Introduction
When bettering an object detection mannequin, many engineers focus solely on tweaking the mannequin structure and hyperparameters. Nevertheless, the foundation reason behind mediocre efficiency usually lies within the information itself.
On this collaborative submit between Roboflow & Tenyks, we’ll present you ways a machine studying engineer tasked with bettering mannequin efficiency can accomplish this purpose by systematically figuring out and fixing dataset points.
On this submit, you’ll be taught the step-by-step course of you possibly can comply with to totally use Tenyks to audit and improve your Roboflow dataset, finally resulting in a lift in efficiency. By the top of this tutorial, you will see how mannequin efficiency elevated from 94% mAP to 97.6% mAP, and particular courses from 60% mAP to 77% mAP.
Undertaking Steps
- The Situation: You’re Tasked with Enhancing Mannequin Efficiency
- Coaching a Baseline: hHigh mAP Doesn’t All the time Imply Your Mannequin is Good
- Zooming In: Efficiency is Missing in Some Lessons
- Discovering Dataset Points
- Fixing Points to Enhance Dataset High quality
- Acquiring Greater Mannequin Efficiency with the Fastened Dataset
Let’s get began!
The Situation: You’re Tasked with Enhancing Mannequin Efficiency
Assume you’re a machine studying engineer who just lately joined a startup constructing self-driving automobile expertise. Say you’re assigned an object detection mannequin that identifies site visitors indicators in digicam footage. Nevertheless, your group is dissatisfied with the present mannequin’s accuracy, which is just too low to reliably detect objects in numerous real-world circumstances.
Throughout analysis, you discover the mannequin efficiency for some courses is under the minimal accuracy wanted for protected autonomous navigation. The mannequin steadily fails to detect small, or uncommon objects. It is usually inconsistent throughout totally different places.
Your first activity is boosting the article detector’s efficiency to fulfill the brink purpose. You could have heard many occasions the gospel that “a mannequin is just as robust as its coaching information”, proper? Think about you embark to carefully audit the dataset to determine alternatives for enchancment.
Okay, the place do you start? 😵
Coaching a Baseline: Excessive mAP Doesn’t All the time Imply Your Mannequin is Good
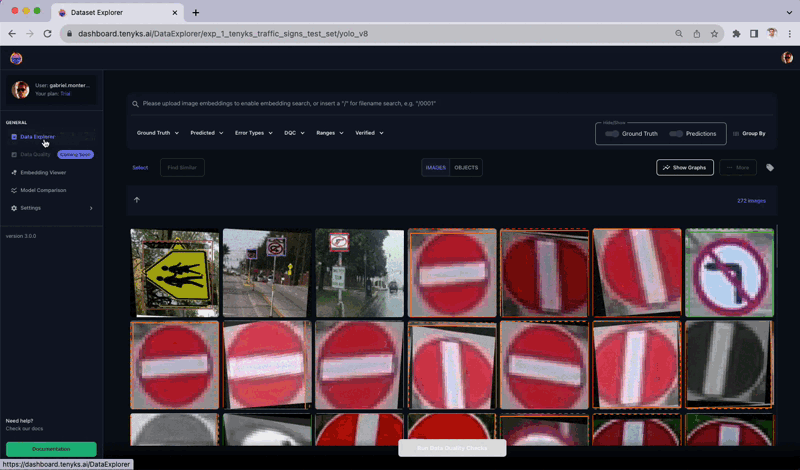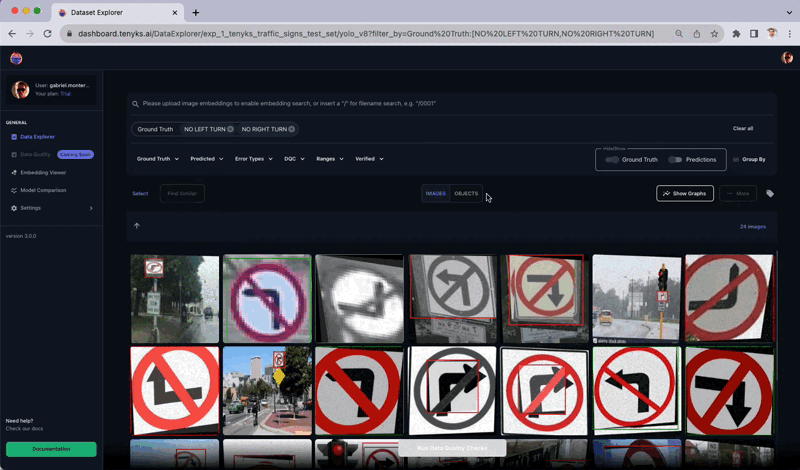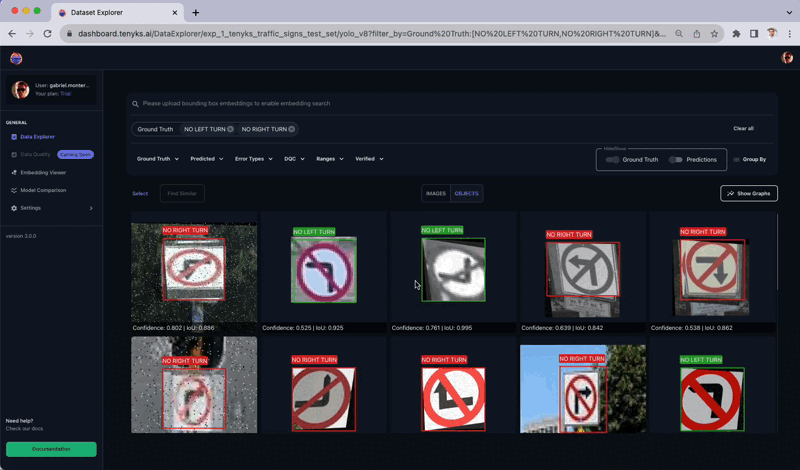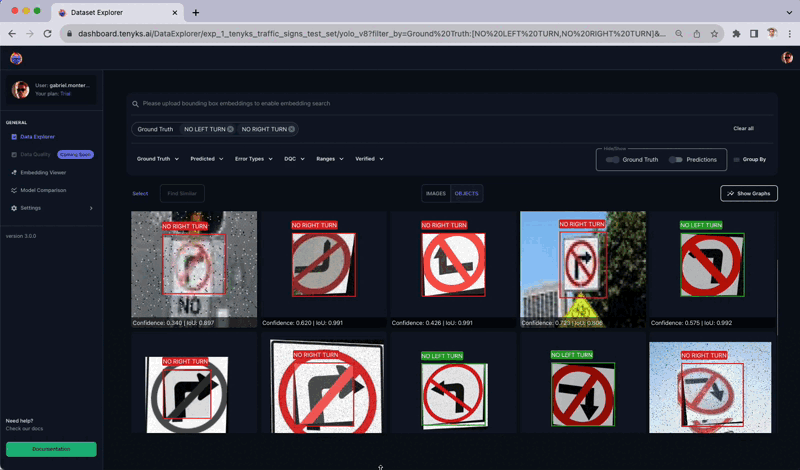
For this tutorial, we’ll use a highway site visitors object detection dataset, see Determine 1. This Roboflow dataset incorporates greater than 2,500 annotated pictures throughout 12 widespread signal varieties together with pace restrict, yield, and pedestrian warnings. The dataset is cut up into 2,200 prepare pictures, 260 validation pictures, and 260 take a look at pictures.
