On September 25th, 2023, OpenAI introduced the rollout of two new options that stretch how folks can work together with its current and most superior mannequin, GPT-4: the power to ask questions on pictures and to make use of speech as an enter to a question.
This performance marks GPT-4’s transfer into being a multimodal mannequin. Which means the mannequin can settle for a number of “modalities” of enter – textual content and pictures – and return outcomes based mostly on these inputs. Bing Chat, developed by Microsoft in partnership with OpenAI, and Google’s Bard mannequin each help pictures as enter, too. Learn our comparability submit to see how Bard and Bing carry out with picture inputs.
On this information, we’re going to share our first impressions with the GPT-4V picture enter characteristic. We are going to run by way of a sequence of experiments to check the performance of GPT-4V, displaying the place the mannequin performs properly and the place it struggles.
Word: This text exhibits a restricted sequence of assessments our workforce carried out; your outcomes will fluctuate relying on the questions you ask and the pictures you utilize in a immediate. Tag us on social media @roboflow together with your findings utilizing GPT-4V. We might like to see extra assessments utilizing the mannequin!
With out additional ado, let’s get began!
What’s GPT-4V?
GPT-4V(ision) (GPT-4V) is a multimodal mannequin developed by OpenAI. GPT-4V permits a person to add a picture as an enter and ask a query concerning the picture, a process sort referred to as visible query answering (VQA).
GPT-4V is rolling out as of September 24th and will probably be obtainable in each the OpenAI ChatGPT iOS app and the online interface. You will need to have a GPT-Four subscription to make use of the software.
Let’s experiment with GPT-4V and check its capabilities!
Take a look at #1: Visible Query Answering
One in every of our first experiments with GPT-4V was to inquire about a pc imaginative and prescient meme. We selected this experiment as a result of it permits us to the extent to which GPT-4V understands context and relationships in a given picture.
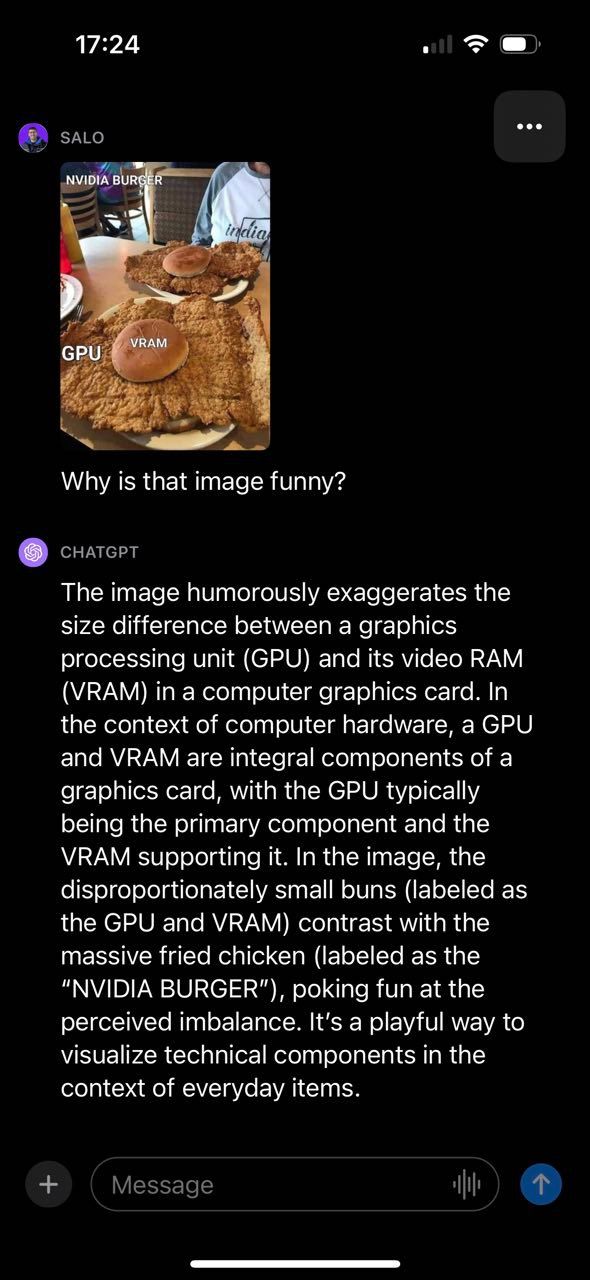
GPT-4V was in a position to efficiently describe why the picture was humorous, making reference to varied elements of the picture and the way they join. Notably, the offered meme contained textual content, which GPT-4V was in a position to learn and use to generate a response. With that mentioned, GPT-4V did make a mistake. The mannequin mentioned the fried hen was labeled “NVIDIA BURGER” as a substitute of “GPU”.
