Autodistill is an open-source ecosystem of instruments for distilling the information from giant, basic pc imaginative and prescient fashions (i.e. Phase Something (SAM)) into smaller fashions (i.e. YOLOv8). These smaller fashions are extra appropriate for edge deployment, providing higher efficiency when it comes to inference time and compute constraints.
Autodistill takes in a folder of photos related to your challenge, routinely labels them utilizing a big, basic mannequin (referred to as a “base mannequin”), and makes use of these photos to coach a goal mannequin. To inform Autodistill the right way to label photos in your challenge, that you must specify a immediate that can instruct the bottom mannequin on what to annotate.
However what immediate will work finest in your use case? How are you aware if in case you have chosen the correct immediate? These are key questions, particularly if you happen to plan to label tons of or 1000’s of photos to be used along with your mannequin. You don’t need to label a thousand photos with Autodistill and discover your immediate didn’t label your information precisely.
On this information, we’re going to present the right way to use the open supply CV evals framework to judge prompts to be used with Autodistill. With out additional ado, let’s get began!
Step 1: Set up Autodistill and CVevals
On this information, we’re going to make use of Grounded SAM, a mixture of Grounding DINO and the Phase Something Mannequin (SAM), as our base mannequin with Autodistill. We’ll distill information from Grounded SAM right into a smaller mannequin.
First, we have to set up Autodistill and the related base mannequin bundle, autodistill-grounded-sam:
pip set up autodistill autodistill-grounded-samSubsequent, we have to set up CVevals, the framework we are going to use for evaluating completely different prompts to be used with Autodistill:
git clone https://github.com/roboflow/cvevals
cd cvevals
pip set up -e .CVevals is a standalone utility bundled with a set of starter scripts to be used with evaluating prompts. All starter scripts are within the examples/ listing. On this information, we’ll use the examples/grounding_dino_compare.py evaluator to be used with Autodistill.
We’ll additionally want to put in Grounding DINO for this instance. Run the next instructions within the root cvevals folder:
git clone https://github.com/IDEA-Analysis/GroundingDINO.git
cd GroundingDINO/ pip3 set up -r necessities.txt
pip3 set up -e . mkdir weights