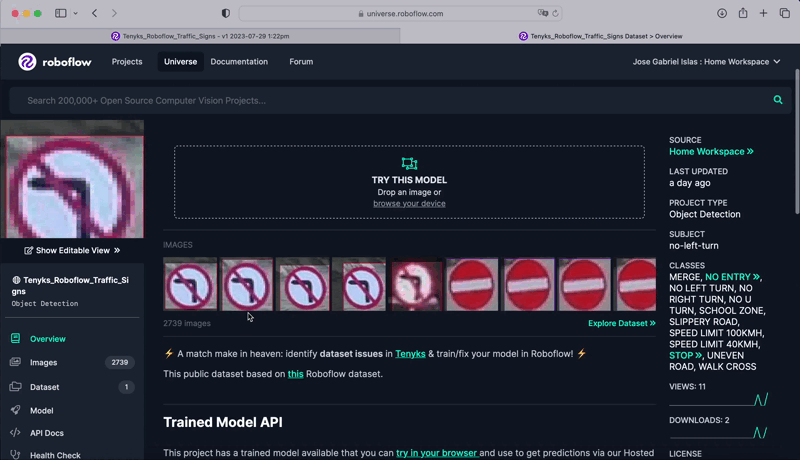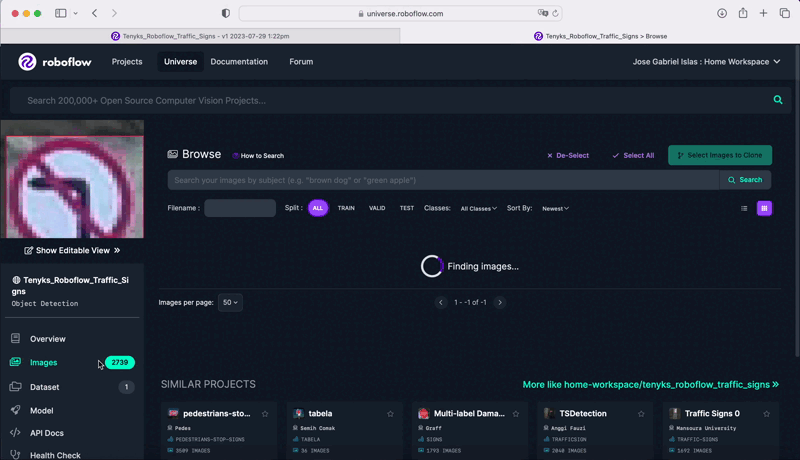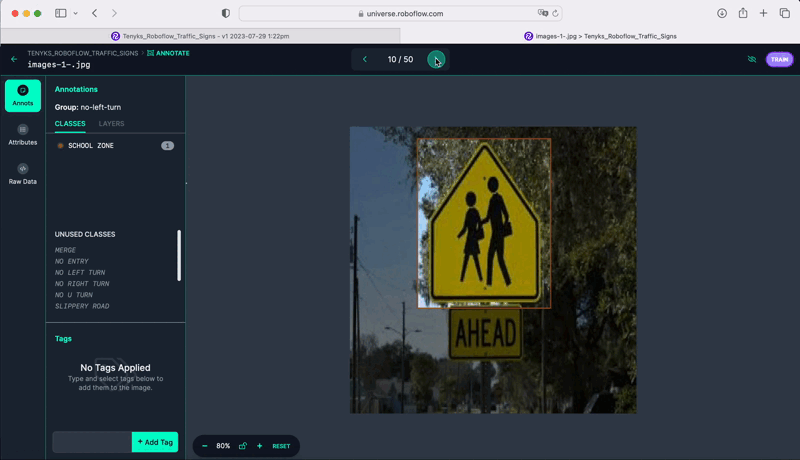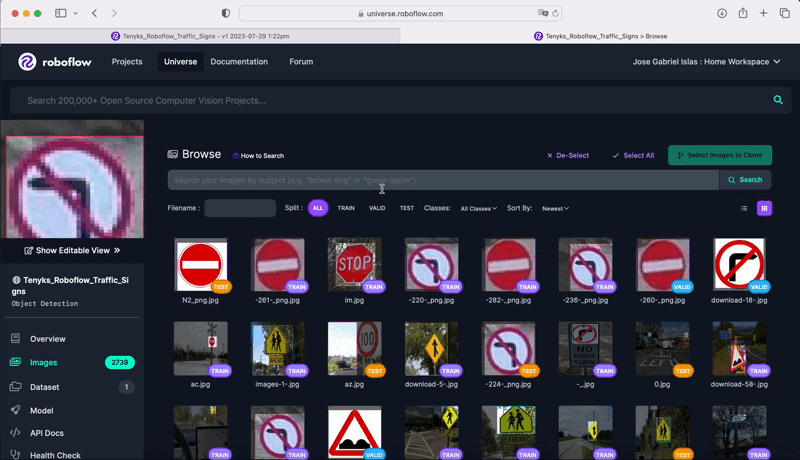
We educated a baseline mannequin on our object detection dataset utilizing Roboflow. For this activity, we utilized Roboflow Practice (Determine 2), which affords an automatic method to coaching state-of-the-art pc imaginative and prescient fashions. We employed one among our three obtainable free credit to coach the mannequin with only a few clicks.
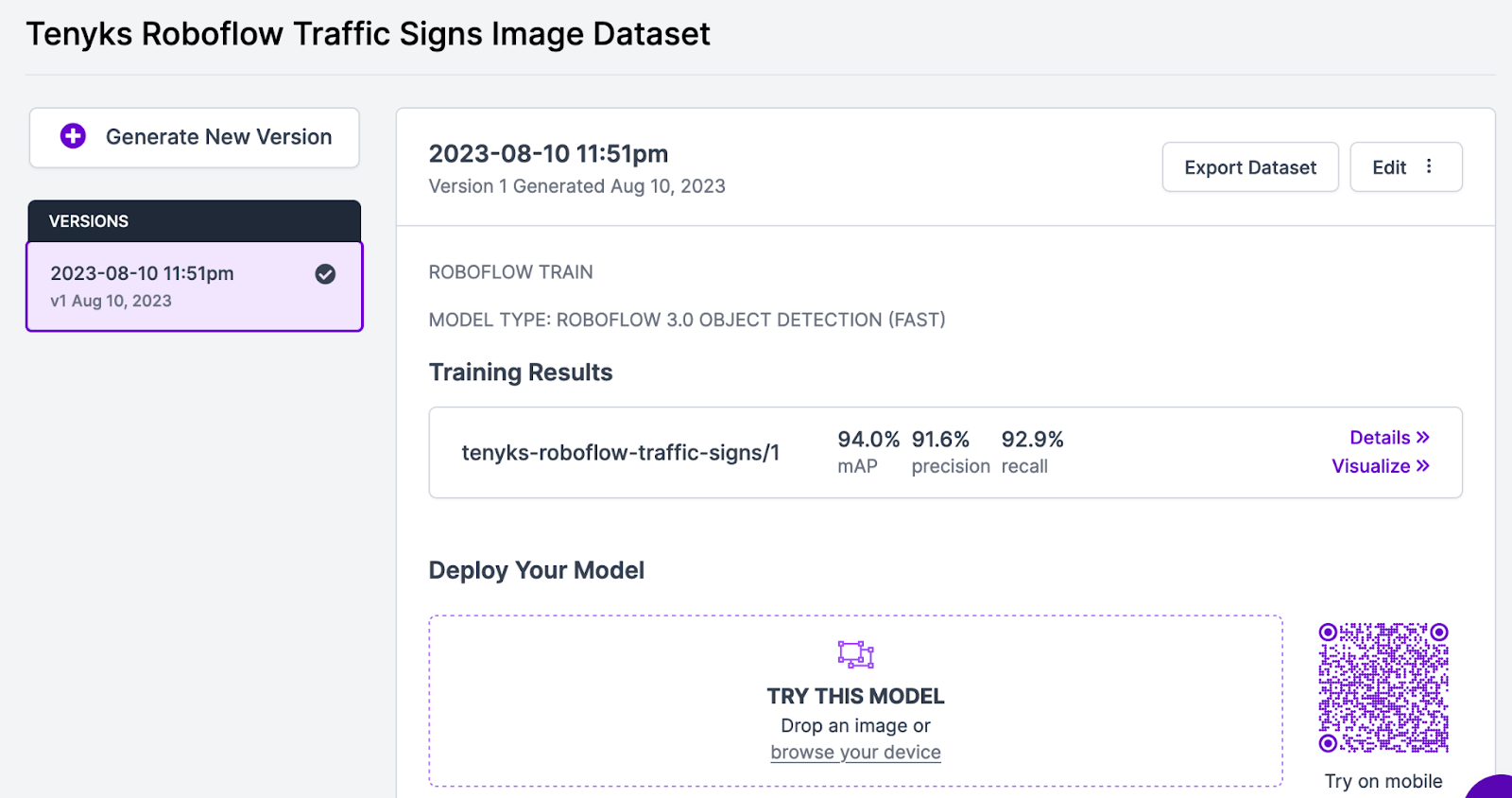
The baseline mannequin achieved an total 94.0% imply common precision (mAP) as proven in Determine 3.
Don’t belief, confirm: a excessive mAP doesn’t at all times imply your mannequin is dependable. We conduct a easy but sensible take a look at to confirm our mannequin’s reliability: the next determine reveals how our educated mannequin –with a significantly excessive mAP (i.e. 94%)– is embarrassingly failing to detect a variety of samples taken randomly from Google Search:
- A ‘No Proper Flip’ instance is predicted as ‘No Left Flip’
- A ‘No Left Flip’ instance is predicted as ‘No Proper Flip’
- A ‘No Left Flip’ instance is predicted as ‘No U Flip’

We will see on Desk 1 what our mannequin is predicting for the earlier examples. Why is the mannequin confidently predicting the unsuitable labels? The remainder of this text will try to reply this query.
|
Instance |
Model_v1 (94% mAP) |
|
Floor Fact: ‘No proper flip’ |
Inference Prediction: ‘No left flip’ ❌ |
|
Floor Fact: ‘No left flip’ |
Inference Prediction: ‘No proper flip’ ❌ |
|
Floor Fact: ‘No left flip’ |
Inference Prediction: ‘No U flip’ ❌ |






Zooming In: Efficiency is Missing in Some Lessons
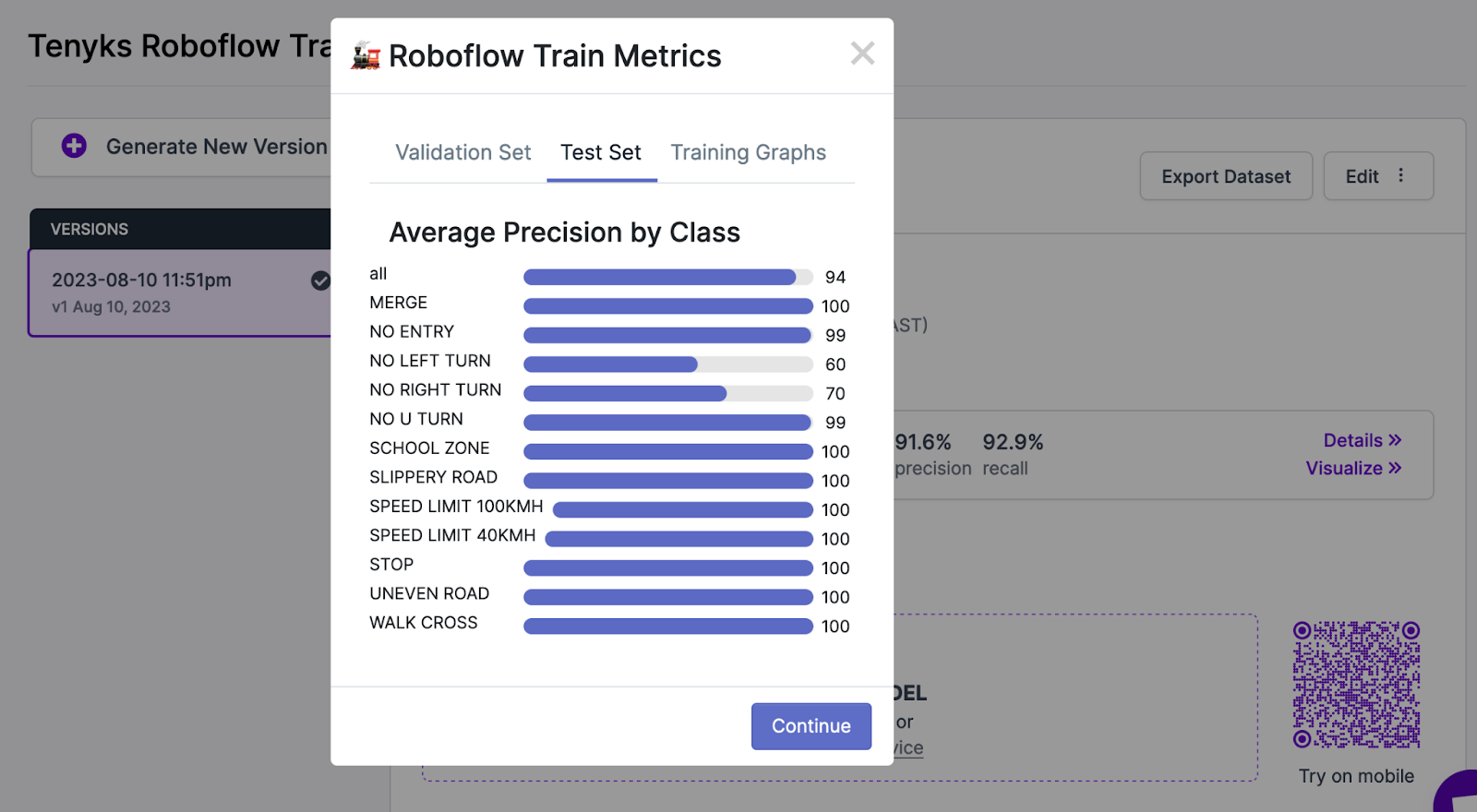
A part of the reply to the above query is mirrored within the take a look at set: whereas some courses achieved a really excessive mAP, different courses corresponding to ‘No Left Flip’ (60% mAP) and ‘No Proper Flip’ (70% mAP) didn’t carry out as nicely, see Determine 5.
