It is a visitor submit from Mateo Rojas-Carulla, CTO at Lakera AI
Introduction to the Mannequin Robustness Experiment
Mannequin choice is a elementary problem for groups deploying to manufacturing: how do you select the mannequin that’s most probably to generalize to an ever-changing world?
On this weblog submit, we’ll concentrate on two features of mannequin choice:
- Given a number of fashions with related check mAP, which mannequin must you truly deploy? Are all mAPs created equal?
- Including augmentations is a vital instrument for constructing dependable fashions. If you add augmentations to your fashions, do they all the time have the specified impact (e.g., does including blur all the time shield towards blur)? And do they result in “higher” fashions?
To reply these questions, we skilled fashions with completely different augmentation methods utilizing the Roboflow platform, and stress-tested the robustness of those fashions utilizing Lakera’s MLTest.
TL;DR:
- Mixture check metrics like mAP are useful however they don’t inform the entire story. Two fashions with the identical mAP can have very completely different behaviors in manufacturing. Intensive robustness evaluation can assist to efficiently select between these fashions.
- Augmentation methods ought to be examined as a part of the event course of. Typically, including no augmentations in any respect can result in a greater mannequin. As we’ll see, generally including the augmentation could make the mannequin worse with respect to that augmentation! This has large implications for operational efficiency. Once more, the mAP rating does not inform the entire story.
- Mannequin robustness scoring, which you are able to do with Lakera’s MLTest, goes deeper and permits you to differentiate between fashions that look in any other case similar. It would inform you if the augmentations you may have added are having the specified impact; if not, it is going to let you recognize which augmentations that you must concentrate on in your subsequent coaching iteration.
What’s Mannequin Robustness Testing?
Lakera’s MLTest seems for vulnerabilities in pc imaginative and prescient programs, and helps builders determine which fashions will generalize to manufacturing throughout growth.
Probing for generalization requires a number of angles of assault, from analyzing the robustness of the mannequin, to understanding information points (corresponding to mislabeled pictures) or mannequin failure clustering and evaluation. For the aim of this experiment, we focus solely on robustness evaluation.
First, what can we imply by the mannequin’s robustness? To make sure efficiency in manufacturing, you’ll wish to stress check your mannequin by straight modifying your dataset in methods which can be prone to have an effect on the mannequin in manufacturing, corresponding to adjustments in picture high quality and lighting. This stress testing solutions a elementary query: how does my mannequin behave when the information begins to deviate from the coaching distribution in ways in which I can realistically anticipate to see in manufacturing?
Whereas realizing how brittle a mannequin is supplies essential alerts, robustness scores can inform us rather more a few mannequin. It supplies a robust indicator of a system’s means to generalize: if a system breaks down underneath delicate deviations from the unique coaching distribution, it’s prone to fail underneath the variations it is going to undoubtedly face in manufacturing. YOLOv8 and different widespread pre-trained backbones have very completely different robustness properties, which can find yourself being inherited by your fine-tuned mannequin.
Let’s take a look at what this implies for a number of fashions skilled on the Roboflow platform.
How one can Check and Perceive Mannequin Robustness
On this part, we take you step-by-step by way of working MLTest on Roboflow fashions.
We begin from a easy quest, commonplace for builders constructing product pc imaginative and prescient programs:
- Prepare a number of fashions with completely different augmentation methods.
- Choose the mannequin most probably to generalize to the manufacturing atmosphere.
We wish to dig deeper into these fashions: can we inform these fashions aside, and the way do they differ? What implication does this have for you when selecting the right fashions to ship into the world?
We give an in depth overview of the experiments so to additionally run MLTest by yourself Roboflow fashions to pick out higher fashions sooner or later.
Choose a Dataset
To get began, we have to choose a dataset. We used the Development Website Security Dataset, which represents a number of of the challenges confronted by groups aiming to ship a dependable system to their buyer, with a number of buyer websites, a continually altering atmosphere, and so on.
