CogVLM, a robust open-source Giant Multimodal Mannequin (LMM), gives strong capabilities for duties like Visible Query Answering (VQA), Optical Character Recognition (OCR), and Zero-shot Object Detection.
On this information, I am going to stroll you thru deploying a CogVLM Inference Server with 4-bit quantization on Amazon Internet Companies (AWS). Let’s get began.
Setup EC2 Occasion
This part is essential even for these skilled with EC2. It should assist you to perceive the {hardware} and software program necessities for a CogVLM Inference Server.
To begin the method seek for EC2, then below ‘Cases’ click on the ‘Launch Cases’ button and fill out the shape in accordance with the specs under.
- GPU Reminiscence: The 4-bit quantized CogVLM mannequin requires 11 GB of reminiscence. Go for an NVIDIA T4 GPU, usually accessible in AWS g4dn cases. You would possibly must request a rise in your AWS quota to entry these cases.
- CUDA and Software program Necessities: Guarantee your machine has a minimum of CUDA 11.7 and Docker supporting NVIDIA. Selecting an OS Picture like ‘Deep Studying AMI GPU Pytorch’ simplifies the method.
- Community: For this setup, enable all incoming SSH and HTTP visitors for safe entry and net connections.
- Keys: Create and securely retailer an SSH key for accessing your machine.
- Storage: Allocate round 50 GB for the Docker picture and CogVLM mannequin weights, with a little bit additional house as a buffer.
Setup Inference Server
As soon as logged in by way of SSH utilizing your domestically saved key, proceed with the next steps:
- Verify CUDA Model, GPU Accessibility, and Confirm Docker and Python Installations.
# confirm GPU accessibility and CUDA model
nvidia-smi # confirm Docker set up
docker --version
nvidia-docker --version # confirm Python set up
python --version- Set up Python packages and begin the Inference Server.
# set up required python packages
pip set up inference==0.9.7rc2 inference-cli==0.9.7rc2 # begin inference server
inference server beginThis step entails downloading a big Docker picture (11GB) to run CogVLM, which could take a couple of minutes.
- Run
docker psto ensure the server is operating. You must see aroboflow/roboflow-inference-server-gpu:newestcontainer operating within the background.
Run Inference
To check the CogVLM inference, use a consumer script accessible on GitHub:
- Clone the repository and arrange the atmosphere.
# clone cog-vlm-client repository
git clone https://github.com/roboflow/cog-vlm-client.git
cd cog-vlm-client # setup python atmosphere and activate it [optional]
python3 -m venv venv
supply venv/bin/activate # set up required dependencies
pip set up -r necessities.txt # obtain instance information [optional]
./setup.sh- Purchase your Roboflow API key and export it as an atmosphere variable to authenticate to the Inference Server.
export ROBOFLOW_API_KEY="xSI558nrSshjby8Y4WMb"- Run the Gradio app and question photos.
python app.pyThe Gradio app will generate for you a novel hyperlink that you need to use to question your CogVLM mannequin from any pc or cellphone.
