Generative Adversarial Networks (GANs) have advanced since their inception in 2015 once they have been launched by Ian Goodfellow. GANs include two fashions: a generator and a discriminator. The generator creates new synthetic knowledge factors that resemble the coaching knowledge, whereas the discriminator distinguishes between actual knowledge factors from the coaching knowledge and synthetic knowledge from the generator. The 2 fashions are educated in an adversarial method. Originally of coaching, the discriminator has virtually 100% accuracy as a result of it’s evaluating actual construction pictures with noisy pictures from the generator. Nevertheless, because the generator will get higher at producing sharper pictures, the accuracy of the discriminator decreases. The coaching is alleged to be full when the discriminator can not enhance its classification accuracy (also referred to as an adversarial loss). At this level, the generator has optimized its knowledge technology capability. On this weblog publish, I’ll evaluate an unsupervised GAN, StyleGAN, which is arguably essentially the most iconic GAN structure that has ever been proposed. This evaluate will spotlight the assorted architectural adjustments which have contributed to the state-of-the-art efficiency of the mannequin. There are numerous elements/ideas to look out for when evaluating completely different StyleGAN fashions: their approaches to producing high-resolution pictures, their strategies of styling the picture vectors within the latent area, and their completely different regularization methods which inspired easy interpolations between generated samples.
Concerning the latent area ….
On this article and the unique analysis papers, you would possibly examine a latent area. GAN fashions encode the coaching pictures into vectors that symbolize essentially the most ‘descriptive’ attributes of the coaching knowledge. The hyperspace that these vectors exist in is called the latent area. To grasp the distribution of the coaching knowledge, you would wish to know the distribution of the vectors within the latent area. The remainder of the article will clarify how a latent vector is manipulated to encode a sure ‘fashion’ earlier than being decoded and upsampled to create a man-made picture that comprises the encoded ‘fashion’.

The StyleGAN mannequin was developed to create a extra explainable structure as a way to perceive varied features of the picture synthesis course of. The authors selected the fashion switch activity as a result of the picture synthesis course of is controllable and therefore they may monitor the adjustments within the latent area. Usually, the enter latent area follows the chance density of the coaching knowledge there may be some extent of entanglement. Entanglement, on this context, is when altering one attribute inadvertently adjustments one other attribute e.g. altering somebody’s hair coloration may additionally change their pores and skin tone. In contrast to the predecessor GANs, the StyleGAN generator embeds the enter knowledge into an intermediate latent area which has an influence on how components of variation are represented within the community. The intermediate latent area on this mannequin is free from the restriction of mimicking the coaching knowledge due to this fact the vectors are disentangled.
As an alternative of taking in a latent vector by means of its first layer, the generator begins from a discovered fixed. Given an enter latent vector, $z$, derived from the enter latent area $Z$, a non-linear mapping community $f: Z rightarrow W$ produces $w in W$. The mapping community is an 8-layer MLP that takes in and outputs 512-dimensional vectors. After we get the intermediate latent vector, $w$, discovered affine transformations then specialize $w$ into types that management adaptive occasion normalization (AdaIN) operations after every convolution layer of the synthesis community $G$.
The AdaIN operations normalize every characteristic map of the enter knowledge individually, thereafter the normalized vectors are scaled and biased by the corresponding fashion vector that’s injected into the operation. On this mannequin, they edit the picture by enhancing the characteristic maps that are output after each convolutional step.
What is that this fashion vector? StyleGAN can encode fashion by means of completely different methods specifically, style-mixing and by including pixel noise through the technology course of. In style-mixing, the mannequin makes use of one enter picture to supply the fashion vector (encoded attributes) for a portion of the technology course of earlier than it’s randomly switched out for one more fashion vector from one other enter picture. For per-pixel noise, random noise is injected into the mannequin at varied levels of the technology course of.
