Labeling giant datasets could be a time-consuming and labor-intensive job. Nevertheless, with developments in deep studying and pure language processing, it’s now doable to automate the labeling course of.
On this weblog publish, we’ll information you thru the method of utilizing CLIP (Contrastive Language-Picture Pretraining) and Roboflow to robotically label your dataset immediately inside a Jupyter Pocket book atmosphere.
💡
What’s CLIP?
CLIP, developed by OpenAI, is a cutting-edge deep studying mannequin designed to extract visible ideas from pure language descriptions. This mannequin achieves cross-modal retrieval and understanding by associating photographs and textual content inside a shared embedding house. By way of intensive coaching on giant corpora of photographs and their corresponding textual descriptions, CLIP learns to encode photographs and textual content in a means that their embeddings mirror semantic similarity.
Robotically Labeling Classification Datasets
For this demonstration, we might be utilizing the Roboflow Artwork Classification Dataset. This classification dataset comprises creative motion artwork photographs that vary from Summary Expressionism to Pop Artwork. The dataset has been curated and labeled to incorporate a various vary of creative types, permitting us to discover the capabilities of CLIP and automatic labeling.
Step 1: Set up and Setup
Earlier than we dive into autolabeling, let’s arrange the required atmosphere. We’ll be utilizing a Jupyter pocket book for this demonstration. Begin by putting in the mandatory dependencies:
!pip set up ftfy regex tqdm
!pip set up git+https://github.com/openai/CLIP.git
!pip set up roboflowSubsequent, import the required libraries:
import glob
import os
import clip
import math
import torch
import matplotlib.pyplot as plt
from IPython.core.show import HTML
import numpy as np
from PIL import Picture
from roboflow import Roboflow
import csvStep 2: Loading the Dataset
Subsequent, we have to put together our dataset for autolabeling. If you do not have a Roboflow account, you may join free and create a brand new venture.
Upon getting your venture arrange on Roboflow, you need to use the Roboflow Python bundle to obtain the dataset immediately into your Jupyter pocket book. This is an instance of find out how to obtain the dataset:
rf = Roboflow(api_key="YOUR_API_KEY")
venture = rf.workspace("art-dataset").venture("wiki-art")
dataset = venture.model(2).obtain("clip")To robotically label the dataset, we have to extract options from the photographs utilizing the CLIP mannequin. Execute the next code to extract the picture options:
for i in vary(batches): photographs = img[i*batch : (i+1)*batch] batch_preprocessed = batch_preprocessed = torch.stack([preprocess(i) for i in images if i is not None]).to(machine) with torch.no_grad(): image_embeddings = mannequin.encode_image(batch_preprocessed) image_embeddings /= image_embeddings.norm(dim=-1, keepdim=True) options = torch.cat((options, image_embeddings)) print(f"Pictures Extracted: {options.form}")Step 4: Discovering Comparable Pictures with Textual content Enter
Now, let’s use the extracted picture options to seek out related photographs primarily based on a textual content enter. Execute the next code to outline a operate that finds related photographs given a textual content question:
def findImg(input_text, threshold=25.9, num=5): with torch.no_grad(): text_embeddings = mannequin.encode_text(clip.tokenize(input_text).to(machine)) text_embeddings /= text_embeddings.norm(dim=-1, keepdim=True) similarities = (100.0 * options @ text_embeddings.T) values, top_poster = similarities.topk(num, dim=0) for frame_id in top_poster: rating = similarities[frame_id.item()] if rating > threshold: print("Cosine Similarity Rating for Picture", frame_id.merchandise(), ":", rating) show(img[frame_id]) findImg("Cubism")

This operate takes an enter textual content and finds probably the most related photographs primarily based on the cosine similarity between the textual content and picture embeddings. You may modify the edge parameter to regulate the similarity threshold for displaying photographs. Change the textual content question with your personal description to seek out related photographs.
Step 5: Visualizing Cosine Similarity between Textual content and Picture Options
To visualise the similarity between the textual content and picture options, you may check with the whole code offered within the interactive pocket book.
We compute the cosine similarity between the textual content and picture options and visualize it as a warmth map. Every row represents a textual content description, and every column represents a picture class. The values within the heatmap point out the similarity scores between the textual content and picture options.
