Massive imaginative and prescient fashions like YOLO-World, a zero-shot open-vocabulary object detection mannequin by Tencent’s AI Lab, have proven spectacular efficiency. Whereas zero-shot detection fashions can detect objects with growing accuracy, smaller customized fashions have confirmed to be sooner and extra compute-efficient than massive fashions whereas being extra correct in particular domains and use circumstances.
Regardless of these tradeoffs, there’s an necessary profit to massive, zero-shot fashions: they require no knowledge labeling or mannequin coaching to make use of in manufacturing.
On this information, we show an method to making use of the advantages of YOLO-World whereas utilizing energetic studying for knowledge assortment to coach a customized mannequin. To do that, we’ll:
- Deploy YOLO-World utilizing Inference
- Combine energetic studying with our deployment
- Prepare a customized mannequin utilizing our routinely labeled knowledge
Step 1: Deploy YOLO-World
In a couple of steps, we will arrange YOLO-World to run on Roboflow Inference. First, we’ll set up our required packages:
pip set up -q inference-gpu[yolo-world]==0.9.12rc1
Then, we’ll import YOLO-World from Roboflow Inference, the place we’ll arrange the lessons that we wish to detect:
from inference.fashions.yolo_world.yolo_world import YOLOWorld mannequin = YOLOWorld(model_id="yolo_world/l") # There are a number of completely different sizes: s, m and l. lessons = ["book"] # Change this to no matter you wish to detect
mannequin.set_classes(lessons)
💡
Subsequent, we will run an inference on a pattern picture and see the mannequin in motion:
import supervision as sv
import cv2 picture = cv2.imread(IMAGE_PATH)
outcomes = mannequin.infer(picture, confidence=0.2) # Infer a number of occasions and mess around with this confidence threshold
detections = sv.Detections.from_inference(outcomes)Utilizing Supervision, we will visualize the predictions:
labels = [ f"{classes[class_id]} {confidence:0.3f}" for class_id, confidence in zip(detections.class_id, detections.confidence)
] annotated_image = picture.copy()
annotated_image = sv.BoundingBoxAnnotator().annotate(annotated_image, detections)
annotated_image = sv.LabelAnnotator().annotate(annotated_image, detections, labels=labels)
sv.plot_image(annotated_image)

Now we will begin working predictions with YOLO-World, and with a bit of additional code, we will begin to create a mannequin that’s sooner, extra environment friendly, and extra correct on the similar time.
Step 2: Lively Studying
First, to have a spot to retailer our knowledge, we’ll create a Roboflow mission for our guide detection mannequin.
As soon as that’s finished, we will entry our workspace with the Roboflow API utilizing Python. First, let’s set up the Roboflow Python SDK:
pip set up roboflowThen, we will entry our mission through the use of our API key and getting into our workspace and mission ID.
from roboflow import Roboflow rf = Roboflow(api_key="YOUR_ROBOFLOW_API_KEY")
mission = rf.workspace("*workspace_id*").mission("*project_id*")After that, we now have all we have to mix all of the earlier components of this information to create a perform that we will use to foretell with YOLO-World, whereas including these predictions to a dataset so we will practice a customized mannequin.
from inference.fashions.yolo_world.yolo_world import YOLOWorld
import supervision as sv
import cv2
from roboflow import Roboflow # Undertaking Setup (Copied From Earlier Part)
rf = Roboflow(api_key="YOUR_ROBOFLOW_API_KEY")
mission = rf.workspace("*workspace_id*").mission("*project_id*") # Mannequin Setup (Copied From Earlier Part)
mannequin = YOLOWorld(model_id="yolo_world/l") # There are a number of completely different sizes: s, m and l.
lessons = ["book"] # Change this to no matter you wish to detect
mannequin.set_classes(lessons) def infer(picture): outcomes = mannequin.infer(picture, confidence=0.1) detections = sv.Detections.from_inference(outcomes) image_id = str(uuid.uuid4()) image_path = image_id+".jpg" dataset = sv.DetectionDataset(lessons=lessons,photographs={image_path:picture},annotations={image_path:detections}) dataset.as_pascal_voc("dataset_upload/photographs","dataset_upload/annotations") mission.add( image_path=f"dataset_upload/photographs/{image_path}", annotation_path=f"dataset_upload/annotations/{image_id}.xml", batch_name="Bookshelf Lively Studying", is_prediction=True ) return detectionsYou possibly can change the infer perform to fit your deployment wants. For our instance, we plan to run detections on a video, and we don’t need nor want each single body to be uploaded, so we’ll modify our infer perform to add randomly 25% of the time:
def infer(picture): outcomes = mannequin.infer(picture, confidence=0.1) detections = sv.Detections.from_inference(outcomes) if random.random() < 0.25: print("Including picture to dataset") image_id = str(uuid.uuid4()) image_path = image_id+".jpg" dataset = sv.DetectionDataset(lessons=lessons,photographs={image_path:picture},annotations={image_path:detections}) dataset.as_pascal_voc("dataset_upload/photographs","dataset_upload/annotations") mission.add( image_path=f"dataset_upload/photographs/{image_path}", annotation_path=f"dataset_upload/annotations/{image_id}.xml", batch_name="Bookshelf Lively Studying", is_prediction=True ) return detectionsUtilizing Supervision and the next code, we’ll run inferences towards a video of a library:
def process_frame(body, i): print(i) detections = infer(body) annotated_image = body.copy() annotated_image = sv.BoundingBoxAnnotator().annotate(annotated_image, detections) return annotated_image sv.process_video("library480.mov","library_processed.mp4",process_frame)A video of visualized predictions from YOLO-World
Then, as you run inferences, you will notice photographs being added to your Roboflow mission.