To make sure that StyleGAN provided the consumer the flexibility to regulate the styling of the generated pictures, the authors designed two metrics to find out the diploma of disentanglement of the latent area. Though I outlined ‘entanglement’ above, I consider defining disentanglement additional cements the idea. Disentanglement is when a single styling operation solely impacts one issue of variation (one attribute). The metrics they launched embrace:
- Perceptual Path Size: That is the distinction between generated pictures shaped from vectored sampled alongside a linear interpolation. Given two factors inside a latent area, pattern vectors at uniform intervals alongside the linear interpolation between the supply and endpoints. Discover the spherical interpolation inside normalized enter latent
- Linear Separability: They prepare auxiliary classification networks on all 40 of the CelebA attributes after which classify 200Okay generated pictures primarily based on these attributes. They then match a linear SVM to foretell the label primarily based on the latent-space level and classify the factors by this place. They then compute the conditional entropy H(Y|X) the place X are the lessons predicted by the SVM and Y are the lessons decided by the pre-trained classifier. → This tells us how a lot info is required to find out the true class of the pattern provided that we all know which aspect of the hyperplane it lies. A low worth suggests constant latent area instructions for the corresponding components of variation. A decrease rating exhibits extra disentanglement of options.
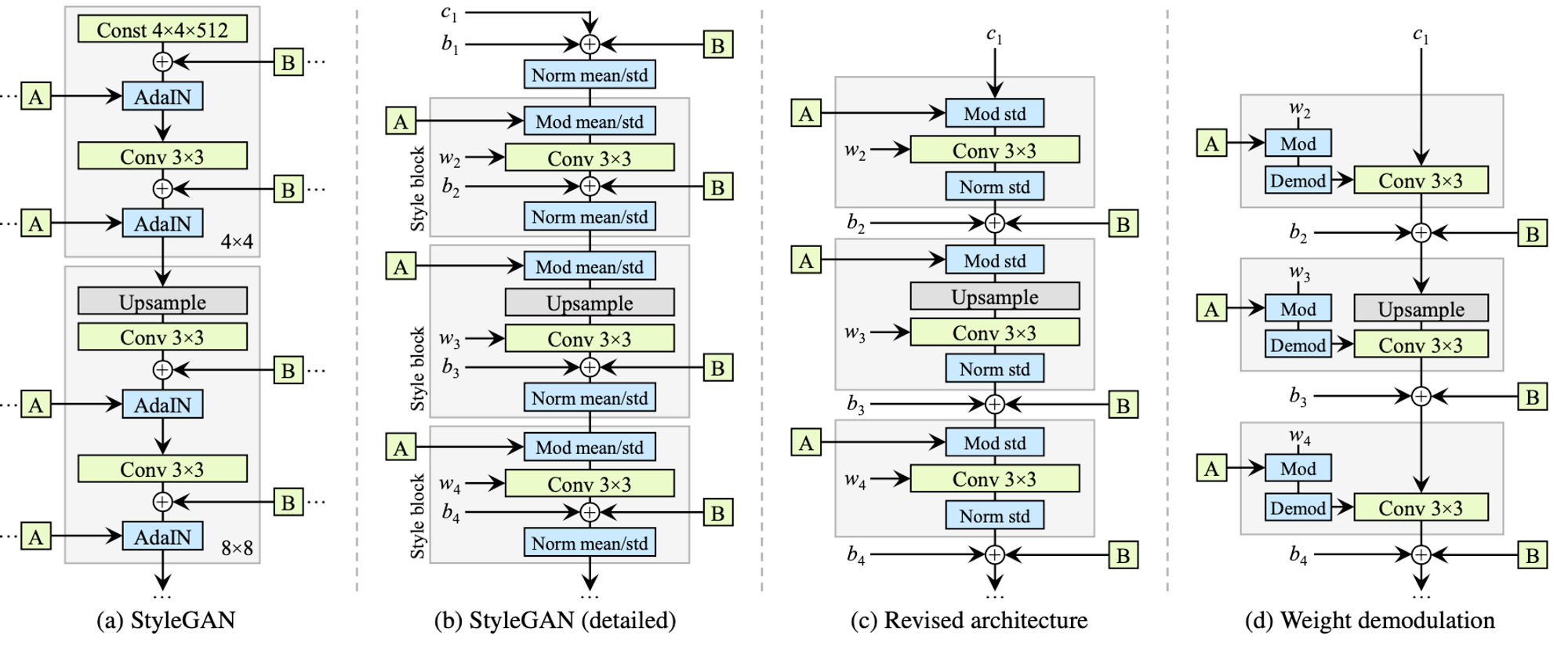
After the discharge of the primary StyleGAN mannequin to the general public, its widespread use led to the invention of among the quirks that have been inflicting random blob-like artifacts on the generated pictures. To repair this, the authors redesigned the characteristic map normalization methods they have been utilizing within the generator, revised the ‘progressive rising’ method they have been utilizing to generate high-resolution pictures, and employed new regularization to encourage good conditioning within the mapping from latent code to photographs.
