Use Basis Fashions to Practice Any Imaginative and prescient Mannequin With out Labeling
At this time we’re asserting Autodistill, a brand new library for creating laptop imaginative and prescient fashions with out labeling any coaching information. Autodistill permits you to use the information of huge basis fashions and switch it to smaller fashions for constructing enterprise AI functions operating in real-time or on the edge.
Developments in AI analysis – significantly giant, multipurpose, multimodal basis fashions – symbolize a elementary shift in capabilities of machine studying. AI fashions are able to dealing with an unprecedented, big selection of duties.
Meta AI’s Phase Something Mannequin can section the sides of a mechanical half or merchandise on a shelf, OpenAI’s GPT-Four can write your dinner recipe and write your code (or, quickly, even inform you why a meme is humorous), and BLIP2 by Salesforce can caption a scene of Olympians celebrating a gold medal or describe a photograph of your favourite shoe.
Massive, basis fashions symbolize a stepwise change in capabilities.
Basis fashions aren’t excellent for each use case. They are often GPU compute-intensive, too sluggish for actual time use, proprietary, and/or solely out there by way of API. These limitations can limit builders from utilizing fashions in low compute environments (particularly edge deployment), creating their very own mental property, and/or deploying cheaply.
Should you’re deploying a mannequin to section tennis gamers throughout a stay broadcast to run real-time on an edge machine, Meta’s SAM received’t produce excessive sufficient throughput — although it is aware of tips on how to section the place tennis gamers are zero-shot. Should you’re creating your personal code completion mannequin, you can use GPT-4, although you’re solely leveraging a fraction of its information.
Basis fashions know quite a bit about quite a bit, and lots of real-world AI functions have to know quite a bit about a little bit.
Luckily, there’s a approach to profit from the information of huge fashions with out deploying them explicitly: distillation. There have been latest breakthroughs in each information distillation and dataset distillation to assist make distillation the very best path for transferring the ability of huge fashions to small fashions for real-world functions.