To run MLTest with Roboflow, you’ll need to obtain the dataset to your machine. The practice/validation/check break up for this dataset seems as follows:
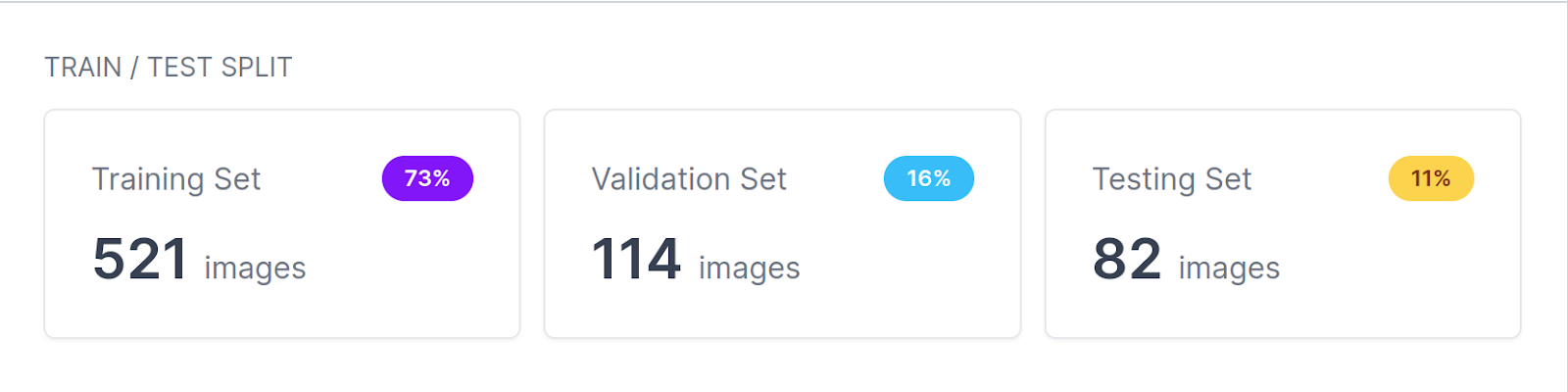
Prepare a Mannequin with Roboflow
The subsequent step is to create a venture of your personal. We created a model new venture and copied all the information from the unique website security dataset. We are able to practice our first mannequin by going to the Generate tab.
All fashions have been skilled with the Correct mannequin, which trains for longer. The fashions have been then deployed utilizing Roboflow’s hosted API.
For the aim of this experiment, we skilled three fashions with completely different augmentation methods. All augmentations use the default parameters. Let’s take a look at these three fashions in a bit extra element.
