
Introduction
In our earlier blogs, we mentioned the most effective institutes internationally for pc imaginative and prescient analysis. On this enjoyable learn, we’ll have a look at the totally different levels of Pc Imaginative and prescient analysis and how one can go about publishing your analysis work. Allow us to delve into them now.
Trying to turn into a Pc Imaginative and prescient Engineer? Take a look at our Complete Information!
Desk of Contents
Totally different Levels of Pc Imaginative and prescient Analysis
Pc Imaginative and prescient Analysis will be put into varied levels, one constructing to the subsequent. Allow us to have a look at them intimately.
Identification of Drawback Assertion
Pc Imaginative and prescient analysis begins with figuring out the issue assertion. It’s a essential step in defining the scope and objectives of a analysis venture. It includes clearly understanding the precise problem or process the researchers intention to deal with utilizing pc imaginative and prescient methods. Listed below are the steps concerned in figuring out the issue assertion in pc imaginative and prescient analysis:
- Drawback Assertion Evaluation: Step one is to pinpoint the precise utility area inside pc imaginative and prescient. This could possibly be associated to object recognition in autonomous autos or medical picture evaluation for illness detection.
- Defining the issue: Subsequent, we outline the exact drawback we need to resolve inside that area, like classifying photos of animals or diagnosing ailments from X-rays.
- Understanding the aims: We have to perceive the analysis aims and description what we intend to attain by way of this venture. As an illustration, enhancing classification accuracy or decreasing false positives in a medical imaging system.
- Knowledge availability: Subsequent, we have to analyze the provision of knowledge for our venture. Examine if present datasets are appropriate for our process or if we have to collect our personal information, like amassing photos of particular objects or medical instances.
- Evaluate: Conduct an intensive assessment of present analysis and the newest methodologies within the subject. This may make it easier to acquire insights into the present state-of-the-art methods and the challenges others have confronted in related tasks.
- Query formulation: As soon as we assessment the work, we will formulate analysis inquiries to information our experiments. These questions may handle particular features of our pc imaginative and prescient drawback and assist higher construction our analysis.
- Metrics: Subsequent, we outline the analysis metrics that we’ll use to measure the efficiency of our imaginative and prescient system. Some widespread metrics embrace accuracy, precision, recall, and F1-score.
- Highlighting: Spotlight how fixing the issue will have an impact in the actual world. As an illustration, enhancing highway security by way of higher object recognition or enhanced medical diagnoses for early therapy.
- Analysis Define: Lastly, define the analysis plan, and element the methodology employed for information assortment, mannequin improvement, and analysis. A structured define will guarantee we’re heading in the right direction all through our analysis venture.

Allow us to transfer to the subsequent step, information assortment and creation.
Dataset Assortment and Creation
Creating and gathering datasets is likely one of the key constructing blocks in pc imaginative and prescient analysis. These datasets facilitate the algorithms and fashions utilized in imaginative and prescient programs. Allow us to see how that is completed.
- Firstly we have to know what we are attempting to unravel. As an illustration, are we coaching fashions to acknowledge canines in pictures or determine anomalies in medical photos?
- Now, we’ll want photos or movies. Relying on the analysis wants, we will discover them on public datasets or accumulate our personal.
- Subsequent, we mark up the information. As an illustration, in case you’re instructing a pc to identify canines in footage, you’ll draw packing containers across the automobiles and say, “These are canines!”
- Uncooked information generally is a mess. We could must resize photos, regulate colours, or add extra examples to make sure our dataset is neat and full.
- Divide the dataset into components,
- 1-part for coaching your mannequin
- 1-part for fine-tuning
- 1-part for testing how nicely your mannequin works
- Subsequent, make sure the dataset pretty represents the actual world and doesn’t favor one group or class an excessive amount of.
One may also share their dataset and analysis with others for inputs and enhancements. Dataset assortment and creation are important in pc imaginative and prescient analysis.