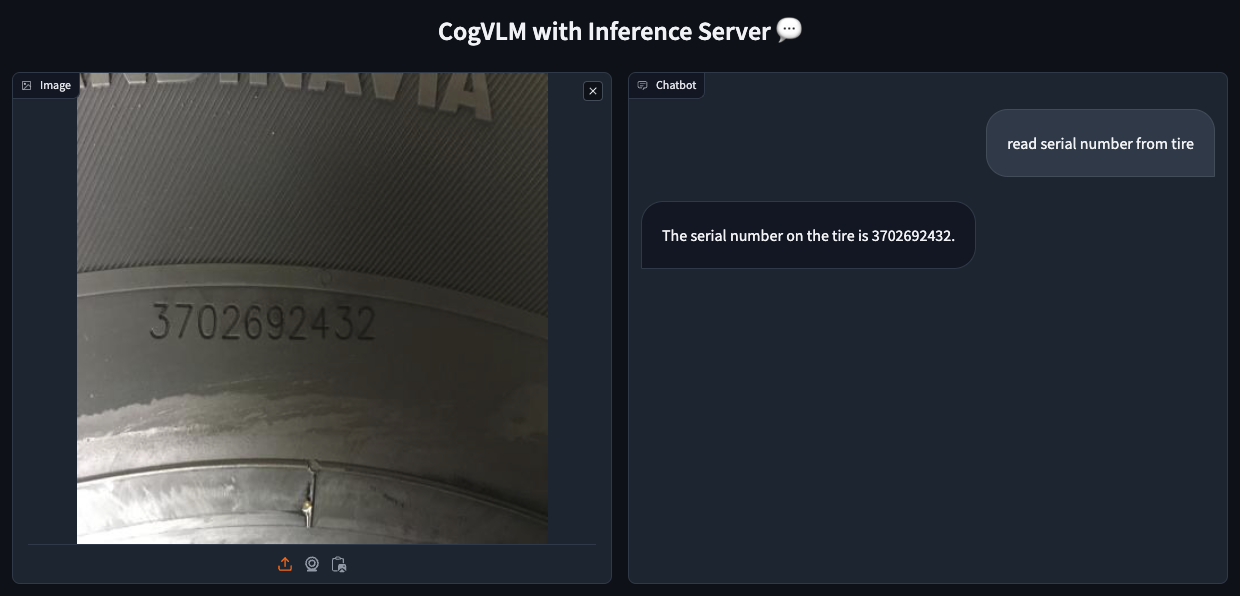
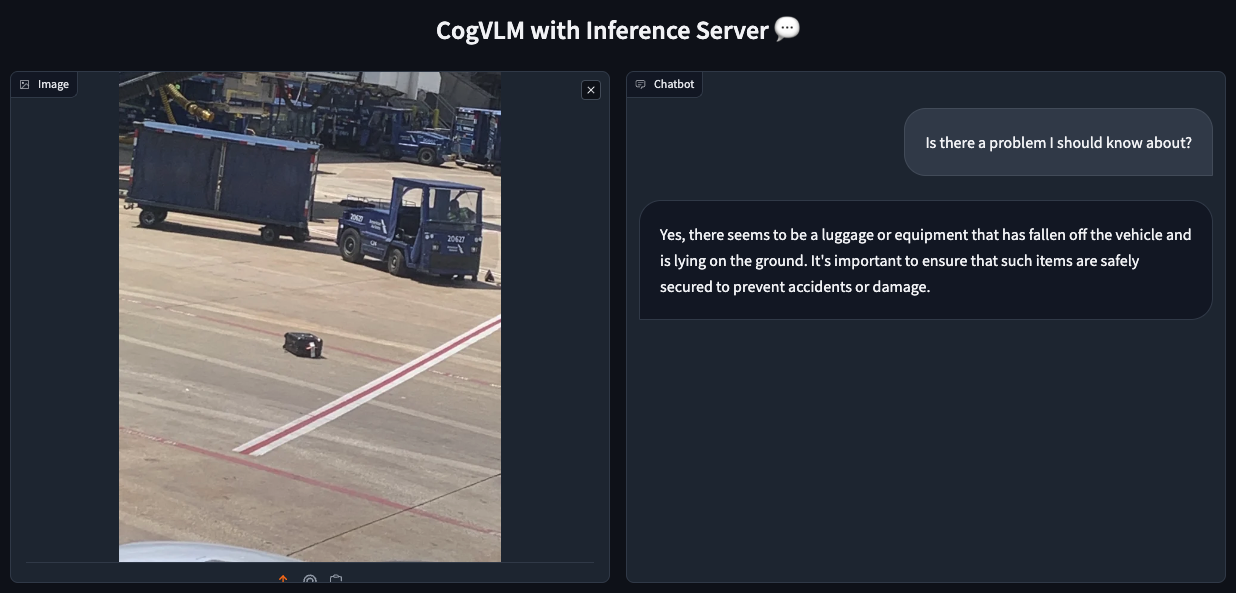
Be aware: The primary request to the server would possibly take a number of minutes because it hundreds mannequin weights into the GPU reminiscence. Monitor this course of utilizing docker system df and nvidia-smi. Subsequent requests shouldn’t take longer than a dozen seconds.
