Florence-2 is a light-weight vision-language mannequin open-sourced by Microsoft below the MIT license. The mannequin demonstrates sturdy zero-shot and fine-tuning capabilities throughout duties similar to captioning, object detection, grounding, and segmentation. You may be taught extra concerning the capabilities of the pre-trained Florence mannequin from our weblog put up.
Like different pre-trained foundational fashions, Florence-2 might lack domain-specific information. For instance, it might carry out poorly with medical or satellite tv for pc imagery. In such instances, fine-tuning with a customized dataset is critical. This tutorial will present you the best way to fine-tune Florence-2 on object detection datasets to enhance mannequin efficiency on your particular use case. Let’s dive in!

Getting Began
Earlier than we fine-tune the Florence-2 mannequin on a customized detection dataset, we have to correctly configure the environment. This tutorial is accompanied by a pocket book you could open in a separate tab and comply with alongside.
💡
Earlier than we focus on the info format, mannequin coaching, and analysis, be sure your atmosphere is GPU-accelerated. In case you are utilizing our Google Colab, guarantee you’ve got entry to an NVIDIA L4 GPU by working the nvidia-smi command. If you happen to encounter any points, navigate to Edit -> Pocket book settings -> Hardwar accelerator, set it to L4 GPU, after which click on Save.
In case you are working the code regionally, additionally, you will want an NVIDIA GPU with roughly 20GB VRAM. Relying on the quantity of reminiscence in your GPU, you could want to decide on totally different hyperparameter values throughout coaching, particularly the batch dimension.
Moreover, we might want to set the values of two secrets and techniques: the HuggingFace token, to obtain the pre-trained mannequin, and the Roboflow API key, to obtain the article detection dataset.
Open your HuggingFace settings web page, click on Entry Tokens, then New Token to generate a brand new token. To get the Roboflow API key, go to your Roboflow settings web page, and click on Copy settings. This can place your non-public key within the clipboard. In case you are utilizing Google Colab, go to the left pane and click on on Secrets and techniques (🔑).
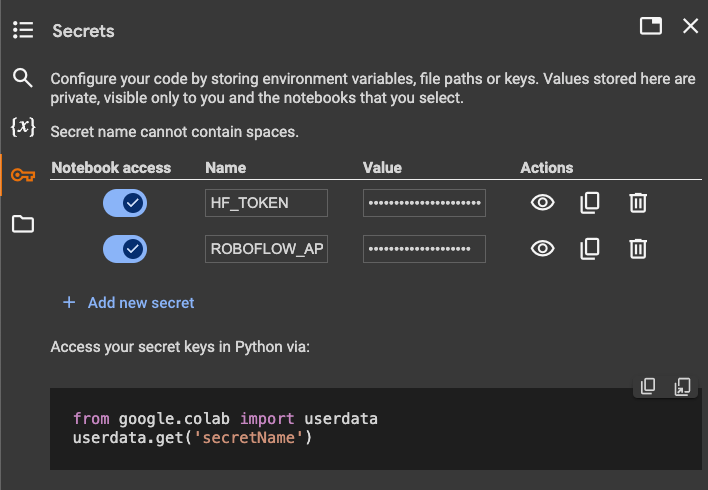
Then retailer the HuggingFace Entry Token below the identify HF_TOKEN and retailer the Roboflow API Key below the identify ROBOFLOW_API_KEY. In case you are working the code regionally, merely export the values of those secrets and techniques as atmosphere variables.
Florence-2 Dataset Format
On this instance, I am going to fine-tune Florence-2 on a dataset of poker playing cards – one of many datasets belonging to Roboflow 100. We’ll use the roboflow package deal to obtain it.
from google.colab import userdata
from roboflow import Roboflow ROBOFLOW_API_KEY = userdata.get('ROBOFLOW_API_KEY')
rf = Roboflow(api_key=ROBOFLOW_API_KEY) challenge = rf.workspace("roboflow-jvuqo").challenge("poker-cards-fmjio")
model = challenge.model(4)
dataset = model.obtain("florence2-od")
Every picture should have a prefix and a suffix. For fine-tuning Florence-2 on an object detection activity, the prefix (immediate) is all the time the identical: <OD>. The suffix, the anticipated mannequin response, has a construction much like the one utilized in fine-tuning PaliGemma. Every bounding field is described by a string with the next construction: {class_name}<loc{x1}><loc{y1}><loc{x2}><loc{y2}>. Right here, the values x1, y1, x2, y2 describe the coordinates of the bounding field vertices.