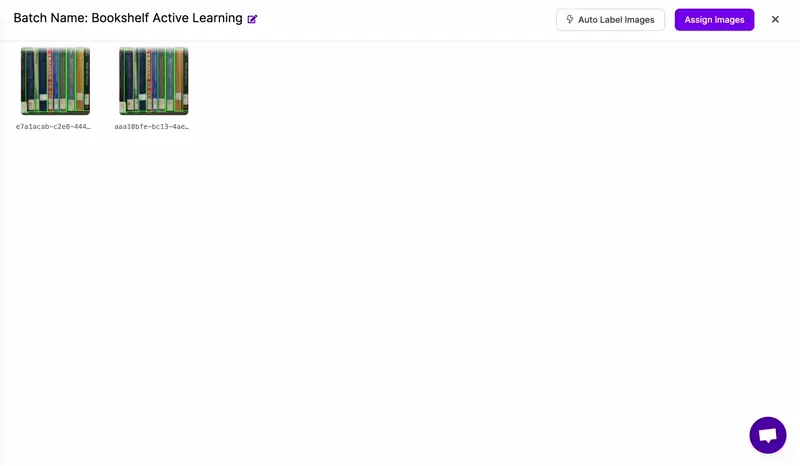
As soon as uploaded, you’ll be able to evaluation and proper annotations as crucial, then create a brand new model to begin coaching your customized mannequin!
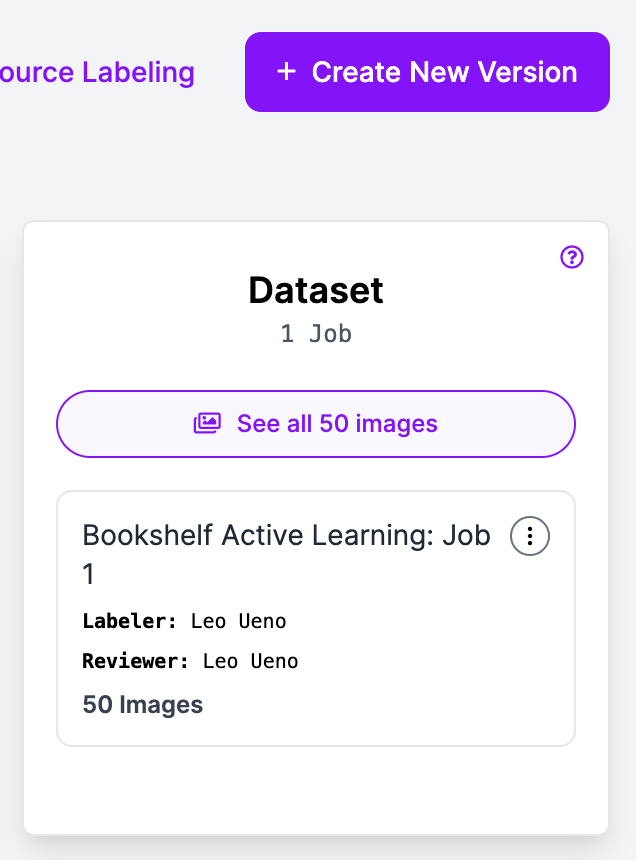
After coaching, we had been in a position to practice a customized mannequin with round 98.3% imply common precision (mAP).

As you proceed utilizing your mannequin, whether or not that be a customized mannequin or a big mannequin like YOLO-World, you’ll be able to proceed gathering knowledge to additional enhance our fashions sooner or later.
Conclusion
On this information, we had been in a position to mix the very best of each worlds: Utilizing a state-of-the-art zero-shot object detection mannequin for instant use after which utilizing that deployed mannequin to coach a customized mannequin with higher efficiency with out spending time gathering and labeling a dataset.
After you create your customized mannequin, you’ll be able to hold bettering your fashions by means of built-in energetic studying options within the Roboflow platform.