Nevertheless, to actually discover the foundation reason behind the unreliable excessive efficiency of the mannequin we have to look at the info.
Discovering Dataset Points
After making a sandbox account (https://sandbox.tenyks.ai) within the Tenyks platform, you’ll find the dataset of this text pre-uploaded.
If you happen to want to add and repair your individual dataset, right here you will discover detailed documentation on find out how to arrange your first dataset within the Tenyks platform.
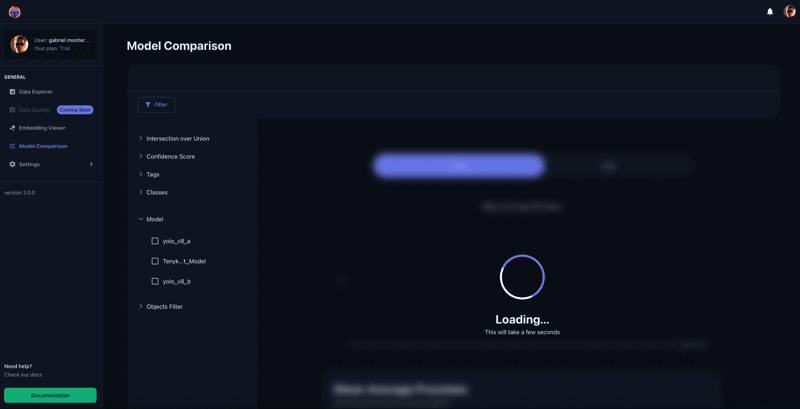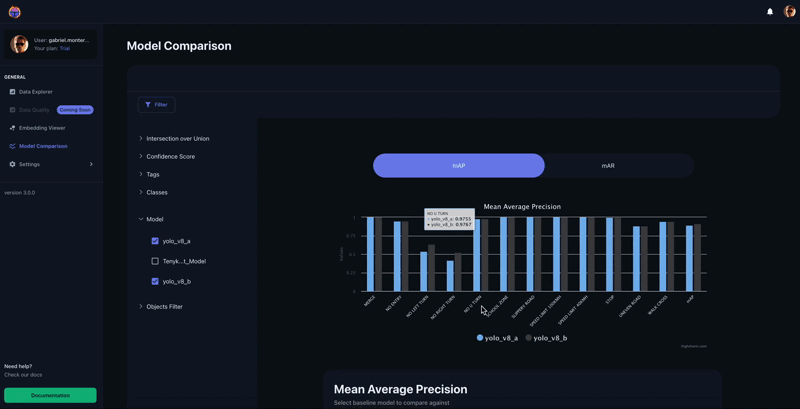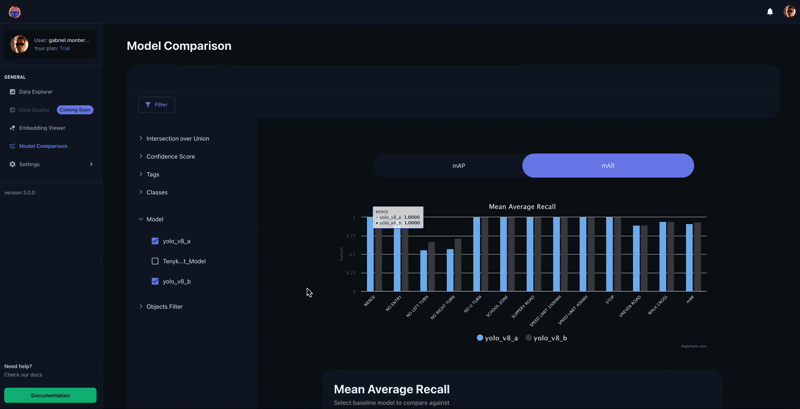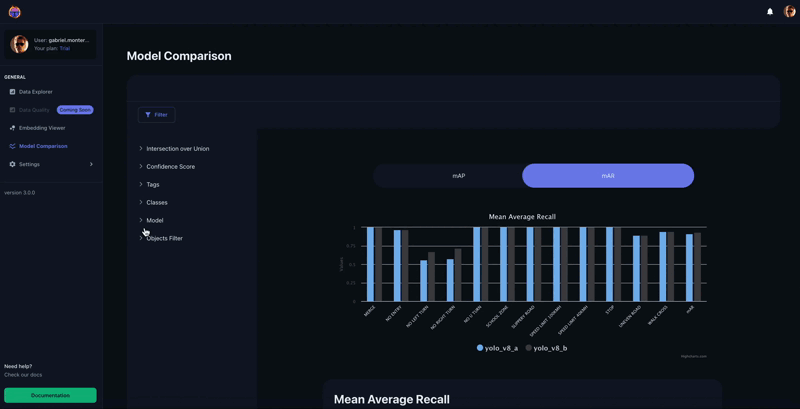
As soon as within the Tenyks platform, we are able to promptly confirm the result of evaluating the educated mannequin on the take a look at set. In Determine 6, the Mannequin Comparability characteristic offers a breakdown of mAP for every class. As anticipated, two most important courses stand out as a consequence of its low efficiency: ‘No Left Flip’ and ‘No Proper Flip’.
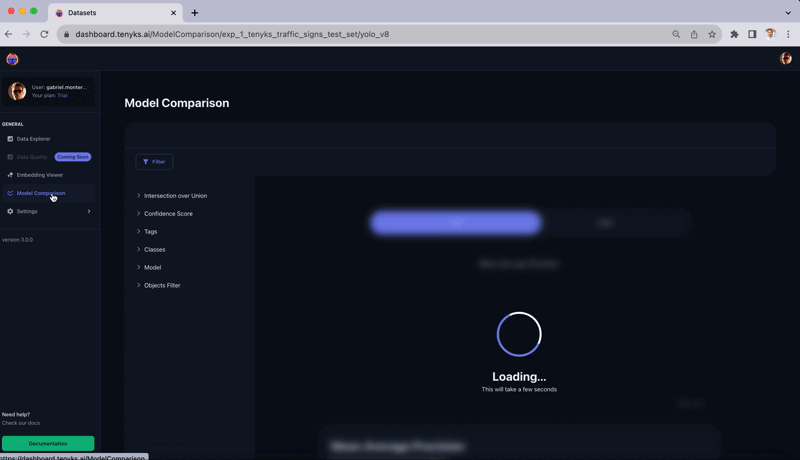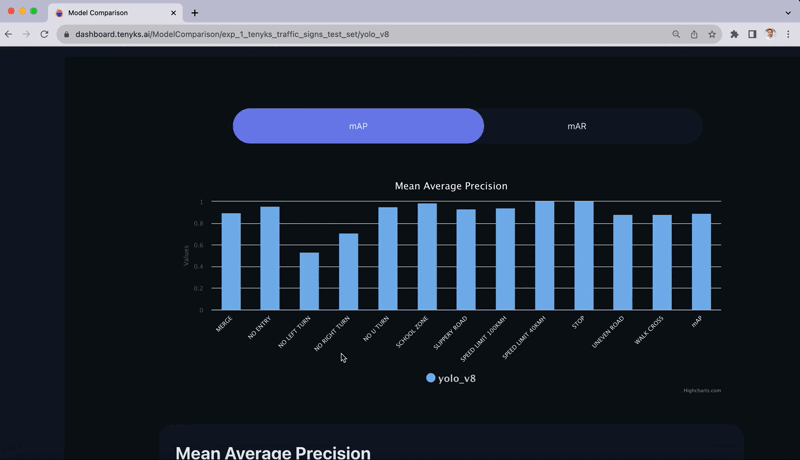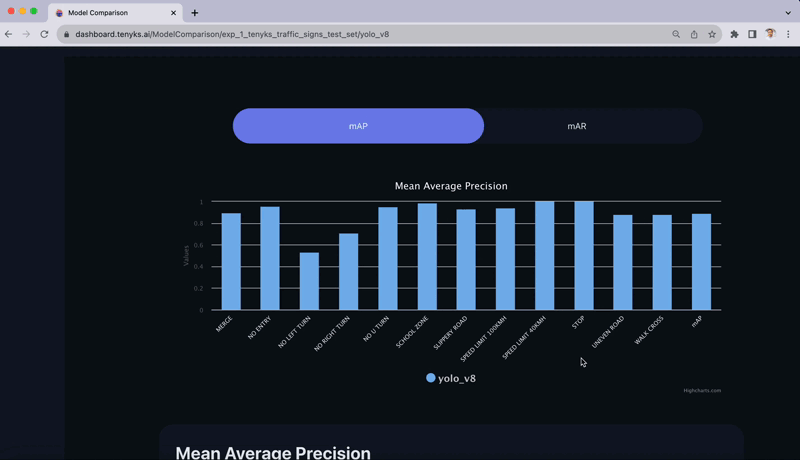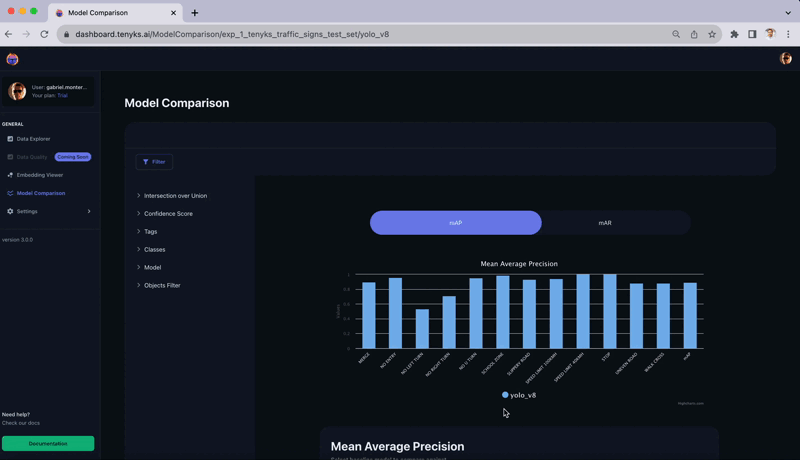
What in case your security group requires a selected mAP threshold in every class earlier than deploying the mannequin in manufacturing? On this part, we’ll discover potential shortcomings within the dataset. Then, in Part 5, we’ll display find out how to handle these points — the truth is, we’ll present you find out how to improve the dataset high quality of any Roboflow dataset.
