If you happen to’ve been working with object detection lengthy sufficient, you’ve undoubtedly encountered the issue of double detection. That is when the identical object is detected by the mannequin a number of instances.
That is generally solved with Non-Max Suppression (NMS), which retains essentially the most assured bounding detection and discards the remainder. However what if you wish to merge the bins as an alternative?
This text will clarify double detections and current Non-Max Merging (NMM). We are going to talk about:
- What causes double detections
- The Non-Max Merging algorithm
- Variations between NMS and NMM
We are going to then clarify some instance code that reveals find out how to run NMS with laptop imaginative and prescient mannequin predictions.
Double Detection Drawback
What causes double detections? Two instances are outstanding offenders.
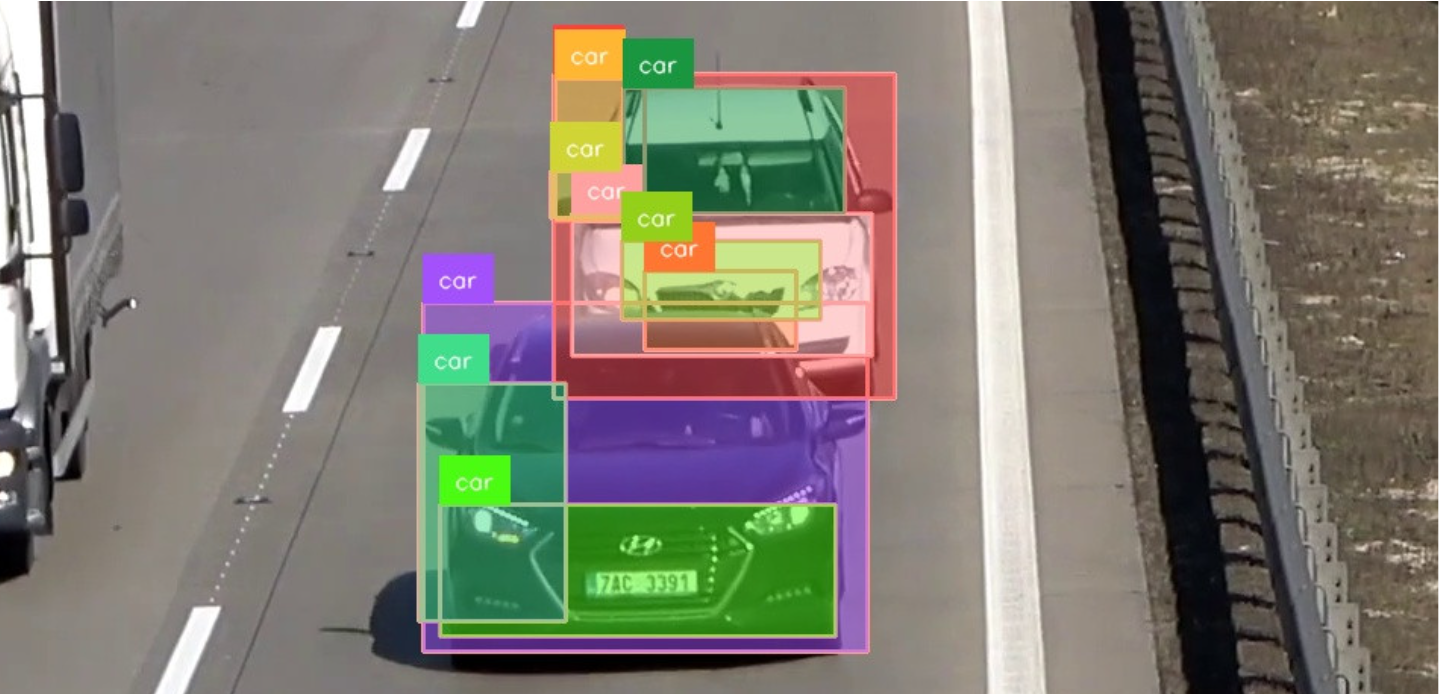
First, overlapping detections could also be produced by the mannequin itself.
- Fashions equivalent to YOLO or Sooner R-CNN use anchor bins or area proposals to foretell objects. A number of anchor bins may cowl the identical object with slight place, measurement, or side ratio variations, resulting in a number of detections.
- The mannequin is likely to be overconfident about a number of areas of the identical object, particularly if it has been skilled on a dataset with noisy annotations or if the item has distinct options that stand out at totally different areas or scales.
- If the mannequin is unsure about which class the item belongs to, it’d produce a number of detections with totally different class labels. For instance, it’d detect a “automobile” and likewise a “automobile” as separate entities, although they confer with the identical object.
By default, frameworks equivalent to Ultralytics filter away most mannequin predictions. Specifying a decrease confidence threshold reveals extra mannequin predictions.