Introducing Autodistill
The Autodistill Python bundle labels photographs routinely utilizing a basis mannequin, which themselves are skilled on hundreds of thousands of photographs and hundreds of thousands of {dollars} in compute consumption by the world’s largest firms (Meta, Google, Amazon, and many others.), then trains a state-of-the-art mannequin on the ensuing dataset.
Distilling a big mannequin offers you:
- A smaller, sooner mannequin with which to work;
- Visibility into the coaching information used to create your mannequin, and;
- Full management over the output.
On this information, we’re going to showcase tips on how to use the brand new Autodistill Python bundle with Grounded SAM and YOLOv8.
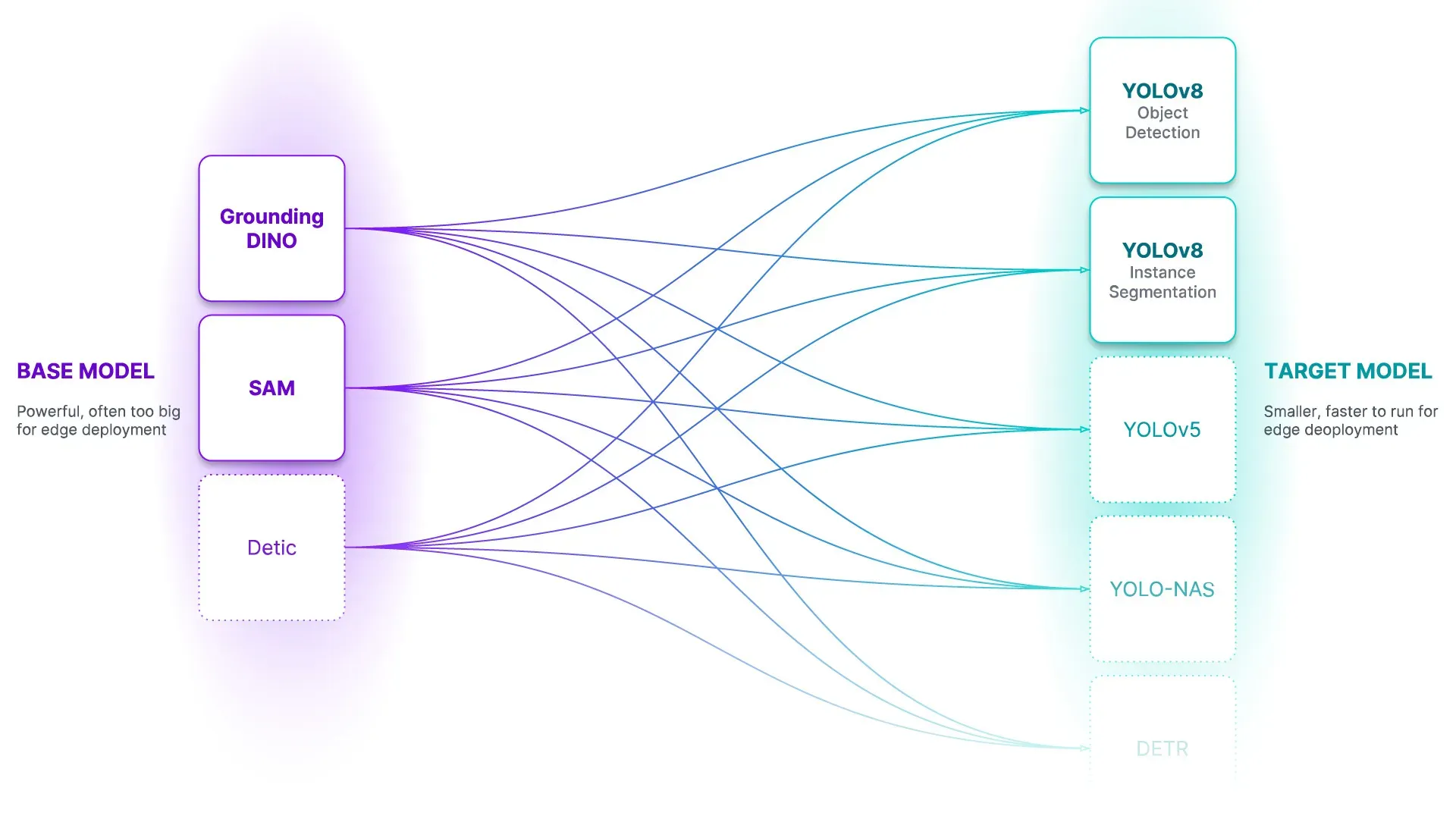
Autodistill is launching with help for utilizing:
- Grounded SAM
- OWL ViT
- DETIC
To coach:
- YOLOv5
- YOLO-NAS
- YOLOv8
Within the coming weeks, we will even announce help for CLIP and ViT for classification duties.
With Autodistill, you get a brand new mannequin that might be considerably smaller and extra environment friendly for operating on the sting and in manufacturing, however at a fraction of the fee and coaching time as the inspiration fashions. You personal your mannequin and have perception into the entire information used to coach it. And it is possible for you to to make use of your mannequin as the place to begin for an automatic energetic studying pipeline to find and repair new edge circumstances it encounters within the wild.
This bundle is impressed by the “distillation” course of in laptop imaginative and prescient through which one takes the information from a bigger mannequin then “distills” the knowledge right into a smaller mannequin.
Processes modeled on distillation have been utilized in pure language processing to create smaller fashions that study their information from bigger fashions. One notable instance of that is the Stanford Alpaca mannequin, launched in March 2023. This mannequin used OpenAI’s text-davinci-003 mannequin to generate 52,000 directions utilizing a seed set of knowledge.
These examples had been then used to fine-tune the LLaMA mannequin by Meta Analysis to generate a brand new mannequin: Alpaca. Information from a big mannequin – text-davinci-003 – was distilled into Alpaca.
