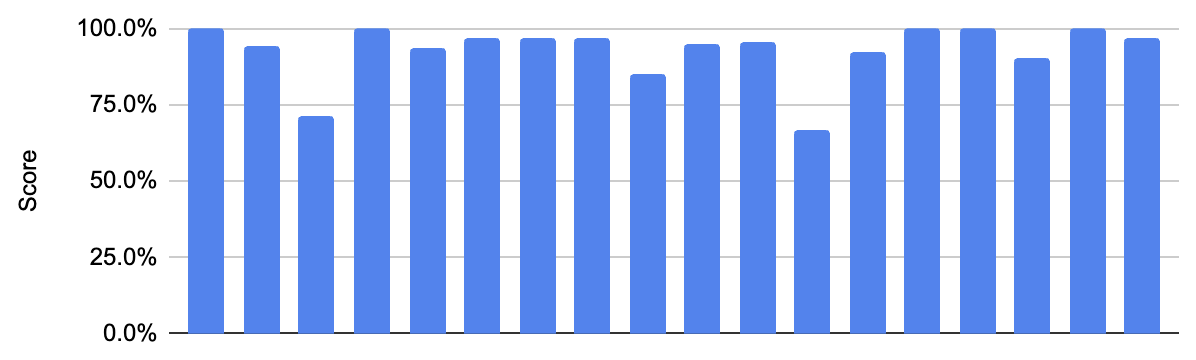
For this activity, we current Bard with a sequence of photographs from ImageNet, a picture classification benchmark dataset, and ask it to caption it with a label.
Labels getting a precise match will obtain a 100% and any assigned label that isn’t a precise match will obtain a semantic similarity rating (similarity primarily based on which means) from 0-100%.
On this regard, Bard carried out extremely nicely, getting a median of 92.8%, with 5 precise matches and low variability, demonstrating its capability to persistently and precisely detect and talk the content material of a picture. We didn’t take a look at Bard on the total dataset, however the efficiency right here is kind of spectacular in comparison with state-of-the-art mannequin outcomes.
How Bard Compares With Bing/GPT-4
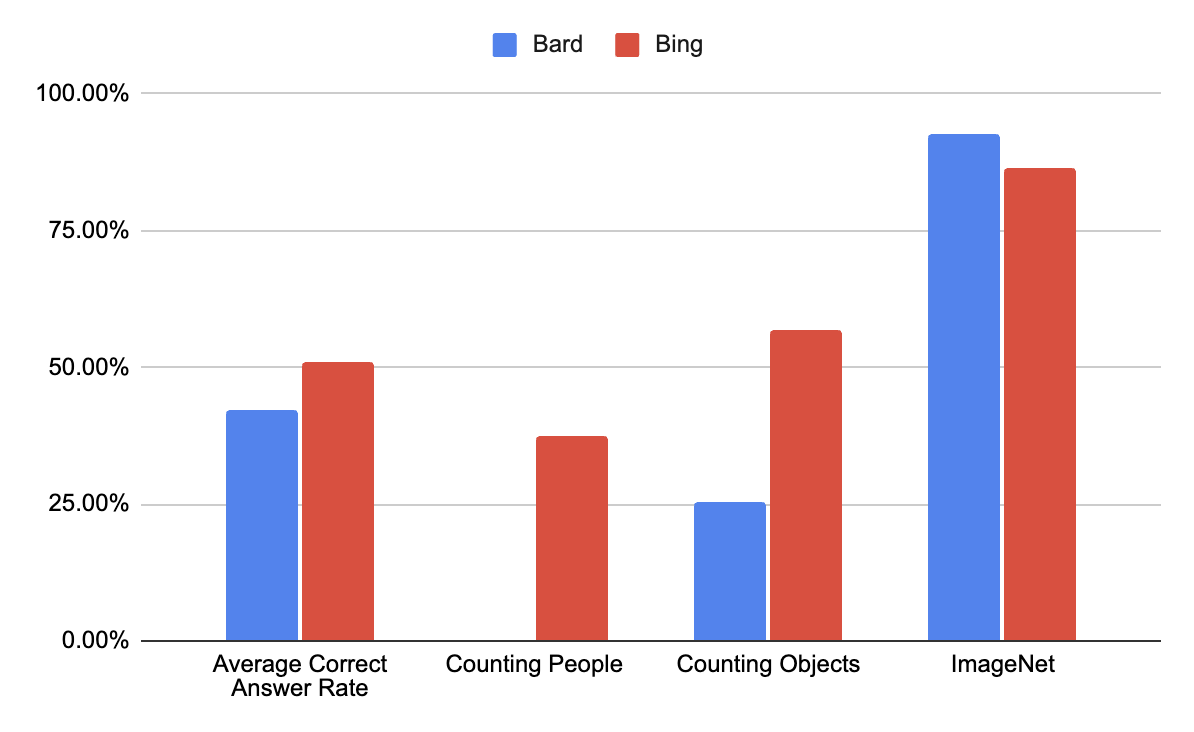
After beforehand performing the identical assessments on the GPT-Four powered Bing chat, we compiled and in contrast the efficiency of each LLMs.