Secondly, the overlap is likely to be created on function.
- InferenceSlicer (SAHI) divides a picture into small slices, applies a mannequin to every one, after which merges the outcomes. To keep away from objects being abruptly lower off on the slice edges, the slices are made to overlap barely. Nonetheless, this overlap can lead to the identical object or its components being recognized a number of instances.
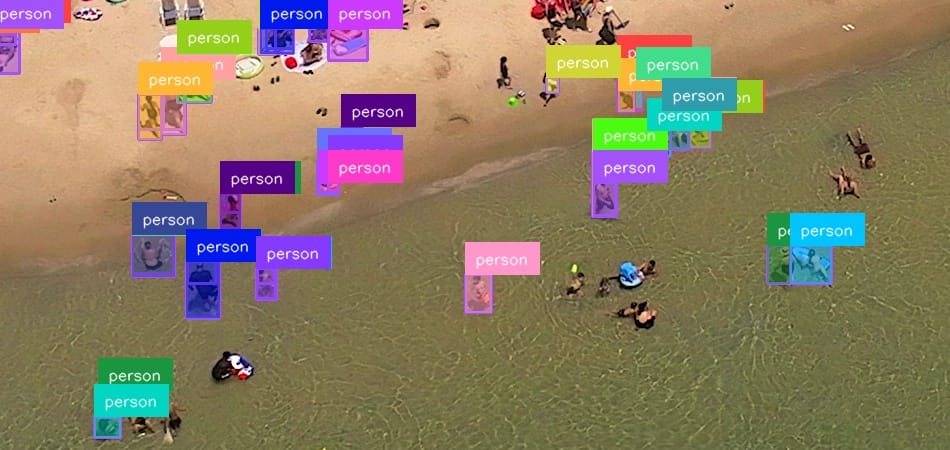
How would you detect individuals on this picture?

You should use InferenceSlicer, which handles the duty simply.

Discover that if you happen to zoom in, you will note that beneath most detections, there’s one other double detection.
Overlap Filtering
Two comparable algorithms are used to resolve double detections:
- Non-Max Suppression (NMS), which checks for field overlap and solely retains the most effective detection
- Non-Max Merging (NMM), which checks for field overlap and merges the detections into one

Let’s make clear the prerequisite ideas after which dig deeper into the algorithms.
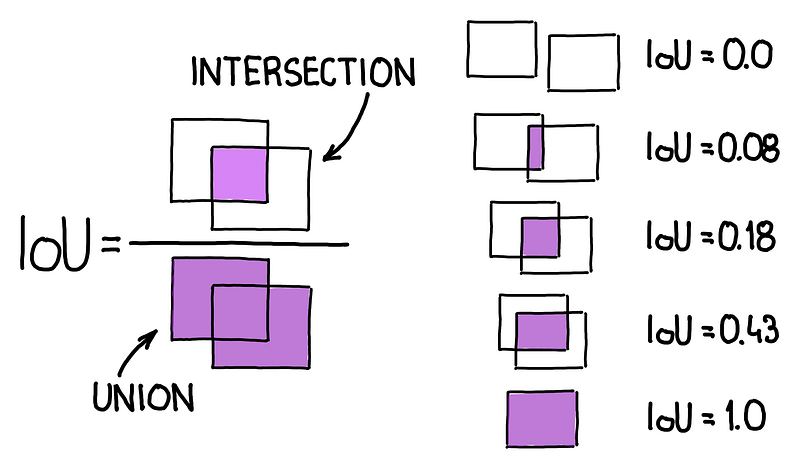
Intersection-Over-Union (IOU)
Once we say ‘overlap,‘ we sometimes imply a excessive Intersection-Over-Union worth. It’s computed by dividing the realm the place two bins intersect by the merged space of the 2 bins. IOU spans from Zero to 1. The upper the worth, the better the overlap!
Non-Max Suppression (NMS)
Suppose you run a mannequin over a picture, producing a listing of detections. You want to filter out instances when two detections are positioned on the identical object.
The commonest method is to make use of Non-Max Suppression.

- First, it types all detections by their confidence rating, from highest to lowest.
- It then takes all pairs of detections and computes their IOU, checking how a lot the pair overlaps.
- For each pair the place the overlap is larger than the user-specified
iou_threshold, discard the much less assured one. - That is executed till all courses and detection pairs are accounted for.
Non-Max Suppression could be carried out both on a per-class foundation (e.g., automobile, canine, plant) or in a class-agnostic method, the place overlaps are checked with bins of any class.
For additional studying, Piotr wrote an in-depth evaluation of Non-Max Suppression with NumPy.
Non-Max Merging (NMM)
The steps of this algorithm are barely extra concerned. Let’s once more begin with the case when a mannequin produces a listing of detections, a few of them detecting the item twice.

