Introduction to Dimensionality Discount
Dimensionality discount, a vital approach in machine studying and information evaluation, has seen appreciable developments lately, addressing the challenges posed by high-dimensional information in varied fields. This system, which includes lowering the variety of enter variables or options, is essential for simplifying fashions, bettering efficiency, and lowering computational prices whereas retaining important data.
Dimensionality discount strategies can remodel advanced datasets by mapping them into lower-dimensional areas whereas preserving relationships inside the information, reminiscent of patterns or clusters which can be typically obscured in high-dimensional environments.
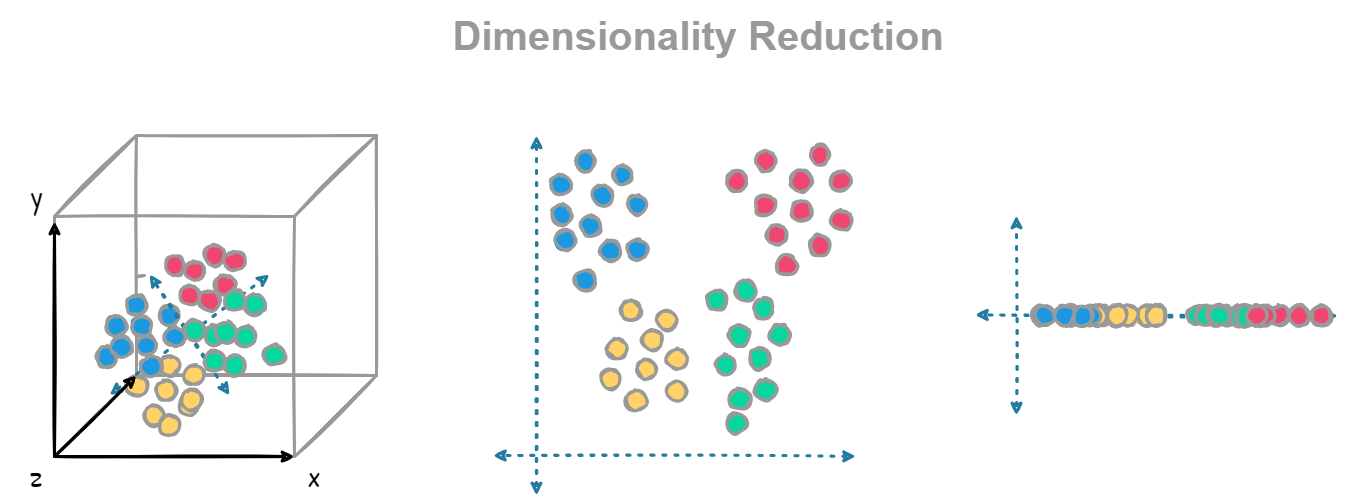
This method to simplifying information buildings results in extra environment friendly algorithms, allows higher visualization, and reduces the danger of overfitting in machine studying fashions. Dimensionality discount is especially efficient in areas like picture processing, pure language processing, and genomics, the place the amount of options might be overwhelming.
On this weblog put up, we’ll discover the core strategies of dimensionality discount, look at their functions, and talk about their influence on fashionable information science and machine studying workflows.
What’s Dimensionality Discount?
Dimensionality discount is a key approach in information evaluation and machine studying, designed to cut back the variety of enter variables or options in a dataset whereas preserving probably the most related data. In real-world datasets, the presence of quite a few variables can enhance complexity, make fashions susceptible to overfitting, and scale back interpretability.
Dimensionality discount strategies sort out these challenges via the creation of recent variables or projections that seize the info’s important traits. The target is to retain the underlying construction, patterns, and relationships inside the information whereas working with fewer dimensions.
By lowering dimensionality, the info turns into simpler to visualise, discover, and analyze, resulting in sooner computations, improved mannequin efficiency, and clearer insights into the underlying elements driving the info.
Why is Dimensionality Discount Obligatory?
Dimensionality discount essential for a number of causes, particularly:
Curse of Dimensionality: Excessive-dimensional information typically suffers from sparsity, making it tough to realize helpful insights or construct correct fashions. Because the variety of options will increase, information factors turn into unfold out, lowering their density. Dimensionality discount counters this subject by lowering characteristic area, bettering the info’s density and interpretability.
