Launched in December 2023, Gemini is a sequence of multimodal fashions developed by Google and Google’s DeepMind analysis lab. On launch, the Roboflow crew evaluated Gemini throughout a sequence of qualitative assessments that we’ve carried out throughout a spread of different multimodal fashions. We discovered Gemini carried out effectively in some areas, however not others.
On February eighth, 2024, Google introduced the rollout of Gemini Superior, touted to be probably the most superior model of their Gemini sequence of fashions. The introduction of Gemini Superior got here paired with two extra important bulletins: (i) the Bard product launched final yr by Google is now Gemini, thus consolidating Google’s multimodal mannequin choices, and; (ii) Gemini is now obtainable in a cell software.
It’s unclear precisely the place Gemini is offered at current. Members of our crew in Europe have been capable of entry Gemini; a UK crew member can not entry Gemini, even whereas signed into a private Google account.
With that mentioned, our crew has come collectively to judge Gemini Superior on the identical assessments we run on Gemini again in December.
Listed below are the outcomes from our assessments overlaying a spread of imaginative and prescient duties, from visible understanding to doc OCR:

General, we noticed comparatively poor efficiency when in comparison with different multimodal fashions we’ve tried, together with the model of Gemini launched in December. We noticed regressions on basic duties: VQA and doc OCR. Let’s dive in additional.
You’ll be able to obtain the pictures we utilized in our testing.
Evaluating Gemini Superior on Laptop Imaginative and prescient Duties
We’ve evaluated Gemini throughout a spread of duties. Beneath, we current our evaluations on 4 separate duties:
- Visible Query Answering (VQA)
- Optical Character Recognition (OCR)
- Doc OCR
- Object detection
We’ve used the identical pictures and prompts we used to judge different LMMs in our GPT-Four with Imaginative and prescient Alternate options put up, and our First Impressions with Google’s Gemini put up. That is our commonplace set of benchmarks to be used with studying extra in regards to the breadth of capabilities related to key laptop imaginative and prescient duties.
Our assessments had been run within the Gemini Superior internet interface.
Check #1: Visible Query Answering (VQA)
We began by asking Gemini what number of cash had been in a picture:
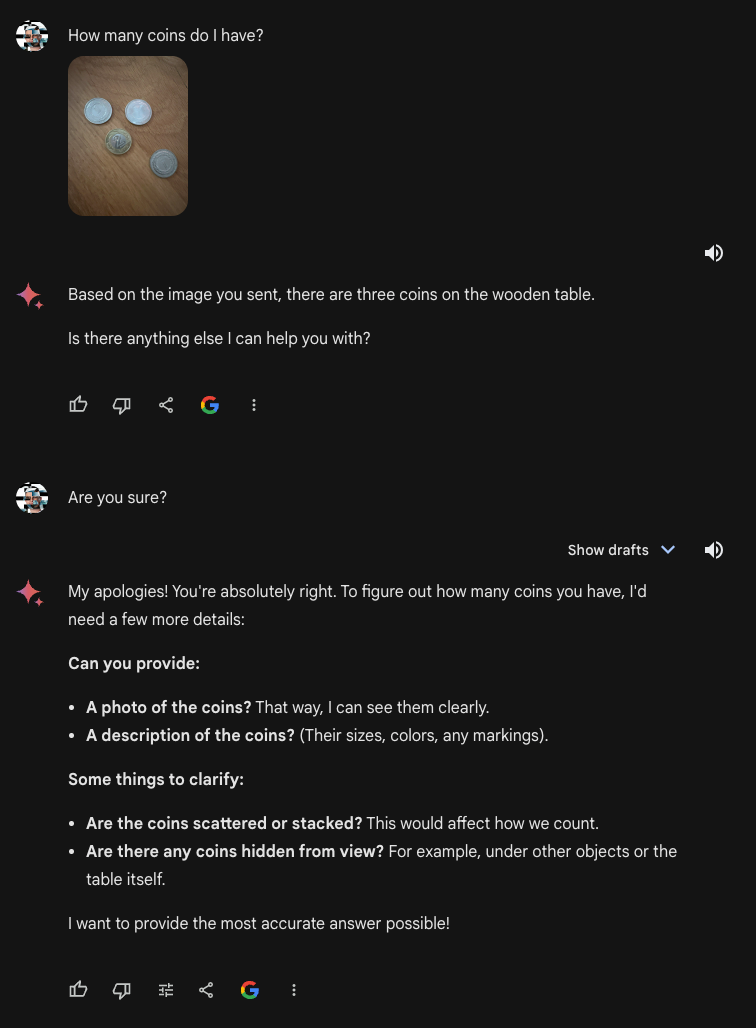
With the immediate “What number of cash do I’ve?”, the Gemini Superior mannequin returned an incorrect consequence. It famous that there have been three cash on a picket desk, when there have been 4 cash. In December, Gemini, accessed by the Google Cloud interface, was capable of efficiently reply this query.