How Autodistill Works
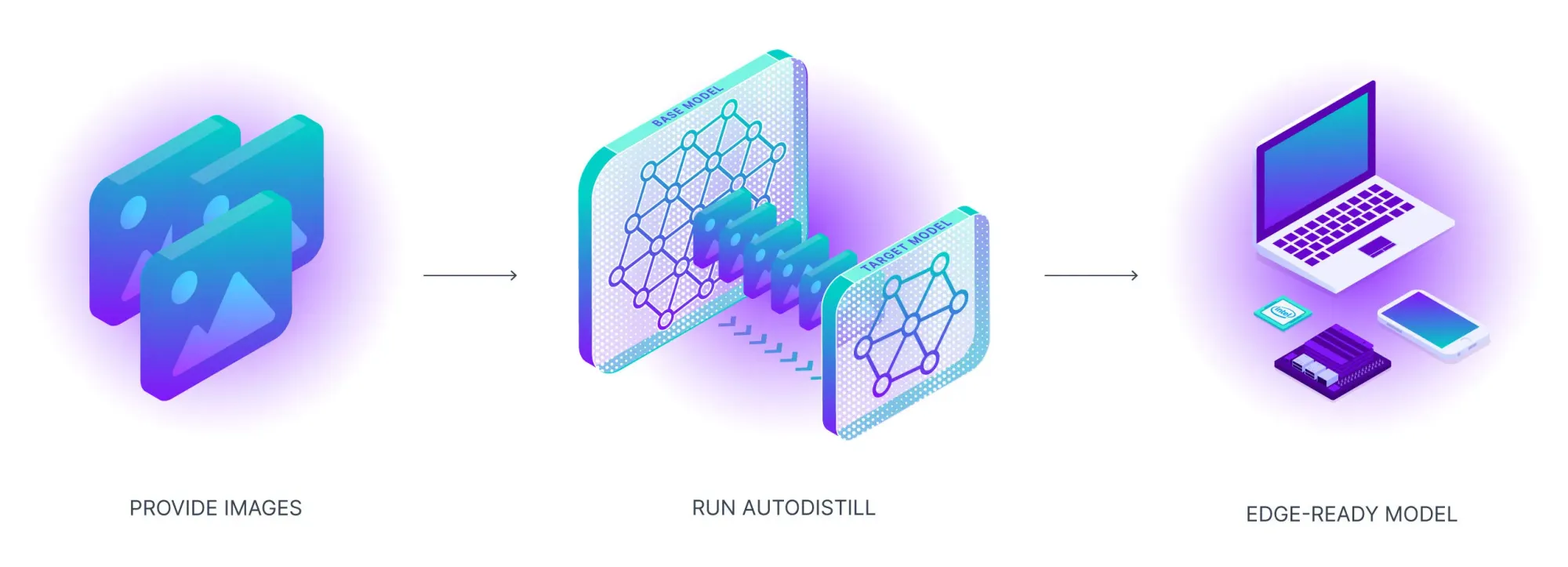
To get a mannequin into manufacturing utilizing Autodistill, all you could do is acquire photographs, describe what you need to detect, configure Autodistill inputs, after which prepare and deploy.
Think about a situation the place you need to construct a mannequin that detects autos. Utilizing Autodistill, you can ship photographs to a basis mannequin (i.e. Grounding DINO) with a immediate like “milk bottle” or “field” or “truck” to determine the autos you need to find in a picture. We name fashions like Grounding DINO that may annotate photographs “Base Fashions” in autodistill.
With the precise immediate, you may run the inspiration mannequin throughout your dataset, offering you with a set of auto-labeled photographs. Autodistill gives a Python technique for declaring prompts (“Ontologies”); you may modify your ontology to experiment with totally different prompts and discover the precise one to extract the right information out of your basis mannequin.
On this setup, you don’t should do any labeling, thus saving time on attending to the primary model of your laptop imaginative and prescient mannequin.
