A analysis examine from China has revealed that its in-house AI processing chip “ACCEL” is alleged to supply efficiency that’s 3000 occasions quicker than NVIDIA’s A100 & A800 GPUs. Within the face of world sanctions, China is working to enhance its personal options to take care of the present tempo of business development. Tsinghua College in China has developed a brand new approach for AI computation and designed the ACCEL chip, which harnesses the facility of photonics and analog know-how to realize spectacular efficiency. The revealed figures are extraordinarily spectacular, however ought to in fact be taken with a grain of salt.

With out a real-time benchmark, you’ll be able to’t declare {that a} chip is the quickest in its trade. Due to this fact, ACCEL was examined in experiments towards Vogue-MNIST, the 3-class ImageNet classification and time-lapse video recognition eventualities to find out the efficiency of the deep studying chip. It achieved accuracies of 85.5%, 82.0% and 92.6%, which exhibits that the chip can be utilized in varied industries and isn’t restricted to a particular area. This makes ACCEL significantly fascinating and it will likely be fascinating to see what future prospects the chip provides.
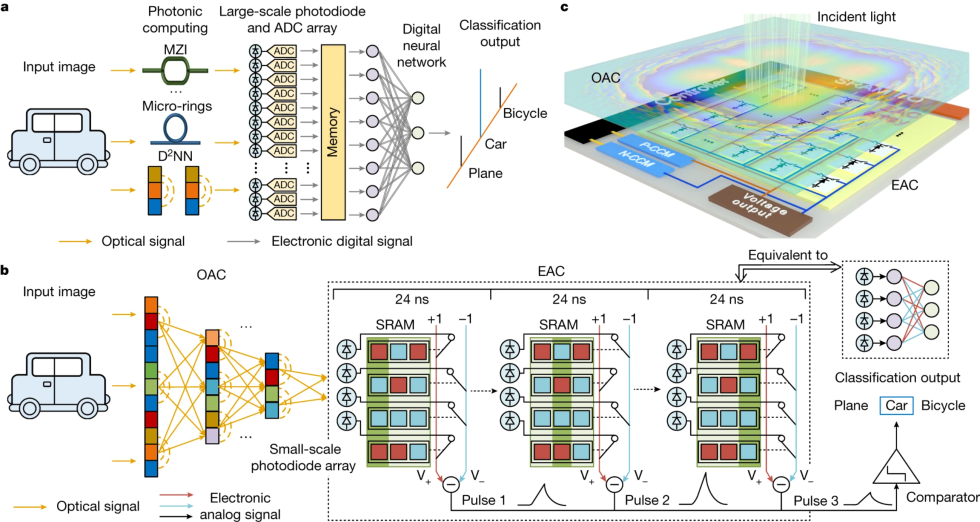
This chip combines the capabilities of diffractive optical analog computation (OAC) and digital analog computation (EAC) with scalability, nonlinearity and suppleness. To realize such efficiencies, the chip makes use of a hybrid structure of optics and electronics to scale back massive quantities of analog-to-digital conversions (ADCs) in massive workloads. This leads to considerably improved efficiency. A printed analysis paper discusses the chip’s mechanism intimately.