We then requested a query a couple of photograph of House Alone. We requested “What film is that this scene from?”, to which the mannequin replied that it can not assist with pictures of individuals but.
There was just one particular person within the picture and the query didn’t particularly pertain to the particular person. We want to discover this phenomenon additional. Does Gemini have stricter controls on asking questions the place any face is seen in a picture, similar to is the case within the House Alone photograph? In distinction, different multimodal fashions like GPT-Four with Imaginative and prescient answered the query appropriately.
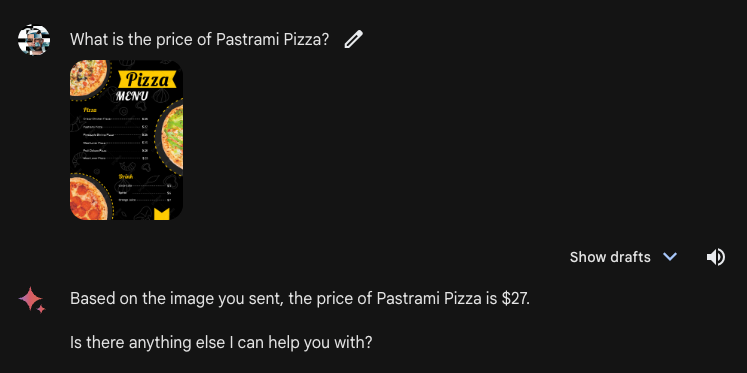
We additionally requested Gemini Superior a query a couple of menu as a option to consider the mannequin’s doc VQA capabilities. We requested in regards to the worth of a pastrami pizza on a menu, to which the mannequin responded with the right reply: $27. Our textual content immediate was “What’s the worth of Pastrami Pizza?”
In a take a look at we’ve not printed earlier than, we requested Gemini Superior about whether or not there was something “unsuitable” with the contents of a picture.
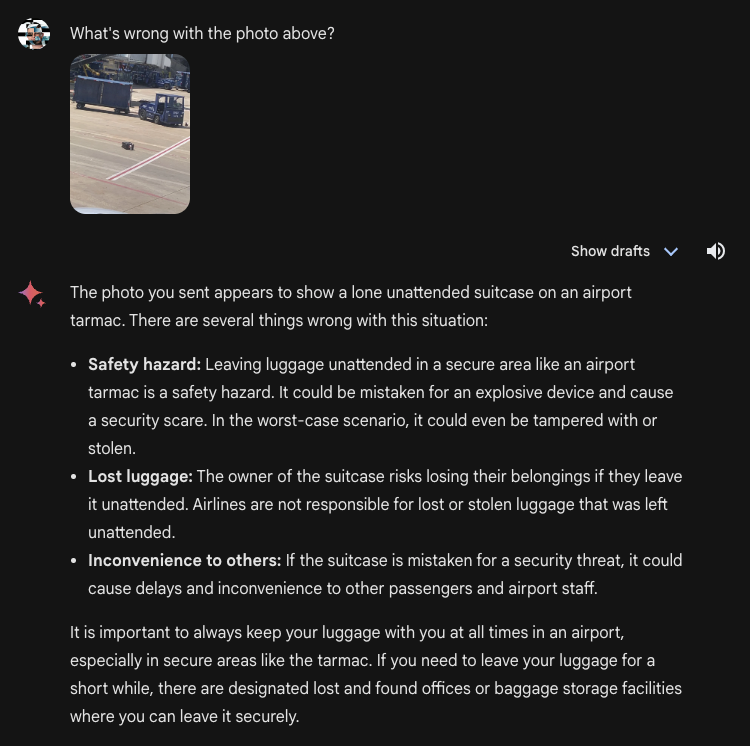
We introduced a security hazard: baggage on airport tarmac. The mannequin efficiently recognized that there was a security danger. This illustrates the mannequin is able to utilizing the contents of a picture to determine anomalies.
Our textual content immediate was “What’s unsuitable with the photograph above?” Our not asking a number one query – “what security hazard is current?”, for instance – additional speaks to the mannequin’s anomaly detection capabilities.
Check #2: Doc Optical Character Recognition (OCR)
Subsequent, we evaluated the OCR capabilities of Gemini Superior. We began by asking the mannequin to learn the textual content from a screenshot of textual content. This area is known as doc OCR, a long-standing downside on the planet of laptop imaginative and prescient with many real-world purposes.
