Fb launched the Section Something mannequin showcasing spectacular zero-shot inference capabilities and comes with the promise of changing into a brand new foundational mannequin for pc imaginative and prescient purposes.
On this weblog put up, we are going to dive into the analysis of how the Section Something mannequin was educated and speculate on the impression it will have.
Background on Basis Fashions
Basis fashions have been making main strides in pure language processing beginning with the discharge of BERT in 2018 and up till the current launch of GPT-4.
Pc imaginative and prescient has struggled to discover a activity that gives semantically wealthy unsupervised pre-training, akin to subsequent token masking in textual content. Masked pixels haven’t packed the identical punch. The best pre-training routines in pc imaginative and prescient have been multi-model, like CLIP, the place textual content and pictures are utilized in a pre-training routine.
The Section Something analysis crew got down to create a activity, mannequin, and dataset that will kind a basis mannequin for pc imaginative and prescient.
Let’s dive in to how they did it.
Section Something Job
The Section Something authors arrange a coaching activity for his or her mannequin that includes predicting a set of “legitimate masks” for a given immediate to the mannequin. The immediate might be within the type of factors (presumably from a dwell annotator) and goal masks or a phrase utilizing semantic options from CLIP.

Having a prompt-able prediction like because of this coaching can very simply modulate the prompts together with the bottom fact to indicate the mannequin many examples alongside the way in which. Different work in interactive segmentation has used comparable strategies up to now.
The opposite giant profit of getting this activity construction is that the mannequin works nicely on zero-shot switch at inference time when the mannequin is getting used to label masks in a picture.
Section Something Mannequin
The Section Something mannequin is damaged down into two sections. The primary is a featurization transformer block that takes and picture and compresses it to a 256x64x64 function matrix. These options are then handed right into a decoder head that additionally accepts the mannequin’s prompts, whether or not that be a tough masks, labeled factors, or textual content immediate (observe textual content prompting shouldn’t be launched with the remainder of the mannequin).
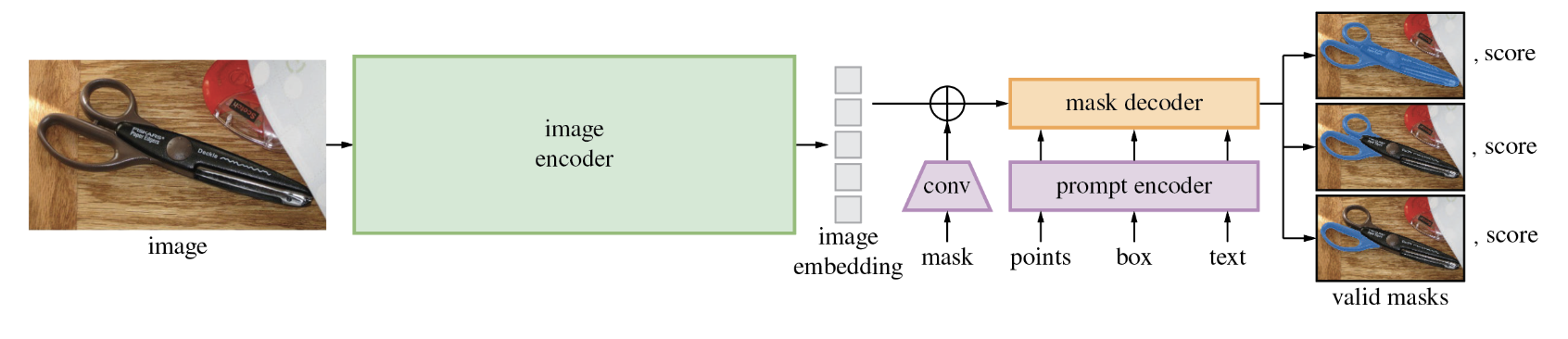
The Section mannequin structure is revolutionary as a result of it places the heavy lifting of picture featurization to a transformer mannequin after which trains a lighter mannequin on high. For deploying SAM to manufacturing, this makes for a very nice person expertise the place the featurization could be performed by way of inference on a backend GPU and the smaller mannequin could be run throughout the net browser.
Section Something Dataset
Section Something releases an open supply dataset of 11MM pictures and over 1 billion masks, SA-1B Dataset, the biggest masks corpus to this point. The authors of the Section Something dataset product their dataset by means of three levels:
1) Assisted Handbook – annotators annotate alongside SAM to select all masks in a picture.
2) Semi-Automated – annotators are requested to solely annotate masks that SAM is not sure of.