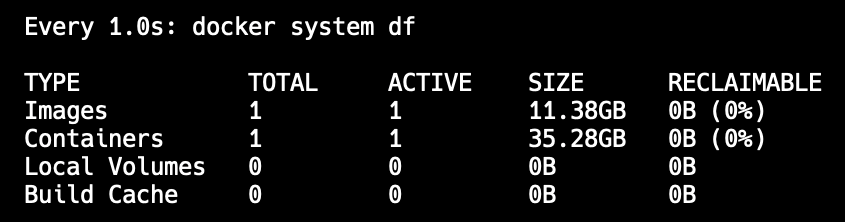
docker system df output after loading the Inference Server picture and CogVLM weights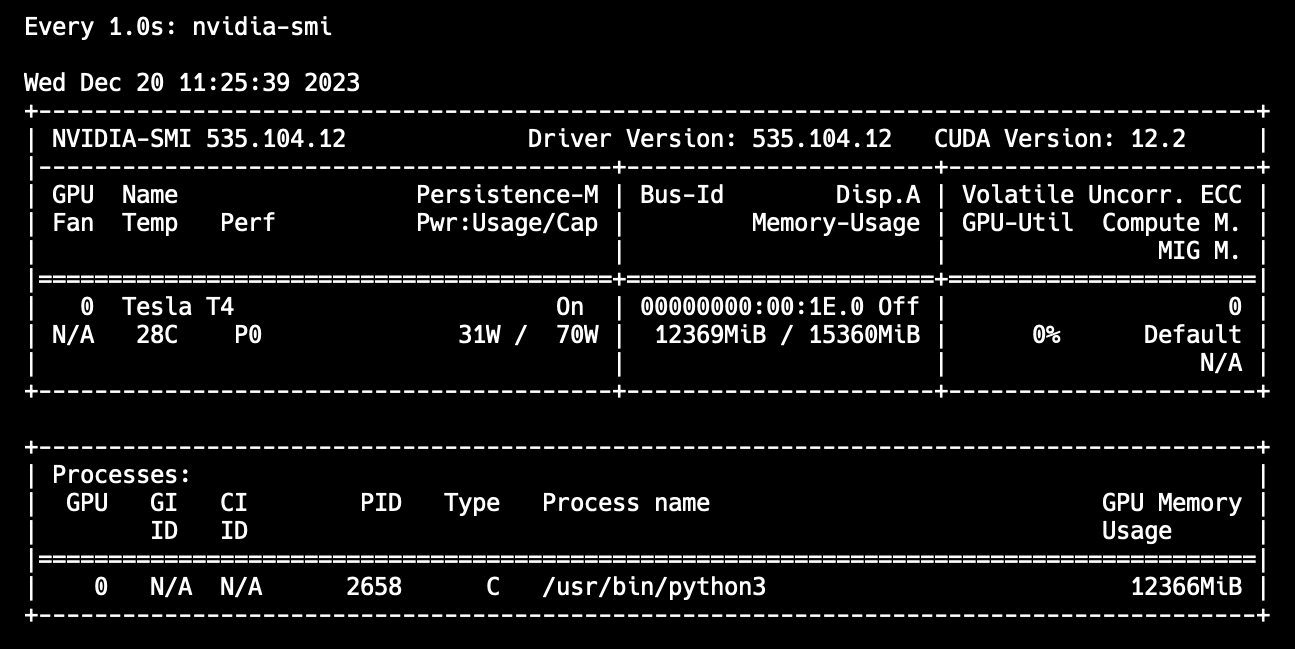
nvidia-smi output after loading CogVLM weights into reminiscence Conclusions
CogVLM is a flexible and highly effective LMM, adept at dealing with a spread of pc imaginative and prescient duties. In lots of instances, it could efficiently substitute GPT-4V and offer you extra management. Go to the Inference documentation to discover ways to deploy CogVLM in addition to different pc imaginative and prescient fashions.