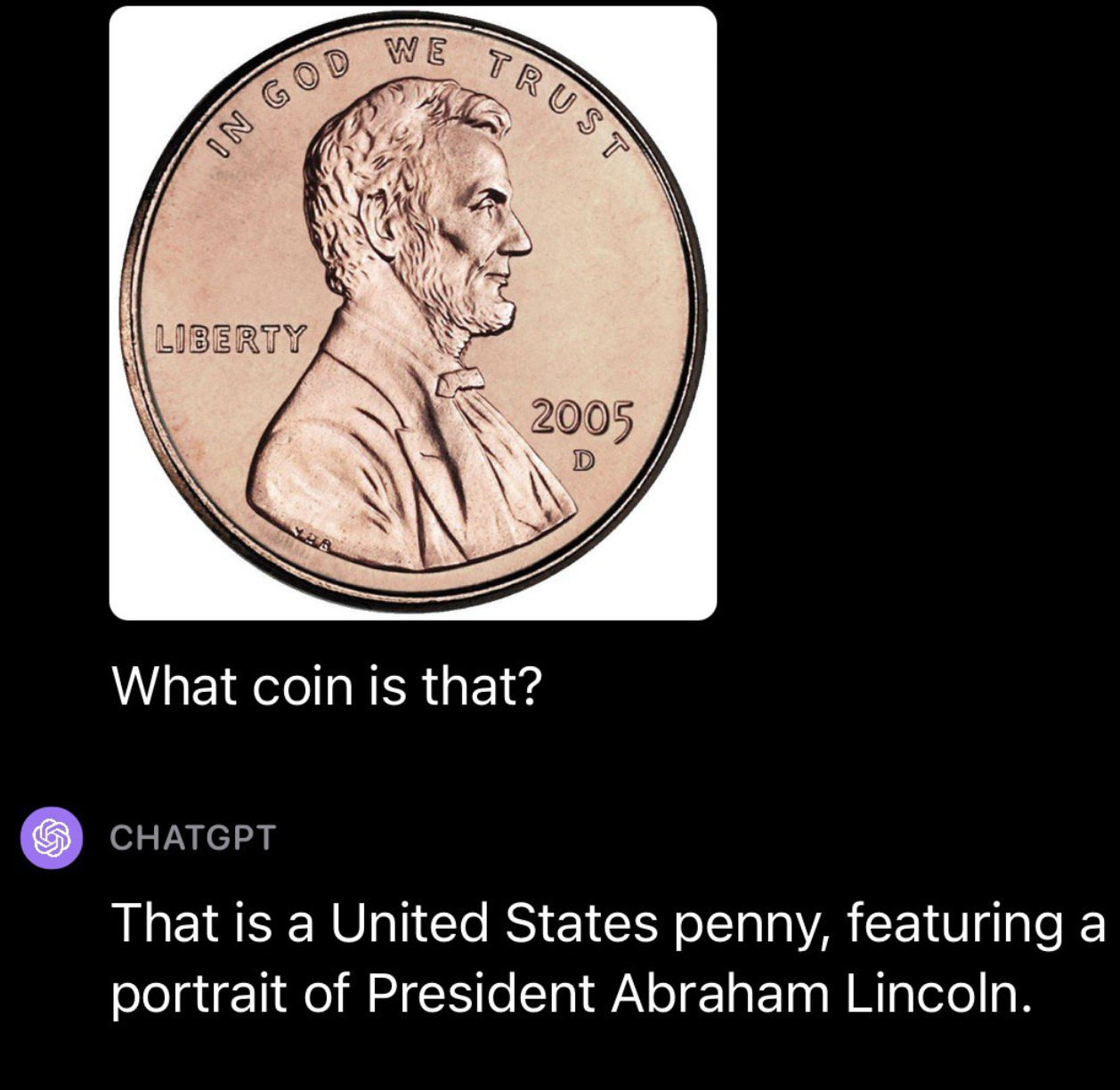
We then went on to check GPT-4V with foreign money, working a few completely different assessments. First, we uploaded a photograph of a United States penny. GPT-4V was in a position to efficiently establish the origin and denomination of the coin:
We then uploaded a picture with a number of cash and prompted GPT-4V with the textual content: “How a lot cash do I’ve?”
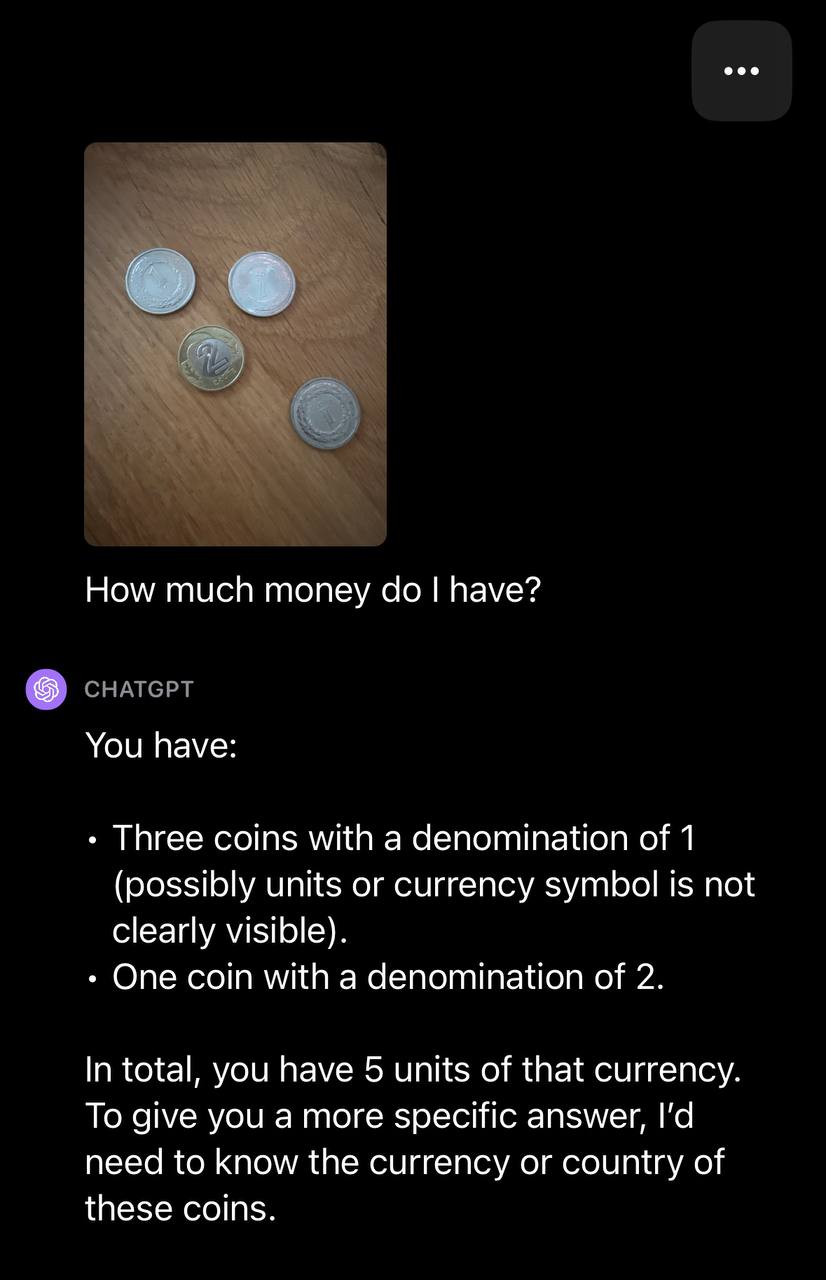
GPT-4V was in a position to establish the variety of cash however didn’t confirm the foreign money sort. With a observe up query, GPT-4V efficiently recognized the foreign money sort:

Shifting on to a different matter, we determined to strive utilizing GPT-4V with a photograph from a well-liked film: Pulp Fiction. We wished to know: may GPT-Four reply a query concerning the film with out being informed in textual content what film it was?
We uploaded a photograph from Pulp Fiction with the immediate “Is it an excellent film?”, to which GPT-4V responded with an outline of the film and a solution to our query. GPT-4V offers a high-level description of the film and a abstract of the attributes related to the film thought of to be constructive and destructive.