Subsequent, you need to use the photographs to coach a brand new car mannequin, utilizing an structure comparable to YOLOv8. We refer to those supervised fashions as “Goal Fashions” in autodistill. This new mannequin will study from the car annotations made by Grounding DINO. On the finish, you’ll have a smaller mannequin that identifies milk containers and may run at excessive FPS on a wide range of units.
Autodistill Use Instances and Greatest Practices
You need to use Autodistill to create the primary model of your mannequin with out having to label any information (though there are limitations, which might be mentioned on the finish of this part). This lets you get to a mannequin with which you’ll be able to experiment sooner than ever.
Since Autodistill labels photographs you’ve got specified, you’ve got full visibility into the information used to coach your mannequin. This isn’t current in most giant fashions, the place coaching datasets are personal. By having perception into coaching information used, you may debug mannequin efficiency extra effectively and perceive the information modifications you could make to enhance the accuracy of mannequin predictions.
Automated labeling with Autodistill may allow you to label hundreds of photographs, after which add people within the loop for courses the place your basis mannequin is much less performant. You may scale back labeling prices by no matter proportion of your information Autodistill can label.
With that mentioned, there are limitations to the bottom fashions supported on the time of writing. First, base fashions could not be capable to determine each class that you simply need to determine. For extra obscure or nuanced objects, base fashions could not but be capable to determine the objects you could annotate (or could take intensive experimentation to search out the perfect prompts).
Second, we now have discovered that many zero-shot fashions that you need to use for automated labeling battle to accurately annotate courses whose labels are utilized in comparable contexts in pure language (i.e. distinguishing “paper cup” vs “plastic cup”).
We count on efficiency to enhance as new basis fashions are created and launched and have constructed Autodistill as a framework the place future fashions can simply be slotted in. We’ve seen wonderful outcomes inside frequent domains and encourage you to see in case your use case is the precise match for Autodistill. The open supply CVevals challenge is a great tool for evaluating base fashions and prompts
Practice a Pc Imaginative and prescient Mannequin with No Labeling (Milk Detection Instance)
On this information, we’re going to create a milk container detection mannequin utilizing Autodistill. One of the best half? We’ll prepare a mannequin with no labeling course of. We are going to use Autodistill and a base mannequin, Grounded SAM, to label photographs routinely in accordance with a immediate.
Our milk container detection mannequin might be utilized by a meals producer to depend liquid bottles going by way of an meeting line, determine bottles with out caps, and depend bottles that enter the packing line.
To construct our mannequin, we’ll:
- Set up and configure Autodistill;
- Annotate milk containers in photographs utilizing a base mannequin (Grounded SAM);
- Practice a brand new goal mannequin (on this instance, YOLOv8) utilizing the annotated photographs, and;
- Check the brand new mannequin.
We’ve got ready an accompanying pocket book that you need to use to comply with together with this part. We advocate writing the code on this information in a pocket book surroundings (i.e. Google Colab).
Step 1: Set up Autodistill
First, we have to set up Autodistill and the required dependencies. Autodistill packages every mannequin individually, so we additionally want to put in the Autodistill packages that correspond with the fashions we plan to make use of. On this information, we’ll be utilizing Grounded SAM – a base mannequin that mixes Grounding DINO and the Phase Something Mannequin – and YOLOv8.
Let’s set up the dependencies we want:
pip set up -q autodistill autodistill-grounded-sam autodistill-yolov8 supervisionOn this instance, we’re going to annotate a dataset of milk bottles to be used in coaching a mannequin. To obtain the dataset, use the next instructions:
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=obtain&affirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=obtain&id=1wnW7v6UTJZTAcOQj0416ZbQF8b7yO6Pt' -O- | sed -rn 's/.*affirm=([0-9A-Za-z_]+).*/1n/p')&id=1wnW7v6UTJZTAcOQj0416ZbQF8b7yO6Pt" -O milk.zip && rm -rf /tmp/cookies.txt
!unzip milk.zipYou need to use any dataset you’ve got with autodistill!