- Reminder: StyleGAN is a particular kind of picture generator as a result of it takes a latent code $z$ and transforms it into an intermediate latent code $w$ utilizing a mapping community. Thereafter affine transformations then produce types that management the layers of the synthesis community by way of adaptive occasion normalization (AdaIN). Stochastic variation is facilitated by offering extra noise to the synthesis community → This noise contributes to picture variation/variety
- Metrics Reminder:
- FID → A measure of the variations in density of two distributions within the excessive dimensional characteristic area of an InceptionV3 classifier
- Precision → A measure of the proportion of the generated pictures which might be just like coaching knowledge
- Recall → Proportion of the coaching knowledge that may be generated
The authors point out that the metrics above are primarily based on classifier networks which were proven to deal with texture slightly than shapes and due to this fact some features of picture high quality usually are not captured. To repair this, they suggest a perceptual path size (PPL) metric that correlates with the consistency and stability of shapes. They use PPL to regularize the synthesis community to favor easy mappings and enhance picture high quality.

By reviewing the earlier StyleGAN mannequin, the authors observed blob-shaped artifacts that resemble water droplets. The anomaly begins across the $64^2$ decision and is current in all characteristic maps and will get stronger at increased resolutions. They observe the issue all the way down to the AdaIN operation that normalizes the imply and variance of every characteristic map individually. They hypothesize that the generator deliberately sneaks sign energy info previous the occasion normalization operations by creating a powerful, localized spike that dominates the statistics. By doing so, the generator can successfully scale the sign because it likes elsewhere. This results in producing pictures that may idiot the discriminator however finally fail the ‘human’ qualitative take a look at. Once they eliminated the normalization step, the artifacts disappeared fully.
The unique StyleGAN applies bias and noise throughout the fashion block inflicting their relative influence to be inversely proportional to the present fashion’s magnitude. In StyleGAN2 the authors transfer these operations exterior the fashion block the place they function on normalized knowledge. After this modification, the normalization and modulation function on the usual deviation alone.