One notable comparability is between Bing and Bard on the thing counting activity. Though Bard was in a position to full a few of the given duties, it carried out persistently poorly each usually and relative to Bing. In contrast to Bing, Bard struggled even additional when tasked with structuring the info or categorizing counts primarily based on qualitative traits.
Then again, on the ImageNet classification/captioning activity, Bard carried out barely higher than Bing, performing 6.29% higher than Bing. Regardless of that, Bard did carry out usually worse than Bing, even when excluding the failed folks counting activity.
Ideas on How Bard Would possibly Work
After conducting our assessments, we examined the way it carried out and inferred the way it would possibly work.
As Google acknowledged in its launch notes, Bard’s new picture enter options aren’t precisely a singular multimodal mannequin. Reasonably, it’s primarily based on Google Lens, which makes use of a mix of a number of Google options and capabilities. It integrates a lot of Google’s merchandise like Search, Translate, and Buying.
Though unconfirmed, we consider that it makes use of Google Cloud’s Imaginative and prescient API that acts equally to a lot of Google Lens’ capabilities, together with its spectacular OCR accuracy and skill to establish picture content material and context, with the ability to extract textual content and assign labels primarily based on picture content material.
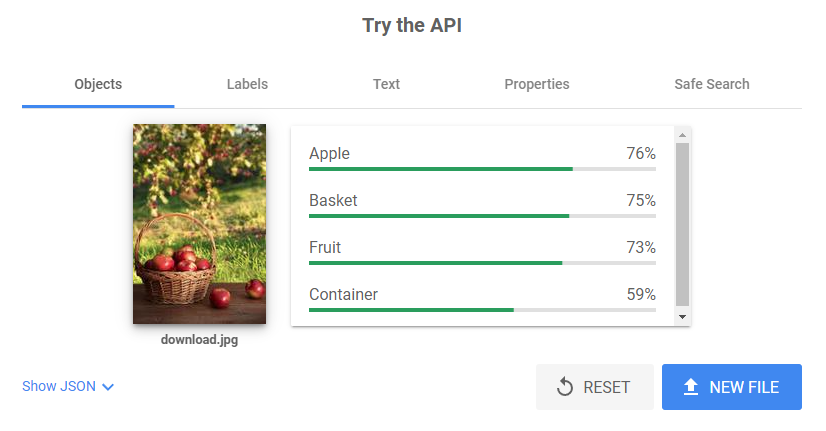
As seen within the instance picture, this might considerably clarify the inaccuracies that Bard made that have been current in our testing, recognizing one apple, one fruit, one container, and one basket.
Conclusion
After experimenting with and analyzing Bard, pc imaginative and prescient duties aren’t a powerful use case but, and as we concluded with Bing’s chat options, the primary use case for Bard is probably going for direct shopper use quite than pc imaginative and prescient duties. The picture context data, supplemented by the overall data of the LLM and Google’s different capabilities, will doubtless make it a really great tool for generalized search and lookup of knowledge.
Past that, any use for Bard in an industrial or developer context would doubtless be in zero-shot image-to-text, common picture classification, and categorization since Bard, just like GPT-4, was seen to carry out extremely nicely on picture captioning and classification duties with no coaching.
Fashions similar to Bard have plenty of highly effective, generalized data. However, operating inference on it may be costly because of the computation that Google has to do to return outcomes The most effective use case for builders and firms is likely to be to make use of the knowledge and energy of those massive multimodal fashions to coach smaller, leaner fashions as you are able to do with Autodistill.