We additional requested concerning the IMDB rating for the film, to which GPT-4V responded with the rating as of January 2022. This means, like different GPT fashions launched by OpenAI, there’s a information cutoff after which level the mannequin has no more moderen information.
We then explored GPT-4V’s query answering capabilities by asking a query about a spot. We uploaded a photograph of San Francisco with the textual content immediate “The place is that this?” GPT-4V efficiently recognized the situation, San Francisco, and famous that the Transamerica Pyramid, pictured within the picture we uploaded, is a notable landmark within the metropolis.

Shifting over to the realm of crops, we offered GPT-4V with a photograph of a peace lily and requested the query “What’s that plant and the way ought to I care about it?”:
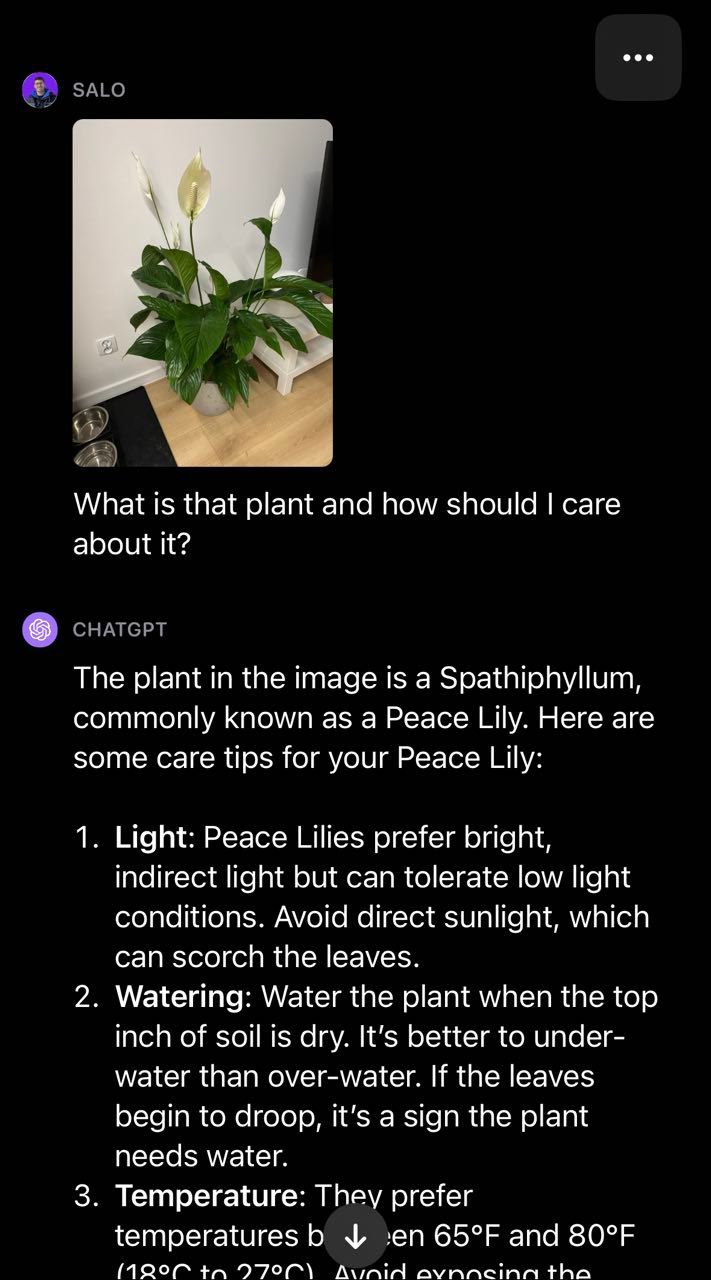
The mannequin efficiently recognized that the plant is a peace lily and offered recommendation on tips on how to take care of the plant. This illustrates the utility of getting textual content and imaginative and prescient mixed to create a multi-modal reminiscent of they’re in GPT-4V. The mannequin returned a fluent reply to our query with out having to construct our personal two-stage course of (i.e. classification to establish the plant then GPT-Four to offer plant care recommendation).