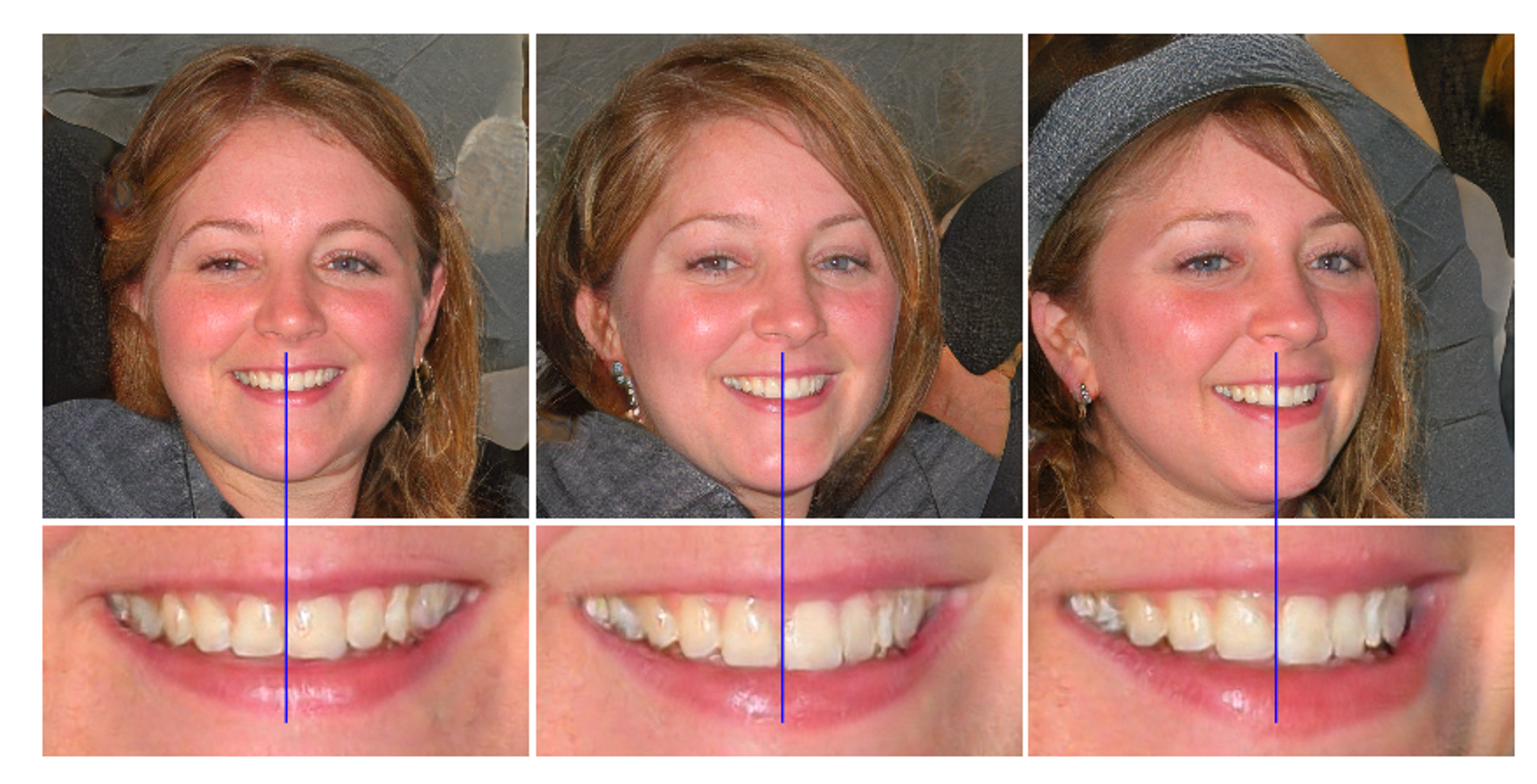
Along with the droplet-like artifacts, the authors found the problem of ‘texture sticking’. Texture sticking happens when progressively grown mills appear to have a powerful location choice for particulars the place sure attributes of a picture appear to have a choice for sure areas of the picture. This could possibly be seen when mills at all times generate pictures with the particular person’s mouth on the middle of the picture (as seen within the picture above). The speculation is that in progressive development every intermediate decision serves as a brief output decision. This, due to this fact, forces these intermediate layers to be taught very high-frequency particulars if the enter which compromises shift-invariance.
To repair this concern, they use a modified model of the MSG-GAN generator which connects the matching resolutions of the generator and the discriminator utilizing a number of skip connections. On this new structure, every block outputs a residual which is summed up and scaled, versus a “potential output” for a given decision of StyleGAN.
For the discriminator, they supply the downsampled picture to every decision block. In addition they use bilinear becoming in up and downsampling operations and modify the design to make use of residual connections. The skip connections within the generator drastically enhance PPL and the residual discriminator is useful for FID.

The authors word that though there are a number of methods of controlling the generative course of, the foundations of the synthesis course of are nonetheless solely partially understood. In the true world, the small print of various scales have a tendency to rework hierarchically e.g. transferring a head causes the nostril to maneuver which in flip strikes the pores and skin pores round it. Altering the small print of the coarse options adjustments the small print of the high-frequency options. That is the situation by which texture sticking doesn’t have an effect on the spatial invariance of the technology course of.
For a typical GAN generator the “coarse, low-resolution options are hierarchically refined by upsampling layers, domestically blended by convolutions, and new element is launched by means of nonlinearities” (Karras, Tero, et al.) Present GANs don’t synthesize pictures in a pure hierarchical method: The coarse options primarily management the presence of finer options however not their exact positions. Though they fastened the artifacts in StyleGAN2, they didn’t fully repair the spatial invariance of finer options like hair.
