On the coronary heart of the sector of pc imaginative and prescient is a elementary idea: enabling computer systems to grasp visible inputs. This concept might be damaged down into many duties: figuring out objects in photos, clustering photos to seek out outliers, creating methods by which to go looking massive catalogs of visible knowledge, and extra. Picture embeddings are on the coronary heart of many imaginative and prescient duties, from clustering to picture comparability to enabling visible inputs with Giant Multimodal Fashions (LMMs).
On this information, we’re going to discuss what picture embeddings are, how they can be utilized, and discuss CLIP, a preferred pc imaginative and prescient mannequin that you should utilize to generate picture embeddings to be used in constructing a variety of functions.
With out additional ado, let’s get began!
Embeddings 101: What’s an Picture Embedding?
A picture embedding is a numeric illustration of a picture that encodes the semantics of contents within the picture. Embeddings are calculated by pc imaginative and prescient fashions that are normally educated with massive datasets of pairs of textual content and picture. The purpose of such a mannequin is to construct an “understanding” of the connection between photos and textual content.
These fashions allow you to create embeddings for photos and textual content, which might then be in contrast for search, clustering, and extra. See our publish on clustering with picture embeddings to see a tutorial on the subject.
Embeddings are totally different from photos of their uncooked kind. A picture file incorporates RGB knowledge that claims precisely what coloration every pixel is. Embeddings encode info that represents the contents of a picture. These embeddings are unintelligible of their uncooked kind, simply as photos are when learn as a listing of numbers. It’s whenever you use embeddings that they begin to make sense.
Take into account the next picture:

This picture incorporates a bowl of fruit. A picture embedding will encode this info. We may then examine the picture embedding to a textual content embedding like “fruit” to see how comparable the idea of “fruit” is to the contents of the picture. We may take two prompts, corresponding to “fruit” and “vegetable”, and see how comparable each is. Probably the most comparable immediate is taken into account essentially the most consultant of the picture.
Let’s talk about CLIP, a preferred picture embedding mannequin created by OpenAI, then stroll via a couple of examples of embeddings to see what you are able to do with embeddings.
What’s CLIP?
CLIP (Contrastive Language-Picture Pretraining), developed by OpenAI, is a multimodal embedding mannequin developed by OpenAI and launched in 2019. CLIP was educated utilizing over 400 million pairs of photos and textual content. You’ll be able to calculate each picture and textual content embeddings with CLIP. You’ll be able to examine picture embeddings and textual content embeddings.
CLIP is a zero-shot mannequin, which implies the mannequin doesn’t require any fine-tuning to calculate an embedding. For classification duties, it’s good to calculate a textual content embedding for every potential class, a picture embedding for the picture that you just wish to classify, then examine every textual content embedding to the picture embedding utilizing a distance metric like cosine similarity. The textual content embedding with the very best similarity is the label most associated to the picture.
Classify Photos with Embeddings
Picture classification is a process the place you goal to assign one or a number of labels to a picture from a restricted variety of courses. For instance, contemplate the next picture of a parking zone:

We may examine this picture with the phrases “parking zone” and “park” to see how comparable every are. Let’s move the picture via CLIP, a preferred embedding mannequin and examine the similarity of the picture to every immediate. CLIP is a zero-shot classification mannequin powered by embeddings. This implies you’ll be able to classify photos with out coaching a fine-tuned mannequin utilizing embeddings.
Under are the boldness outcomes from an embedding comparability. These outcomes present how assured CLIP is {that a} given textual content label matches the contents of a picture.
- Parking zone: 0.99869776
- Park: 0.00130221
Because the class parking zone has the very best “confidence”, we will assume the picture is nearer to a parking zone fairly than a park. Confidence within the instance above is measured by the quantity closest to 1. You’ll be able to multiply every worth by 100 to retrieve a share. We used the demo code within the OpenAI CLIP GitHub repository to run the calculation.
Classify Video Scenes with Embeddings
A video incorporates a collection of frames. You’ll be able to consider every body as its personal distinctive picture that you would be able to classify. You’ll be able to run frames in a video via CLIP for zero-shot video classification. You’ll find how comparable every body, or each n-th body is, in a picture, to a listing of textual content prompts.
The next video reveals CLIP operating to categorise how shut a video body is to the textual content immediate “espresso cup”:
You may use CLIP to determine when an object seems in a video. As an illustration, you would add a tag to say the video incorporates an individual if CLIP turns into assured {that a} video body incorporates an individual. Or you would preserve monitor of what number of frames comprise cats so you’ll be able to monitor the place the cat scenes are in a video. See our end-to-end tutorial on analyzing movies utilizing CLIP in the event you’d wish to attempt by yourself knowledge.
Video classification with CLIP has many functions, together with figuring out when a selected idea is current in a video and if a video just isn’t secure for work (evidenced by the presence of violent or express content material).
Cluster Photos with Embeddings
Embeddings can be utilized to cluster photos. You’ll be able to cluster photos into an outlined set of teams (i.e. three teams), or you’ll be able to cluster embeddings with out a set variety of clusters. Within the former case, you’ll be able to determine patterns between photos in a restricted set of clusters; within the latter, you’ll be able to calculate the gap between photos in a dataset. Clustering is commonly used for outlier detection, the place you goal to seek out photos which are sufficiently dissimilar.
k-means clustering is usually used to cluster embeddings right into a set variety of classes. There are various algorithms that allow you to cluster photos into an undefined variety of clusters in line with your embeddings. DBSCAN is one such instance. Now we have written a information that walks via tips on how to cluster picture embeddings.