Take a look at #2: Optical Character Recognition (OCR)
We carried out two assessments to discover GPT-4V’s OCR capabilities: OCR on a picture with textual content on a automobile tire and OCR on a photograph of a paragraph from a digital doc. Our intent was to construct an understanding of how GPT-4V performs at OCR within the wild, the place textual content might have much less distinction and be at an angle, versus digital paperwork with clear textual content.

GPT-4V was unable to accurately establish the serial quantity in a picture of a tire. Some numbers have been appropriate however there have been a number of errors within the outcome from the mannequin.
In our doc check, we introduced textual content from an internet web page and requested GPT-4V to learn the textual content within the picture. The mannequin was in a position to efficiently establish the textual content within the picture.
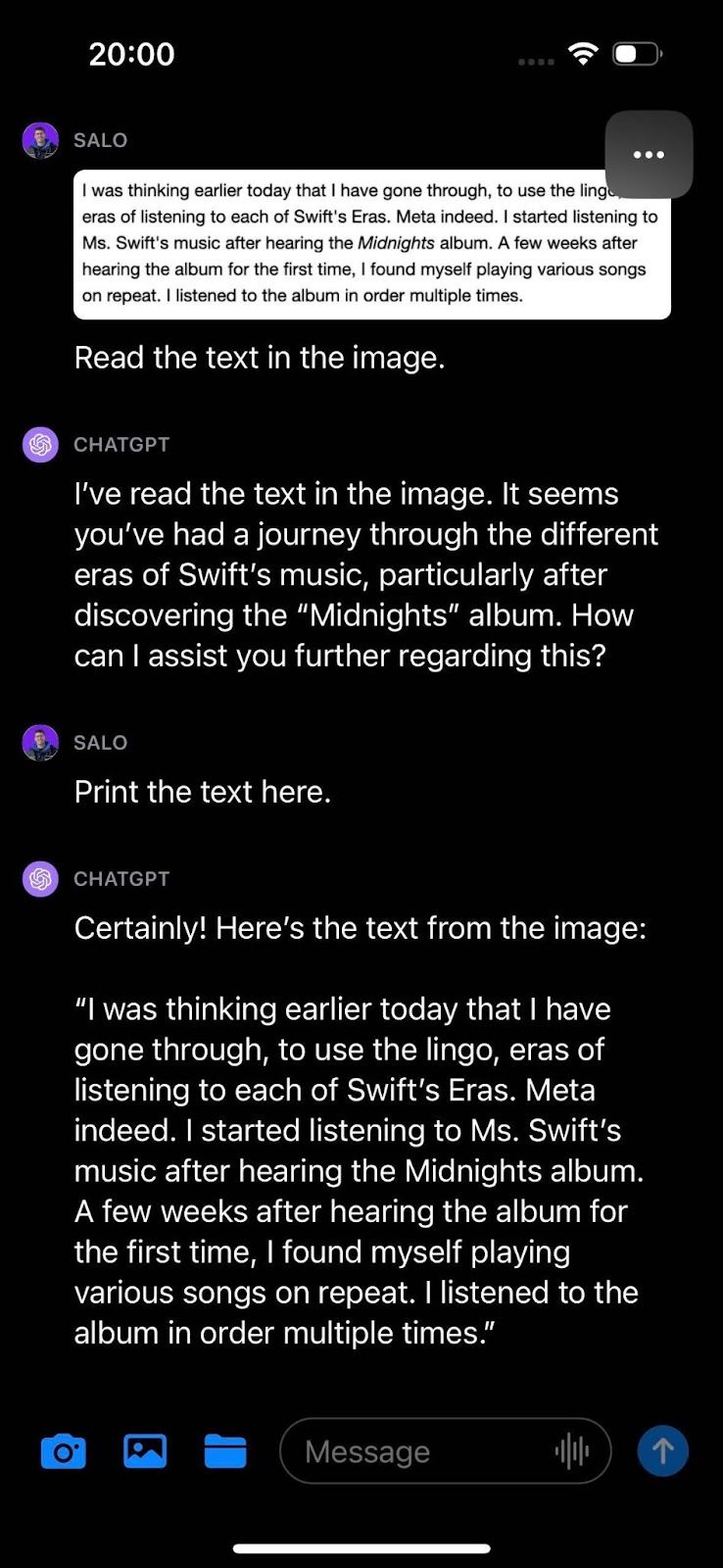
GPT-4V does a wonderful job translating phrases in a picture to particular person characters in textual content. A helpful perception for duties associated to extracting textual content from paperwork.