The purpose of StyleGAN3 is to create an “structure that displays a extra pure transformation hierarchy, the place the precise sub-pixel place of every characteristic is completely inherited from the underlying coarse options.” This merely implies that coarse options discovered in earlier layers of the generator will have an effect on the presence of sure options however not their place within the picture.
Present GAN architectures can partially encode spatial biases by drawing on unintentional positional references accessible to the intermediate layers by means of picture borders, per-pixel noise inputs and positional encodings, and aliasing.
Regardless of aliasing receiving little consideration in GAN literature, the authors determine two sources of it:
- faint after-images ensuing from non-ideal upsampling filters
- point-wise utility of non-linearities within the convolution course of i.e. equivalent to ReLU / swish
Earlier than we get into among the particulars of StyleGAN3, I have to outline the phrases aliasing and equivariance for the context of StyleGAN.
Aliasing → “Customary convolutional architectures include stacked layers of operations that progressively downscale the picture. Aliasing is a well known side-effect of downsampling which will happen: it causes high-frequency elements of the unique sign to turn out to be indistinguishable from its low-frequency elements.”(supply)
Equivariance → “Equivariance research how transformations of the enter picture are encoded by the illustration, invariance being a particular case the place a change has no impact.” (supply)
One in all StyleGAN3’s objectives is to redesign the StyleGAN2 structure to suppress aliasing. Recall that aliasing is likely one of the components that ‘leak’ spatial info into the technology course of thereby implementing texture sticking of sure attributes. The spatial encoding of a characteristic could be helpful info within the later levels of the generator, due to this fact, making it a high-frequency element. To make sure that it stays a high-frequency element, the mannequin must implement a technique to filter it from low-frequency elements which might be helpful earlier within the generator. They word that earlier upsampling methods are inadequate to forestall aliasing and due to this fact they current the necessity to design high-quality filters. Along with designing high-quality filters, they current a principled answer to aliasing attributable to point-wise nonlinearities (ReLU, swish) by contemplating their impact within the steady area and appropriately low-pass filtering the outcomes.
Recall that equivariance implies that the adjustments to the enter picture are traceable by means of its vector illustration. To implement steady equivariance of sub-pixel translation, they describe a complete redesign of all signal-processing features of the StyleGAN2 generator. As soon as aliasing is suppressed, the interior representations now embrace coordinate methods that enable particulars to be accurately hooked up to the underlying surfaces.

StyleGAN 1,2, & Three have proven great success with regard to face-image technology however have lagged when it comes to picture technology for extra various datasets. The purpose of StyleGAN XL is to implement a brand new coaching technique influenced by Projected GAN to coach StyleGAN3 on a big, unstructured, and high-resolution dataset like ImageNet.
The two mains points addressed with earlier GAN fashions are:
- The necessity for structured datasets to ensure semantically right generated pictures
- The necessity for bigger costlier fashions to deal with massive datasets (a scale concern)
What’s Projected GAN? Projected GAN works by projecting generated and actual samples into a set, pretrained characteristic area. This revision improves the coaching stability, coaching time, and knowledge effectivity of StyleGAN3. The purpose is to coach the StyleGAN3 generator on ImageNet and success is outlined when it comes to pattern high quality primarily measured by inception rating (IS) and variety measured by FID.
To coach on a various class-conditional dataset, they implement layers of StyleGAN3-T the translation-equivariant configuration of StyleGAN3. The authors found that regularization improves outcomes on uni-modal datasets like FFHQ or LSUN whereas it may be disadvantageous to multi-modal datasets due to this fact, they keep away from regularization the place attainable on this challenge.
In contrast to StyleGAN 1&2 they disable fashion mixing and path size regularization which results in poor outcomes and unstable coaching when used on advanced datasets. Regularization is barely useful when the mannequin has been sufficiently educated. For the discriminator, they use spectral normalization with out gradient penalties they usually additionally apply a gaussian filter to the photographs as a result of it prevents the discriminator from specializing in excessive frequencies early on. As we noticed in earlier StyleGAN fashions, specializing in excessive frequencies early on can result in points like spatial invariance or random disagreeable artifacts.