Exploratory Knowledge Evaluation
Exploratory Knowledge Evaluation (EDA) briefly analyzes a dataset to reply preliminary questions and information the modeling course of. As an illustration, this could possibly be in search of patterns throughout totally different courses. This isn’t solely utilized by Pc Imaginative and prescient Engineers but in addition Knowledge Scientists to make sure that the information they supply are aligned with totally different enterprise objectives or outcomes. This step includes understanding the specifics of picture datasets. As an illustration, EDA is used to identify anomalies, perceive information distribution, or acquire insights to additional mannequin coaching. Allow us to have a look at the function of EDA in mannequin improvement.
- With EDA, one can develop information preprocessing pipelines and select information augmentation methods.
- We are able to analyze how the findings from EDA can have an effect on the selection of mannequin structure. As an illustration, the necessity for some convolutional layers or enter photos.
- EDA can also be essential for superior Pc Imaginative and prescient duties like object detection, segmentation, and picture era backed by research.
Supply
Now allow us to dive into the specifics of EDA strategies and making ready picture datasets for mannequin improvement.
Visualization
- Pattern Picture Visualization includes displaying a random set of photos from the dataset. It is a basic step the place we get an concept of the information like lighting situations or variations in picture high quality. From this, one can infer the visible range and any challenges within the dataset.
- Analyzing the pixel distribution intensities affords insights into the brightness and distinction variations throughout the dataset if there may be any want for picture enhancement methods.
- Subsequent, creating histograms for various coloration channels offers us a greater understanding of the colour distribution of the dataset. It is a essential step for duties resembling picture classification.
Picture Property Evaluation
- One other essential half is knowing the decision and the facet ratio of photos within the dataset. It helps make choices like resizing the picture or normalizing the facet ratio, which is essential in sustaining consistency in enter information for neural networks.
- Analyzing the dimensions and distribution of annotated objects will be insightful in datasets with annotations. This influences the design layers within the neural community and understanding the size of objects.
Correlation Evaluation
- With some superior EDA processes like excessive dimensional picture information, analyzing the relation between totally different options is useful. This may help with dimensionality discount or characteristic choice.
- Subsequent, it’s essential to grasp the spatial correlations inside photos, like the connection between totally different areas in a picture. It helps within the improvement of spatial hierarchies in neural networks.
Class Distribution Evaluation
- EDAs are essential in understanding the imbalances at school distribution. That is key in classification duties the place imbalanced information can result in biased fashions.
- As soon as the imbalances are recognized, we will undertake methods like undersampling majority courses or oversampling minority courses throughout mannequin coaching.
Geometric Evaluation
- Understanding geometric properties like edges, shapes, and textures in photos affords insights into the options essential for the issue at hand. We are able to make knowledgeable choices on deciding on particular filters or layers within the community structure.
- It’s essential to grasp how totally different morphological transformations have an effect on photos for segmentation and object detection duties.
Sequential Evaluation
The sequential evaluation applies to video information.
- As an illustration, analyzing adjustments between frames can provide data like movement, temporal consistency, or the necessity for temporal modeling in video datasets or video sequences.
- Figuring out temporal variations and scene adjustments offers us insights into the dynamics throughout the video information which might be essential for duties like occasion detection or motion recognition.
Now that we’ve mentioned Exploratory Knowledge Evaluation and a few of its methods allow us to transfer to the subsequent stage in Pc Imaginative and prescient analysis, defining the mannequin structure.
Defining Mannequin Structure
Defining a mannequin structure is a vital part of analysis in pc imaginative and prescient, because it lays the muse for a way a machine studying mannequin will understand, course of, and interpret visible information. We analyze a mannequin that impacts the flexibility of the mannequin to be taught from visible information and carry out duties like object detection or semantic segmentation.
Mannequin structure in pc imaginative and prescient refers back to the structural design of a man-made neural community. The structure defines how the mannequin processes enter photos, extracts options, and makes predictions and classifications.