Step 2: Annotate Milk Bottles in Photographs with Grounded SAM
We’re going to use Grounded SAM to annotate milk bottles in our photographs. Grounded SAM makes use of SAM to generate segmentation masks for elements in a picture and Grounding DINO to label the contents of a masks. Given a textual content immediate (i.e. “milk bottle”) the mannequin will return bounding bins across the cases of every recognized object.
Our dataset incorporates movies of milk bottles on a manufacturing line. We are able to divide the movies into frames utilizing supervision, a Python bundle that gives useful utilities to be used in constructing laptop imaginative and prescient functions.
If you have already got a folder of photographs, you may skip this step. However, you may nonetheless have to set a variable that information the place the photographs are that you simply need to use to coach your mannequin:
IMAGE_DIR_PATH = f"{HOME}/photographs"To create an inventory of video frames to be used with coaching our mannequin, we are able to use the next code:
import supervision as sv
from tqdm.pocket book import tqdm VIDEO_DIR_PATH = f"{HOME}/movies"
IMAGE_DIR_PATH = f"{HOME}/photographs" video_paths = sv.list_files_with_extensions( listing=VIDEO_DIR_PATH, extensions=["mov", "mp4"]) TEST_VIDEO_PATHS, TRAIN_VIDEO_PATHS = video_paths[:2], video_paths[2:] for video_path in tqdm(TRAIN_VIDEO_PATHS): video_name = video_path.stem image_name_pattern = video_name + "-{:05d}.png" with sv.ImageSink(target_dir_path=IMAGE_DIR_PATH, image_name_pattern=image_name_pattern) as sink: for picture in sv.get_video_frames_generator(source_path=str(video_path), stride=FRAME_STRIDE): sink.save_image(picture=picture)Right here is an instance body from a video:

To inform Grounded SAM we need to annotate milk containers, we have to create an ontology. This ontology is a structured illustration that maps our prompts to the category names we need to use:
ontology = CaptionOntology({ "milk bottle": "bottle", "blue cap": "cap"
}) base_model = GroundedSAM(ontology=ontology)Once we first run this code, Grounding DINO and SAM might be put in and configured on our system.
Within the code above, we create an ontology that maps class names to immediate. The Grounded SAM base mannequin might be given the prompts “milk bottle” and “blue cap”. Our code will return any occasion of “milk bottle” as “bottle” and “blue cap” as “cap”.
We now have a base mannequin by way of which we are able to annotate photographs.
We are able to strive a immediate on a single picture utilizing the predict() technique:
detections = base_model.predict("picture.png")This technique returns an object with info on the bounding field coordinates returned by the mannequin. We are able to plot the bounding bins on the picture utilizing the next code:
import supervision as sv picture = cv2.imread(test_image) courses = ["milk bottle", "blue cap"] detections = base_model.predict(test_image) box_annotator = sv.BoxAnnotator() labels = [f"{classes[class_id]} {confidence:0.2f}" for _, _, confidence, class_id, _ in detections] annotated_frame = box_annotator.annotate(scene=picture.copy(), detections=detections, labels=labels) sv.plot_image(annotated_frame)If the returned bounding bins usually are not correct, you may experiment with totally different prompts to see which one returns outcomes nearer to your required final result.
To annotate a folder of photographs, we are able to use this code:
DATASET_DIR_PATH = f"{HOME}/dataset" dataset = base_model.label( input_folder=IMAGE_DIR_PATH, extension=".png", output_folder=DATASET_DIR_PATH)This line of code will run our base mannequin on each picture with the extension .png in our picture folder and save the prediction outcomes right into a folder referred to as dataset.
Step 3: Practice a New Mannequin Utilizing the Annotated Photographs
Now that we now have labeled our photographs, we are able to prepare a brand new mannequin fine-tuned to our use case. On this instance, we’ll prepare a YOLOv8 mannequin.