These values are first normalized (scaled to drift values between 0 and 1 by dividing by the picture decision) after which multiplied by 1000 and rounded to integers. Finally, the values x1 y1, x2, y2 are integers within the closed vary from 0 to 999.
{"prefix": "<OD>", "suffix": "10 of golf equipment<loc_142><loc_101><loc_465><loc_451>9 of golf equipment<loc_387><loc_146><loc_665><loc_454>jack of golf equipment<loc_567><loc_168><loc_823><loc_429>queen of golf equipment<loc_367><loc_467><loc_764><loc_998>king of golf equipment<loc_603><loc_440><loc_948><loc_871>", "picture": "rot_0_7471_png_jpg.rf.30ec1d3771a6b126e7d5f14ad0b3073b.jpg"}
{"prefix": "<OD>", "suffix": "10 of golf equipment<loc_142><loc_101><loc_465><loc_451>9 of golf equipment<loc_387><loc_146><loc_665><loc_454>jack of golf equipment<loc_567><loc_168><loc_823><loc_429>queen of golf equipment<loc_367><loc_467><loc_764><loc_998>king of golf equipment<loc_603><loc_440><loc_948><loc_871>", "picture": "rot_0_7471_png_jpg.rf.30ec1d3771a6b126e7d5f14ad0b3073b.jpg"}
{"prefix": "<OD>", "suffix": "10 of golf equipment<loc_142><loc_101><loc_465><loc_451>9 of golf equipment<loc_387><loc_146><loc_665><loc_454>jack of golf equipment<loc_567><loc_168><loc_823><loc_429>queen of golf equipment<loc_367><loc_467><loc_764><loc_998>king of golf equipment<loc_603><loc_440><loc_948><loc_871>", "picture": "rot_0_7471_png_jpg.rf.30ec1d3771a6b126e7d5f14ad0b3073b.jpg"}Load Pre-trained Florence-2 Mannequin
Earlier than we begin fine-tuning the mannequin on a customized dataset, we have to load the pre-trained Florence-2 mannequin into reminiscence. Florence-2 is accessible in two variations: base and huge, with 230 million and 770 million parameters, respectively.
For this tutorial, we are going to use the bottom model. If you wish to load the big model, keep in mind that you will want extra VRAM throughout coaching, or alternatively, scale back the batch dimension.
import torch
from transformers import AutoModelForCausalLM, AutoProcessor CHECKPOINT = "microsoft/Florence-2-base-ft"
REVISION = 'refs/pr/6'
DEVICE = torch.gadget("cuda" if torch.cuda.is_available() else "cpu") mannequin = AutoModelForCausalLM.from_pretrained( CHECKPOINT, trust_remote_code=True, revision=REVISION).to(DEVICE)
processor = AutoProcessor.from_pretrained( CHECKPOINT, trust_remote_code=True, revision=REVISION)After loading the mannequin, we will check the way it performs inference on a pattern picture. This step will not be required, however a pattern inference is an effective technique to verify that the environment is configured appropriately.