What are the elements of a mannequin structure? Let’s discover them.

Enter Layer
That is the place the mannequin receives the picture information, principally within the type of a multi-dimensional array. For coloured photos, this could possibly be a 3D array the place coloration channels present RGB values. Preprocessing steps like normalization are utilized right here.
Convolutional Layers
These layers apply a set of filters to the enter. Each filter convolves throughout the width and peak of the enter quantity, computing the dot product between the entries of the filter and the enter, producing a 2D activation map for every filter. Preserving the connection between pixels captures spatial hierarchies within the picture.
Activation Capabilities
Activation capabilities facilitate networks to be taught extra complicated representations by introducing them to non-linear properties. As an illustration, the ReLU (Rectified Linear Unit) perform applies a non-linear transformation (f(x) = max(0,x)) that retains solely constructive values and units all adverse values to zero. Different capabilities embrace sigmoid and tanh.
Pooling Layers
These layers are used to carry out a down-sampling operation alongside the spatial dimensions (width, peak), decreasing the variety of parameters and computations within the community. As an illustration, Max pooling, a typical strategy, takes the utmost worth from a set of values within the filter space, is a typical strategy. This operation affords spatial variance, making the popularity of options within the enter invariant to scale and orientation adjustments.
Absolutely Related Layers
Right here, the layers join each neuron in a single layer to each neuron within the subsequent layer. In a CNN, the high-level reasoning within the neural community is carried out through these dense layers. Usually, they’re positioned close to the top of the community and are used to flatten the output of convolutional and pooling layers to kind a single vector of options used for ultimate classification or regression duties.
Dropout Layers
Dropout is a regularization approach the place randomly chosen neurons are ignored throughout coaching. Because of this the contribution of those neurons to activate the downstream neurons is eliminated temporally on the ahead go and any weight updates usually are not utilized to the neuron on the backward go. This helps in stopping overfitting.
Batch Normalization
In batch normalization, the output from a earlier activation layer is normalized by subtracting the batch imply after which dividing it by the usual deviation of the batch. This system helps stabilize the educational course of and considerably reduces the variety of coaching epochs required for deep community coaching.
Loss Operate
The distinction between the anticipated outcomes and the predictions made by the mannequin is quantified by the loss perform. Cross-entropy for classification duties and imply squared error for regression duties are a few of the widespread loss capabilities in pc imaginative and prescient.
Optimizer
The optimizer is an algorithm used to attenuate the loss perform. It updates the community’s weights primarily based on the loss gradient. Some widespread optimizers embrace Stochastic Gradient Descent (SGD), Adam, and RMSprop. They use backpropagation to find out the course during which every weight ought to be adjusted to attenuate the loss.
Output Layer
That is the ultimate layer, the place the mannequin’s output is produced. The output layer usually features a softmax perform for classification duties that converts the outputs to likelihood values for every class. For regression duties, the output layer could have a single neuron.
Frameworks like TensorFlow, PyTorch, and Keras are broadly used for designing and implementing mannequin architectures. They provide pre-built layers, coaching routines, and simple integration with {hardware} accelerators.
Defining a mannequin structure requires a great grasp of each the theoretical features of neural networks and the sensible features of the precise process.
Coaching and Validation
Coaching and validation are essential in creating a mannequin. They assist consider a mannequin’s efficiency, particularly when coping with object detection or picture classification duties.
Supply
Coaching
On this section, the mannequin is represented as a neural community that learns to acknowledge picture patterns and options by altering its inside parameters iteratively. These parameters are weights and biases associated to the community’s layers. Coaching is vital for extracting significant options from uncooked visible information. Allow us to see how one can go about coaching a mannequin.
- Buying a dataset is step one. It could possibly be within the type of photos or movies for mannequin studying functions. For robustness, they cowl varied environmental situations, variations, and object courses.
- The subsequent step is information preprocessing. This includes resizing, normalization, and augmentation.
- Resizing is the place all of the enter information has the identical dimensions for batch processing.