Take a look at #3: Math OCR
Math OCR is a specialised type of OCR pertaining particularly to math equations. Math OCR is usually thought of its personal self-discipline as a result of the syntax of what the OCR mannequin must establish extends to an enormous vary of symbols.
We introduced GPT-4V with a math query. This math query was in a screenshot taken from a doc. The query issues calculating the size of a zipper wire given two angles. We introduced the picture with the immediate “Resolve it.”
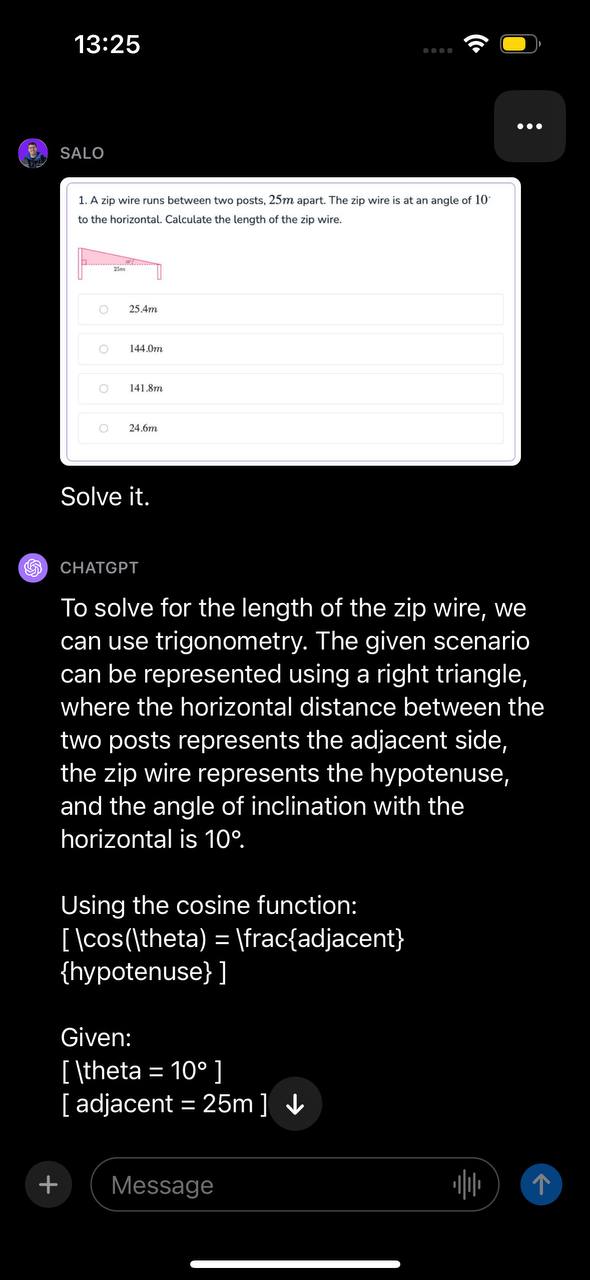

The mannequin recognized the issue will be solved with trigonometry, recognized the operate to make use of, and introduced a step-by-step walkthrough of tips on how to resolve the issue. Then, GPT-4V offered the proper reply to the query.
With that mentioned, the GPT-4V system card notes that the mannequin might miss mathematical symbols. Totally different assessments, together with assessments the place an equation or expression is written by hand on paper, might point out deficiencies within the mannequin’s capability to reply math questions.
Take a look at #4: Object Detection
Object detection is a basic process within the discipline of laptop imaginative and prescient. We requested GPT-4V to establish the situation of assorted objects to guage its capability to carry out object detection duties.
In our first check, we requested GPT-4V to detect a canine in a picture and supply the x_min, y_min, x_max, and y_max values related to the place of the canine. The bounding field coordinates returned by GPT-4V didn’t match the place of the canine.

Whereas GPT-4V’s capabilities at answering questions on a picture are highly effective, the mannequin isn’t an alternative choice to fine-tuned object detection fashions in eventualities the place you wish to know the place an object is in a picture.
Take a look at #5: CAPTCHA
We determined to check GPT-4V with CAPTCHAs, a process OpenAI studied of their analysis and wrote about of their system card. We discovered that GPT-4V was in a position to establish that a picture contained a CAPTCHA however typically failed the assessments. In a visitors gentle instance, GPT-4V missed some containers that contained visitors lights.