3) Full-Auto – SAM is allowed to totally predict masks given it is skill to type out ambiguous masks by way of a full sweep.
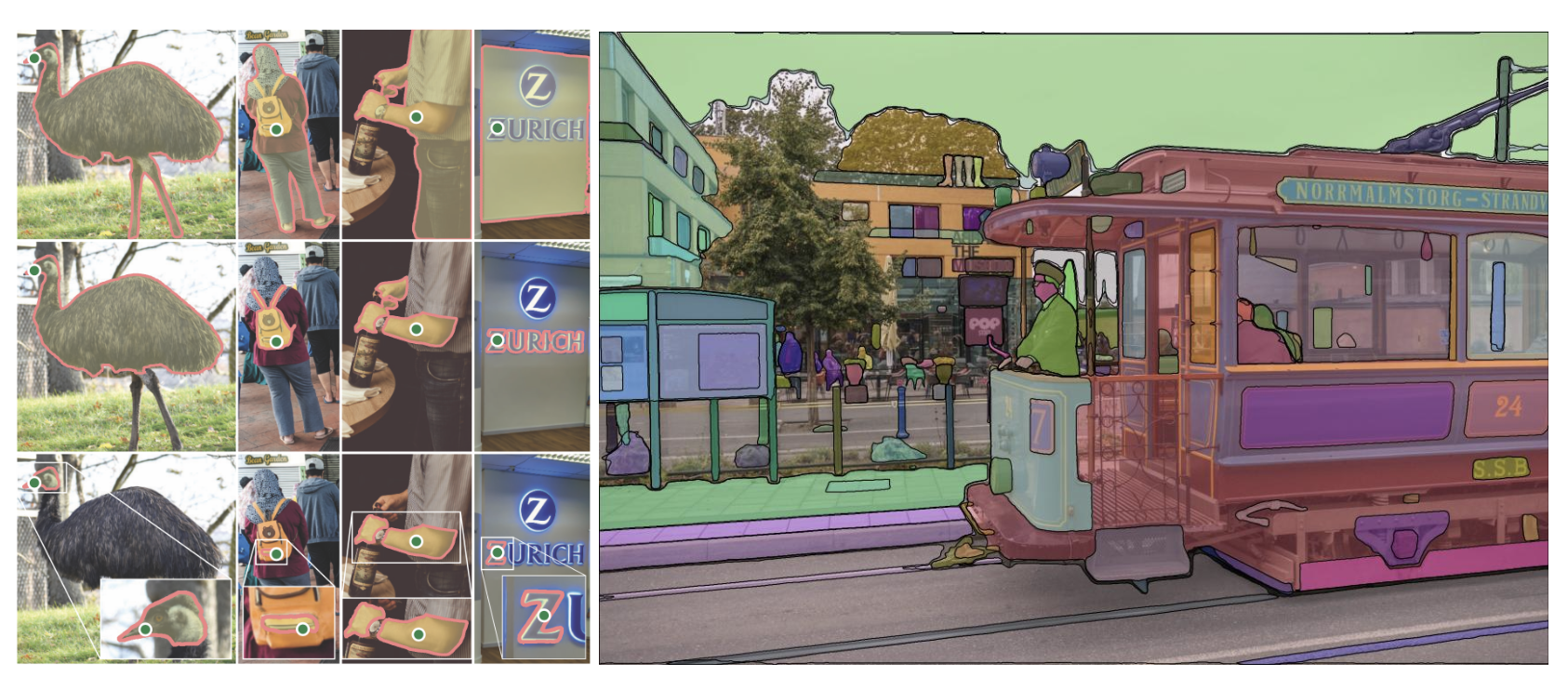
Section Something Impression Predictions and Conclusion
Section Something will definitely revolutionize the way in which that individuals label pictures for segmentation on the internet (we will probably be providing this functionality throughout the Roboflow Annotate platform quickly!).
We predict that there will probably be quite a few purposes which are constructed off of the SAM options as they’ve been demonstrated to be extraordinarily highly effective as an engine for zero-shot capabilities. Maybe they may even be setting a SOTA on the COCO dataset for object detection with some supervision.
Much more impactful than the mannequin itself and its options is the strategy that the Section Something researchers have been in a position to show out. That’s, you may prepare an especially giant transformer to featurize pictures nicely into a powerful semantic area that can be utilized for downstream duties. That is why many are calling Section Something a GPT-esque second for pc imaginative and prescient.
We are going to see the way it all performs out!
Till then, joyful segmenting!