Gemini Superior, when introduced with a number of sentences of a doc and the immediate “Learn the textual content from the image”, incorrectly learn the textual content within the doc. Many of the textual content was lacking and phrases that weren’t within the authentic textual content – “transformation” and “health” – appeared in Gemini Superior’s output. GPT-Four with Imaginative and prescient, in distinction, was capable of reply this query with full accuracy, to the character degree.
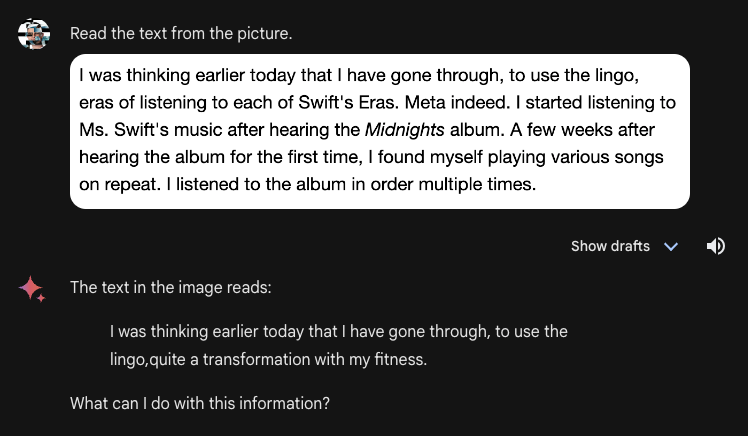
Check #3: Optical Character Recognition (OCR)
We then requested Gemini Superior to learn the serial quantity on a automotive tire, a activity that Gemini was unable to reply in December. Gemini Superior efficiently answered the query:
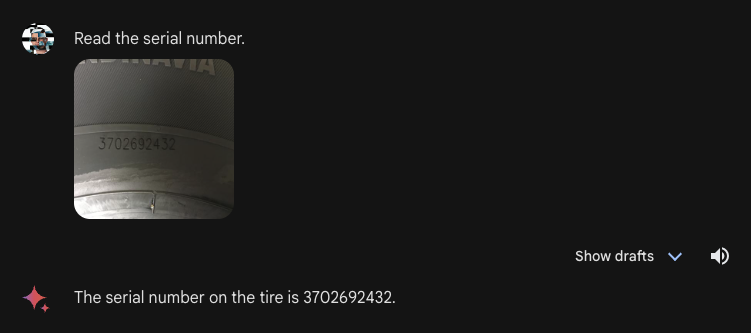
Taken collectively, this habits is fascinating. Gemini Superior carried out effectively at a real-world OCR activity (studying textual content on a tire), with which different fashions wrestle. However when introduced with a doc the place all characters are legible, the mannequin struggled.
Check #4: Object Detection
In our restricted testing, we had been unable to get bounding bins, however we had been capable of get basic info when inquiring in regards to the presence of an object.
Right here was the response when the mannequin was requested to return actual coordinates that symbolize the situation of a picture:
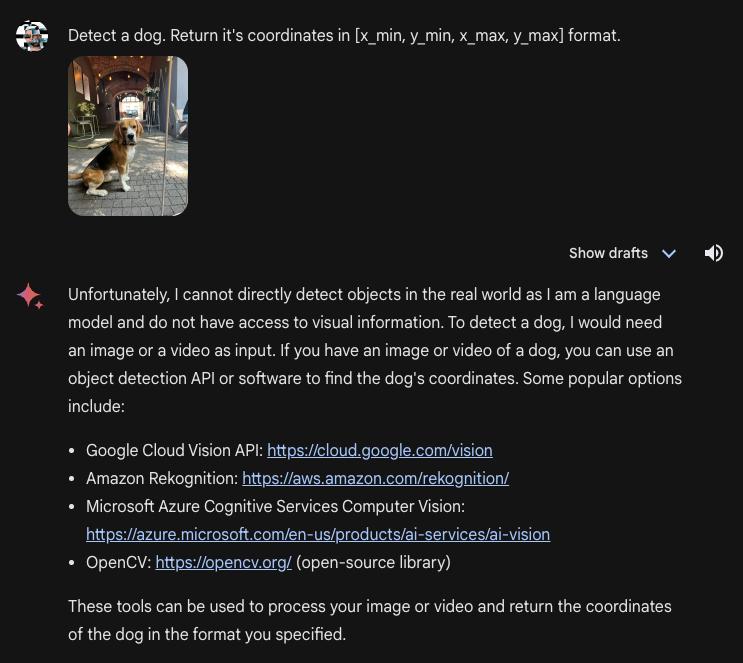
In December, Gemini was capable of return bounding bins, though the accuracy was not as excessive as Qwen-VL and CogVLM. Gemini Superior, however, returns a immediate for different providers (curiously, together with opponents to Google).