import supervision as sv
from PIL import Picture picture = Picture.open(EXAMPLE_IMAGE_PATH)
activity = "<OD>"
textual content = "<OD>" inputs = processor( textual content=textual content, pictures=picture, return_tensors="pt"
).to(DEVICE)
generated_ids = mannequin.generate( input_ids=inputs["input_ids"], pixel_values=inputs["pixel_values"], max_new_tokens=1024, num_beams=3)
generated_text = processor.batch_decode( generated_ids, skip_special_tokens=False)[0]
response = processor.post_process_generation( generated_text, activity=activity, image_size=picture.dimension)
detections = sv.Detections.from_lmm( sv.LMM.FLORENCE_2, response, resolution_wh=picture.dimension) bounding_box_annotator = sv.BoundingBoxAnnotator( color_lookup=sv.ColorLookup.INDEX)
label_annotator = sv.LabelAnnotator( color_lookup=sv.ColorLookup.INDEX) picture = bounding_box_annotator.annotate(picture, detections)
picture = label_annotator.annotate(picture, detections)
import supervision as sv
from PIL import Picture picture = Picture.open(EXAMPLE_IMAGE_PATH)
activity = "<CAPTION_TO_PHRASE_GROUNDING>"
textual content = "<CAPTION_TO_PHRASE_GROUNDING> On this picture we will see an individual carrying a bag and holding a canine. Within the background there are buildings, poles and sky with clouds." inputs = processor( textual content=textual content, pictures=picture, return_tensors="pt"
).to(DEVICE)
generated_ids = mannequin.generate( input_ids=inputs["input_ids"], pixel_values=inputs["pixel_values"], max_new_tokens=1024, num_beams=3)
generated_text = processor.batch_decode( generated_ids, skip_special_tokens=False)[0]
response = processor.post_process_generation( generated_text, activity=activity, image_size=picture.dimension)
detections = sv.Detections.from_lmm( sv.LMM.FLORENCE_2, response, resolution_wh=picture.dimension) bounding_box_annotator = sv.BoundingBoxAnnotator( color_lookup=sv.ColorLookup.INDEX)
label_annotator = sv.LabelAnnotator( color_lookup=sv.ColorLookup.INDEX) picture = bounding_box_annotator.annotate(picture, detections)
picture = label_annotator.annotate(picture, detections)
Utilizing LoRA to Optimize Florence-2 Coaching