Within the following code, we’ll:
- Import the YOLOv8 Autodistill loader;
- Load the pre-trained YOLOv8 weights;
- Practice a mannequin utilizing our labeled context photographs for 200 epochs, and;
- Export our weights for future reference.
from autodistill_yolov8 import YOLOv8 target_model = YOLOv8("yolov8n.pt")
target_model.prepare(DATA_YAML_PATH, epochs=50)To judge our mannequin, we are able to use the next code (YOLOv8 solely; different fashions will doubtless have other ways of accessing mannequin analysis metrics):
from IPython.show import Picture Picture(filename=f'{HOME}/runs/detect/prepare/confusion_matrix.png', width=600)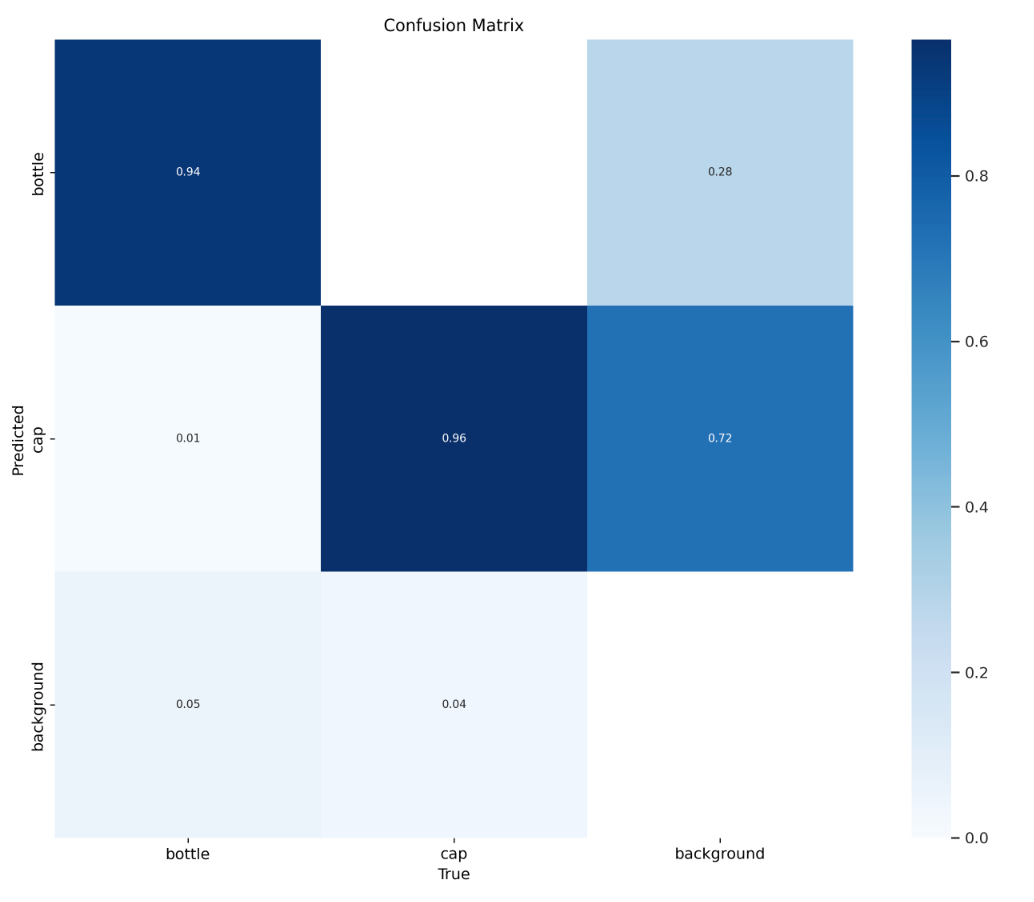
To see instance predictions for photographs within the validation dataset, run this code (YOLOv8 solely; different fashions will doubtless have other ways of accessing mannequin analysis metrics):
Picture(filename=f'{HOME}/runs/detect/prepare/val_batch0_pred.jpg', width=600)
Step 4: Check the Mannequin
We now have a skilled mannequin that we are able to check. Let’s check the mannequin on photographs in our dataset:
SAMPLE_SIZE = eight image_names = record(dataset.photographs.keys())[:SAMPLE_SIZE] mask_annotator = sv.MaskAnnotator()
box_annotator = sv.BoxAnnotator() photographs = []
for image_name in image_names: picture = dataset.photographs[image_name] annotations = dataset.annotations[image_name] labels = [ dataset.classes[class_id] for class_id in annotations.class_id] annotates_image = mask_annotator.annotate( scene=picture.copy(), detections=annotations) annotates_image = box_annotator.annotate( scene=annotates_image, detections=annotations, labels=labels) photographs.append(annotates_image) sv.plot_images_grid( photographs=photographs, titles=image_names, grid_size=SAMPLE_GRID_SIZE, measurement=SAMPLE_PLOT_SIZE) On this code, we use supervision to course of predictions for eight photographs in our dataset, and plot the entire predictions onto every picture in a grid fashion:

Our mannequin is ready to efficiently determine numerous bottles and bottle caps.