StyleGAN inherently works with a latent dimension of dimension 512. This dimension is fairly excessive for pure picture datasets (ImageNet’s dimension is ~40). A latent dimension code of 512 is extremely redundant and makes the mapping community’s activity tougher originally of coaching. To repair this, they scale back StyleGAN’s latent code z to 64 to have secure coaching and decrease FID values.
Conditioning the mannequin on class info is crucial to regulate the pattern class and enhance total efficiency. In a class-conditional StyleGAN, a one-hot encoded label is embedded right into a 512-dimensional vector and concatenated with z. For the discriminator, class info is projected onto the final layer. These edits to the mannequin make the generator produce comparable samples per class leading to excessive IS but it surely results in low recall. They hypothesize that the category embeddings collapse when coaching with Projected GAN. To repair this, they ease the optimization of the embeddings by way of pertaining. They extract and spatially pool the bottom decision options of an Efficientnet-lite0 and calculate the imply per ImageNet class. Utilizing this mannequin retains the output embedding dimension sufficiently small to keep up secure coaching. Each the generator and discriminator are conditioned on the output embedding.
Progressive development of GANs can result in quicker extra secure coaching which results in increased decision output. Nevertheless, the unique methodology proposed in earlier GANs results in artifacts. On this mannequin, they begin the progressive development at a decision of $16^2$ utilizing 11 layers and each time the decision will increase, we reduce off 2 layers and add 7 new ones. For the ultimate stage of $1024^2$, they add solely 5 layers because the final two usually are not disregarded. Every stage is educated till FID stops lowering.
Earlier research present that “pretrained characteristic networks F carry out equally when it comes to FID when used for Projected GAN coaching no matter coaching knowledge, pertaining goal, or community structure.” (Sauer, Axel, Katja Schwarz, and Andreas Geiger.) On this paper, they discover the worth of mixing completely different characteristic networks. Ranging from the usual configuration, an EfficientNet-lite0, they add a second characteristic community to examine the affect of its pertaining goal and structure. They point out that combining an EfficientNet with a ViT improves efficiency considerably as a result of these two architectures be taught completely different representations. Combining each architectures has complementary outcomes.
The ultimate contribution of this mannequin is using classifier steering primarily as a result of it specializes on various datasets. Classifier steering injects class info into diffusion fashions. Along with the category embeddings given by EfficientNet, additionally they inject class info into the generator. How do they do that?
- They cross a generated picture $x$ by means of a pretrained classifier (DeiT-small) to foretell the category label $c_i$
- Add a cross-entropy loss as a further time period to the generator loss and scale this time period by a relentless $lambda$
Doing this results in an enchancment within the inception rating (IS) indicating a rise in pattern high quality. Classifier steering solely works effectively for increased resolutions ($>32^2$) in any other case it results in mode collapse. With the intention to be certain that the fashions usually are not inadvertently optimizing for FID and IS when utilizing classifier steering, they suggest random FID (rFID). They assess the spatial construction of the photographs utilizing sFID. They report pattern constancy and variety are evaluated by way of precision and recall metrics.
StyleGAN-XL considerably outperforms all different ImageNet technology fashions throughout all resolutions in FID, sFID, rFID, and IS. StyleGAN-XL additionally attains excessive variety throughout all resolutions, due to the redefined progressive development technique.

Simply after we thought GANs have been about to be extinct with the daybreak of diffusion fashions, StyleGAN-T stated “maintain my beer soda”. Present Textual content-to-Picture (TI) synthesis is gradual as a result of producing a single pattern requires a number of analysis steps utilizing diffusion fashions. GANs are a lot quicker as a result of they include one analysis step. Nevertheless, earlier GAN strategies don’t outperform diffusion fashions (SOTA) when it comes to secure coaching on various datasets, robust textual content alignment, and controllable variation vs textual content alignment tradeoff. They suggest StyleGAN-T performs higher than earlier SOTA-distilled diffusion fashions and former GANs.
