This text was contributed to the Roboflow weblog by Abirami Vina.
When you’re constructing pc imaginative and prescient methods, there are a number of metrics you should utilize to judge the effectiveness of a system.
One widely-used metric is F1 rating. F1 rating combines precision and recall right into a single worth. A mannequin’s F1 rating is very helpful when false positives and negatives have to be averted.
For instance, take into consideration a medical imaging system used for diagnosing illnesses. False positives might result in pointless remedies, inflicting stress and potential hurt to sufferers, whereas false negatives would possibly end in missed essential remedies. A excessive F1 rating tells us that the mannequin successfully identifies true circumstances with few errors and can be utilized in medical settings.
On this article, we’ll discover the F1 rating, the way it’s calculated, its significance in your pc imaginative and prescient mannequin, and its strengths and limitations in real-world functions. Let’s get began!
An Introduction to Precision and Recall
Earlier than we go in-depth into the F1 rating, we have to study precision and recall. To grasp their formulation, let’s introduce a confusion matrix. A confusion matrix summarizes the outcomes of the mannequin’s predictions on a set of knowledge, evaluating the expected labels to the precise labels.
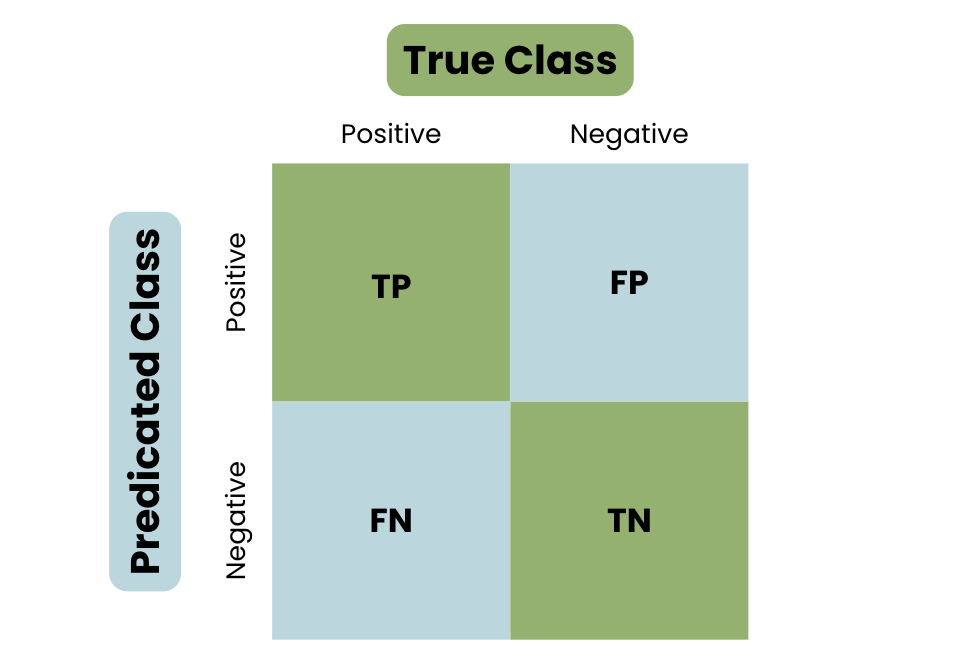
The 4 elements of a confusion matrix are:
- True Optimistic (TP): The variety of cases appropriately predicted as optimistic by the mannequin.
- False Optimistic (FP): The variety of cases incorrectly predicted as optimistic by the mannequin.
- True Destructive (TN): The variety of cases appropriately predicted as unfavourable by the mannequin.
- False Destructive (FN): The variety of cases incorrectly predicted as unfavourable by the mannequin.
Precision measures how correct a mannequin is at figuring out optimistic circumstances. It focuses on the proportion of appropriately recognized optimistic objects (like an apple in a picture) and avoids false positives (mistakenly figuring out an orange as an apple). This helps consider the mannequin’s general skill to differentiate related objects from irrelevant ones.