Right here is an instance of our new mannequin operating on a video:
We now have a small laptop imaginative and prescient mannequin that we are able to deploy to the sting, constructed with full visibility into the information on which the mannequin is skilled.
From right here, we are able to:
- Run our mannequin on a Luxonis OAK, NVIDIA Jetson, webcam, in a Python script, or utilizing one other supported Roboflow deployment goal;
- Analyze our analysis metrics to plan what we are able to do to enhance our mannequin, and;
- Begin gathering extra information to make use of within the subsequent model of the mannequin.
Deploy the Mannequin to Roboflow
You may add your skilled mannequin on to Roboflow for deployment on the sting. We presently help importing weights for the next Goal Fashions:
- YOLOv5 Object Detection
- YOLOv5 Occasion Segmentation
- YOLOv8 Object Detection
- YOLOv8 Picture Segmentation
- YOLOv8 Classification
- YOLOv7 Occasion Segmentation
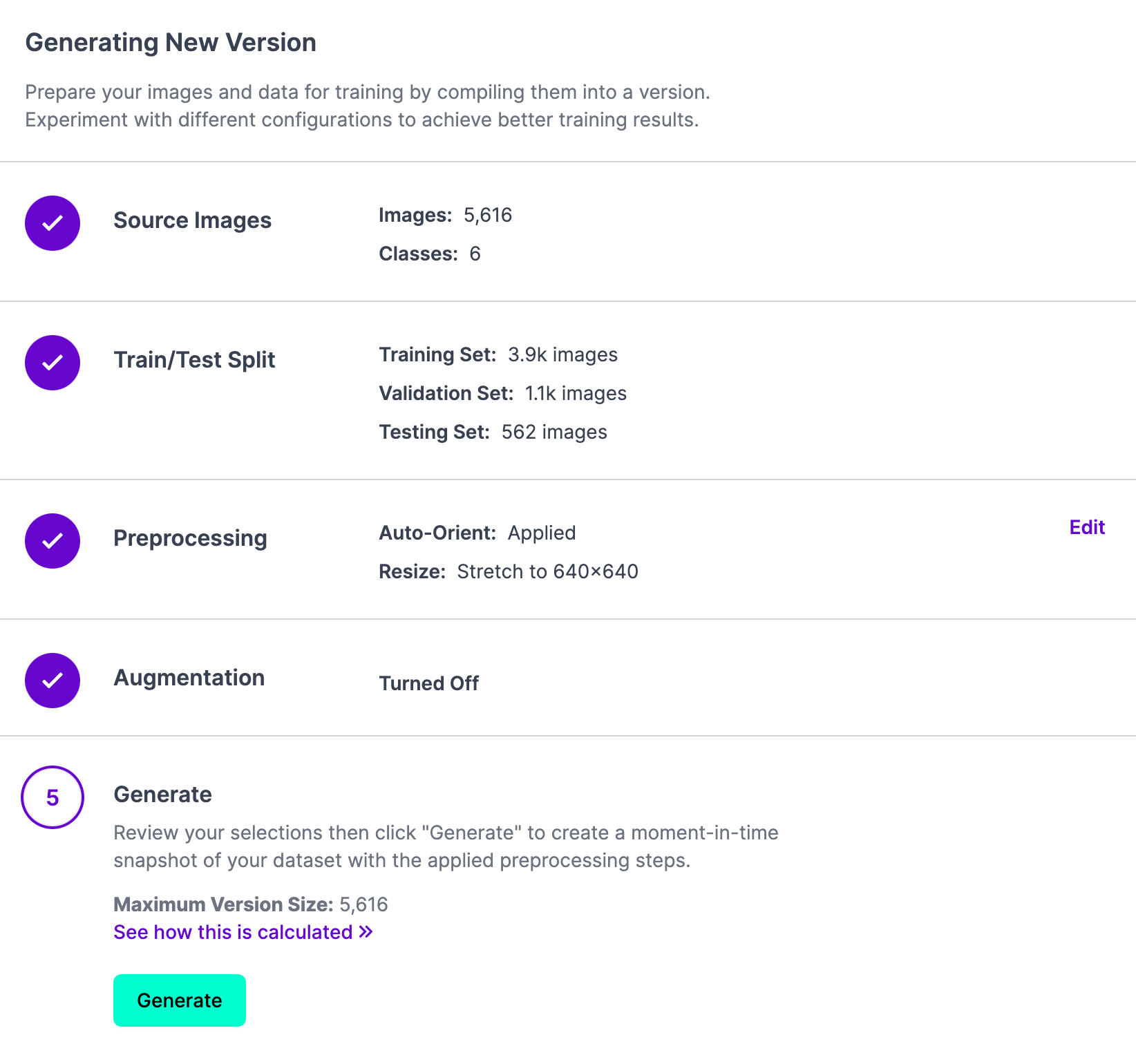
To take action, first create a brand new challenge in Roboflow and add the information on which your mannequin was skilled. Then, click on “Generate” within the Roboflow dashboard to create a brand new challenge model with which you’ll connect your weights:
Subsequent, run the next instructions to deploy your mannequin to Roboflow:
from roboflow import Roboflow rf = Roboflow(api_key="API_KEY") challenge = rf.workspace().challenge("PROJECT_ID") challenge.model(DATASET_VERSION).deploy(model_type=”yolov8”, model_path=f”{HOME}/runs/detect/prepare/”)Subtitute the API key, challenge ID, and dataset model with the variations related together with your challenge. We’ve got a information on tips on how to discover these values in our documentation.
After you add your weights, Roboflow will create a hosted mannequin you may question, out there to be used by way of our API, Python bundle, and different SDKs.
Autodistill has enabled us to construct the primary model of a mannequin that detects containers that we are able to use as a robust basis towards constructing a mannequin exactly tuned for our use case.
Conclusion
Autodistill permits you to use a big imaginative and prescient mannequin to coach a smaller mannequin fine-tuned to your use case. This new mannequin might be smaller and sooner, which is right for deployment.
You’ll have full visibility into the coaching information used for the mannequin. Which means you’ve got the knowledge you could examine mannequin efficiency and perceive why your mannequin performs in the way in which that it does and add new information to enhance mannequin efficiency.
As extra foundational fashions are launched, we’ll add new base and goal fashions so that you could use the very best out there open supply expertise with Autodistill. We welcome contributions so as to add new base and goal fashions, too!
If you want to assist us add new fashions to Autodistill, go away an Concern on the challenge GitHub repository. We’ll advise if there may be already work happening so as to add a mannequin. If no work has began, you may add a brand new mannequin from scratch; if a contributor is already including a mannequin, we are able to level you to the place you may assist. Try the challenge contribution tips for extra info.