A few issues make test-to-image synthesis attainable:
- Textual content prompts are encoded utilizing pretrained massive language fashions that make it attainable to situation synthesis primarily based on basic language understanding
- Largescale datasets containing picture and caption pairs
Current success in TI has been pushed by diffusion fashions (DM) and autoregressive (ARM) fashions which have the massive capability to soak up the coaching knowledge and the flexibility to cope with extremely multi-modal knowledge. GANs work finest with smaller and fewer various datasets which make them much less very best than higher-capacity diffusion fashions
GANs have the benefit of quicker inference pace & management of the synthesized picture attributable to manipulation of the latent area. The advantages of StyleGAN-T embrace “quick inference pace and easy latent area interpolation within the context of text-to-image synthesis”
The authors select the StyleGAN-XL mannequin because the baseline structure due to its “robust efficiency in class-conditional ImageNet synthesis”. The picture high quality metrics they use are FID and CLIP Rating utilizing a ViT-g-14 mannequin educated on LAION-2B. To transform the category conditioning into textual content conditioning, they embedded the textual content prompts utilizing a pre-trained CLIP ViT-L/14 textual content encoder and use the embeddings rather than class embeddings.
For the generator, the authors drop the constraint for translation equivariance as a result of profitable DM & ARM don’t require equivariance. They “drop the equivariance and change to StyleGAN2 spine for the synthesis layers, together with output skip connections and spatial noise inputs that facilitate stochastic variation of low-level particulars” (Sauer, Axel, et al.)
The fundamental configuration of StyleGAN implies {that a} “vital improve within the generator’s depth results in an early mode collapse in coaching”. To handle this they “make half the convolution layers residual and wrap them by GroupNorm” for normalization and LayerScale for scaling their contribution. This enables the mannequin to step by step incorporate the contributions of the convolutional layer and stabilize the early coaching iterations.
In a style-based structure, all of this variation must be carried out by the per-layer types. This leaves little room for the textual content embedding to affect the synthesis. Utilizing the baseline structure they observed a bent of the enter latent $z$ to dominate over the textual content embedding $c_{textual content}$, resulting in poor textual content alignment.
To repair this they let the $c_{textual content}$ bypass the mapping community assuming that the CLIP textual content encoder defines an applicable intermediate latent area for the textual content conditioning. They concatenate $c_{textual content}$ to $w$ and use a set of affine transforms to supply per-layer types $tilde{s}$. As an alternative of utilizing the ensuing $tilde{s}$ to modulate the convolutions as-is, they additional break up $tilde{s}$ into Three vectors of equal dimensions $tilde{s}{1,2,3}$ and compute the ultimate fashion vector as, $s = tilde{s}! circledcirc tilde{s}_2 + tilde{s}_3$. This operation ensures element-wise multiplication that turns the affine transformation right into a $2^{nd}$ order polynomial community that has elevated expressive energy.
The discriminator borrows the next concepts from StyleGAN-XL like counting on a frozen, pre-trained characteristic community and utilizing a number of discriminator heads. The mannequin makes use of ViT-S (ViT: Visible Transformer) for the characteristic community as a result of it’s light-weight, fast inferencing, and encodes semantic information at excessive decision. They use the identical isotropic structure for all of the discriminator heads which they area equally between the transformer layers. These discriminator heads are evaluated independently utilizing hinge loss. They use knowledge augmentation (random cropping) when working with resolutions bigger than 224×224. They increase the information earlier than passing it into the characteristic community and this has proven vital efficiency will increase.
Steerage: This can be a idea in TI that trades variation for perceived picture high quality in a principled approach preferring pictures which might be strongly aligned with the textual content conditioning
To information the generator StyleGAN-XL makes use of an ImageNet classifier to supply extra gradients throughout coaching. This guides the generator towards pictures which might be simple to categorise.