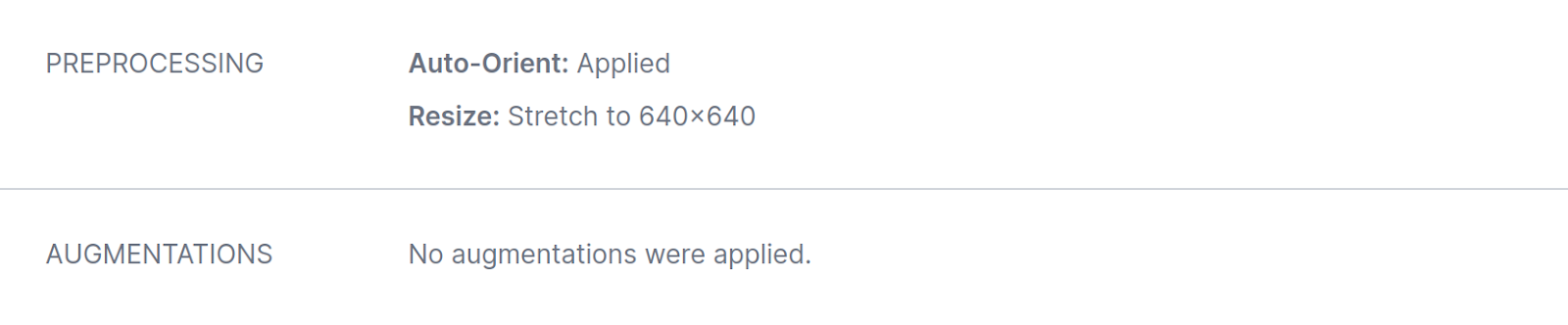
Mannequin A was skilled utilizing a YOLOv8 spine, with no augmentations added to the mannequin:
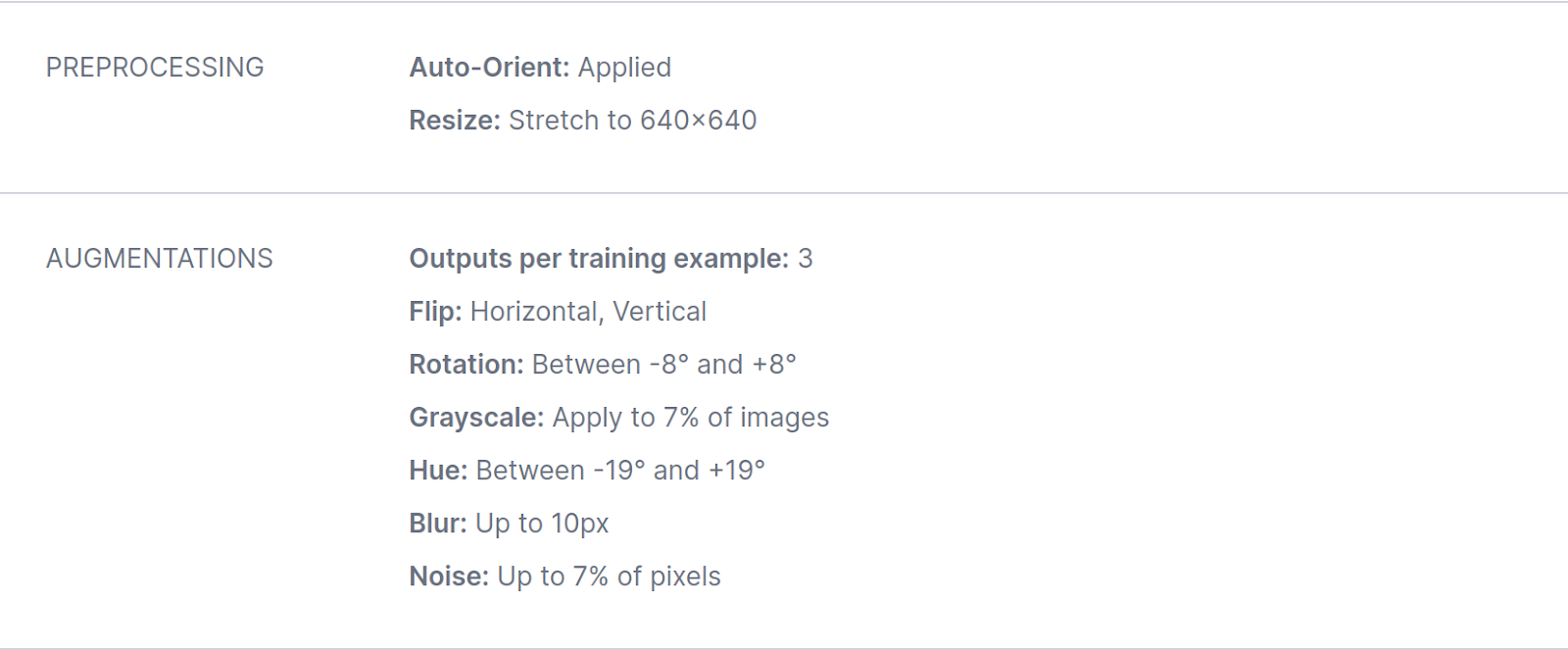
Mannequin B was skilled utilizing a YOLOV8 spine, with a number of augmentations added throughout coaching:
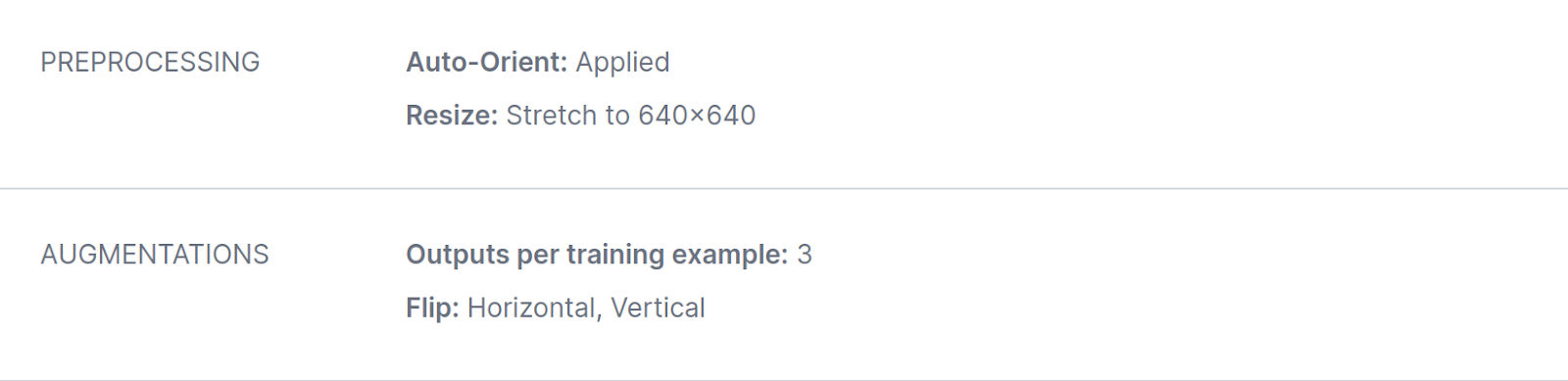
Lastly, Mannequin C was skilled ranging from the checkpoint from mannequin A, whereas additionally including a focused augmentation – vertical and horizontal flips:
Commonplace Mannequin Metrics
Let’s check out the check mAPs for all three fashions, each total and by particular person class. As you may see, there may be little distinction between the three fashions. There are some discrepancies for the completely different courses, however all fashions have a mAP round 0.5.
