Florence-2 is a light-weight vision-language mannequin open-sourced by Microsoft beneath the MIT license. The mannequin demonstrates robust zero-shot and fine-tuning capabilities throughout duties corresponding to captioning, object detection, grounding, and segmentation.
Regardless of its small dimension, it achieves outcomes on par with fashions many instances bigger, like Kosmos-2. The mannequin’s power lies not in a fancy structure however within the large-scale FLD-5B dataset, consisting of 126 million pictures and 5.Four billion complete visible annotations.
You may check out the mannequin through HF House or Google Colab.
Unified Illustration
Imaginative and prescient duties are numerous and fluctuate when it comes to spatial hierarchy and semantic granularity. Occasion segmentation offers detailed details about object areas inside a picture however lacks semantic info. Alternatively, picture captioning permits for a deeper understanding of the relationships between objects, however irrespective of their precise areas.
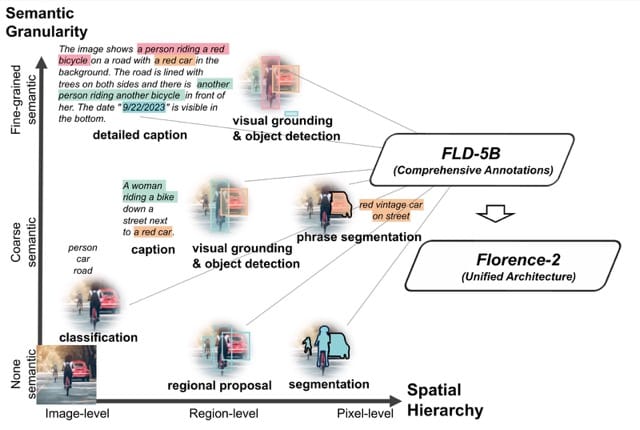
The authors of Florence-2 determined that as a substitute of coaching a sequence of separate fashions able to executing particular person duties, they’d unify their illustration and practice a single mannequin able to executing over 10 duties. Nonetheless, this requires a brand new dataset.
Constructing Complete Dataset
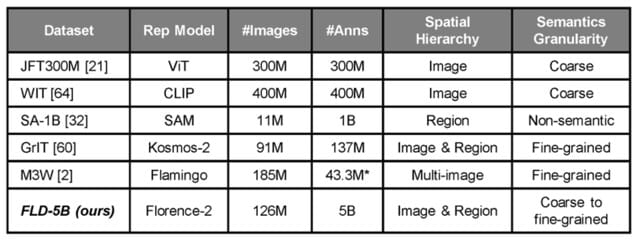
Sadly, there are presently no giant, unified datasets accessible. Present large-scale datasets cowl restricted duties for single pictures. SA-1B, the dataset used to coach Section Something (SAM), solely incorporates masks. COCO, whereas supporting a wider vary of duties, is comparatively small.

Handbook labeling is dear, so to construct a unified dataset, the authors determined to automate the method utilizing present specialised fashions. This led to the creation of FLD-5B, a dataset containing 126 million pictures and 5 billion annotations, together with bins, masks, and a wide range of captions at completely different ranges of granularity. Notably, the dataset would not comprise any new pictures; all pictures initially belong to different pc imaginative and prescient datasets.
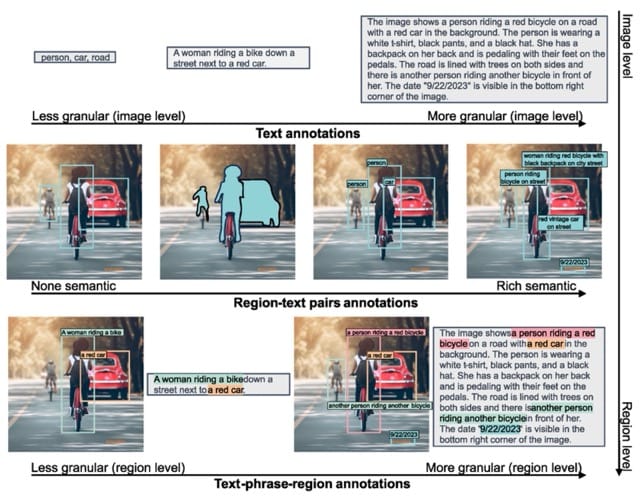
FLD-5B is just not but publicly accessible, however the authors introduced its upcoming launch throughout CVPR 2024.
Mannequin Structure
The mannequin takes pictures and process prompts as enter, producing the specified ends in textual content format. It makes use of a DaViT imaginative and prescient encoder to transform pictures into visible token embeddings. These are then concatenated with BERT-generated textual content embeddings and processed by a transformer-based multi-modal encoder-decoder to generate the response.
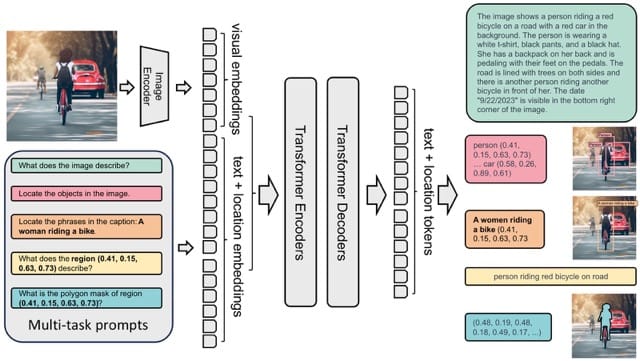
For region-specific duties, location tokens representing quantized coordinates are added to the tokenizer’s vocabulary.
- Field Illustration (x0, y0, x1, y1): Location tokens correspond to the field coordinates, particularly the top-left and bottom-right corners.
- Polygon Illustration (x0, y0, …, xn, yn): Location tokens characterize the polygon’s vertices in clockwise order.
Capabilities
Florence-2 is smaller and extra correct than its predecessors. The Florence-2 sequence consists of two fashions: Florence-2-base and Florence-2-large, with 0.23 billion and 0.77 billion parameters, respectively. This dimension permits for deployment on even cellular gadgets.
Regardless of its small dimension, Florence-2 achieves higher zero-shot outcomes than Kosmos-2 throughout all benchmarks, although Kosmos-2 has 1.6 billion parameters.




Conclusions
Florence-2 represents a big development in vision-language fashions by combining light-weight structure with strong capabilities, making it extremely accessible and versatile. Its unified illustration method, supported by the intensive FLD-5B dataset, permits it to excel in a number of imaginative and prescient duties with out the necessity for separate fashions. This effectivity makes Florence-2 a robust contender for real-world functions, notably on gadgets with restricted sources.