Listed below are the steps Non-Max Merge takes:
- First, it types all detections by their confidence rating, from highest to lowest.
- It then takes all pairs of detections and computes their IOU, checking how a lot the pair overlaps.
- From most assured to least, it is going to construct teams of overlapping detections.
- It begins by creating a brand new group with essentially the most assured non-grouped detection D1.
- Then, every non-grouped detection that overlaps with D1 by a minimum of
iou_threshold(specified by the consumer) is positioned in the identical group. - By repeating these two steps, we find yourself with mutually unique teams, equivalent to [[D1, D2, D4], [D3], [D5, D6]].
- Then merging begins. That is executed with detection pairs (D1, D2) and is implementation-specific. In supervision we:
- Make a brand new bounding field
xyxyto suit each D1 and D2. - Make a brand new
maskscontaining pixels the place the masks of D1 or D2 have been. - Create a brand new
confidenceworth, including collectively theconfidenceof D1 and D2, normalized by theirxyxyareas.New Conf = (Conf 1 * Space 1 + Conf 2 * Space 2) / (Space 1 + Space 2) - Copy
class_id,tracker_id,andinformationfrom the Detection with the upper confidence.
- Make a brand new bounding field
- The prior step is finished on detection pairs. How can we merge the entire group?
- Create an empty checklist for outcomes.
- If there’s just one detection in a gaggle, add it to the outcomes checklist.
- In any other case, decide the primary two detections, compute the IOU once more, and if it is above the user-specified
iou_threshold, pairwise merge it as outlined within the prior step.
The ensuing merged detection stays within the group as the brand new first component, and the group is shortened by 1. Proceed pairwise merging whereas there are a minimum of two parts in a gaggle.
Notice that the IOU calculation makes the algorithm extra expensive however is required to forestall the merged detection from rising boundlessly.
Ultimately, you get a shorter checklist of detections, with all the unique detections both saved or merged into the probably correct outcomes.
When to make use of every methodology
As you possibly can see, the strategies usually produce comparable outcomes. Which must you decide in your use case? The short reply is to go for non-max suppression because the default however do just a few assessments for non-max merge in your use case.
Discover that within the following picture, Non-Max Merge carried out higher:

For the reason that aspect of the truck was detected with very excessive confidence, non-max suppression discards different overlapping detections. In case your assessments present that part of your object is detected with excessive confidence and it is advisable to develop the detection space, or the detections underestimate the item measurement, you must first tinker with the nms_threshold parameter after which take a look at Non-Max Merge.
Efficiency Issues
In our implementation, we seen that Non-Max Suppression (NMS) is about 2x quicker than Non-Max Merge (NMM).
When run on 35 detections, the outcomes have been (in milliseconds):
- NMS: 1.25 ms
- NMM: 4.23 ms
When run on 750 detections:
- NMS: 41.15 ms
- NMM: 75.71 ms
Verdict
I counsel beginning with Non-Max Suppression, operating just a few experiments to see the way it performs, and checking a number of values for nms_threshold. Then, strive Non-Max Merging, however rigorously consider the efficiency price.
Non-Max Merge in supervision

Non-Max Suppression and Non-Max Merge are constructed into essentially the most generally used objects of Supervision. The library provides two methods of accessing NMS and NMM:
Inside Detections
The primary is the comfort strategies of with_nms and with_nmm within the Detections class. This is some ready-to-use code you possibly can apply to your photos:
import cv2
import supervision as sv
from inference import get_model picture = cv2.imread(<SOURCE_IMAGE_PATH>)
mannequin = get_model(model_id="yolov8m-640") consequence = mannequin.infer(picture)[0]
detections = sv.Detections.from_inference(consequence)
detections = detections.with_nmm( threshold=0.5
)You might also visualize the consequence:
annotated_frame = sv.BoundingBoxAnnotator().annotate( scene=picture.copy(), detections=detections
)
sv.plot_image(annotated_frame)Inside InferenceSlicer
InferenceSlicer (SAHI) divides a picture into small slices, applies a mannequin to every one, after which merges the outcomes. To keep away from objects being abruptly lower off on the slice edges, the slices are made to overlap barely. Nonetheless, this overlap can lead to the identical object or its components being recognized a number of instances.
Since InferenceSlicer might deliberately trigger double detections, we additionally added an answer. By setting the overlap_filter_strategy parameter, along with iou_threshold, you could apply NMS and NMM to the ensuing detections.
This is how that appears:
import numpy as np
import cv2
import supervision as sv
from inference import get_model picture = cv2.imread("seashore.jpg")
mannequin = get_model("yolov8s-640") def slicer_callback(slice: np.ndarray) -> sv.Detections: consequence = mannequin.infer(slice)[0] detections = sv.Detections.from_inference(consequence) return detections slicer = sv.InferenceSlicer( callback=slicer_callback, slice_wh=(512, 512), overlap_ratio_wh=(0.4, 0.4), overlap_filter_strategy=sv.OverlapFilter.NON_MAX_MERGE
)
detections = slicer(picture)
You’ll be able to learn extra in How one can Detect Small Objects with Inference Slicer.
Conclusion
Non-Max Suppression (NMS) and Non-Max Merging (NMM) handle double detections in object detection. NMS is environment friendly, retaining essentially the most assured detections, whereas NMM merges overlaps for a extra consolidated consequence. Begin with NMS for velocity, modify thresholds as wanted, and use NMM for exact overlap dealing with. Each strategies can be found by way of our Open Supply supervision library and are prepared for use at any time when double detection points come up.