- In Normalization, pixels are standardized to zero imply and unit variance, aiding convergence.
- Augmentation applies random transformations to extend the dimensions of the dataset artificially, thereby enhancing the mannequin’s capability to generalize.
- As soon as information preprocessing is completed, we should select the suitable neural community structure catering to the precise imaginative and prescient process. As an illustration, CNNs are broadly used for image-related duties.
- Subsequent, we initialize the mannequin parameters, normally weights, and biases, utilizing random values or pre-trained weights from a mannequin skilled on a easy dataset. Switch studying can considerably enhance efficiency, particularly when information is proscribed.
- Then we will optimize the algorithm to regulate its parameters iteratively with stochastic gradient descent (SGD) or RMSprop. Gradients in relation to the mannequin’s parameters are computed by way of backpropagation that are used to replace the parameters.
- As soon as the algorithm is optimized, the information is skilled in mini-batches by way of the community, computing the loss for every mini-batch and performing gradient updates. This occurs till the loss falls under a predefined threshold.
- Subsequent, we should optimize the coaching efficiency and convergence velocity by fine-tuning the hyperparameters. This might completed by optimizing studying charges, batch sizes, weight regulation phrases, or community architectures.
- We have to assess the mannequin’s efficiency utilizing validation or take a look at datasets and finally deploy the mannequin in real-world functions by way of software program integrations or embedded units.
Now allow us to transfer to the subsequent step- Validation.
Validation
Validation is prime for the quantitative evaluation of efficiency and generalization capabilities of algorithms. It ensures the reliability and effectiveness of the fashions when utilized to real-world information. Validation evaluates the flexibility of a mannequin to make correct predictions of beforehand unseen information therefore having the ability to gauge its capability for generalization.
Now allow us to discover a few of the key methods concerned in validation.
Cross-Validation Methods
- Okay-Fold Cross-Validation is the strategy the place the dataset is partitioned into Okay non-overlapping subsets. The mannequin is skilled and evaluated Okay instances, with every fold taking turns because the validation set whereas the remaining function the coaching set. The outcomes are averaged to acquire a strong efficiency estimate.
- Go away-One-Out Cross-Validation or LOOCV is an excessive type of cross-validation the place every information level is used because the validation set whereas the remaining information factors represent the coaching set.LOOCV affords an exhaustive analysis of mannequin efficiency.
Stratified Sampling
In some imbalanced datasets the place a number of courses have considerably fewer situations than others, stratified sampling ensures the stability between coaching and validation units for the distribution of courses.
Efficiency Metrics
To evaluate the mannequin’s efficiency, a spread of efficiency metrics specified for pc imaginative and prescient duties are deployed. They don’t seem to be restricted to the next.
- Accuracy is the ratio of the accurately predicted situations to the entire variety of situations.
- Precision is the proportion of true constructive predictions amongst all constructive predictions.
- Recall is the proportion of true constructive predictions amongst all constructive situations.
- F1-Rating is the harmonic imply of precision and recall.
- Imply Common Precision (mAP)is often utilized in object detection and picture retrieval duties to judge the standard of ranked lists of outcomes.
Hyperparameter Tuning
Validation is carefully built-in with hyperparameter tuning, the place the mannequin’s hyperparameters are systematically adjusted and evaluated utilizing the validation set. Methods resembling grid search, random search, or Bayesian optimization assist determine the optimum hyperparameter configuration for the mannequin.
Knowledge Augmentation
Knowledge augmentation methods are utilized to check the mannequin’s robustness and the flexibility to deal with totally different situations or transformations throughout validation to simulate variations within the enter information.
Coaching is the place the mannequin learns from labeled information, and Validation is the place the mannequin’s studying and generalization capabilities are assessed. They be certain that the ultimate mannequin is strong, correct, and able to performing nicely on unseen information, which is vital for pc imaginative and prescient analysis.