Right here is the method for calculating Precision:
Precision = True Positives (TP) / (True Positives (TP) + False Positives (FP))
Recall, alternatively, focuses on how effectively a mannequin captures all of the optimistic circumstances. It considers each appropriately recognized optimistic objects (like discovering all apples in a picture) and people the mannequin missed (like failing to detect an apple). When evaluating lacking optimistic cases, like detecting a thief utilizing a safety system, a mannequin’s recall must be excessive.
Right here is the method for calculating Recall:
Recall = True Positives (TP) / (True Positives (TP) + False Negatives (FN))
Now that we’ve understood precision and recall, let’s dive into the F1 rating metric.
What’s an F1 Rating?
An F1 rating is a invaluable metric for assessing a mannequin’s efficiency as a result of it incorporates the trade-off between precision and recall. The fundamental idea of the F1 Rating is that it’s the measure of the harmonic imply of each precision and recall. The worth of the F1 Rating lies between Zero and 1, with one being the perfect.
The method for F1 rating is:
F1 Rating = 2 * (Precision * Recall) / (Precision + Recall)

Calculate F1 Rating For Your Mannequin
Now that we’ve discovered what the F1 Rating is, let’s discover ways to compute it step-by-step with an instance.
Binary Classification
Step 1: You’re creating a pc imaginative and prescient mannequin to find out if a picture has an apple or an orange in it. You have got a mannequin and need to consider its efficiency utilizing the F1 rating. You move 15 pictures with apples and 20 pictures with oranges to the mannequin. From the given 15 apple pictures, the algorithm predicts 9 photos because the orange ones, and from the 20 orange pictures – 6 photos because the apple ones.
Step 2: Let’s take into account apple pictures because the optimistic class and orange pictures because the unfavourable ones.
- Out of 15 Apple pictures (P), 9 had been predicted as oranges. So solely 15 – 9 = 6 predictions had been right. True Optimistic (TP) = 6.
- Despite the fact that 9 had been predicted as oranges, they’d apples on them. So, False Destructive (FN) = 9
- Equally, out of 20 Orange pictures (N), solely 20 – 6 = 14 predictions had been right. True Destructive (TN) = 14.
- Despite the fact that 6 had been predicted as apples, they’d oranges on them. So, False Optimistic (FP) = 6
Step 3: Let’s put this knowledge right into a confusion matrix to visualization it higher.

Step 4: Now, let’s calculate the precision and recall values.
Precision = (TP) / (TP + FP) = (6) / (6 + 6) ~ 0.5
Recall = (TP) / (TP + FN) = (6) / (6 + 9) ~ 0.4
Step 5: Utilizing the values calculated above, compute the F1 Rating.
F1 rating = 2 * (Precision * Recall) / (Precision + Recall) = 2 * (0.5 * 0.4) / (0.5 + 0.4) ~ 0.44
We’ve got arrived at an F1 rating of 0.44 for the mannequin. That is for binary classification.
Now, let’s check out an instance of calculating the F1 rating for multiclass situations. There are three approaches to calculating the F1 rating for a multiclass case: Macro, Micro, and Weighted. We’ll undergo every.
Multiclass Classification
Let’s add one other class to our instance: Mangoes. Let’s say you move 15 pictures with apples, 20 pictures with oranges, and 12 pictures with mangoes to the mannequin. The predictions are as follows:
- 15 apple pictures: 9 as oranges, Three as mangoes, and 15 – 9 – 3 = Three as apples.
- 20 orange pictures: 6 as apples, Four as mangoes, and 20 – 6 – 4 = 10 as oranges.
- 12 mango pictures: Four as oranges, 2 as apples, and 12 – 4 – 2 = 6 as mangoes.