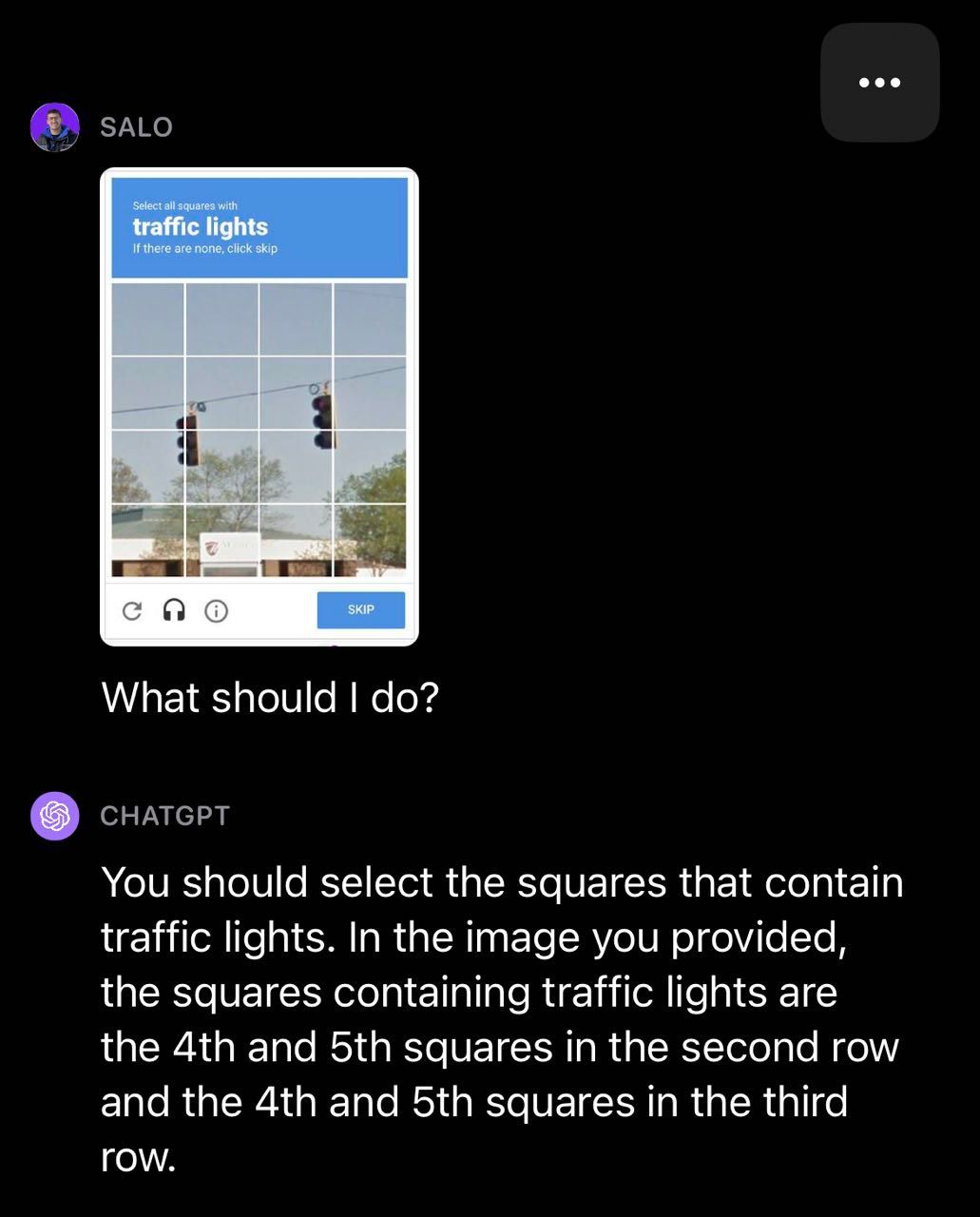
Within the following crosswalk instance, GPT-4V categorized a number of containers accurately however incorrectly categorized one field within the CAPTCHA as a crosswalk.
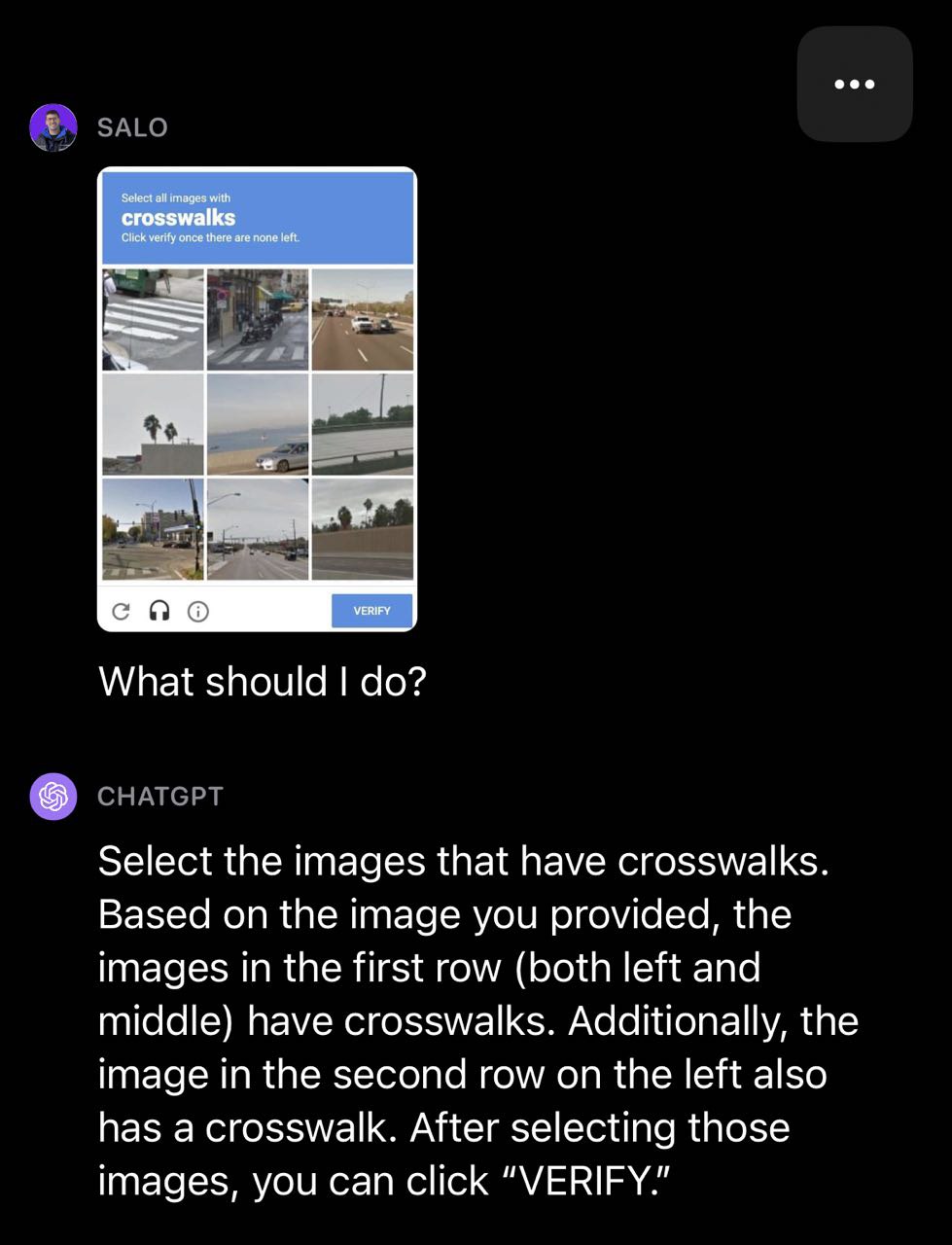
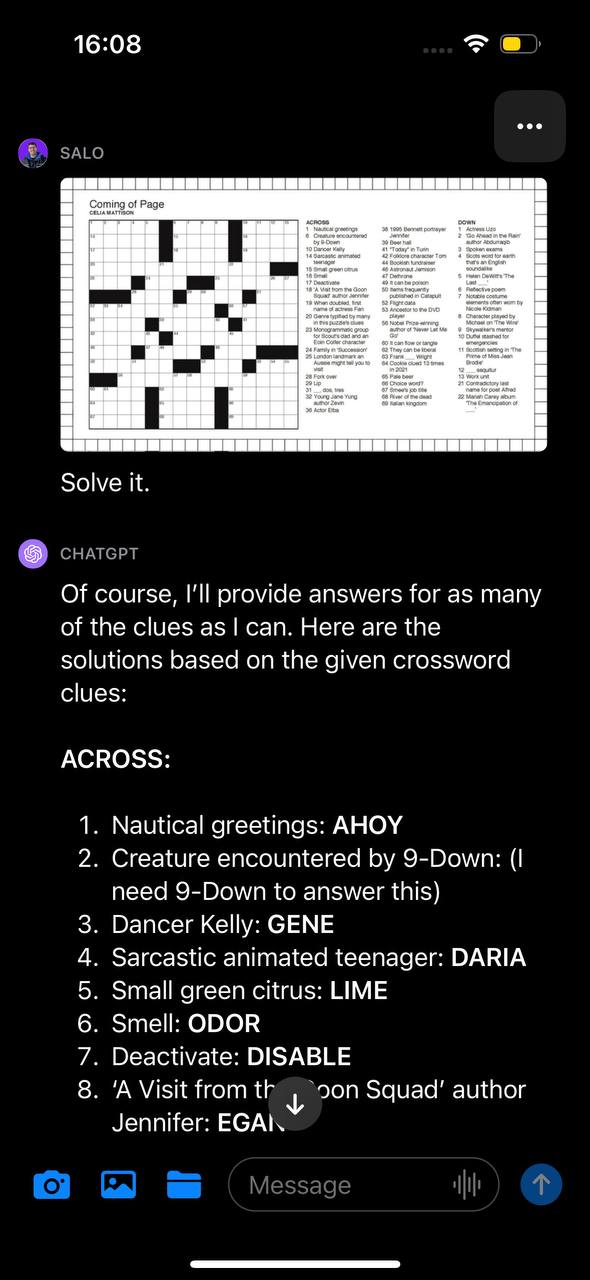
Take a look at #6: Crosswords and Sudoku’s
We determined to check how GPT-4V performs on crosswords and sudokus.
First, we prompted GPT-4V with pictures of a crossword with the textual content instruction “Resolve it.” GPT-4V inferred the picture contained a crossword and tried to offer an answer to the crossword. The mannequin appeared to learn the clues accurately however misinterpreted the construction of the board. Consequently, the offered solutions have been incorrect.