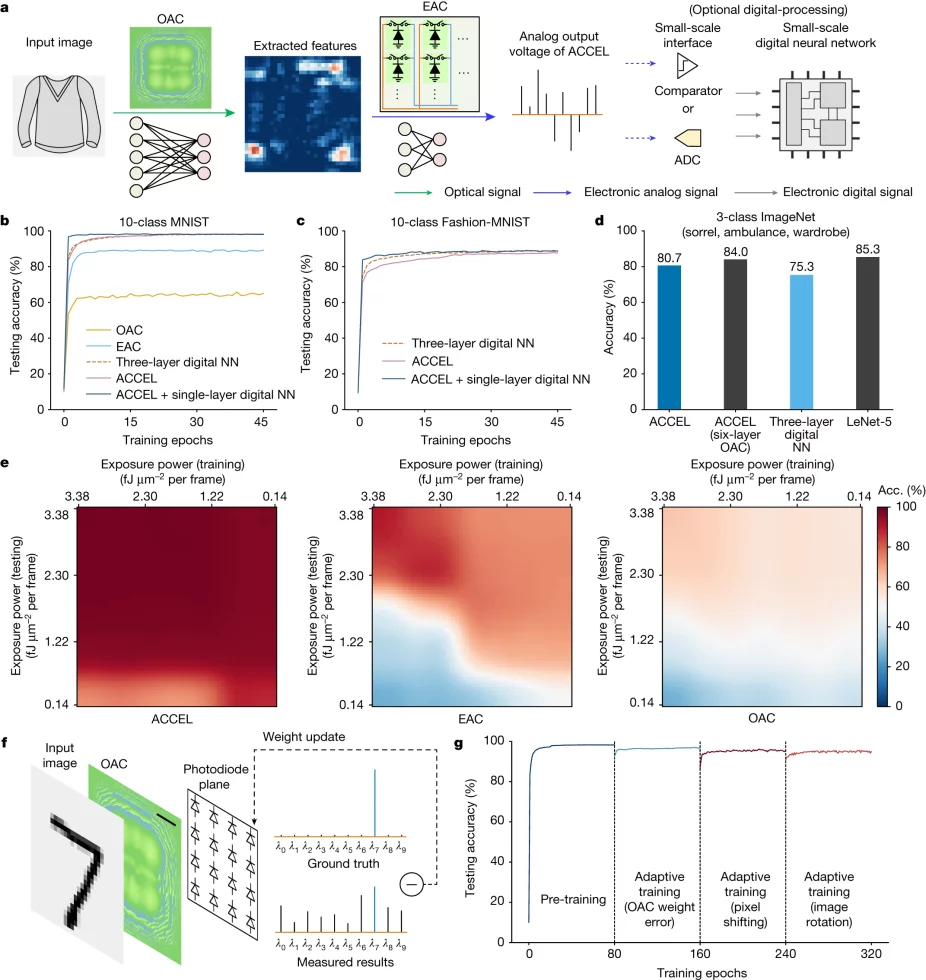
For state-of-the-art GPU, we used NVIDIA A100, whose claimed computing pace reaches 156 TFLOPS for float32 (ref.33). ACCEL with two-layer OAC (400 × 400 neurons in every OAC layer) and one-layer EAC (1,024 × Three neurons) experimentally achieved a testing accuracy of 82.0% (horizontal dashed line in Fig. 6d,e). As a result of OAC computes in a passive manner, ACCEL with two-layer OAC improves the accuracy over ACCEL with one-layer OAC at virtually no enhance in latency and power consumption (Fig. 6d ,e, purple dots). Nonetheless, in a real-time imaginative and prescient job equivalent to computerized driving on the highway, we can’t seize a number of sequential photos prematurely for a GPU to make full use of its computing pace by processing a number of streams concurrently48 (examples as dashed traces in Fig. 6d,e). To course of sequential photos in serial on the similar accuracy, ACCEL experimentally achieved a computing latency of 72 ns per body and an power consumption of 4.38 nJ per body, whereas NVIDIA A100 achieved a latency of 0.26 ms per body and an power consumption of 18.5 mJ per body.
through Nature
The impression of ACCEL and comparable analog AI chip developments on the trade is at present troublesome to foretell, because the introduction of AI accelerators primarily based on analog know-how continues to be sooner or later. Though the efficiency figures and statistics are fairly optimistic, it must be famous that “implementation” within the trade just isn’t a straightforward job and requires time, important monetary sources and thorough analysis. Nonetheless, nobody can deny that the way forward for computing is shiny, and it’s only a matter of time earlier than we see such efficiency within the mainstream.
Supply: Tom’s {Hardware}




