AMD has launched its first sequence of totally open-source 1-billion-parameter giant language fashions (LLMs), referred to as AMD OLMo that’s geared toward a wide range of functions and pre-trained on the corporate’s Intuition MI250 GPUs. The LLMs are mentioned to supply sturdy reasoning, instruction-following, and chat capabilities.
AMD’s open supply LLMs are supposed to enhance the corporate’s place within the AI trade and allow its shoppers (and everybody else) to deploy these open-source fashions with AMD’s {hardware}. By open-sourcing the information, weights, coaching recipes, and code, AMD goals to empower builders to not solely replicate the fashions but additionally construct upon them for additional innovation. Past use in datacenters, AMD has enabled native deployment of OLMo fashions on AMD Ryzen AI PCs outfitted with neural processing models (NPUs), enabling builders to leverage AI fashions on private gadgets.
Multi-stage pre-training
The AMD OLMo fashions had been educated on an enormous dataset of 1.Three trillion tokens on 16 nodes, every with 4 AMD Intuition MI250 GPUs (64 processors in whole). AMD’s OLMo mannequin lineup was educated in three steps.
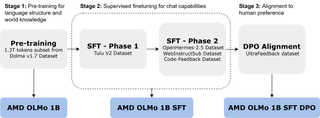
- The preliminary AMD OLMo 1B pre-trained on a subset of Dolma v1.7 is a decoder-only transformer centered on next-token prediction to seize language patterns and common information.
- The second model is AMD OLMo 1B supervised fine-tuned (SFT) was educated on on Tulu V2 dataset (1st section) after which OpenHermes-2.5, WebInstructSub, and Code-Suggestions datasets (2nd section) to refine its instruction-following and improved its efficiency on duties involving science, coding, and arithmetic.
- After fine-tuning, the AMD OLMo 1B SFT mannequin was aligned to human preferences utilizing Direct Desire Optimization (DPO) with the UltraFeedback dataset, resulting in the ultimate AMD OLMo 1B SFT DPO model to prioritize outputs that align with typical human suggestions.
Efficiency outcomes
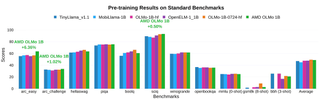
In AMD’s personal testing, AMD OLMo fashions confirmed spectacular efficiency in opposition to equally sized open-source fashions, akin to TinyLlama-1.1B, MobiLlama-1B, and OpenELM-1_1B in normal benchmarks for common reasoning capabilities and multi-task understanding.

The 2-phase SFT mannequin noticed vital accuracy enhancements, with MMLU scores growing by 5.09%, and GSM8k by 15.32%, which exhibits affect of AMD’s coaching strategy. The ultimate AMD OLMo 1B SFT DPO mannequin outperformed different open-source chat fashions by at the least 2.60% on common throughout benchmarks.

Relating to instruction-tuning outcomes of AMD OLMo fashions on chat benchmarks, particularly evaluating the AMD OLMo 1B SFT and AMD OLMo 1B SFT DPO fashions with different instruction-tuned fashions, AMD’s fashions outperformed the following finest rival in AlpacaEval 2 Win Charge by +3.41% and AlpacaEval 2 LC Win Charge by +2.29%. Moreover, within the MT-Bench check, which measures multi-turn chat capabilities, the SFT DPO mannequin achieved a +0.97% efficiency achieve over its closest competitor.

Moreover, AMD examined accountable AI benchmarks, akin to ToxiGen (which measures poisonous language, the place a decrease rating is best), crows_pairs (evaluating bias), and TruthfulQA-mc2 (assessing truthfulness in responses). It was discovered that the AMD OLMo fashions had been on par with related fashions in dealing with moral and accountable AI duties.