cd weights wget https://github.com/IDEA-Analysis/GroundingDINO/releases/obtain/v0.1.0-alpha/groundingdino_swint_ogc.pth
Step 2: Put together Information for Analysis
On this information, we’re going to use Autodistill to construct a mannequin that identifies delivery containers. We’ve got ready a dataset of delivery containers to be used with coaching the mannequin.
To judge prompts, we want each predictions from our goal mannequin – on this case, Grounded SAM, which makes use of Grounding DINO – and floor reality information from annotations we’ve got made. The predictions from the goal mannequin are in contrast towards the bottom reality information to determine how correct the goal mannequin was at annotating photos in your dataset.
Earlier than we are able to consider prompts for our delivery container mannequin, we want some floor reality information. First, create a challenge in Roboflow:
Then, add ~10-20 photos which are consultant of the pictures you need to label with Autodistill.
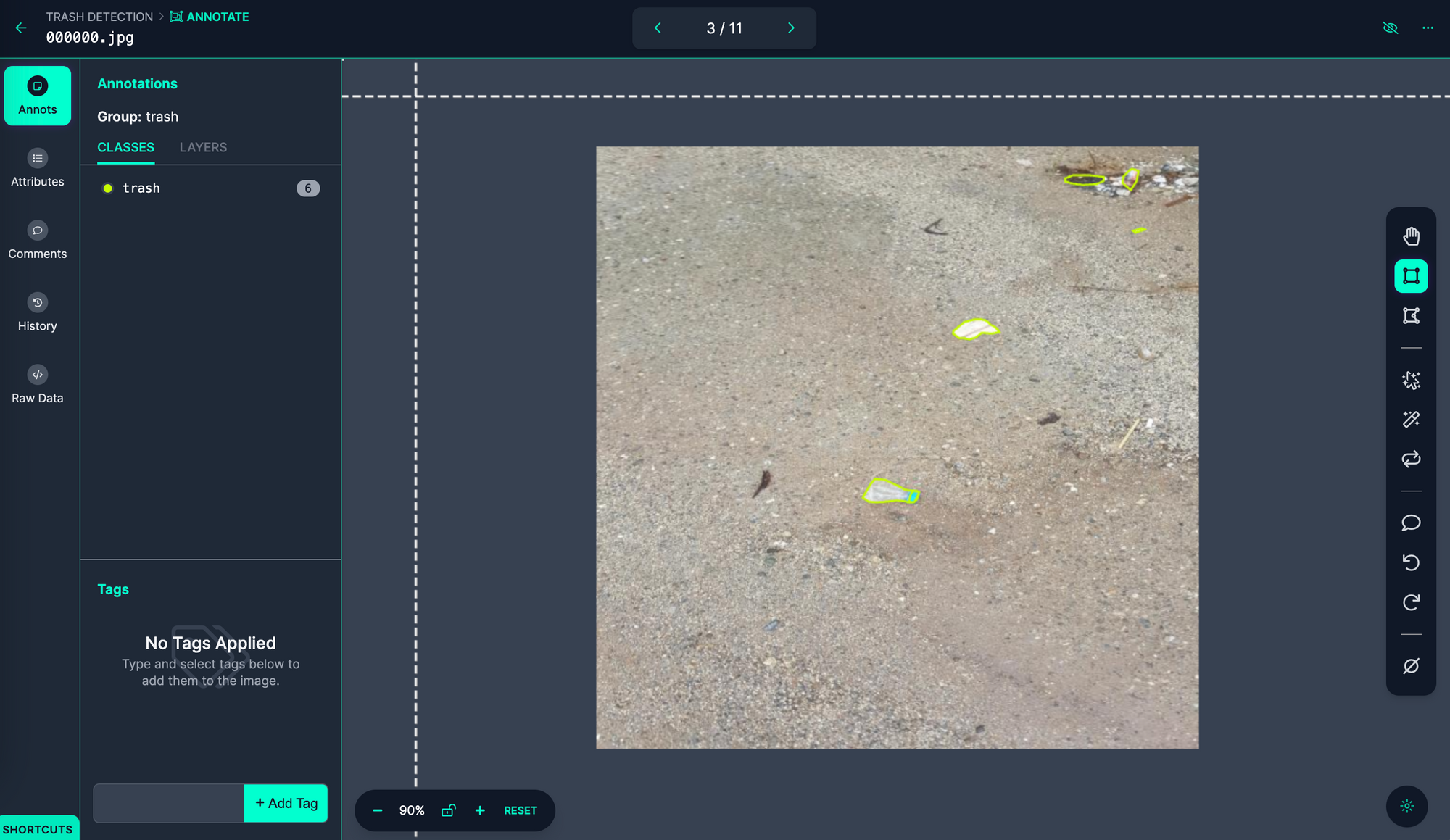
Utilizing Roboflow Annotate, create annotations in your dataset:
When approving your photos for inclusion in a dataset, be sure you add all photos to your Coaching Set:
When you’ve got annotated your photos, click on “Generate” within the sidebar of the Roboflow platform and create a model with your entire annotated photos:
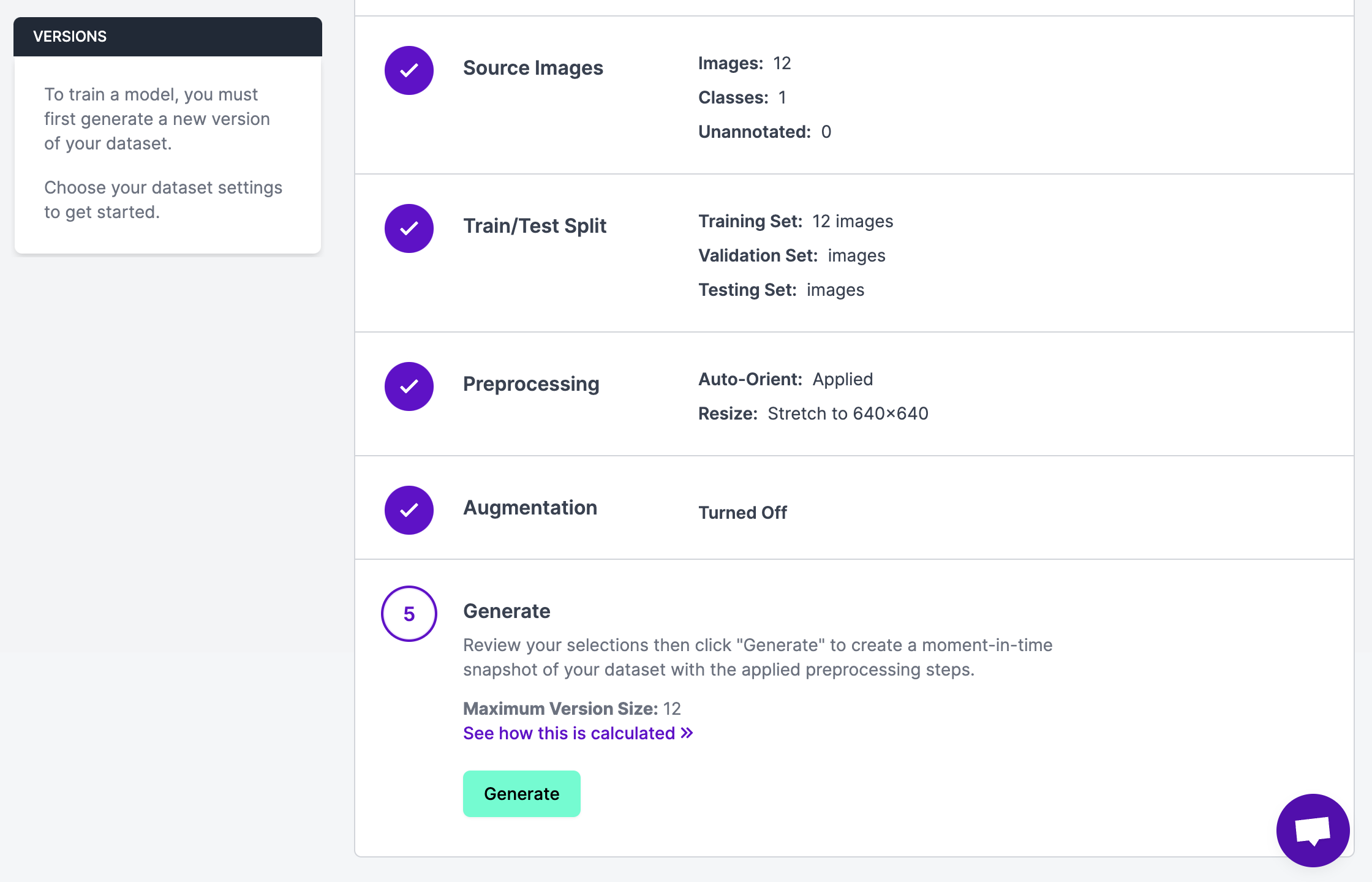
We at the moment are prepared to check completely different prompts to be used with Autodistill.
Step 3: Consider Base Mannequin Prompts
The entire CVevals scripts settle for Roboflow datasets as an enter. To set prompts, open up the examples/grounding_dino_compare.py file (or no matter instance file from which you’re working) and exchange the prompts within the `evals` record with an inventory of prompts you need to check.
The entire comparability scripts that work with Autodistill have a normal API so the code on this part is relevant irrespective of the bottom mannequin with which you’re working.
Listed here are the prompts we’ll check on this instance:
trashgarbagewaste
Let’s edit the evals record in our examples/grounding_dino_compare.py file:
evals = [ {"classes": [{"ground_truth": "trash", "inference": "trash"}], "confidence": 0.5}, {"courses": [{"ground_truth": "trash", "inference": "rubbish"}], "confidence": 0.5}, {"courses": [{"ground_truth": "trash", "inference": "waste"}], "confidence": 0.5},
]“floor reality” is the label we gave every bit of trash in our annotation. In the event you used one other floor reality label, exchange the worth as acceptable. inference is what might be handed to the underlying mannequin.