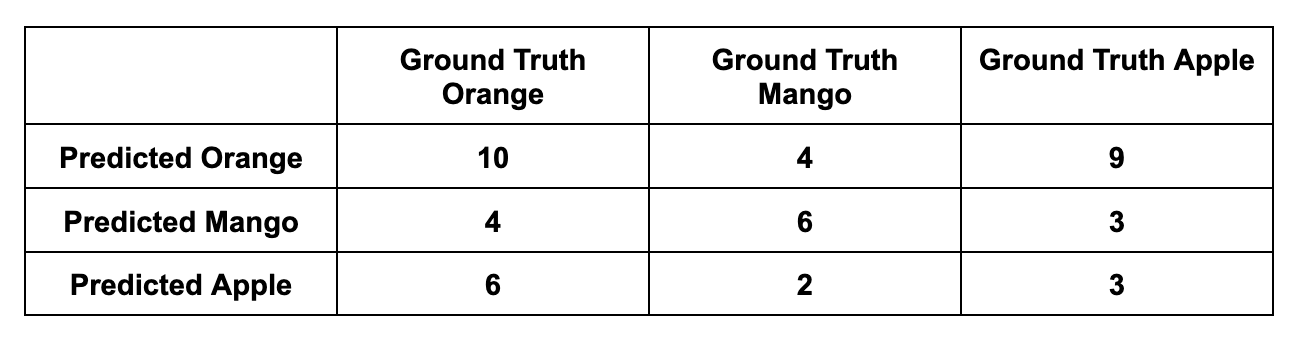
Macro F1 Rating
Macro F1 rating is a option to examine the multiclass classification as a complete. To calculate the Macro F1 rating, you possibly can compute the Macro Precision and the Macro Recall after which use the F1 rating method. This method treats all of the courses equally because it goals to see the larger image and consider the algorithm’s efficiency throughout all of the courses in a single worth.
Let’s see how it’s calculated:
Orange Precision: 10 / (4 + 9 + 10) ~ 0.43
Mango Precision: 6 / (4 + 3 + 6) ~ 0.46
Apple Precision: 3 / (6 + 2 + 3) ~ 0.27 Macro Precision rating: (Orange Precision + Mango Precision + Apple Precision) / 3 = (0.43 + 0.46 + 0.27) / 3 ~ 0.386 Orange Recall: 10 / (4 + 6 + 10) ~ 0.5
Mango Recall: 6 / (4 + 2 + 6) ~ 0.5
Apple Recall: 3 / (9 + 3 + 3) ~ 0.2 Macro Recall rating: (Orange Recall + Mango Recall + Apple Recall) / 3 = (0.5 + 0.5 + 0.2) / 3 ~ 0.Four Macro F1 rating = 2 * (Macro Precision * Macro Recall) / (Macro Precision + Macro Recall) = 2 * (0.386 * 0.4) / (0.386 + 0.4) ~ 0.392Micro F1 Rating
In contrast to the Macro F1 rating, the Micro F1 rating research particular person courses. To calculate it, you possibly can compute Micro Precision and Micro Recall after which use the F1 rating method. The Micro F1 rating will mix the contributions of all courses to calculate the common metric.
Let’s see how this one is calculated:
Micro Precision rating: (TP Orange + TP Mango + TP Apple) / ((TP + FP) Orange + (TP + FP) Mango + (TP + FP) Apple) = (10 + 6 + 3) / ((4 + 9 + 10) + (4 + 3 + 6) + (6 + 2 + 3)) ~ 0.Four Micro Recall rating: (TP Orange + TP Mango + TP Apple) / ((TP + FN) Orange + (TP + FN) Mango + (TP + FN) Apple) = (10 + 6 + 3) / ((4 + 6 + 10) + (4 + 2 + 6) + (9 + 3 + 3)) ~ 0.404 Micro F1 rating = 2 * (Micro Precision * Micro Recall) / (Micro Precision + Micro Recall) = 2 * (0.4 * 0.404) / (0.4 + 0.404) ~ 0.401Weighted F1 Rating
The weighted F1 rating calculates the F1 rating for every class independently, however when it averages them, it makes use of a weight that is determined by the variety of true cases (assist) for every class.