Hyperparameter Tuning
Hyperparameter tuning refers to systematically optimizing hyperparameters in deep studying fashions for duties like picture processing and segmentation. They management the educational algorithm’s efficiency however didn’t be taught from the coaching information. Advantageous-tuning hyperparameters are essential if we want to obtain correct outcomes.
Allow us to have a look at a few of the essential hyperparameters for mannequin coaching. 
Batch Dimension
It’s the variety of coaching examples utilized in each ahead and backward go. Giant batch sizes provide smoother convergence however want extra reminiscence. Quite the opposite, small batch sizes want much less reminiscence and can assist escape native minima.
Variety of Epochs
The Variety of epochs defines how typically the complete coaching dataset is processed throughout coaching. Too few epochs can result in underfitting, and too many can result in overfitting.
Studying Price
This determines the step dimension throughout gradient-based optimization. If the educational price is simply too excessive, it might probably result in overshooting, inflicting the loss perform to diverge, and if the educational price is simply too quick, it might probably trigger sluggish convergence.
Weight Initialization
The coaching stability is affected by the initialization of weights. Methods resembling Glorot initialization are designed to deal with the vanishing gradient issues.
Regularization Methods
Some methods like dropout and weight decay help in stopping overfitting. The mannequin generalization is enhanced by way of random rotations utilizing information augmentation.
Selection of Optimizer
The updates throughout coaching for mannequin weights are decided by the optimizer. They’ve their parameters like momentum, decay charges and epsilon.
Hyperparameter tuning is normally approached as an optimization drawback. Few methods like Bayesian optimization effectively discover the hyperparameter area balancing computational prices and don’t slack on the efficiency. A well-defined hyperparameter tuning contains not simply adjusting particular person hyperparameters but in addition additionally considers their interactions.
Efficiency Analysis on Unseen Knowledge
Within the earlier part, we mentioned how one should go about doing the coaching and validation of a mannequin. Now we’ll focus on how one can consider the efficiency of a dataset on unseen information.
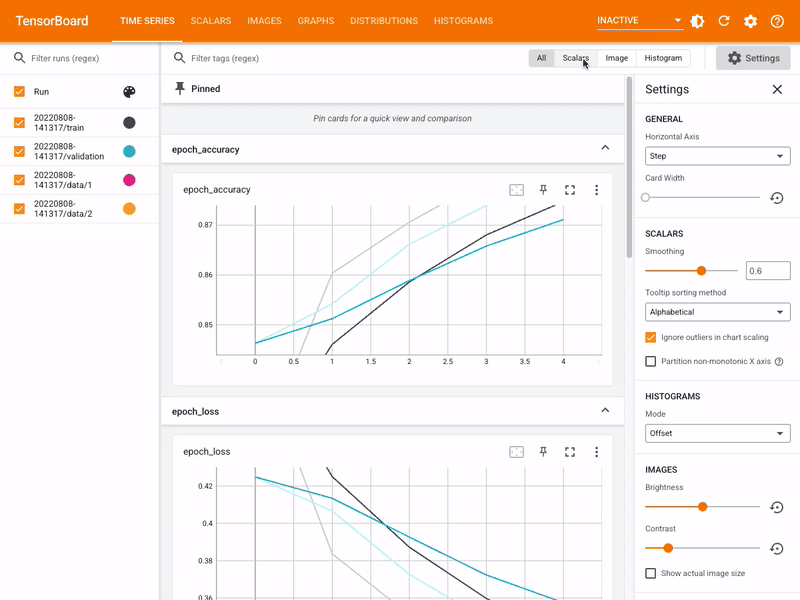
Supply
Coaching and validation dataset cut up is paramount when creating and evaluating fashions. This isn’t to be confused with the coaching and validation we mentioned earlier for a mannequin. Splitting the dataset for coaching and validation aids in understanding the mannequin’s efficiency on unseen information. This ensures that the mannequin generalizes nicely to new information. Allow us to have a look at them.