As determine 7 reveals, we are able to receive a giant image of the info by utilizing Tenyk’s multi-class object detection matrix.
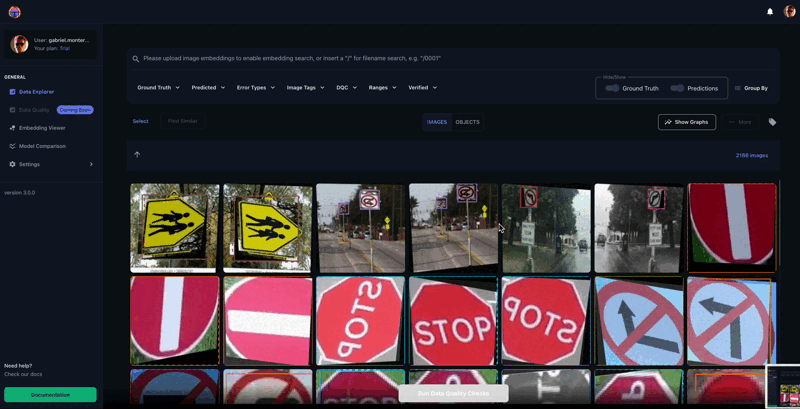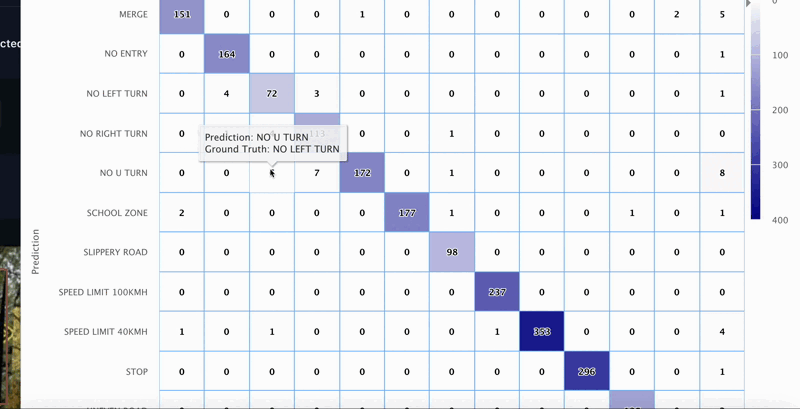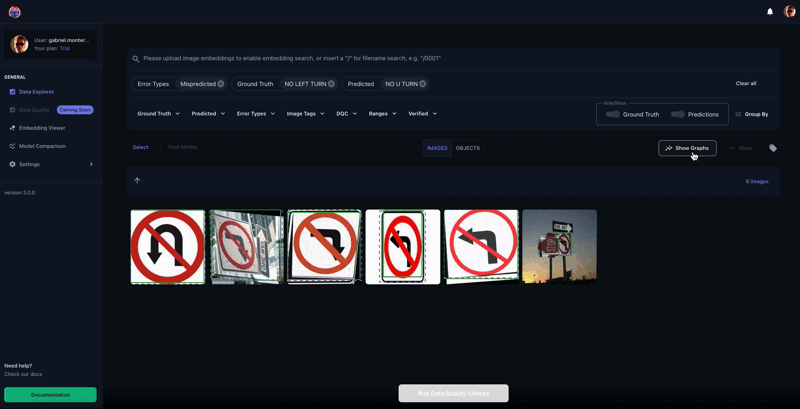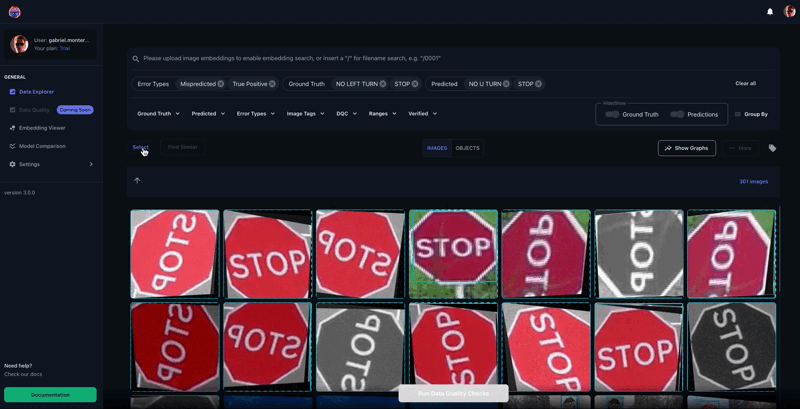
From this graph we are able to see that each ‘No Left Flip’ and ‘No Proper Flip’ have a excessive variety of mispredictions. For example, there are at the least 6 samples the place ‘No Left Flip’ was mispredicted as ‘No U Flip’. Then again, we are able to additionally see that there are 19 undetected examples for the category ‘No Proper Flip’.
In a nutshell the multi-class confusion matrix permits us to shortly grasp some key insights of the place the mannequin could be failing.
For this text we’ll concentrate on just one form of failure: label high quality.
“Label high quality refers as to if the labels of the dataset are full and correct”. Top quality labels are crucial for an object detection mannequin to be taught successfully.
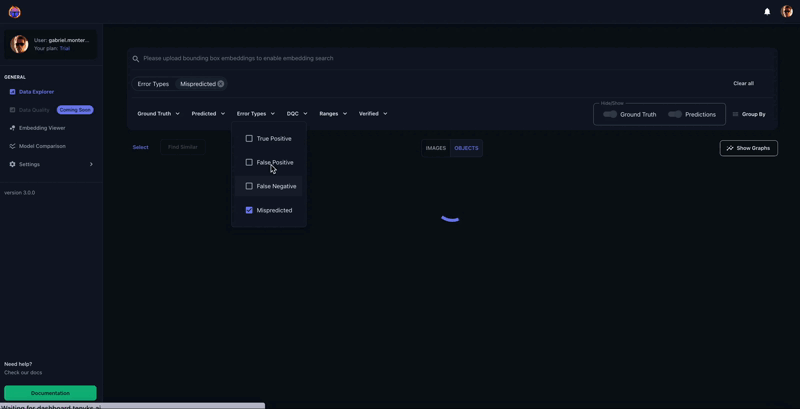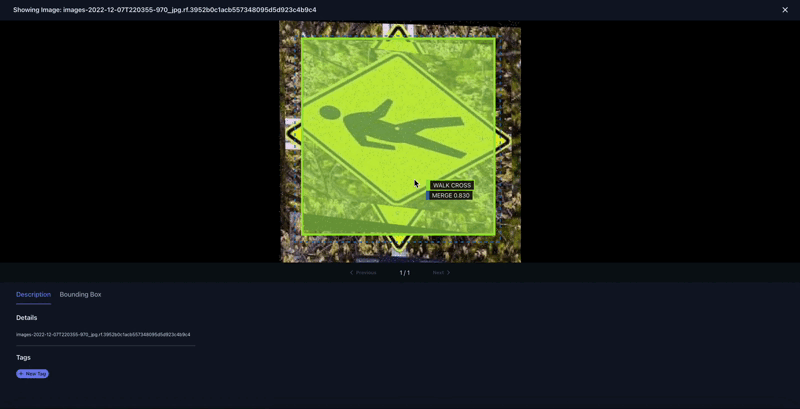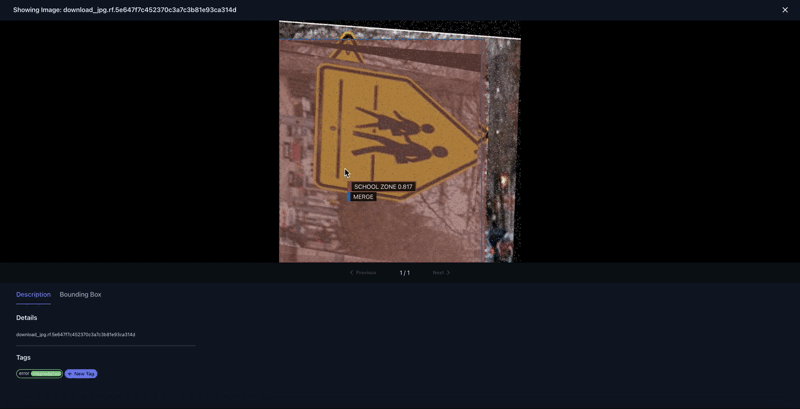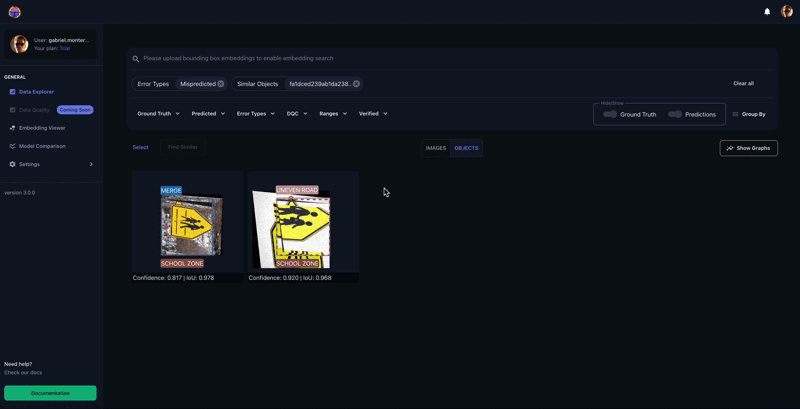
Determine Eight shows a number of cases within the dataset that have been incorrectly labeled. The Tenyks platform offers built-in one-click options to disclose numerous kinds of errors. On this explicit case, we employed the misprediction filter to swiftly determine objects with incorrect labels.