Let’s see how the weighted F1 rating is calculated:
Step #1: Calculate Precision and Recall for every class
Orange:
Precision = TP / (TP + FP) = 10 / (10 + 4 + 9) = 10 / 23 ≈ 0.435
Recall = TP / (TP + FN) = 10 / (10 + 4 + 6) = 10 / 20 = 0.5
Mango:
Precision = TP / (TP + FP) = 6 / (6 + 4 + 3) = 6 / 13 ≈ 0.462
Recall = TP / (TP + FN) = 6 / (6 + 4 + 2) = 6 / 12 = 0.5
Apple:
Precision = TP / (TP + FP) = 3 / (3 + 6 + 2) = 3 / 11 ≈ 0.273
Recall = TP / (TP + FN) = 3 / (3 + 9 + 3) = 3 / 15 = 0.2Calculate the F1 rating for every class:
Orange:
F1 = 2 * (Precision * Recall) / (Precision + Recall) = 2 * (0.435 * 0.5) / (0.435 + 0.5) ≈ 0.465
Mango:
F1 = 2 * (Precision * Recall) / (Precision + Recall) = 2 * (0.462 * 0.5) / (0.462 + 0.5) ≈ 0.480
Apple:
F1 = 2 * (Precision * Recall) / (Precision + Recall) = 2 * (0.273 * 0.2) / (0.273 + 0.2) ≈ 0.231Calculate the Weighted F1 Rating with true cases(assist) of every class:
Assist for Orange = 20
Assist for Mango = 12
Assist for Apple = 15
Weighted F1 = (F1_Orange * Support_Orange + F1_Mango * Support_Mango + F1_Apple * Support_Apple) / (Support_Orange + Support_Mango + Support_Apple)
Weighted F1 = (0.465 * 20 + 0.480 * 12 + 0.231 * 15) / (20 + 12 + 15) = (9.3 + 5.76 + 3.465) / 47 ≈ 18.525 / 47 ≈ 0.394Benefits and Limitations of F1 Rating
Because the F1 Rating is a balanced metric, it’s good for imbalanced datasets, the place one class of observations considerably outweighs the opposite. In such circumstances, accuracy alone may be deceptive, as a mannequin that merely predicts the bulk class can obtain a excessive accuracy rating. The F1 rating, by contemplating each precision and recall, offers a extra strong analysis metric.
One other benefit of utilizing the F1 Rating is that it may be used to check and select fashions that strike the suitable steadiness between precision and recall, relying on the particular necessities of the applying. For instance, in a fraud detection system, precision could also be extra vital, as false positives may be pricey. Alternatively, in a spam e-mail classification system, the recall could also be extra vital, as lacking optimistic cases can have extreme penalties.
Listed below are some limitations that additionally should be thought-about when calculating the F1 rating for a mannequin:
- Unequal Price of Errors: The F1 rating assumes equal significance for precision and recall. This won’t be perfect in conditions the place some errors are much more important than others.
- Restricted Data: It offers a single worth, which could be a downside. It would not reveal particulars concerning the distribution of errors (e.g., what number of false positives vs. negatives).
- Ignores True Negatives: This metric focuses on appropriately classifying optimistic cases and capturing all related ones. Nonetheless, it would not take into account true negatives, which may be vital in some situations the place figuring out irrelevant circumstances is essential.
Conclusion
The F1 rating enables you to perceive a pc imaginative and prescient mannequin’s efficiency past it’s fundamental accuracy. By balancing precision and recall, it grants a clearer image of a mannequin’s real-world effectiveness. So, whereas the F1 rating won’t be the one metric in your dashboard, it is a highly effective instrument for unlocking deeper insights into your mannequin’s true capabilities.