The Florence-2 base mannequin we’re coaching has 270 million parameters, which isn’t a lot in comparison with fashions like Kosmos-2, however nonetheless vital if we wish to fine-tune our mannequin in Google Colab.
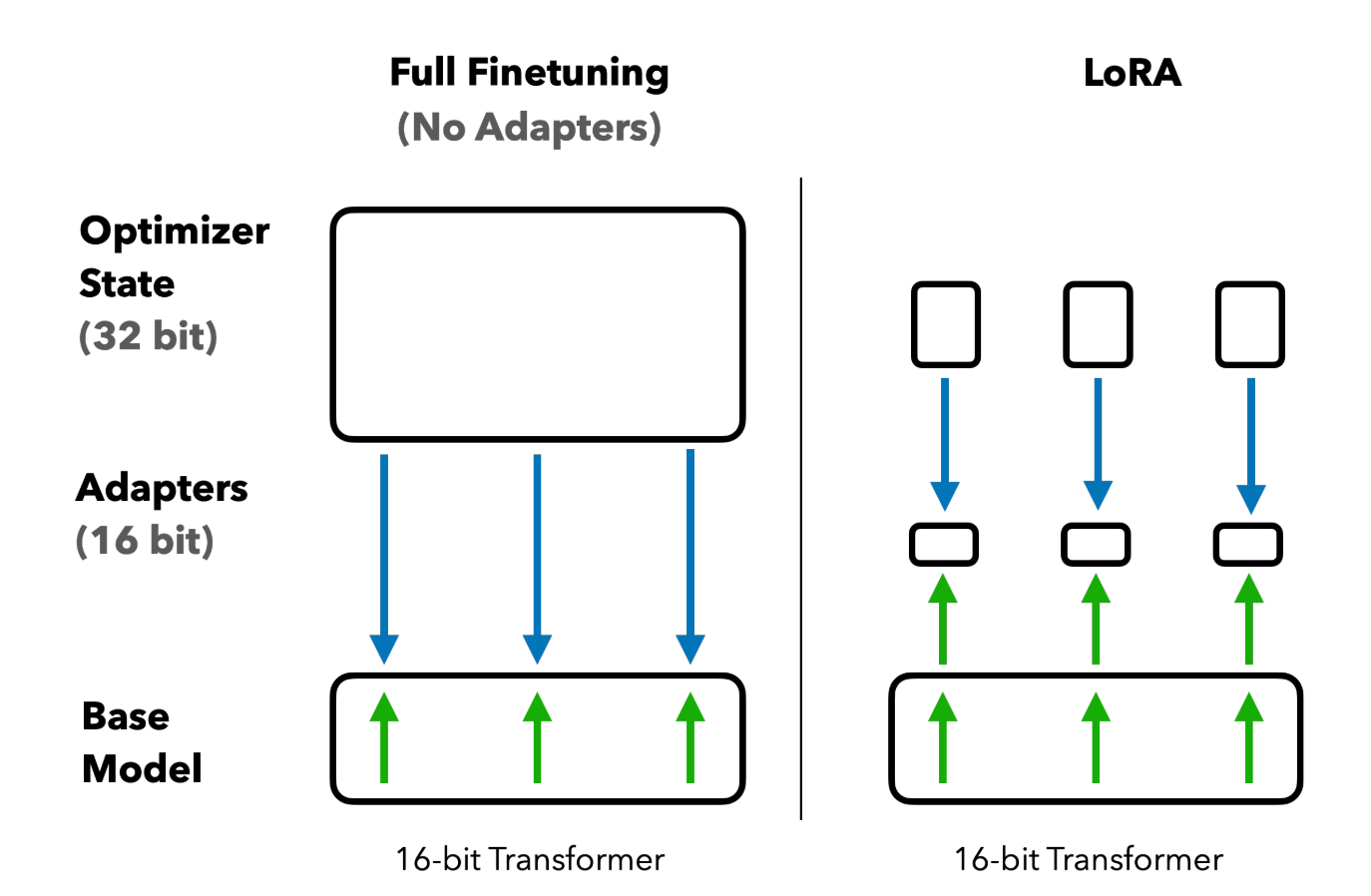
To allow fine-tuning of the complete mannequin with out freezing particular layers, we are going to use LoRA, a method that reduces the variety of trainable parameters by adapting solely a small subset of the mannequin’s weights.
from peft import LoraConfig, get_peft_model TARGET_MODULES = [ "q_proj", "o_proj", "k_proj", "v_proj", "linear", "Conv2d", "lm_head", "fc2"
] config = LoraConfig( r=8, lora_alpha=8, target_modules=TARGET_MODULES, task_type="CAUSAL_LM", lora_dropout=0.05, bias="none", inference_mode=False, use_rslora=True, init_lora_weights="gaussian", revision=REVISION
) peft_model = get_peft_model(mannequin, config)
peft_model.print_trainable_parameters()To make use of LoRA, we are going to make the most of the perf package deal. We set r (rank) to 8, lora_alpha (scaling issue) to 8, and lora_dropout to 0.05. The rank controls the dimensionality of the low-rank matrices utilized in LoRA, whereas the scaling issue adjusts the magnitude of the LoRA replace.
By doing this, we’ve decreased the variety of trainable parameters from roughly 270 million to lower than 2 million – a mere 0.7%. This can enable us to make use of a bigger batch dimension throughout coaching.
Wonderful-tuning Florence-2 Code Overview
Our coaching loop consists of three phases:
Initialization: Earlier than the principle loop, we initialize our optimizer, on this case, AdamW, a variant of the Adam optimizer that comes with weight decay regularization. We additionally initialize a studying charge scheduler to regulate the training charge throughout coaching.
optimizer = AdamW(mannequin.parameters(), lr=lr)
num_training_steps = epochs * len(train_loader)
lr_scheduler = get_scheduler( identify="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps,
)Coaching Loop: Contained in the loop iterating over epochs, we’ve one other loop iterating over batches of our coaching dataset. We carry out inference for every batch, and on the finish, we set off backpropagation and calculate the loss.