Computational Effectivity: The extra contains a dataset incorporates, the extra computationally costly it turns into to run machine studying algorithms. Dimensionality discount helps by reducing the variety of options, lowering the computational burden, and enabling sooner information processing and mannequin coaching.
Overfitting Prevention: Datasets with too many options are extra prone to overfitting, the place fashions seize noise or random variations reasonably than the true patterns. By lowering the dimensionality, we decrease the danger of overfitting, resulting in extra sturdy and generalizable fashions.
Visualization and Interpretation: Visualizing information in excessive dimensions (past three dimensions) is inherently tough. Dimensionality discount strategies mission information into lower-dimensional areas, making it simpler to visualise, interpret, and establish patterns or relationships amongst variables, thus enhancing information understanding and decision-making.
Key Options of Dimensionality Discount
Dimensionality discount strategies supply a number of necessary benefits within the fields of knowledge evaluation and machine studying:
Characteristic Choice: These strategies assist establish and retain probably the most informative and related options from the unique dataset. By eliminating redundant or irrelevant variables, dimensionality discount highlights the subset of options that finest characterize the underlying patterns and relationships within the information.
Information Compression: Dimensionality discount compresses information by reworking it right into a lower-dimensional kind. This condensed illustration preserves as a lot of the vital data as attainable whereas lowering the general measurement of the dataset. It additionally helps scale back each storage calls for and computational complexity.
Noise Discount: Excessive-dimensional datasets typically embody noisy or irrelevant options that may distort evaluation and mannequin efficiency. Dimensionality discount minimizes the impact of this noise by filtering out unimportant variables, thereby bettering the info’s signal-to-noise ratio and enhancing the standard of research.
Enhanced Visualization: Since people can solely visualize information in as much as three dimensions, high-dimensional datasets are tough to interpret. Dimensionality discount initiatives information into decrease dimensions, sometimes two or three, enabling simpler visualization and interpretation of patterns, clusters, and relationships inside the information.
Widespread Dimensionality Discount Methods
On this part, we’ll discover among the mostly used dimensionality discount strategies. Every technique presents distinctive approaches to simplifying high-dimensional information whereas retaining its important options, making them helpful instruments in varied machine studying and information evaluation duties.
Principal Part Evaluation (PCA)
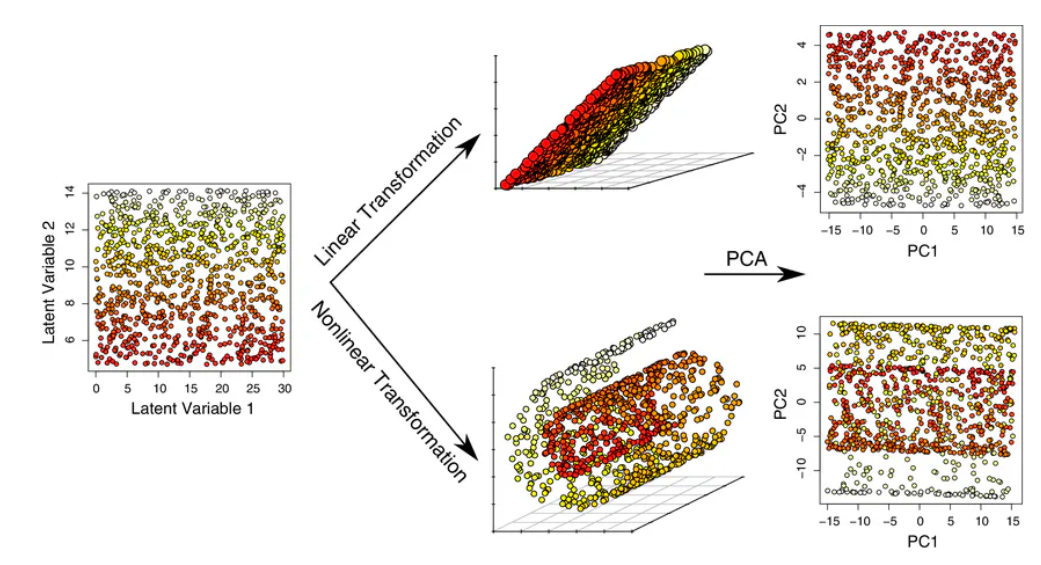
Principal Part Evaluation (PCA) is a linear dimensionality discount approach designed to extract a brand new set of variables from an present high-dimensional dataset. Its main objective is to cut back the dimensionality of the info whereas preserving as a lot variance as attainable.