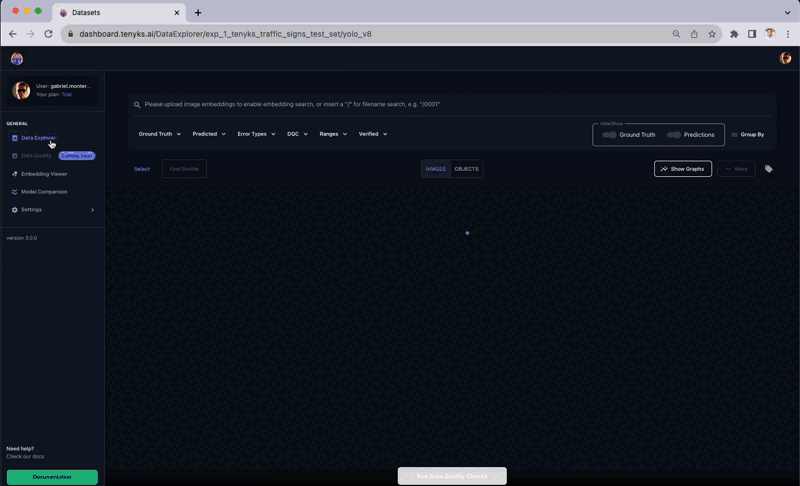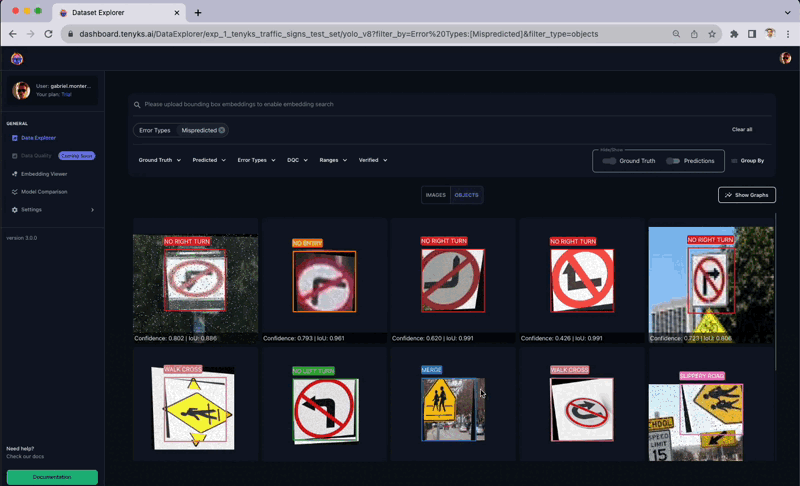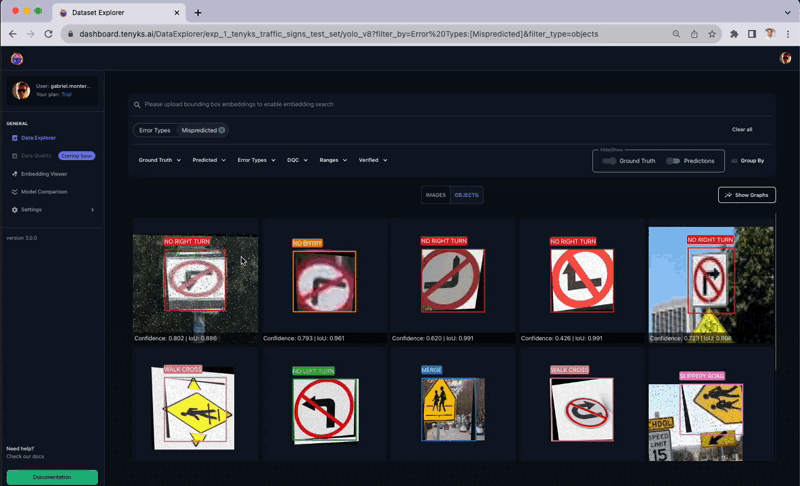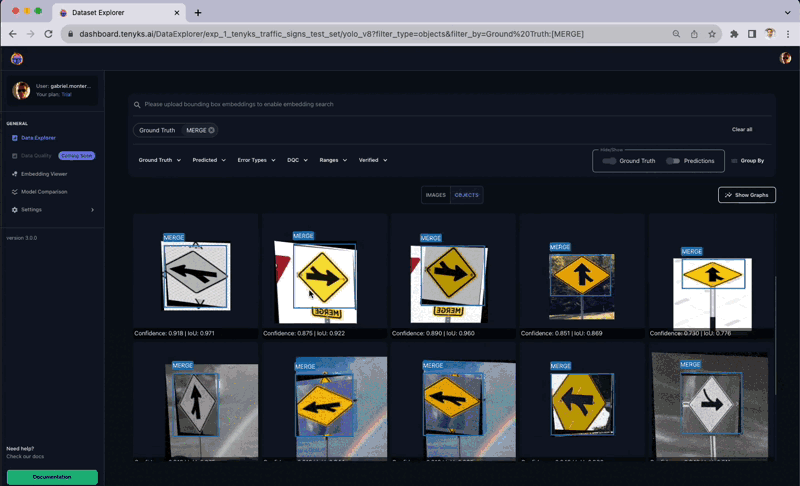
The above determine presents a complete sequence the place the ‘College Zone’ class is inaccurately labeled as a ‘Merge’ class. Extra cases of mislabeling embody a ‘No U-Flip’ class wrongly marked as a ‘Stroll Cross’ class, and a ‘College Zone’ class erroneously recognized as ‘Slippery Street,’ as illustrated in Determine 9.
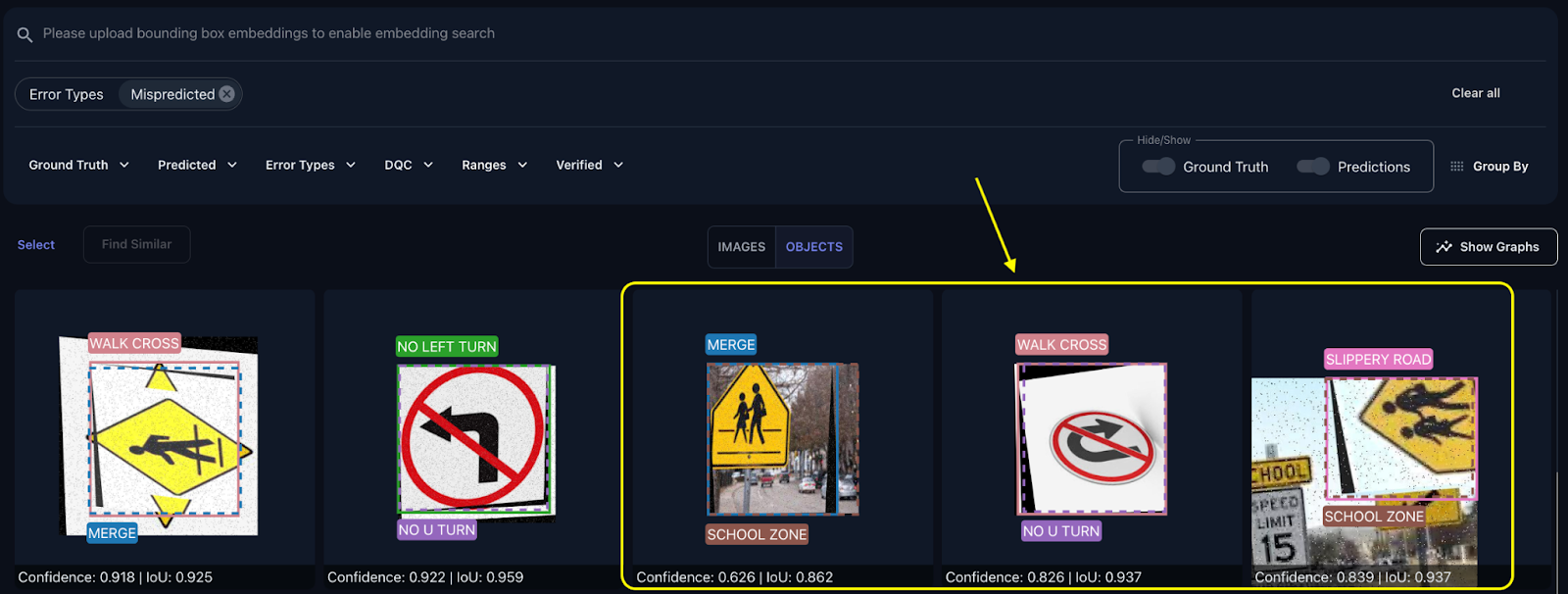
The misprediction filter is not the one instrument we are able to use to identify potential errors with the labels. One other instrument within the Tenyks platform that may assist us to search out comparable examples is the similarity-search characteristic: given a picture or an object, we are able to discover different comparable pictures or objects that share comparable traits.