Are these fashions created equal, have they realized the identical behaviors? Are there any variations hiding between these numbers?
Robustness Scoring Unveils Deeper Insights
To see mannequin robustness, we’ll use MLTest which is easy and requires writing two easy courses, a RoboflowDataset which signifies tips on how to learn the pictures and their labels, in addition to a RoboflowAPIPredictor which, given an enter picture, queries Roboflow’s hosted API. Yow will discover all of the code required to run MLTest on this repository. It’s also possible to discover all the outcomes from this experiment on this hosted dashboard
Do not forget that all three fashions right here had roughly the identical mAP, so distinguishing them based mostly on commonplace check metrics, even by class, was troublesome. Right here’s what MLTest needed to say about these fashions.
Mannequin A and mannequin B usually are not created equal. They’ve the identical danger rating and mixture metrics, indicating that the general, common robustness of the mannequin didn’t enhance regardless of the intensive augmentation technique.
Nonetheless, the side-by-side comparability beneath (within the pictures beneath: A on the left, B on the suitable) exhibits you that each fashions behave otherwise relying on the kind of the augmentation:
- Mannequin B grew to become extra sturdy to geometric transformations and blur, indicating a optimistic impact of the transformation technique.
- Nonetheless, mannequin B additionally responds a lot worse to numerous varieties of noise within the picture, although corresponding augmentations have been added throughout coaching!