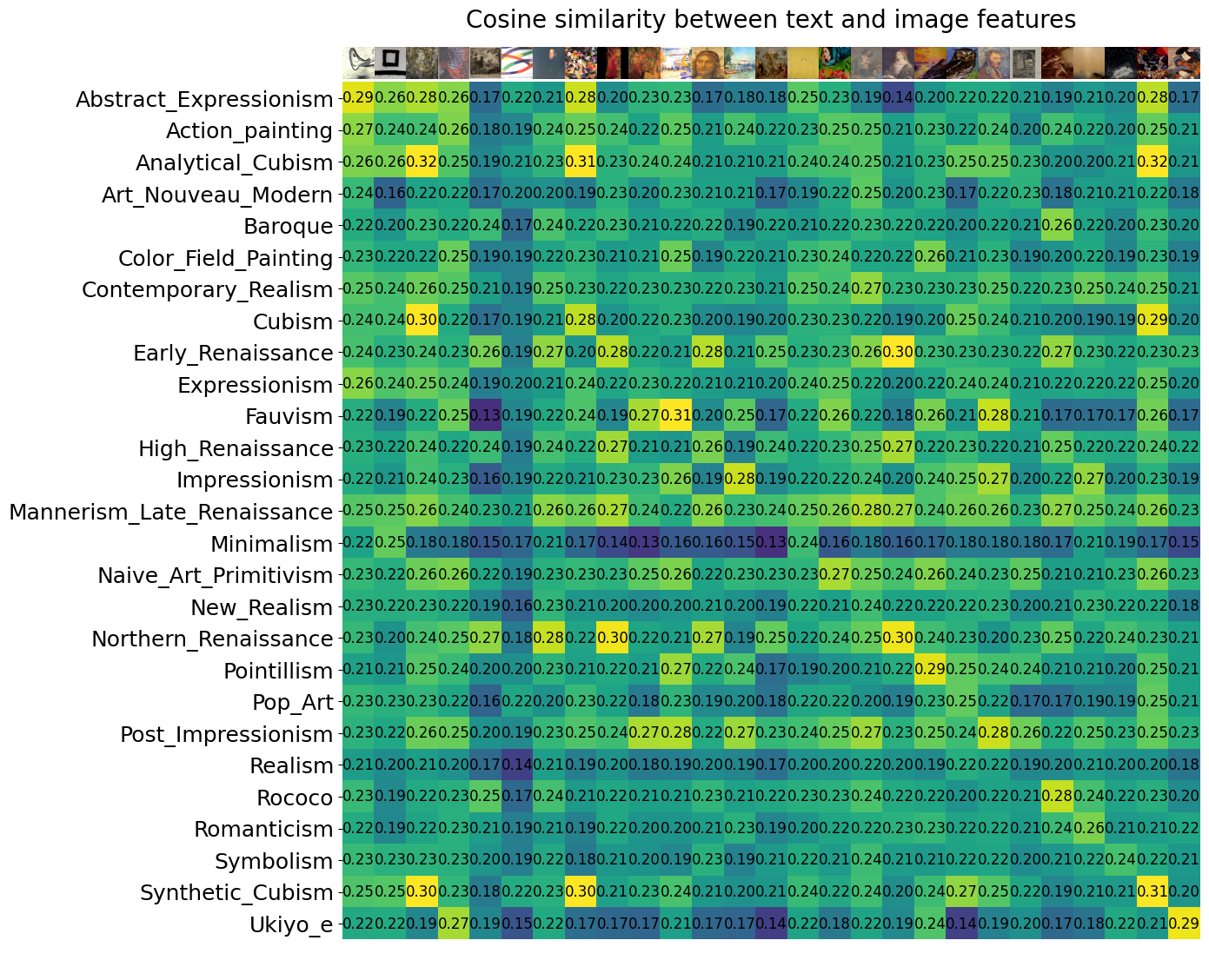
Step 6: Autolabeling with CLIP
Lastly, let’s carry out automated labeling of the dataset utilizing the CLIP mannequin. Execute the next code:
class_tokens = clip.tokenize([desc for desc in labels]).cuda()
with torch.no_grad(): text_features = mannequin.encode_text(class_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
img = []
options = torch.empty([0, 512], dtype=torch.float16).to(machine) header = ["Names"] + labels
rows = [] for i in vary(0, len(image_paths), batch): batch_paths = image_paths[i : i + batch] for path in batch_paths: img_name = os.path.basename(path) with Picture.open(path) as im: im_array = np.array(im) new_im = Picture.fromarray(im_array) img.append(new_im) photographs = img[-len(batch_paths):] batch_preprocessed = torch.stack([preprocess(i) for i in images if i is not None]).to(machine) with torch.no_grad(): image_embeddings = mannequin.encode_image(batch_preprocessed) image_embeddings /= image_embeddings.norm(dim=-1, keepdim=True) options = torch.cat((options, image_embeddings)) similarity_scores = np.dot(image_embeddings.cpu().numpy(), text_features.cpu().numpy().T) most_similar_labels = np.argmax(similarity_scores, axis=1) for img_name, label in zip(batch_paths, most_similar_labels): row = [os.path.basename(img_name)] for j in vary(len(labels)): if label == j: row.append(1) # Most related label, assign 1 else: row.append(0) # Different labels, assign Zero rows.append(row) filename = "autolabel.csv" # Change together with your desired file identify
with open(filename, "w", newline="") as file: author = csv.author(file) author.writerow(header) author.writerows(rows)
This code performs automated labeling by calculating the cosine similarity between the picture options and sophistication textual content embeddings. To offer a visible illustration of the method, take into account the next picture which illustrates the underlying idea:

The labels are then saved in a CSV file named “autolabel.csv”.
Conclusion
You may have efficiently automated dataset labeling utilizing CLIP and Roboflow inside a Jupyter Pocket book. This course of can considerably save effort and time in labeling giant datasets! Comfortable Engineering!