With this code prepared, we are able to run our analysis script. You will want your Roboflow workspace and mannequin IDs, model quantity, and API key. To learn to retrieve these values, confer with the Roboflow documentation.
Let’s run the analysis script:
python3 examples/dino_compare_example.py --eval_data_path=./images1 --roboflow_workspace_url=james-gallagher-87fuq --roboflow_project_url=trash-detection-2xndh --roboflow_model_version=1 --config_path=./GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py --weights_path=./GroundingDINO/weights/groundingdino_swint_ogc.pthThis script will take a couple of minutes to run relying on whether or not you’re engaged on a CPU or GPU and what number of photos you need to label. On the finish, a desk will seem exhibiting the outcomes of the analysis. By default, evaluations are ordered by f1 rating.
Listed here are the outcomes from our trash analysis:

From this code, we are able to see that “trash” is the very best immediate for labeling our information. We are able to now cross that immediate by way of Autodistill to label our information.
Step 4: Run the Base Mannequin
For our Grounding SAM instance, we are able to run our base mannequin utilizing the next code:
base_model = GroundedSAM(ontology=CaptionOntology({"trash": "trash"}))
base_model.label("./context_images", extension=".jpeg")On this code, we map the immediate “trash” to “trash”. “trash” is handed to the bottom mannequin, and all containers are labeled as “trash”. Whereas the immediate and label are the identical, these can be completely different if one other immediate had been more practical (i.e. a immediate could also be “garbage” and the label may very well be “trash”).
We then begin the labeling course of.
We are able to use the labeled photos to coach a goal mannequin. For extra info on the right way to practice a goal mannequin, try the goal mannequin part of our Autodistill information, or confer with the Autodistill documentation.
Conclusion
On this information, we’ve got demonstrated the right way to use CVevals to judge prompts to be used with Autodistill. We arrange Autodistill and CVevals, in contrast the efficiency of three completely different prompts on a dataset of 20 photos, then used the very best immediate to label the remainder of our dataset.
Now you’ve got the instruments that you must discover essentially the most optimum immediate to be used with Autodistill.