PCA is an unsupervised algorithm that creates linear mixtures of the unique options, often called principal parts. These parts are calculated such that the primary one captures the utmost variance within the dataset, whereas every subsequent part explains the remaining variance with out being correlated with the earlier ones.
Moderately than deciding on a subset of the unique options and discarding the remaining, PCA kinds new options via linear mixtures of the prevailing ones, providing an alternate illustration of the info. Typically, only some principal parts are retained, those which can be sufficient to seize round of nearly all of the full variance. It’s because every extra part explains progressively much less variance and introduces extra noise. By preserving fewer parts, PCA successfully preserves the sign and filters out noise.
PCA improves interpretability whereas minimizing data loss, making it helpful for figuring out an important options and for visualizing information in 2D or 3D. Nevertheless, it’s best suited to information with linear relationships and will wrestle to seize advanced patterns. Moreover, PCA is delicate to important outliers, which may distort the outcomes.
t-Distributed Stochastic Neighbor Embedding (t-SNE)
t-SNE is a nonlinear dimensionality discount algorithm designed for visualizing high-dimensional information. Its primary objective is to maximise the likelihood of putting related factors shut collectively in a low-dimensional area, whereas preserving the relationships between factors which can be farther aside as a secondary concern. It successfully clusters close by factors whereas pushing all different factors aside.
In contrast to PCA, t-SNE is a probabilistic approach. It minimizes the divergence between two distributions: one measuring pairwise similarities of the unique information and one other measuring similarities among the many corresponding low-dimensional factors. By aligning these distributions, t-SNE successfully represents the unique dataset in fewer dimensions. Particularly, t-SNE employs a standard distribution for the high-dimensional area and a t-distribution for the low-dimensional area. The t-distribution is just like the traditional distribution however has heavier tails, permitting for a sparser clustering of factors that enhances visualization.
t-SNE has a number of tunable hyperparameters, together with:
Perplexity: This controls the scale of the neighborhood for attracting information factors.
Exaggeration: This adjusts the energy of attraction between factors.
Studying Fee: This determines the step measurement for the gradient descent course of that minimizes error.
Tuning these hyperparameters can considerably influence the standard and accuracy of t-SNE outcomes. Whereas t-SNE is highly effective in revealing buildings that different strategies could miss, it may be tough to interpret, as the unique options turn into unidentifiable after processing. Moreover, as a result of it’s stochastic, totally different runs with various initializations can produce totally different outcomes. Its computational and reminiscence complexity is O(n²), which may demand substantial system sources.

Uniform Manifold Approximation and Projection (UMAP)
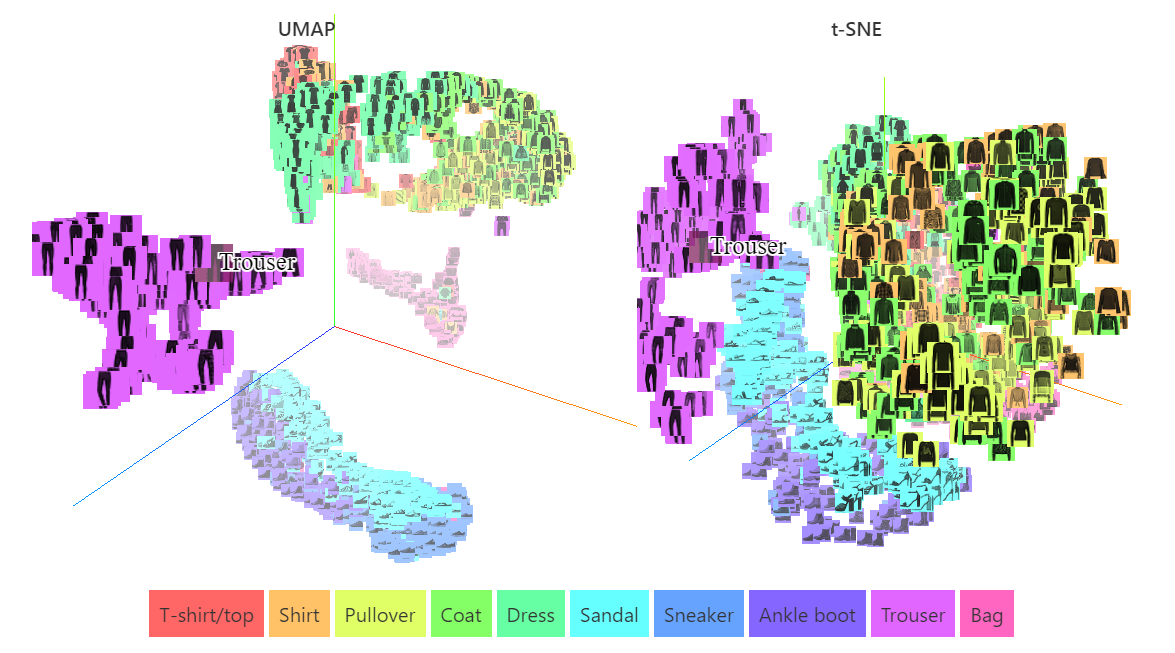
UMAP is a nonlinear dimensionality discount algorithm that addresses among the limitations of t-SNE. Like t-SNE, UMAP goals to create a low-dimensional illustration that preserves relationships amongst neighboring factors in high-dimensional area, but it surely does so with larger velocity and higher retention of the info’s world construction.