To scale this strategy, the authors used a CLIP picture encoder versus a classifier. At every generator replace, StyleGAN-T passes the generated picture by means of the CLIP picture encoder to get $c_{picture}$ and decrease the squared spherical distance to the normalized textual content embedding $c_{textual content}$
$L_{CLIP} = arccos^2(c_{picture},c_{textual content})$
This loss perform is used throughout coaching to information the generated distribution towards pictures which might be captioned equally to the enter textual content. The authors word that overly robust CLIP steering throughout coaching impairs FID because it limits distribution variety. Subsequently the general weight of this loss perform must strike a steadiness between picture high quality, textual content conditioning, and distribution variety. It’s attention-grabbing to notice that the clip steering is barely useful as much as 64×64 decision, at increased resolutions they apply it to random 64×64 crops.
They prepare the mannequin in 2 phases. Within the major part, the generator is trainable and the textual content encoder is frozen. Within the secondary part, the generator turns into frozen and the textual content encoder is trainable so far as the generator conditioning is worried the discriminator and the steering time period within the loss perform $c_{textual content}$ nonetheless obtain enter from the unique frozen textual content encoder. The secondary part permits the next CLIP steering weight with out introducing artifacts to the generated pictures and compromising FID. After the loss perform converges the mannequin resumes the first part.
To commerce excessive variation for top constancy, GANs use the truncation trick the place a sampled latent vector $w$ is interpolated in the direction of its imply w.r.t the given conditioning enter. Truncation pushes $w$ to a higher-density area the place the mannequin performs higher. Pictures generated from vector $w$ are of upper high quality in comparison with pictures generated from far-off latent vectors.
This mannequin StyleGAN-T has a lot better Zero-shot FID scores on 64×64 decision than many diffusion and autoregressive fashions included within the paper. A few of these embrace Imagen, DALL-E (1&2), and GLIDE. Nevertheless, it performs worse than most DM & ARM on 256×256 decision pictures. My tackle that is that there’s a tradeoff between pace and picture high quality. The variance of FID scores on zero-shot analysis is just not as assorted because the differing efficiency on inference pace. Based mostly on this realization, I believe that StyleGAN-T is a high contender.
Abstract
Though StyleGAN might not be thought of the present state-of-the-art for picture technology, its structure was the idea for lots of analysis on explainability in picture technology due to its disentangled intermediate latent area. There may be much less readability on picture technology w.r.t diffusion fashions, due to this fact, giving room for researchers to switch concepts on understanding picture illustration and technology from the latent area.
Relying on the duty at hand, you can carry out unconditional picture technology on a various set of lessons or generate pictures primarily based on textual content prompts utilizing StyleGAN-XL and StyleGAN-T respectively. GANs have the benefit of quick inferencing and the state-of-the-art StyleGAN fashions (StyleGAN XL and StyleGAN T) have the potential to supply output comparable in high quality and variety to present diffusion fashions. One caveat of StyleGAN-T, which relies on CLIP, is that it generally struggles when it comes to binding attributes to things in addition to producing coherent textual content in pictures. Utilizing a bigger language mannequin would resolve this concern at the price of a slower runtime.
Though quick inference pace is a good benefit of GANs, the StyleGAN fashions I’ve mentioned on this article haven’t been explored as completely for personalisation duties as have diffusion fashions due to this fact I can’t confidently converse on how simple or dependable fine-tuning these fashions could be as in comparison with fashions like Customized Diffusion. These are a number of components to contemplate when figuring out whether or not or to not use StyleGAN for picture technology.
Citations:
- Karras, Tero, Samuli Laine, and Timo Aila. “A mode-based generator structure for generative adversarial networks.” Proceedings of the IEEE/CVF convention on laptop imaginative and prescient and sample recognition. 2019.
- Karras, Tero, et al. “Analyzing and enhancing the picture high quality of stylegan.” Proceedings of the IEEE/CVF convention on laptop imaginative and prescient and sample recognition. 2020.
- Karras, Tero, et al. “Alias-free generative adversarial networks.” Advances in Neural Data Processing Methods 34 (2021): 852-863.
- Sauer, Axel, Katja Schwarz, and Andreas Geiger. “Stylegan-xl: Scaling stylegan to massive various datasets.” ACM SIGGRAPH 2022 convention proceedings. 2022.
- Sauer, Axel, et al. “Stylegan-t: Unlocking the ability of gans for quick large-scale text-to-image synthesis.” arXiv preprint arXiv:2301.09515 (2023).