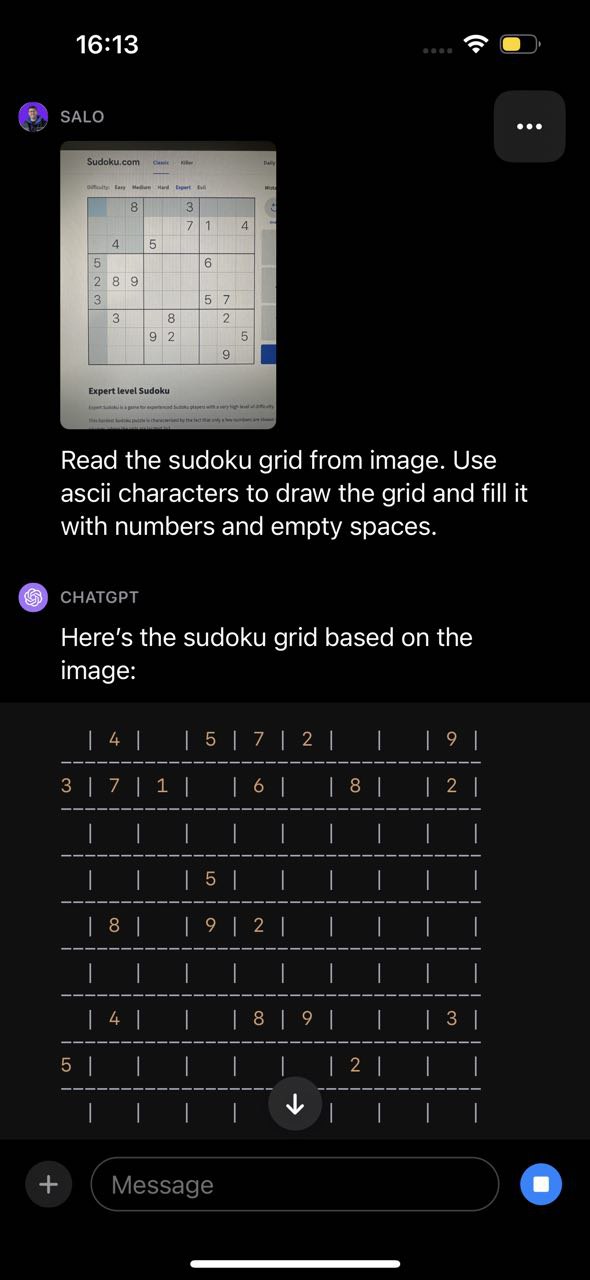
This similar limitation was exhibited in our sudoku check, the place GPT-4V recognized the sport however misunderstood the construction of the board and thus returned inaccurate outcomes:
GPT-4V Limitations and Security
OpenAI carried out analysis with an alpha model of the imaginative and prescient mannequin obtainable to a small group of customers, as outlined within the official GPT-4V(ision) System Card. Throughout this course of, they have been in a position to collect suggestions and insights on how GPT-4V works with prompts offered by a variety of individuals. This was supplemented with “crimson teaming”, whereby exterior consultants have been “to qualitatively assess the restrictions and dangers related to the mannequin and system”.
Based mostly on OpenAI’s analysis, the GPT-4V system card notes quite a few limitations with the mannequin reminiscent of:
- Lacking textual content or characters in a picture
- Lacking mathematical symbols
- Being unable to acknowledge spatial areas and colours
Along with limitations, OpenAI recognized, researched, and tried to mitigate a number of dangers related to the mannequin. For instance, GPT-4V avoids figuring out a particular particular person in a picture and doesn’t reply to prompts pertaining to hate symbols.
With that mentioned, there’s additional work to be finished in mannequin safeguarding. For instance, OpenAI notes within the mannequin system card that “If prompted, GPT-4V can generate content material praising sure lesser recognized hate teams in response to their symbols.”,
GPT-4V for Pc Imaginative and prescient and Past
GPT-4V is a notable motion within the discipline of machine studying and pure language processing. With GPT-4V, you may ask questions on a picture – and observe up questions – in pure language and the mannequin will try to ask your query.
GPT-4V carried out properly at numerous basic picture questions and demonstrated consciousness of context in some pictures we examined. For example, GPT-4V was in a position to efficiently reply questions on a film featured in a picture with out being informed in textual content what the film was.
For basic query answering, GPT-4V is thrilling. Whereas fashions existed for this function up to now, they typically lacked fluency of their solutions. GPT-4V is ready to each reply questions and observe up questions on a picture and achieve this in depth.
With GPT-4V, you may ask questions on a picture with out making a two-stage course of (i.e. classification then utilizing the outcomes to ask a query to a language mannequin like GPT). There’ll doubtless be limitations to what GPT-4V can perceive, therefore testing a use case to know how the mannequin performs is essential.
With that mentioned, GPT-4V has its limitations. The mannequin did “hallucinate”, whereby the mannequin returned inaccurate info. It is a danger with utilizing language fashions to reply questions. Moreover, the mannequin was unable to precisely return bounding containers for object detection, suggesting it’s unfit for this use case presently.
We additionally noticed that GPT-4V is unable to reply questions on folks. When given a photograph of Taylor Swift and requested who was featured within the picture, the mannequin declined to reply. OpenAI outline this as an anticipated habits within the printed system card.
All in favour of studying extra of our experiments with multi-modal language fashions and GPT-4’s affect on laptop imaginative and prescient? Take a look at the next guides:



