Detecting small objects is without doubt one of the most difficult and vital issues in laptop imaginative and prescient. On this put up, we’ll talk about among the methods we now have developed at Roboflow by iterating on a whole lot of small object detection fashions.
What’s small object detection?
Small object detection is a pc imaginative and prescient downside the place you goal to precisely establish objects which are small in a video feed or picture. The thing itself doesn’t essentially have to be small. As an example, small object detection is essential in aerial laptop imaginative and prescient, the place you want to have the ability to precisely establish objects though every particular person object will probably be small relative to the picture dimension.
There are two phases of a pc imaginative and prescient pipeline at which you may make optimizations to detect small objects:
- At inference time (preferrred if you have already got a educated mannequin and also you need to enhance its efficiency on small objects), and;
- Earlier than coaching, by including the precise preprocessing steps.
You can also make optimizations at each phases to enhance detection efficiency.
On this information, we’ll stroll by making optimizations at each phases.

Why is the small object downside laborious to unravel?
There’s one basic query we have to reply earlier than we begin speaking about how one can successfully establish small objects: why is discovering small objects in a picture or video so troublesome within the first place?
The small object downside plagues object detection fashions worldwide. Not shopping for it? Verify the COCO analysis outcomes for current state-of-the-art fashions YOLOv3, EfficientDet, and YOLOv4:
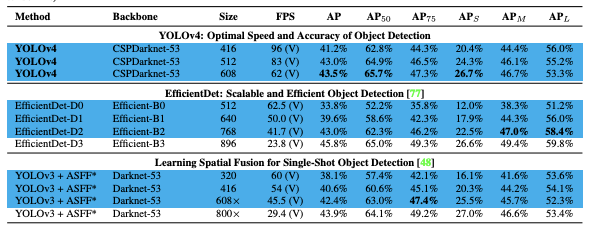
In EfficientDet for instance, imply common precision (mAP) on small objects is barely 12%, held up towards an AP of 51% for big objects. That’s nearly a 5 fold distinction!
So why is detecting small objects so laborious?
All of it comes right down to the mannequin. Object detection fashions type options by aggregating pixels in convolutional layers.
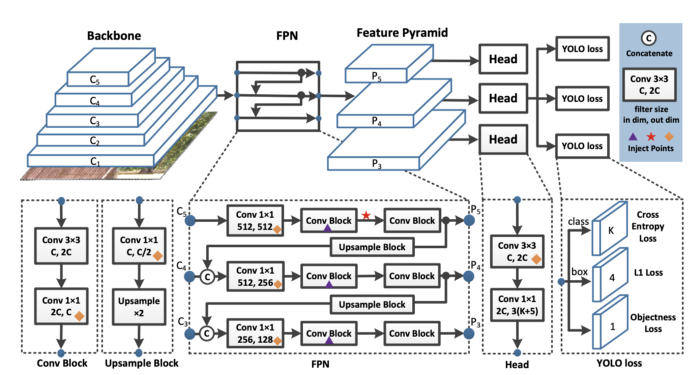
And on the finish of the community a prediction is made primarily based on a loss perform, which sums up throughout pixels primarily based on the distinction between prediction and floor reality.
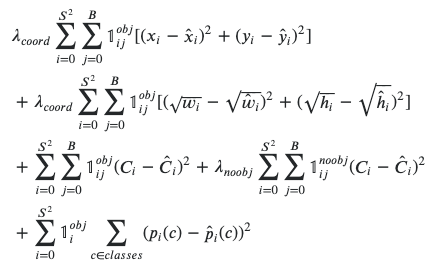
If the bottom reality field just isn’t massive, the sign will small whereas coaching is happening.
Moreover, small objects are almost certainly to have knowledge labeling errors, the place their identification could also be omitted.
Empirically and theoretically, small objects are laborious.
Find out how to detect small objects (inference optimisations)
Whether or not it’s a bustling road, drone footage of a metropolis, or surfers using the waves close to the horizon, naively operating object detection fashions typically yield poor outcomes. The first cause is that fashions educated on bigger objects miss small particulars.

To resolve this, you may use a mannequin educated on higher-resolution pictures, reminiscent of yolov8s-1280. Nonetheless, our strategy to this downside is InferenceSlicer.
On this article, I’ll clarify use it and spotlight two current options:
- Overlap filtering methods
- Segmentation assist.
What’s Inference Slicer?
As a substitute of operating the mannequin on the entire scene, InferenceSlicer splits it into smaller components (slices), runs the mannequin on each, after which stitches the outcomes collectively. Broadly, this is named SAHI.
Utilizing InferenceSlicer is simple:
import supervision as sv
from inference import get_model mannequin = get_model(model_id="yolov8m-640")
picture = cv2.imread(<SOURCE_IMAGE_PATH>) def callback(image_slice: np.ndarray) -> sv.Detections:
outcomes = mannequin.infer(image_slice)[0]
return sv.Detections.from_inference(outcomes) slicer = sv.InferenceSlicer(callback=callback)
detections = slicer(picture)To see the outcomes, you’ll be able to annotate the picture:
annotated_frame = sv.BoundingBoxAnnotator().annotate(
scene=picture.copy(),
detections=detections
)
Whereas It took for much longer, the mannequin detected all of the folks within the water.
Here is the code we ran:
import supervision as sv
from inference import get_model
import cv2 picture = cv2.imread("seaside.jpg")
mannequin = get_model("yolov8s-640") def slicer_callback(slice: np.ndarray) -> sv.Detections: end result = mannequin.infer(slice)[0] detections = sv.Detections.from_inference(end result) return detections slicer = sv.InferenceSlicer( callback=slicer_callback, slice_wh=(512, 512), overlap_ratio_wh=(0.4, 0.4), overlap_filter_strategy=sv.OverlapFilter.NONE
)
detections = slicer(picture) annotated_frame = sv.BoundingBoxAnnotator().annotate(
scene=picture.copy(),
detections=detections
)What are all of those parameters? Let’s look deeper:
slice_whpermits you to set the sizes of every slice. Don’t fear if it doesn’t divide the picture exactly –InferenceSlicerwill decide the slice places robotically, although they overlap generally. Givingslice_whsmaller values will produce extra blocks, making inference slower however extra exact.overlap_ratio_wh, impartial of the earlier parameter, add some overlap to every slice. If set to(0, 0), objects close to the sides could also be cropped off, complicated the mannequin. We suggest at the least 20% overlap –(0.2, 0.2). Bigger values will produce extra slices – inference will take longer however will probably be extra exact.callbackdefines what’s carried out on every slice. It’s a perform accepting anp.ndarraypicture, performing some mannequin logic, and returning onesv.Detectionsobject. Word that perform enter will probably be in BGR (blue-green-red), much like whatcv2.imreadproduces.thread_workersenables you to use a number of threads, which can pace up efficiency when the mannequin is run on a CPU. When working with a GPU, we propose holding this at1. We’re engaged on a parallelized implementation – tell us if that’s one thing you want!- Lastly,
overlap_filter_strategyandiou_thresholdcope with eradicating duplicate or overlapping detections. Let’s dive deeper.
Overlap Filtering Technique
By their nature, some fashions produce a number of overlapping detections. Setting overlap_ratio_wh contributes too – within the earlier seaside instance, we ended up with 575 detections, whereas the precise quantity is nearer to 280. How will we attain that?
Because it’s laborious to see overlaps within the seaside instance, let’s analyze a less complicated picture. Suppose we now have detected the next, with overlap_filter_strategy = sv.OverlapFilter.NONE. We are able to see all detections, however there’s room for enchancment.

By default, InferenceSlicer would have carried out non-max suppression (NMS), suppressing some detections. The gist of it’s – each time detections with vital overlap are discovered, InferenceSlier retains the one with the very best confidence and discards others. You may set the iou_threshold parameter to manage that – the decrease the worth, the extra detections will probably be dropped.
Should you’re , Piotr wrote an in-depth evaluation of Non-Max Suppression with NumPy.

Non-max merge
In supervision v0.21.0, we’ve launched extra filtering methods. By setting overlap_filter_strategy, now you can do no filtering or non-max-merge (NMM).
You need to use it by setting overlap_filter_strategy = sv.OverlapFilter.NON_MAX_MERGE.
Non-max merge is similar to non-max suppression. First, IOU is computed and in comparison with a threshold, figuring out which options overlap considerably. Nonetheless, as a substitute of discarding all however probably the most assured one, options are progressively merged. Right here’s the algorithm:
- Compute the IOU of all options
- Discover teams of options the place every overlap by at the least
iou_threshold - For every group, beginning with probably the most assured detection, merge the subsequent most assured one into the primary
- Recompute the IOU, ensuring we don’t merge infinitely
- Return to step Three and proceed till we discover that additional merges aren’t potential
- Repeat the method with different teams
Ultimately, you need to see packing containers enveloping the detected objects.

Selecting the Proper Parameters
Our recommendation: experiment along with your use case and totally different InferenceSlicer parameters.
First, verify if an ordinary strategy, with out InferenceSlicer can detect all objects you want.
If not, begin by utilizing InferenceSlicer with default parameters. Proceed to set slice_wh and overlap_ratio_wh to fine-tune the outcomes.
Lastly, verify for detection overlaps. Most often, the default worth for overlap_filter_strategy will work nicely. In any other case, experiment with sv.OverlapFilter.NON_MAX_MERGE. Remember to set the iou_threshold!

Segmentation Assist
Within the article, I discussed detections and packing containers, however since supervision v0.21.0, you’ll be able to simply as rapidly do that with segmentation and masks! All you want is a segmentation mannequin, e.g. yolov8s-seg-640:
import supervision as sv
from inference import get_model mannequin = get_model(model_id="yolov8s-seg-640")
picture = cv2.imread(<SOURCE_IMAGE_PATH>) def callback(image_slice: np.ndarray) -> sv.Detections:
outcomes = mannequin.infer(image_slice)[0]
return sv.Detections.from_inference(outcomes) slicer = sv.InferenceSlicer(callback=callback)
detections = slicer(picture)Be sure that to make use of a unique annotator to see the masks!
annotated_frame = sv.MaskAnnotator().annotate(
scene=picture.copy(),
detections=detections
)Here is a run on an AI-generated picture:

Whereas more durable to see, here is a segmentation of the seaside picture created with InferenceSlicer.

Roboflow’s Inference Slicer will break up a picture into small segments, run a mannequin of your alternative on every half, and glue the outcomes collectively. If there are overlapping outcomes, Slicer will robotically deal with it primarily based on the overlap_filter_strategy you select. As of not too long ago, it additionally works with segmentation!
Subsequent time you end up scuffling with small objects, give it a attempt!

Find out how to detect small objects (pre-processing)
Now we perceive the issue, we’re prepared to begin speaking about clear up it. To enhance your mannequin’s efficiency on small objects, we suggest the next strategies:
Within the following video, we talk about sort out the small object downside in additional depth, offering you with the instruments and data you want:
Small object detection information video
Tip #1: Enhance your picture seize decision
Decision, decision, decision… it’s all about decision.
Very small objects could comprise only some pixels inside the bounding field – which means it is extremely vital to extend the decision of your pictures to extend the richness of options that your detector can type from that small field.
Due to this fact, we propose capturing as excessive of decision pictures as potential, if potential.
Tip #2: Enhance your mannequin’s enter decision
Upon getting your pictures at larger decision, you’ll be able to scale up your mannequin’s enter decision. Warning: this may lead to a big mannequin that takes longer to coach, and will probably be slower to deduce whenever you begin deployment. You’ll have to run experiments to seek out out the precise tradeoff of pace with efficiency.
You may simply scale your enter decision in our tutorial on coaching YOLOv4 by altering picture dimension within the config file.
[net]
batch=64
subdivisions=36
width={YOUR RESOLUTION WIDTH HERE}
peak={YOUR RESOLUTION HEIGHT HERE}
channels=3
momentum=0.949
decay=0.0005
angle=0
saturation = 1.5
publicity = 1.5
hue = .1 learning_rate=0.001
burn_in=1000
max_batches=6000
coverage=steps
steps=4800.0,5400.0
scales=.1,.1You can too simply scale your enter decision in our tutorial on practice YOLOv5 by altering the picture dimension parameter within the coaching command:
!python practice.py --img {YOUR RESOLUTON SIZE HERE} --batch 16 --epochs 10 --data '../knowledge.yaml' --cfg ./fashions/custom_yolov5s.yaml --weights '' --name yolov5s_results --cacheWord: you’ll solely see improved outcomes as much as the utmost decision of your coaching knowledge.
Tip #3: Tile pictures throughout preprocessing
One other nice tactic for detecting small pictures is to tile your pictures as a preprocessing step. Tiling successfully zooms your detector in on small objects, however permits you to maintain the small enter decision you want so as to have the ability to run quick inference.
Tiling pictures as a preprocessing step in Roboflow
Should you use tiling throughout coaching, you will need to do not forget that additionally, you will have to tile your pictures at inference time.
Tip #4: Tile pictures at inference
Should you’ve used tiling throughout coaching, additionally, you will want to make use of tiling throughout inference for extra correct outcomes. It is because we need to keep the zoomed in perspective in order that objects throughout inferences are of the same dimension to what they had been throughout coaching.
Right here’s an instance of a mannequin educated to detect vehicles through aerial photographs. The mannequin was educated with tiling to higher acknowledge vehicles given their small dimension and the massive dimension of the supply picture, however with out tiling at inference, it finally ends up detecting buildings and different massive shapes as a substitute of vehicles as a result of they’re nearer to the scale of the item it was making an attempt to detect throughout coaching.

Beneath we’ve utilized tiling to a picture earlier than operating inference. This permits us to zoom in to sections of the picture and make our vehicles larger and simpler to detect for the mannequin.

Tip #5: Generate extra knowledge utilizing picture augmentation
Information augmentation generates new pictures out of your base dataset. This may be very helpful to forestall your mannequin from overfitting to the coaching set.
Some particularly helpful augmentations for small object detection embody random crop, random rotation, and mosaic augmentation.
Tip #6: Use auto-learning mannequin anchors
Anchor packing containers are prototypical bounding packing containers that your mannequin learns to foretell in relation to. That stated, anchor packing containers may be preset and someday suboptimal to your coaching knowledge. It’s good to customized tune these to your activity at hand. Fortunately, the YOLOv5 mannequin structure does this for you robotically primarily based in your customized knowledge. All it’s a must to do is kick off coaching.
Analyzing anchors... anchors/goal = 4.66, Greatest Doable Recall (BPR) = 0.9675. Making an attempt to generate improved anchors, please wait...
WARNING: Extraordinarily small objects discovered. 35 of 1664 labels are < Three pixels in width or peak.
Operating kmeans for 9 anchors on 1664 factors...
thr=0.25: 0.9477 absolute best recall, 4.95 anchors previous thr
n=9, img_size=416, metric_all=0.317/0.665-mean/finest, past_thr=0.465-mean: 18,24, 65,37, 35,68, 46,135, 152,54, 99,109, 66,218, 220,128, 169,228
Evolving anchors with Genetic Algorithm: health = 0.6825: 100%|██████████| 1000/1000 [00:00<00:00, 1081.71it/s]
thr=0.25: 0.9627 absolute best recall, 5.32 anchors previous thr
n=9, img_size=416, metric_all=0.338/0.688-mean/finest, past_thr=0.476-mean: 13,20, 41,32, 26,55, 46,72, 122,57, 86,102, 58,152, 161,120, 165,204Class administration is a crucial approach to enhance the standard of your dataset. You probably have one class that’s considerably overlapping with one other class, you need to filter this class out of your dataset. And maybe, you determine that the small object in your dataset just isn’t value detecting, so you could need to take it out. You may rapidly establish all of those points with the Superior Dataset Well being Verify that is part of Roboflow Professional.
Class omission and sophistication renaming are all potential by Roboflow’s ontology administration instruments.
Conclusion
Correctly detecting small objects is really a problem. On this put up, we now have mentioned a number of methods for enhancing your small object detector, particularly:
As at all times, comfortable detecting!