Determine 10 reveals how we search by similarity on the object-level to search out different cases that may mirror misprediction points. On this instance, we first choose a mispredicted instance: a ‘Stroll Cross’ class that’s being predicted as ‘Merge’ with a worth of 0.83 confidence. As soon as this instance is chosen, we seek for comparable objects.
We receive two different objects that present label issues: an incorrectly labeled ‘Merge’ class predicted as ‘College Zone’, and an incorrectly labeled ‘Uneven Street’ class predicted as ‘College Zone’.]
Whereas auditing an object detection dataset, inspecting false positives generated by the mannequin can unveil cases of incomplete labeling.

By monitoring false positives by means of the Tenyks platform and using the one-click error-type filter ‘False Optimistic,’ it turns into simpler to determine systematic annotation gaps. This permits for the addition of lacking labels. Determine 11 illustrates an object of the ‘Velocity Restrict 100 Kmh’ class that lacks an annotation — the truth is, an annotation exists, however it’s not precisely encompassing the meant object.
Determine 12 shows inconsistent labeling between the ‘No Left Flip’ and ‘No Proper Flip’ courses. Upon making use of the ‘Floor Fact’ filter, it turns into evident that these two courses exhibit labeling inconsistencies: there are a lot of cases the place a ‘No Left Flip’ was labeled as ‘No Proper Flip’, and vice versa.
This lack of uniformity confuses the mannequin and impedes its capability for generalized studying. The truth is, these two courses display the bottom mAP efficiency on a per-class foundation.
To be extra particular, it seems that this dataset was initially augmented 😮, ensuing within the flipping of a number of pictures each horizontally and vertically.
In Determine 13, you possibly can observe how comparable objects have been labeled as each ‘No Left Flip’ and ‘No Proper Flip’ courses ⚠️. Apparently, the augmentation strategy of flipping these two objects (i.e., ‘No Left Flip’ and ‘No Proper Flip’) seems to be counterproductive for the mannequin. Tenyks aids in discovering such insights by means of its built-in options, designed to reinforce the productiveness of ML Engineers.
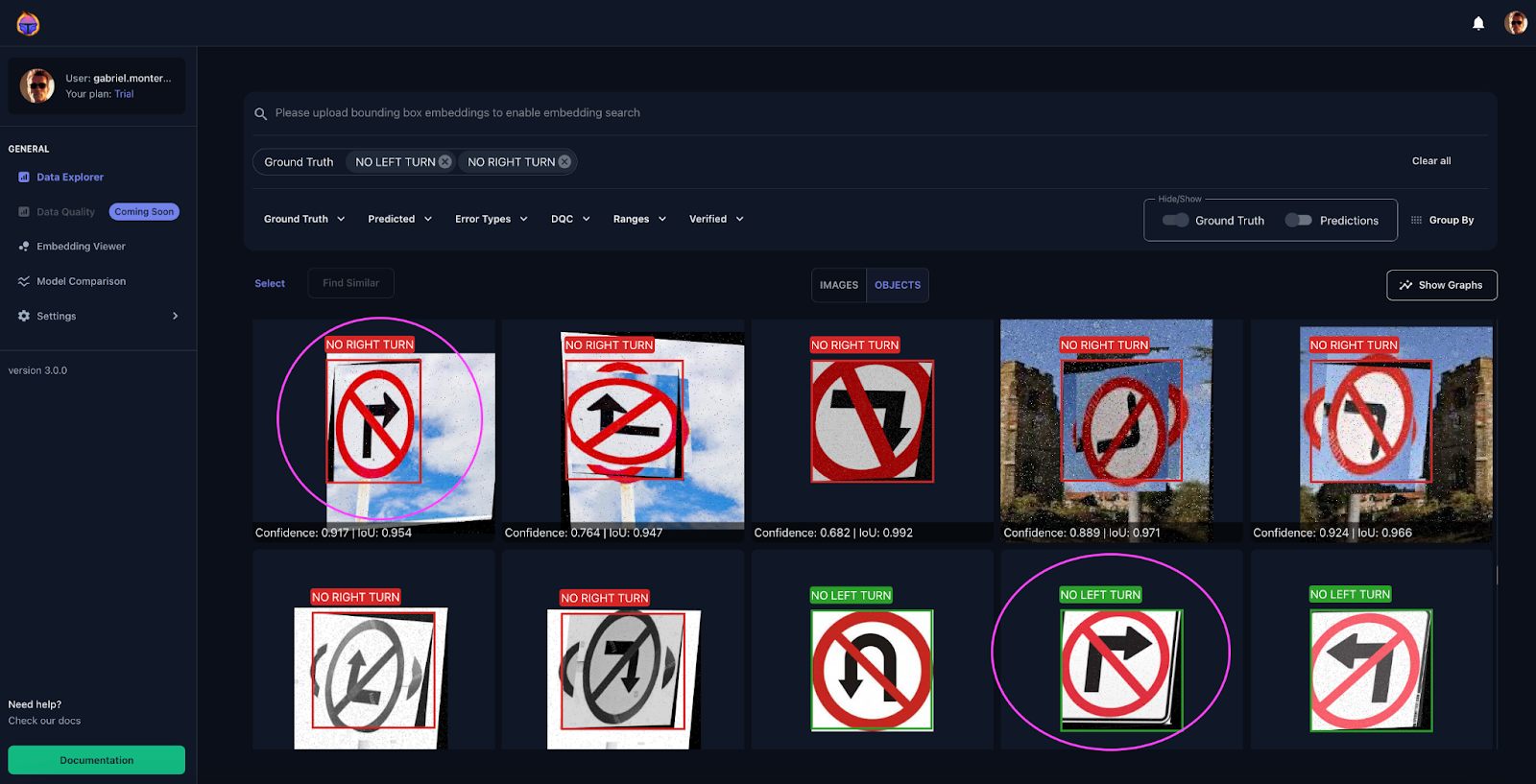
Determine 14, reveals one other instance of how augmentation hurted the dataset: very comparable objects (circled in yellow) have been labeled as each ‘No Left Flip’ and ‘No Proper Flip’ courses ⚠️.
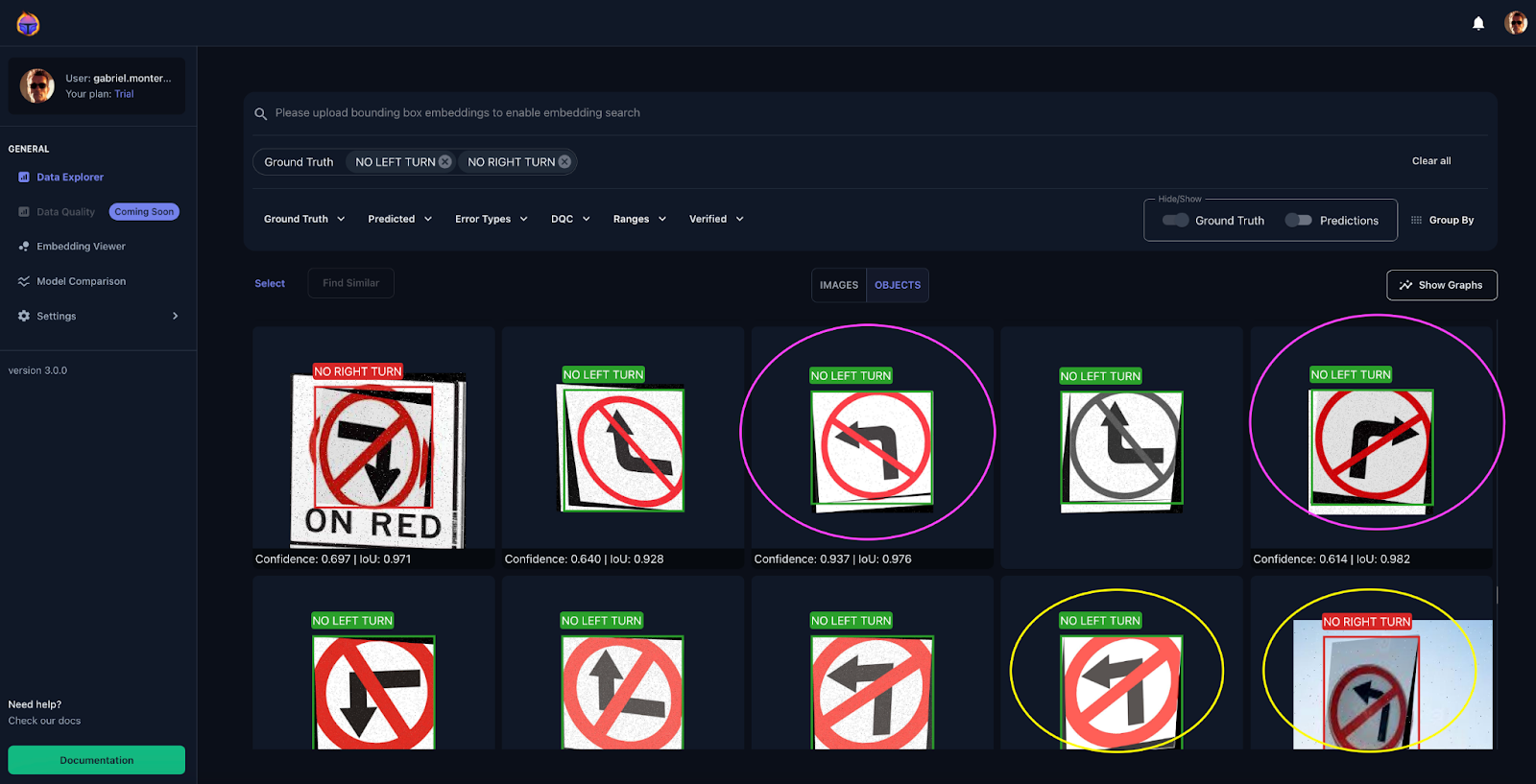
Through the dataset inspection section, you possibly can group the troubled examples by utilizing tags. Determine 15 illustrates how a number of the examples we confirmed you beforehand will be tagged by error, in order that after you categorized a variety of them, the Embedding Viewer will help you determine some patterns in your information by filtering by the tags you assigned.