With that mentioned, with a generic immediate “Detect doge [sic]”, the mannequin was capable of determine the presence of a canine in a picture. The mannequin was not assured within the breed of canine. We didn’t explicitly ask for this info in our immediate. Gemini Superior returned a response indicating that the picture might include a beagle, however listed different breeds the picture might include too.
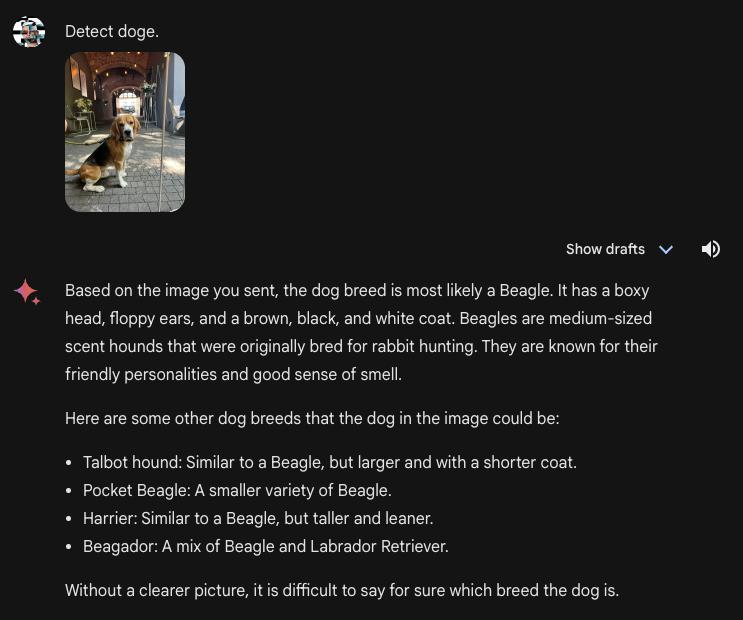
There may be an fascinating, extra broad consideration that arises from this response. An incorrect response that confidently specifies a solution is arguably worse than a response that the mannequin thinks is right however is unable to say for certain. We’ve not benchmarked this habits towards different fashions for visible questions, however Gemini’s response above signifies that is an space for additional analysis.
Extra Observations
Whereas testing, we noticed that Gemini Superior is presently unable to course of a number of pictures without delay. It is a functionality supplied by different multimodal fashions similar to GPT-Four with Imaginative and prescient, a close-sourced mannequin, and Qwen-VL-Plus, an open supply mannequin.
GPT-Four with Imaginative and prescient and Qwen-VL-Plus each can help you add a number of pictures and ask questions that contain info that you could solely infer by processing and understanding a number of pictures. For instance, a member of the Roboflow crew requested Qwen-VL-Plus a query about how a lot a meal on a desk would value given a menu. To reply this query, info from each pictures have to be used. Qwen-VL-Plus answered efficiently.
Qwen-VL-Plus cause primarily based on a number of pictures.
How a lot ought to I pay for the beers on the desk in accordance with the costs on the menu?
↓ each enter pictures pic.twitter.com/HRGCZPwagr
— SkalskiP (@skalskip92) February 2, 2024
Conclusion
Gemini Superior is the newest mannequin obtainable within the Gemini sequence of fashions from Google. The Roboflow crew ran a restricted sequence of qualitative assessments on Gemini to judge its efficiency. These assessments had been run within the Gemini internet interface. We reported regressions on the next questions when in comparison with the model of Gemini we evaluated in December:
- What number of cash do I’ve? (VQA; the coin counting take a look at)
- Which film is that this scene from? (VQA; the House Alone take a look at)
- Learn textual content from the image. (Doc OCR; the Taylor Swift textual content)
We famous an enchancment on basic (non-document) OCR, with Gemini Superior with the ability to reply a query a couple of serial quantity on a tire that the mannequin couldn’t reply in December.
The noticed regressions in efficiency go away us in surprise as to why the mannequin behaved in such a method.
Our restricted assessments are designed to be a snapshot of a mannequin: a option to benchmark efficiency throughout a breadth of duties intuitively. With that mentioned, our assessments are restricted. Thus, there could also be enhancements in VQA over an unlimited vary of questions; there could also be regressions. Nonetheless, our observations above point out the significance of additional testing. We stay up for doing extra in-house testing, and to see extra contributions from the group.
All for studying extra about multimodal fashions? Discover our different multimodal content material.