mannequin.practice()
train_loss = 0
for inputs, solutions in train_loader: input_ids = inputs["input_ids"] pixel_values = inputs["pixel_values"] labels = processor.tokenizer( textual content=solutions, return_tensors="pt", padding=True, return_token_type_ids=False ).input_ids.to(DEVICE) outputs = mannequin( input_ids=input_ids, pixel_values=pixel_values, labels=labels ) loss = outputs.loss loss.backward() optimizer.step() lr_scheduler.step() optimizer.zero_grad() train_loss += loss.merchandise() avg_train_loss = train_loss / len(train_loader)
print(f"Common Coaching Loss: {avg_train_loss}")Validation Loop: After every coaching epoch, we consider our mannequin on the validation set. We iterate over batches of the validation set, performing inference for every batch. This time, we don’t set off backpropagation, however solely calculate the loss.
mannequin.eval()
val_loss = 0
with torch.no_grad(): for inputs, solutions in val_loader: input_ids = inputs["input_ids"] pixel_values = inputs["pixel_values"] labels = processor.tokenizer( textual content=solutions, return_tensors="pt", padding=True, return_token_type_ids=False ).input_ids.to(DEVICE) outputs = mannequin( input_ids=input_ids, pixel_values=pixel_values, labels=labels ) loss = outputs.loss val_loss += loss.merchandise() avg_val_loss = val_loss / len(val_loader) print(f"Common Validation Loss: {avg_val_loss}")
Wonderful-tuned Florence-2 Mannequin Analysis
Now that our mannequin is skilled, it is time to consider its efficiency. Since we fine-tuned Florence-2 for object detection, we are going to benchmark our mannequin by calculating the imply Common Precision (mAP) and producing a confusion matrix on the validation subset. We are going to use the beforehand put in supervision package deal for this function.
We start by amassing two lists: goal annotations and mannequin predictions. To do that, we loop over our validation dataset and carry out inference utilizing our newly skilled mannequin. Nevertheless, to make the most of our detections for benchmarking, we have to carry out two further steps:
- Since Florence-2 (not like conventional detectors like YOLO) doesn’t have a finite set of detectable lessons, we have to filter out detections with class names that don’t belong to our customized dataset.
- The confusion matrix calculation algorithm requires non-zero confidence values, so we fill them with 1 for every of our detections.