- A coaching dataset is a group of labeled information factors for coaching the mannequin, adjusting parameters, and inferring patterns and options.
- A separate dataset is used for evaluating the mannequin throughout improvement for hyperparameter tuning and mannequin choice. That is the Validation dataset.
- Then there may be the take a look at dataset, an unbiased dataset used for assessing the ultimate efficiency and generalization capability on unseen information.
Splitting datasets is required to stop the mannequin from coaching on the identical information. This may hinder the mannequin’s efficiency. Some generally used cut up ratios for the dataset are 70:30, 80:20, or 90:10. The bigger portion is used for coaching, whereas the smaller portion is used for validation.
Analysis Publications
You’ve got put a lot effort into your analysis paper. However how can we publish it? The place can we publish it? How do I discover the suitable pc imaginative and prescient analysis teams? That’s what this part covers, so let’s get to it.
Conferences
There are some top-tier pc imaginative and prescient conferences occurring throughout the globe. They’re among the many finest locations to showcase analysis work, search for future collaborations, and construct networks.
Convention on Pc Imaginative and prescient and Sample Recognition (CVPR)
Additionally known as the CVPR, it is likely one of the most prestigious conferences on the earth of Pc Imaginative and prescient. It’s organized by the IEEE Pc Society and is an annual occasion. It has an incredible historical past of showcasing cutting-edge analysis papers in picture evaluation, object detection, deep studying methods, and far more. CVPR has set the bar excessive, putting a robust emphasis on the technical features of the submissions. They have to meet the next standards.
Papers should possess an revolutionary contribution to the sector. This could possibly be the event of recent algorithms, methods, or methodologies that may convey developments in pc imaginative and prescient.
If relevant, the submissions should have mathematical formulations of their strategies, like equations and theorem proofs. This affords a stable theoretical basis for the paper’s strategy.
Subsequent, the paper ought to embrace complete experimental outcomes involving many datasets and benchmarking towards present fashions. These are key to demonstrating the effectiveness of your proposed strategy.
Readability – it is a no-brainer; the writing and presentation should be clear and concise. The writers are anticipated to elucidate the algorithms, fashions, and leads to a technically sound method.

CVPR is an incredible platform for networking and interesting with the neighborhood. It’s a fantastic place to satisfy lecturers, researchers, and business consultants to collaborate and alternate concepts. The acceptance price for papers is barely 25.8% therefore the popularity throughout the imaginative and prescient neighborhood is spectacular. It typically results in citations, higher visibility, and potential collaborations with famend researchers and professionals.
Worldwide Convention on Pc Imaginative and prescient (ICCV)
The ICCV is one other premier convention held yearly as soon as, providing an incredible platform for cutting-edge pc imaginative and prescient analysis. Very similar to the CVPR, the ICCV can also be organized by the IEEE Pc Society, attracting worldwide visionaries, researchers, and professionals. Matters vary from object detection and recognition all the best way to computational images. ICCV invitations authentic papers providing a big contribution to the sector. The factors for submissions are similar to the CVPR. They have to possess mathematical formulations, algorithms, experimental methodology, and outcomes. ICCV adopts peer assessment so as to add a layer of technical rigor and high quality to the accepted papers. Submissions normally endure a number of levels of assessment, giving detailed suggestions on the technical features of the analysis paper. The acceptance charges at ICCV are usually low at 26.2%.
Moreover the primary convention, the ICCV hosts workshops and tutorials that supply in-depth discussions and displays in rising analysis areas. It additionally affords challenges and competitions related to pc imaginative and prescient duties like picture segmentation and object detection.
Just like the CVPR, it affords wonderful alternatives for future collaborations, networking with friends, and exchanging concepts. The papers accepted on the ICCV are usually printed within the IEEE Pc Society and made out there to the imaginative and prescient neighborhood. This affords vital visibility and recognition to researchers for papers which might be accepted.