The next picture reveals CLIP used to cluster a picture dataset, visualized utilizing Bokeh:
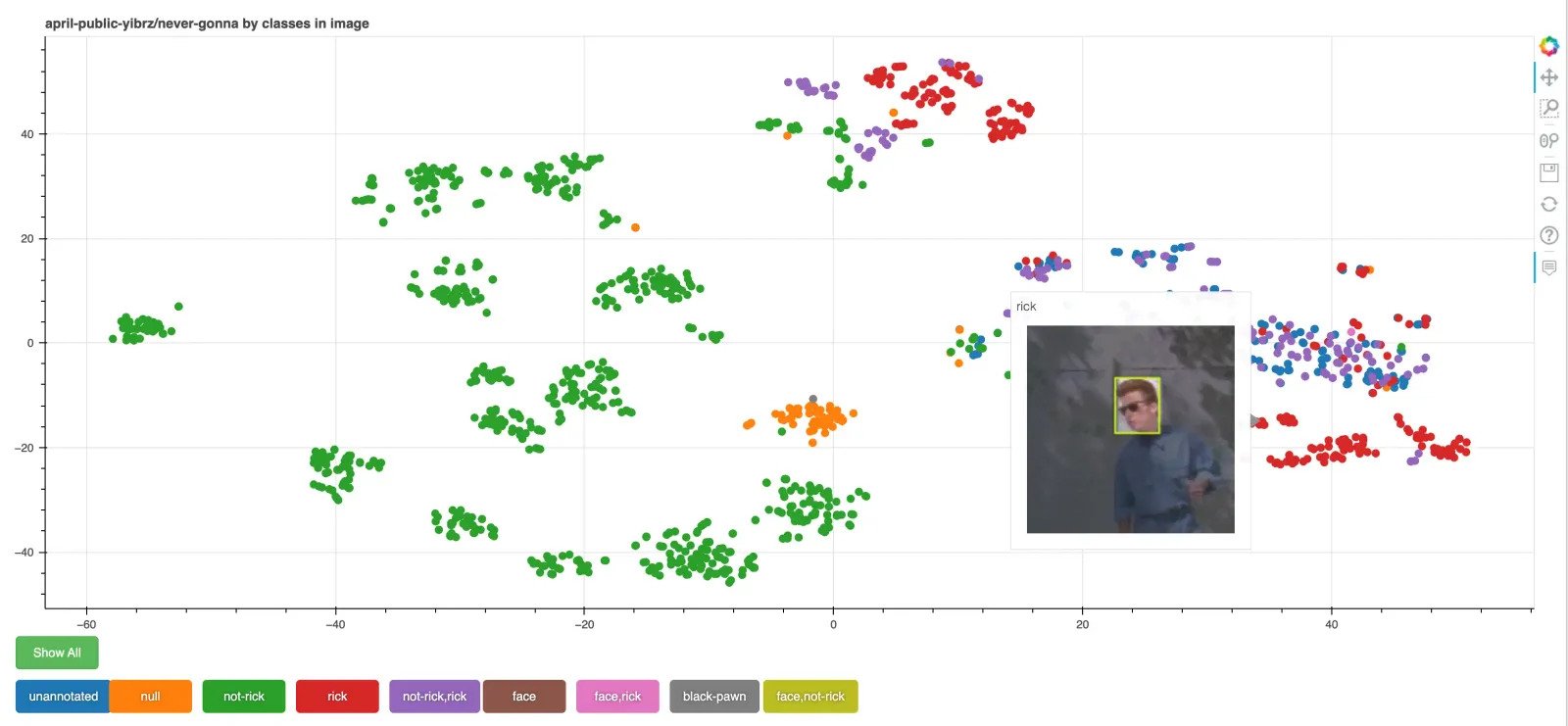
Picture Search with Embeddings
Above, we launched two ideas:
1. The textual content embedding.
2. The picture embedding.
These values are each calculated by an embedding mannequin. You’ll be able to examine textual content and picture embeddings to see how comparable textual content is to a picture. It can save you embeddings in a particular database known as a vector database (used to retailer embedding) to run environment friendly searches between picture and textual content embeddings. This environment friendly looking lets you construct a “semantic” picture search engine.
Semantic picture serps are serps that you would be able to question with pure language ideas. As an illustration, you’ll be able to sort in “cats” to seek out all cats in a dataset, or “onerous hat” to seek out photos which are associated to a tough hat in a dataset. Constructing such a search engine was once prohibitively costly and a technological problem. With embeddings and vector databases, constructing a picture search engine that runs quick is feasible.
The Roboflow platform makes use of semantic search to make it straightforward to seek out photos in a dataset. The next video reveals an instance of offering a pure language question to retrieve photos in a dataset:
Strive querying the COCO dataset on Roboflow Universe to expertise semantic search powered by picture embeddings.
Conclusion
Embeddings are numeric, semantic representations of the contents of a picture. Picture embeddings have a variety of makes use of in trendy imaginative and prescient duties. You should use embeddings to categorise photos, classify video frames, cluster photos to seek out outliers, search via a folder of photos, and extra. Above, we now have mentioned every of those use instances intimately.
To be taught extra about calculating embeddings, take a look at our information to utilizing Roboflow Inference with CLIP for classification. Roboflow Inference is an open supply server for deploying imaginative and prescient fashions that powers thousands and thousands of API calls for big enterprises world wide. You can too use Roboflow’s hosted inference resolution, powered by the identical expertise, to calculate embeddings to be used in imaginative and prescient functions.