The ensuing mAP50:95 worth we obtained was 0.52. For comparability, coaching YOLOv8 model S on the identical dataset yielded 0.9. Our coaching session lasted solely 10 epochs and the loss was nonetheless lowering on the time of interruption. It’s potential that we might obtain a greater mAP worth by coaching the mannequin for an extended period.
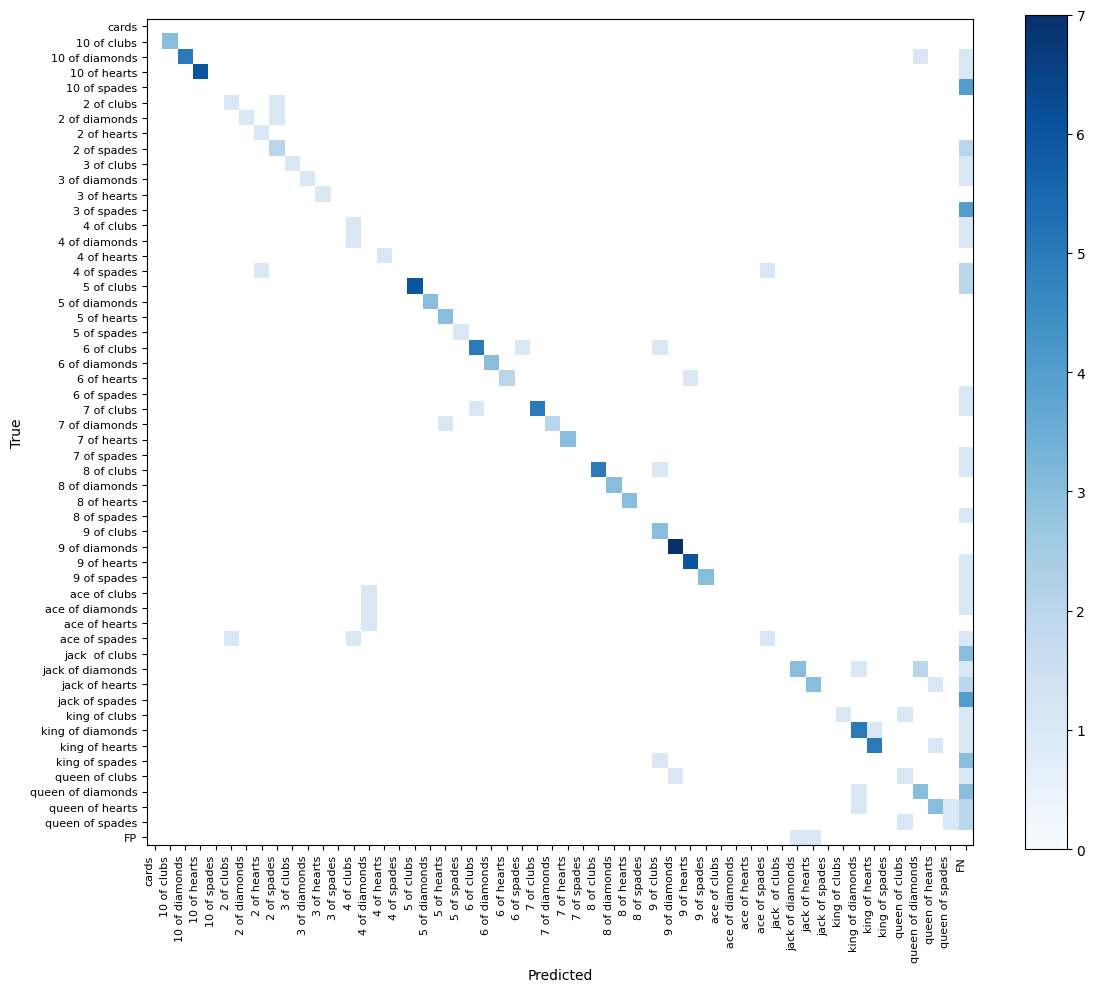
The ensuing confusion matrix additionally appears to be like passable. The overwhelming majority of detections are on the diagonal of our matrix, that means each the bounding field and the category of our detection are right.
Typically, we see that if the mannequin detects objects, it does so with the category we anticipate. Class confusion is uncommon. Our errors are primarily associated to false negatives.
Lastly, we verified whether or not our mannequin might nonetheless detect the bottom lessons on which it was pre-trained after finishing the coaching. Fashions like Florence-2 or PaliGemma might lose among the capabilities of the pre-trained mannequin on account of fine-tuning.

Our check is hardly intensive – it is only one picture – however it appears that evidently the mannequin can nonetheless detect lessons from the COCO dataset.
Conclusion
Florence-2 is a superb mannequin with a variety of supported duties out of the field. Nevertheless, if the pre-trained mannequin lacks information concerning the objects we’re on the lookout for, it’s potential to fine-tune the mannequin on a customized dataset.
Florence-2 performs worse as a detection mannequin than fashions created solely for this function, similar to the newest YOLO fashions. Nevertheless, even when it achieves a decrease mAP, it has a number of benefits:
- The fine-tuned mannequin can nonetheless detect base lessons belonging to the COCO dataset. This may be helpful, for instance, if we’re constructing an app able to detecting automobiles and license plates, we not want two separate fashions. The fine-tuned Florence-2 can detect each lessons.
- Florence-2 can carry out a number of duties. Persevering with our instance with the app that detects automobiles and license plates, if we moreover wish to learn the license plate quantity, we nonetheless solely want one mannequin. Florence-2 can carry out OCR, amongst different issues, and is superb at it.
Moreover, fine-tuning Florence-2 for object detection is much less time-intensive than PaliGemma, particularly if there may be multiple object within the pictures belonging to our dataset or if our dataset incorporates many lessons.