In abstract, we discovered:
- Incorrect labels: some objects have been annotated with the unsuitable label.
- Lacking labels: some objects have been poorly annotated (i.e. the bounding packing containers didn’t body any class object).
- Inconsistent labels: object A and object B got the identical label, even when object A and object B are totally different.
Fixing Points to Enhance Dataset High quality
Now that now we have recognized three kinds of information points, we are able to use the Roboflow annotation instrument to repair our dataset.
Determine 16 reveals how Roboflow helps us shortly repair one of many cases annotated with an incorrect label. The thing was annotated with a label Stroll Cross, when in actuality it belongs to class No U Flip.

Acquiring greater mannequin efficiency — with the brand new improved dataset
After we addressed the label high quality points beforehand mentioned, we retrained our mannequin in Roboflow with the revamped dataset, see determine 17.
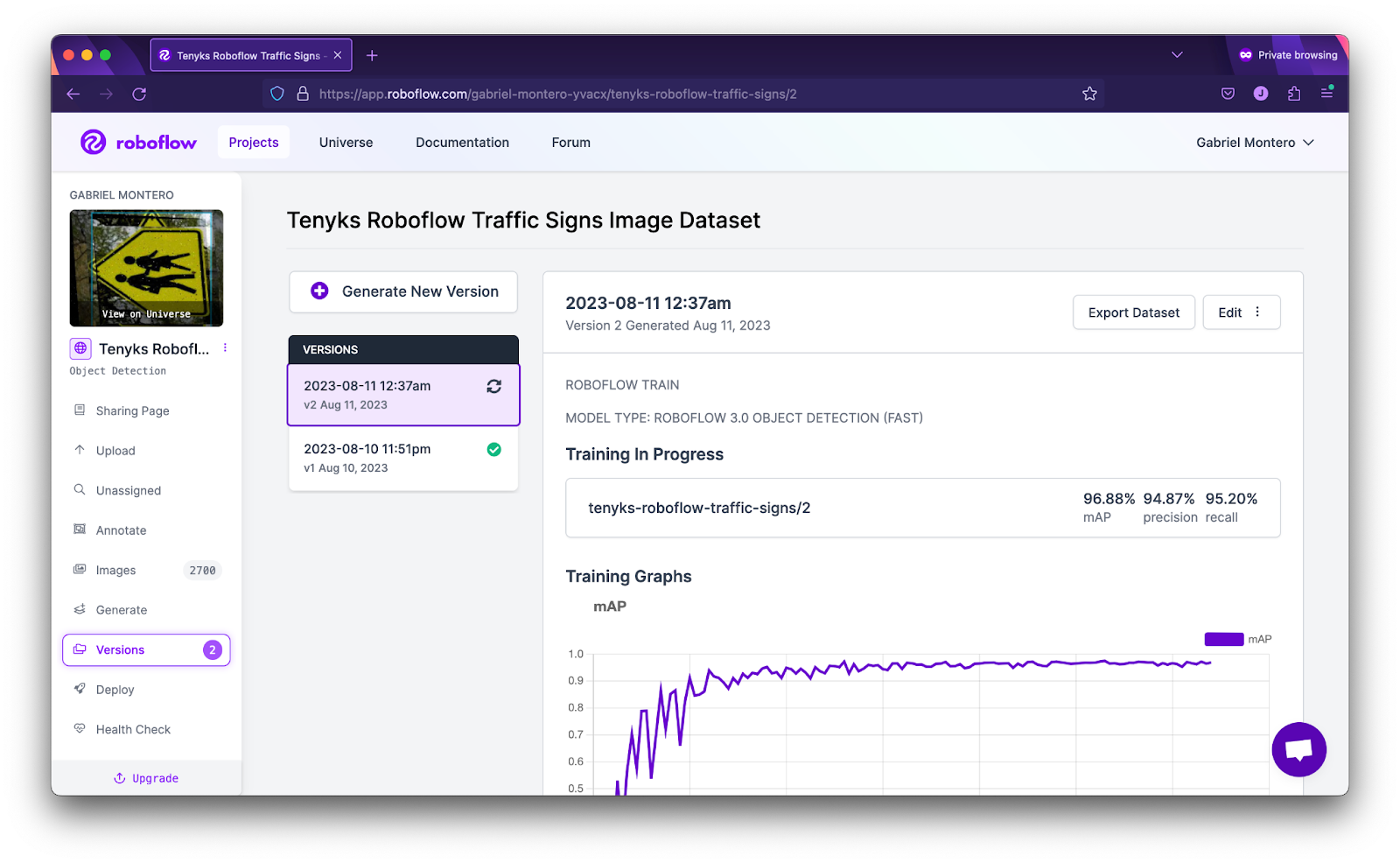
Determine 18 and 19 present that mannequin efficiency elevated from 94% mAP to 97.6% mAP, whereas efficiency for ‘No Left Flip’ class elevated from 60% mAP to 77% mAP, and efficiency for ‘No Proper Flip’ elevated from 70% mAP to 86% mAP.
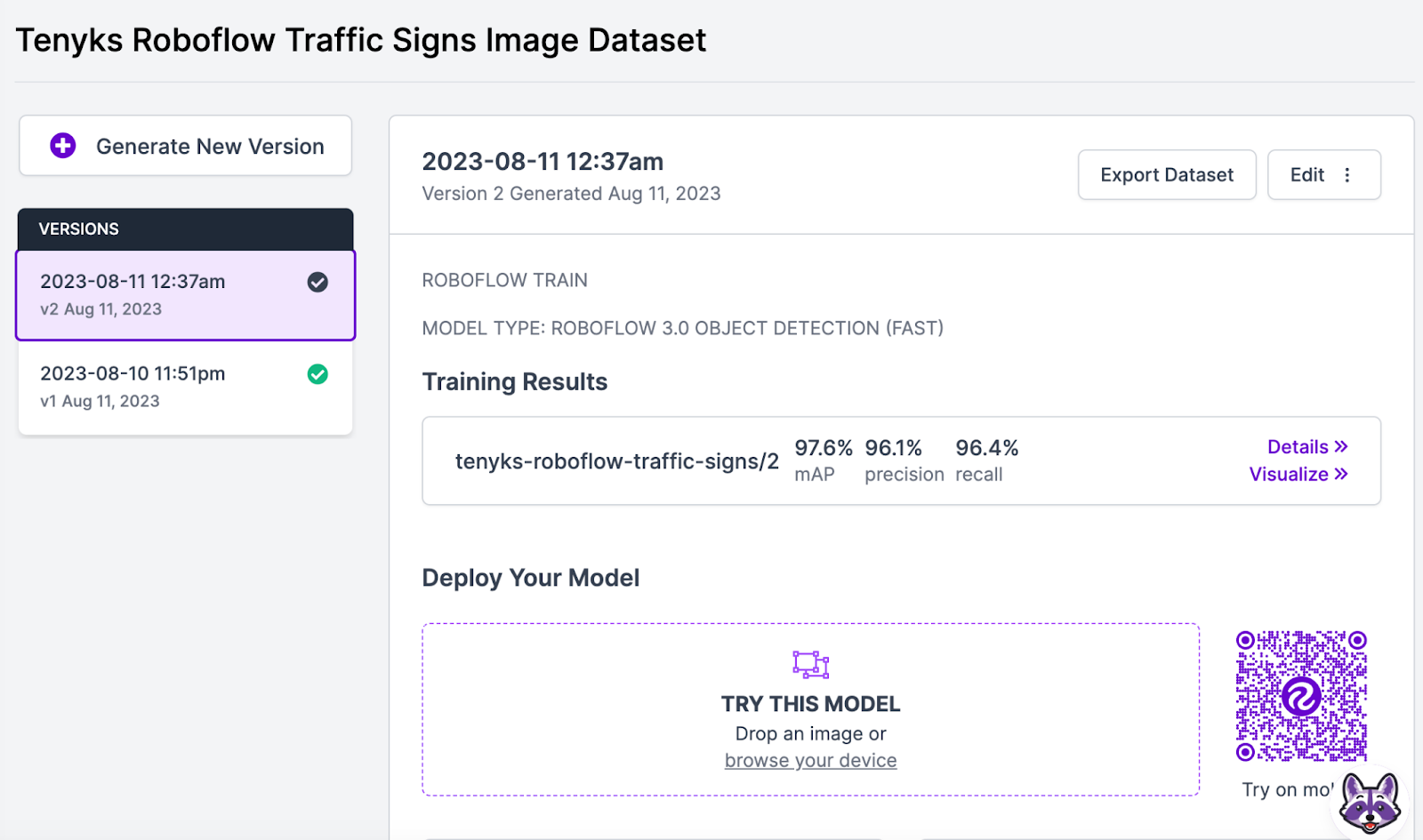
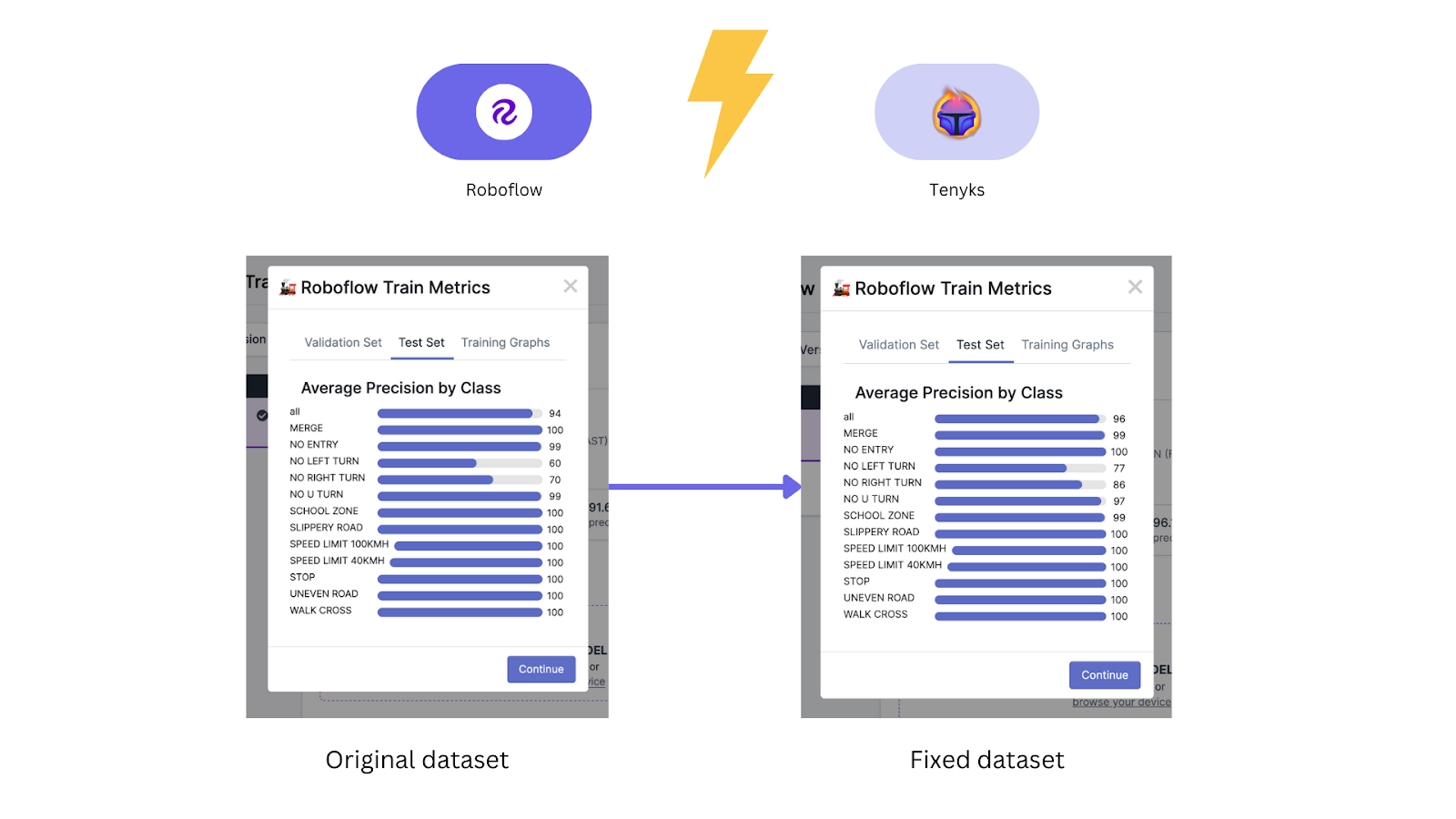
Lastly we are able to use the mannequin comparability characteristic on the Tenyks platform to acquire a transparent image of how the mannequin efficiency improved on a per-class foundation.
|
Instance |
Model_v1 (94% mAP) |
Model_v2 (97% mAP) |