European Convention on Pc Imaginative and prescient (ECCV)
The European Convention on Pc Imaginative and prescient, or ECCV, is one other complete convention if you’re in search of the highest pc imaginative and prescient conferences globally. The ECCV lays a whole lot of emphasis on the scientific and technical high quality of the paper. Just like the above two conferences we mentioned, it emphasizes how the researcher incorporates the mathematical foundations, algorithms, and detailed derivations and proofs with in depth experimental evaluations.
Based on the ECCV formatting pointers, the analysis paper ideally ranges from 10 to 14 pages. It adopts a double-blind peer assessment, the place the researchers should make their submissions nameless to curb any discrepancies.

ECCV additionally affords big alternatives for collaborations and establishing connections. With an acceptance price of 31.8%, a researcher can profit from tutorial recognition, excessive visibility, and citations.
Winter Convention on Purposes of Pc Imaginative and prescient (WACV)
WACV is a high worldwide pc imaginative and prescient occasion with the primary convention and some workshops and tutorials. Very similar to the opposite conferences, it’s held yearly. With an acceptance price under 30%, it attracts main researchers and business professionals. The convention normally takes place within the first week of January.

Journals
As a pc imaginative and prescient researcher, one should publish one’s works in journals to point out your findings and provides extra insights into the sector. Allow us to have a look at a number of of the pc imaginative and prescient journals.
Transactions on Sample Evaluation and Machine Intelligence (TPAMI)
Additionally known as the TPAMI, this journal focuses on the varied features of machine intelligence, sample recognition, and pc imaginative and prescient. It affords a hybrid publication allowing conventional or author-paid open-access manuscript submissions.
With open-access manuscripts, the paper has unrestricted entry to it by way of the IEEE Xplore and Pc Society Digital Library.
Relating to conventional manuscript submissions, the IEEE Pc Society has varied award-winning journals for publication. One can flick through the totally different matters that match their analysis. They typically publish particular sections on rising matters. Some elements you’ll want to think about are submission to publications time, bibliometric scores like influence issue, and publishing charges.
Worldwide Journal of Pc Imaginative and prescient (IJCV)
The IJCV affords a platform for brand spanking new analysis outcomes. With 15 points a yr, the Worldwide Journal of Pc Imaginative and prescient affords high-quality, authentic contributions to the sector of pc imaginative and prescient. The size of the articles ranges from 10-page common articles to as much as 30 pages for survey papers that supply state-of-the-art displays and outcomes. The analysis should cowl mathematical, physics, and computational features of pc imaginative and prescient, like picture formation, processing, interpretation, machine studying methods, and statistical approaches. Researchers usually are not charged to publish on IJCV. It’s not solely a journal that opens doorways for researchers to showcase their papers but in addition a goldmine of knowledge in deep studying, synthetic intelligence, and robotics.
Journal of Machine Studying Analysis (JMLR)
Established in 2000, JMLR is a discussion board for digital and paper publications of complete analysis papers. This platform covers matters like machine studying algorithms and methods, deep studying, neural networks, robotics, and pc imaginative and prescient. JMLR is freely out there to the general public. It’s run by volunteers, and the papers endure rigorous critiques, which function a precious useful resource for the newest updates within the subject.
You’ve invested weeks and months into this paper. Why not get the popularity and credibility your work deserves? The above Journals and Conferences provide the last word gateway for a researcher to showcase their works and open up a plethora of alternatives for educational and business collaborations.
Conclusion
In conclusion, our journey by way of the intricate world of pc imaginative and prescient analysis has been a enjoyable one. From the preliminary levels of understanding the issue statements to the ultimate steps of publication in pc imaginative and prescient analysis teams, we’ve comprehensively delved into every of them.
There isn’t a analysis, large or small; every affords its personal contributions to the ever-evolving subject of the Pc Imaginative and prescient area.

We’ve extra detailed posts coming your manner. Keep tuned! See you guys within the subsequent one!!
Associated Weblog Posts
<!–
–>