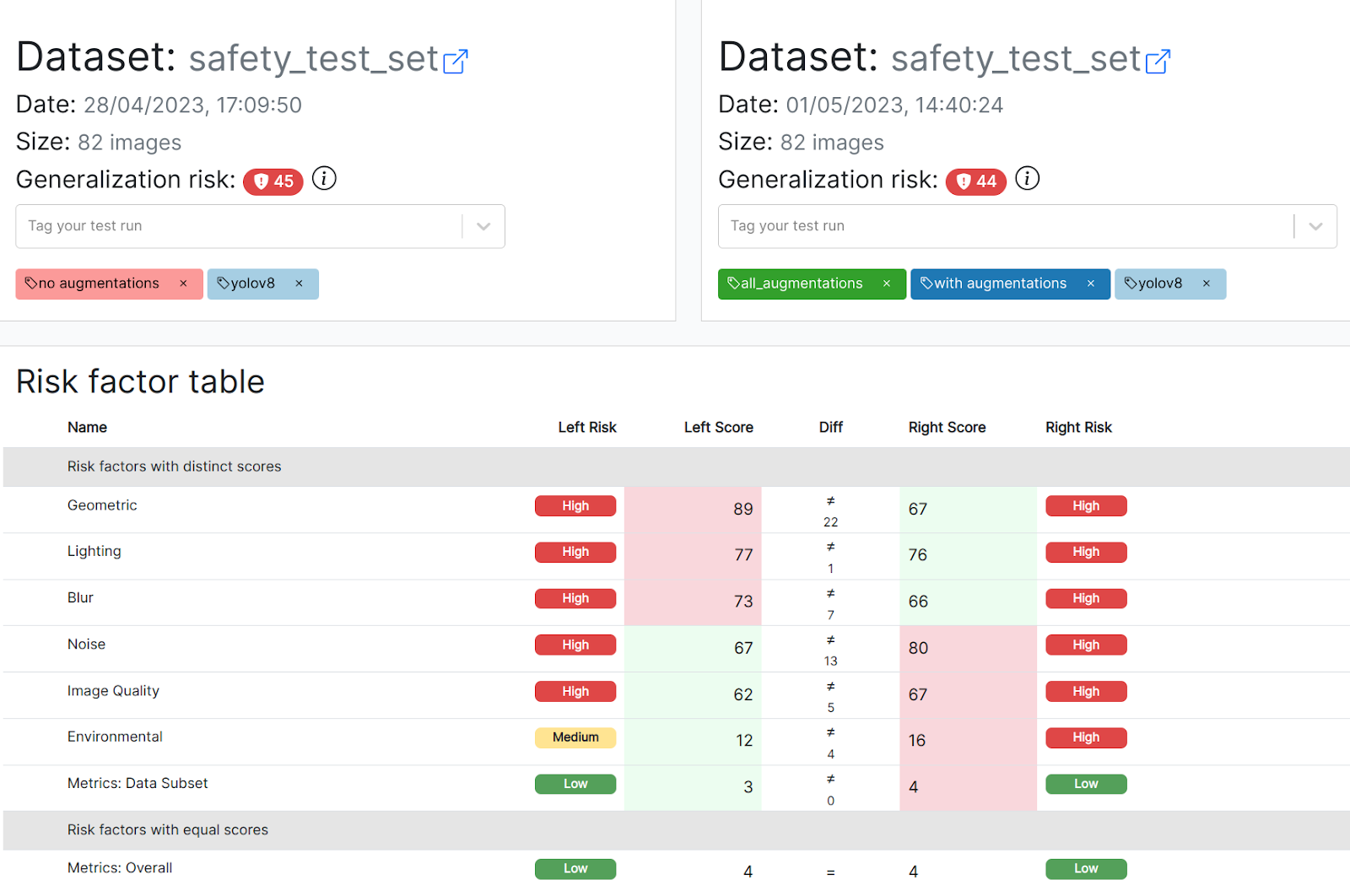
In different phrases, relying on the attribute most probably to seem in manufacturing, you would definitely desire one mannequin over the opposite. For instance, should you anticipate blur artifacts to be confronted in manufacturing, mannequin B is superior. With out these insights, these fashions would appear the identical based mostly on mAP.
As a pure subsequent step, we might return to the Roboflow platform, and practice a mannequin the place we extra aggressively add noise augmentations. We might then use MLTest to confirm that we protect the properties we gained on the primary augmentation spherical, whereas additionally turning into extra sturdy to noise within the enter.
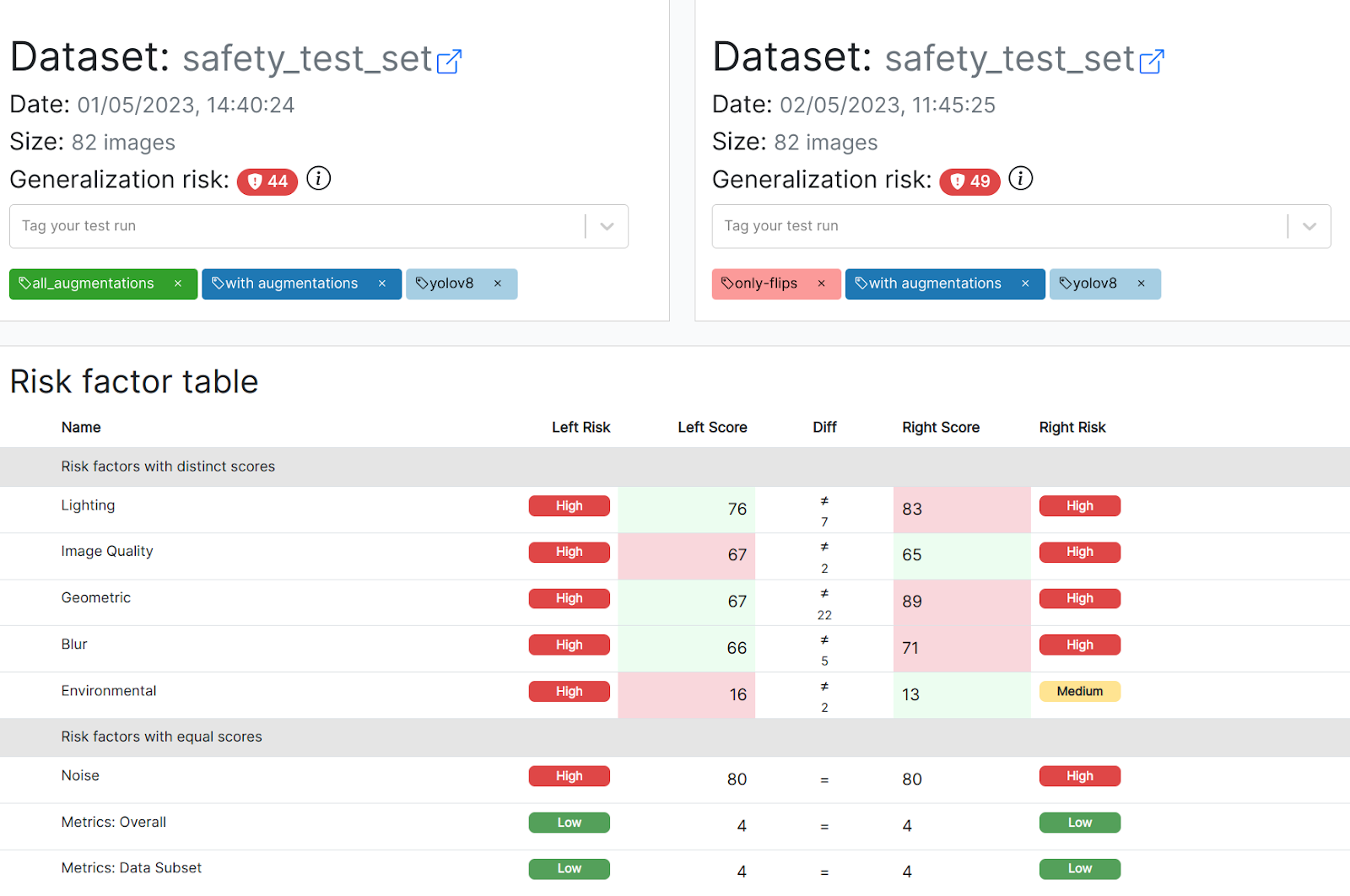
Mannequin C, which provides horizontal and vertical flips throughout coaching, performs worse throughout the board in comparison with mannequin B, together with on flips! The mannequin’s generalization danger rating is over 10% worse than mannequin B (44 -> 49). Between these two fashions, it’s clear that the non-augmented mannequin is safer to deploy to manufacturing. The next comparability exhibits B on the left, C on the suitable.
Examples of Mannequin Failures with Augmentations
The next is a small number of pictures the place the mannequin’s conduct adjustments significantly after the pictures have been modified. Right here for instance, the mannequin accurately identifies an individual and the shortage of a security vest on the unique picture. Nonetheless, the entire individual is missed by the mannequin on the modified picture!

Equally, within the following picture all objects which can be recognized on the unique picture are missed within the modified picture.

Conclusion
Two key takeaways from our mannequin robustness experiment:
- Check metrics are a tough indicator of the behaviors that your mannequin has realized. Even fashions which can be indistinguishable based mostly on these metrics have realized completely different behaviors, and a few are clearly extra seemingly than others to fail in manufacturing.
- Discovering the suitable augmentation technique in your mannequin is essential to success. Nonetheless, the technique ought to be totally validated all through deployment: including augmentations can have unintended results, and may even make fashions worse than not augmenting the dataset in any respect. A strong mannequin is extra prone to generalize and thus cope properly with the difficult environments encountered in manufacturing.
What does this imply for you? MLTest can turn into an integral a part of your growth workflow with Roboflow, displaying you whether or not your augmentation methods are having the meant impact for every new mannequin that you simply practice.
After getting a snapshot of your mannequin’s robustness produced by MLTest, you may then return to the Roboflow platform and add a brand new set of augmentations, or modify what number of pictures are augmented throughout coaching, or how robust the augmentation is. In consequence, you may anticipate a mannequin a lot better ready to deal with the adjustments it is going to encounter in manufacturing. Getting began with MLTest is straightforward, merely fill on this kind.