|
Floor Fact: ‘No proper flip’ |
Inference Prediction: ‘No left flip’ ❌ |
Inference Prediction: ‘No proper flip’ ✅ |
|
Floor Fact: ‘No left flip’ |
Inference Prediction: ‘No proper flip’ ❌ |
Inference Prediction: ‘No left flip’ ✅ |
|
Floor Fact: ‘No left flip’ |
Inference Prediction: ‘No U flip’ ❌ |
Inference Prediction: ‘No U flip’ ❌ |



What Did We Study?
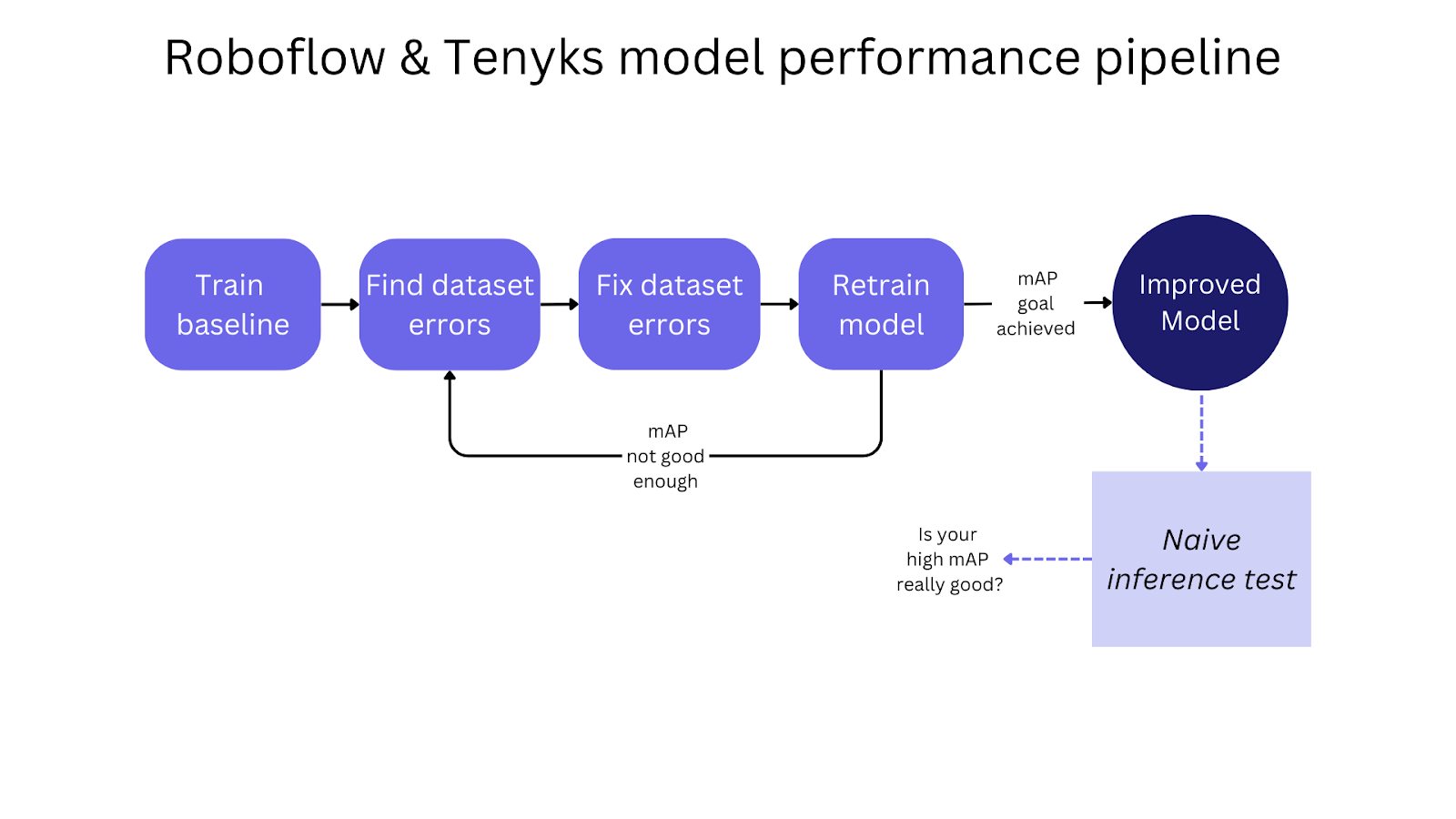
On this article we confirmed how we are able to enhance mannequin efficiency by specializing in the info high quality of your Roboflow dataset.
We began by coaching a baseline mannequin utilizing Roboflow Practice, then we uncovered dataset points utilizing the Tenyks platform. After fixing these points with the Roboflow annotation instrument, we educated a brand new mannequin that confirmed higher efficiency.
Our improved mannequin was not good, we are able to see on Desk 2 that this new mannequin nonetheless fails to discriminate between ‘No Left Flip’ and ‘No U Flip’ courses. One method to repair this downside could be so as to add extra coaching examples of those courses, in order that the mannequin can be taught to differentiate between the 2.
As we confirmed, a naive inference take a look at will help you assess whether or not your “excessive mAP” mannequin is nearly as good because it appears on paper. This fundamental but efficient method can really assist you to to drive your mannequin debugging in the suitable course.
As we mentioned earlier, Roboflow and Tenyks is a match made in heaven, and you’ll enhance your mannequin efficiency with a mix of each.