UMAP operates as a non-parametric algorithm in two primary steps: (1) it computes a fuzzy topological illustration of the dataset, and (2) it optimizes the low-dimensional illustration to intently match this fuzzy topological illustration, utilizing cross-entropy because the measure. There are two key hyperparameters in UMAP that management the trade-off between native and world buildings within the ultimate output:
Variety of Nearest Neighbors: This parameter determines the steadiness between native and world construction. Decrease values concentrate on native particulars by limiting the variety of neighboring factors thought-about, whereas greater values emphasize the general construction at the price of finer particulars.
Minimal Distance: This parameter dictates how intently UMAP clusters information factors within the low-dimensional area. Smaller values end in extra tightly packed embeddings, whereas bigger values result in a looser association, prioritizing the preservation of broader topological options.
Fantastic-tuning these hyperparameters might be advanced, however UMAP’s velocity permits for a number of runs with totally different settings, enabling higher insights into how projections differ.
When evaluating UMAP to t-SNE, UMAP presents a number of notable benefits. Firstly, it delivers comparable visualization efficiency, permitting for efficient illustration of high-dimensional information. Moreover, UMAP excels in preserving the worldwide construction of the info, making certain that the distances between clusters are significant. This enhances interpretability and evaluation of the relationships inside the information.
Moreover, UMAP operates with larger velocity and effectivity, making it well-suited for dealing with giant datasets with out important computational overhead. Lastly, not like t-SNE, which is primarily designed for visualization functions, UMAP features as a flexible dimensionality discount software that may be utilized throughout varied contexts and functions.
Conclusion
In abstract, dimensionality discount strategies reminiscent of PCA, t-SNE, and UMAP play an important function in information evaluation and machine studying by simplifying advanced, high-dimensional datasets. These strategies not solely assist scale back computational prices and mitigate points like overfitting but in addition improve visualization and interpretability of knowledge.
PCA is efficient for linear information, offering a simple method to establish an important options whereas preserving variance. In distinction, t-SNE excels at revealing native buildings in high-dimensional information, though it could possibly wrestle with world relationships and requires cautious parameter tuning. UMAP addresses a few of these limitations, providing sooner efficiency and higher preservation of world construction, making it appropriate for a wider vary of functions.
Finally, the selection of dimensionality discount approach depends upon the precise wants of your evaluation, together with the character of the info, desired outcomes, and computational sources. By understanding the strengths and limitations of every technique, you’ll be able to successfully leverage these instruments to realize deeper insights and drive knowledgeable decision-making in your initiatives.



